
《Self-Supervised Monocular Scene Flow Estimation》论文笔记
参考代码:self-mono-sf
1. 概述
介绍:这篇文章介绍了一种自监督单目相机场景流和深度估计方法,单目场景流是需要在单目视频序列中估计出像素的3D空间移动信息,而且在没有标注的情况下完成该任务,因而其需要克服更多的困难。这篇文章的方法是在PWC-Net的基础上进行创新改进而来的,在预测过程中该方法中将3D场景流和深度估计任务组合起来,并在构建的cost-volume上进行解码预测。对于单目的视觉任务是会存在场景scale不准确、目标遮挡等情况的,对此文章引入了双目图像用于解决单目中存在的scale不准确问题,并通过光流映射采用启发式的遮挡掩膜提取机制解决遮挡的问题。在自监督的单目深度估计中一个比较头疼的问题便是场景中的运动物体,这篇文章将单目深度估计和3D场景流组合起来可看作是对该场景的一种解决思路(文章:Unsupervised Monocular Depth Learning in Dynamic Scenes也是一种类似的解决办法)。
在这篇文章中将单目深度估计与3D场景流组合起来进行预测,并将这两个任务互为补充构建约束表达用于监督。通过双目图像对、光流遮挡掩膜计算、3D空间点约束有效处理自监督过程中存在的问题(如scale问题),文章算法的预测效果见下图所示:

2. 方法设计
2.1 pipeline
文章方法的整体pipeline见下图所示:
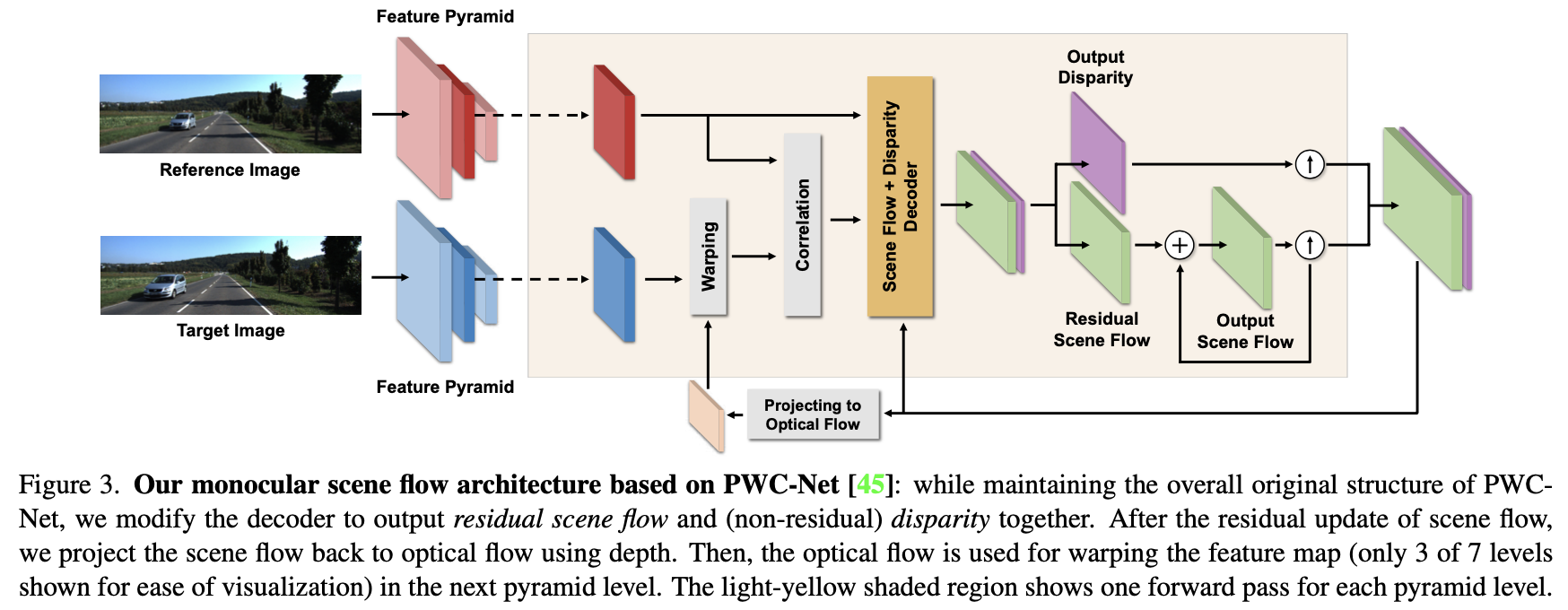
文章的方法的主体架构是来自于双目匹配网络PWC-Net的,不同点是同时估计3D场景流和单目深度信息,并且其中的场景流不是估计的残差而是在每个level都估计完整场景流。另外一个不同点是采用自监督的形式进行约束,因而有了最下面的warp分支。
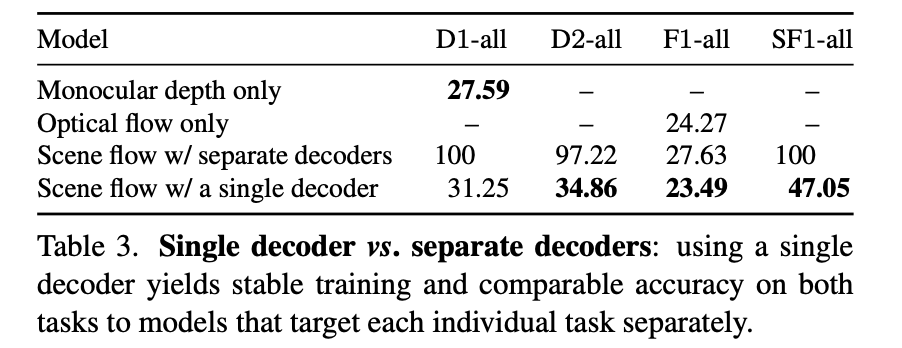
对于文章的方法为何要将scene flow和depth联合估计,以及共同使用一个解码器去预测,这里直接给出实测的性能比较以进行说明:
2.2 单目深度估计
在文章的任务中需要估计参考图像
I
t
I_t
It中像素点
p
=
(
p
x
,
p
y
)
p=(p_x,p_y)
p=(px,py)的3D坐标点
P
=
(
P
x
,
P
y
,
P
z
)
P=(P_x,P_y,P_z)
P=(Px,Py,Pz),和该3D点到目标图像
I
t
+
1
I_{t+1}
It+1对应像素3D点
P
′
=
(
P
x
′
,
P
y
′
,
P
z
′
)
P^{'}=(P^{'}_x,P^{'}_y,P^{'}_z)
P′=(Px′,Py′,Pz′)的场景流
s
=
(
s
x
,
s
y
,
s
z
)
s=(s_x,s_y,s_z)
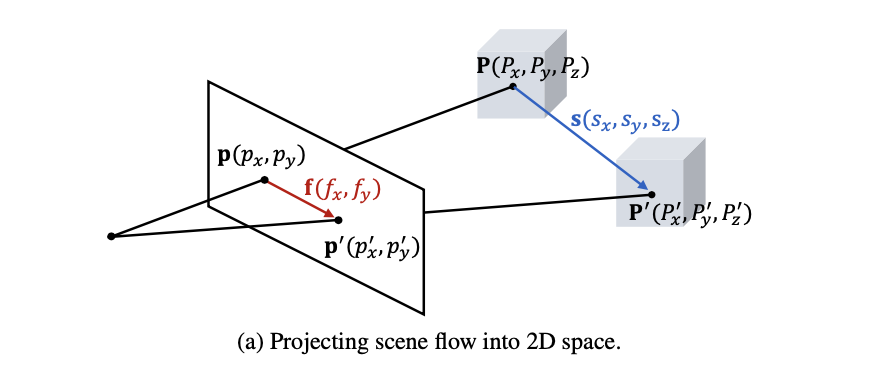
s=(sx,sy,sz)。也就是下图中描绘的对应关系:
要准确估计场景流
s
=
(
s
x
,
s
y
,
s
z
)
s=(s_x,s_y,s_z)
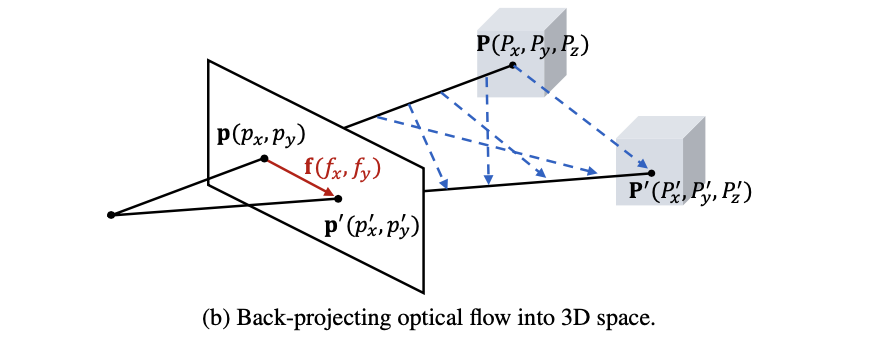
s=(sx,sy,sz)就需要产生运动变化的3D点准确,但是在单目场景下深度是存在scale上的不确定性,也就是下图中展示的情况(一个3D点其对应的真实深度值是存在多个解的):
那么怎么去处理这个深度估计scale上的不确定性呢?一个有效的办法便是使用双目系统,在给定相机焦距
f
f
o
c
a
l
f_{focal}
ffocal,基线距离为
b
b
b,那么对应的深度就可以描述为:
d
^
=
f
f
o
c
a
l
⋅
b
d
\hat{d}=\frac{f_{focal}\cdot b}{d}
d^=dffocal⋅b,这样就可以解决scale带来的不确定性问题。
PS: 这里需要注意的是上述提到的双目图像中参与深度估计与3D场景流估计的图像均为双目系统的左视图,右视图主要用于实现对scale的约束和生成遮挡掩膜。而且上述使用双目的过程是在训练的阶段(也就是在训练过程中右视图用于训练引导),而在测试阶段还是使用的单目视频序列进行预测。
对于这篇文章方法训练所需的数据是连续的双目视频帧 { I t l , I t + 1 l , I t r , I t + 1 r } \{I_t^l,I_{t+1}^l,I_t^r,I_{t+1}^r\} {Itl,It+1l,Itr,It+1r}。在深度估计任务中会使用帧 { I t l , I t + 1 l } \{I_t^l,I_{t+1}^l\} {Itl,It+1l}分别估计对应的视差图 { d t l , d t + 1 l } \{d_t^l,d_{t+1}^l\} {dtl,dt+1l},以及这两帧图像按照顺序排列不同得到的3D场景流 { s f w l , s b w l } \{s_{fw}^l,s_{bw}^l\} {sfwl,sbwl}。
对于深度估计任务其采用约束是光度一致性,这一点与传统意义上的自监督单目深度估计类似。只不过这里光度一致性是建立在双目系统之上的,通过给定的双目相机标定参数和左视图估计出的视差
d
t
l
d_t^l
dtl将右视图
I
t
l
I_t^l
Itl(
t
+
1
t+1
t+1时刻同理,这里只讲
t
t
t时刻)变换到左视图得到左视图的重建结果
I
^
t
l
,
d
\hat{I}_t^{l,d}
I^tl,d。那么就可以在这个重建视图和原视图上进行光度一致性约束:
ρ
(
a
,
b
)
=
α
1
−
S
S
I
M
(
a
,
b
)
2
+
(
1
−
α
)
∣
∣
a
−
b
∣
∣
1
\rho(a,b)=\alpha\frac{1-SSIM(a,b)}{2}+(1-\alpha)||a-b||_1
ρ(a,b)=α21−SSIM(a,b)+(1−α)∣∣a−b∣∣1
其中,
α
=
0.85
\alpha=0.85
α=0.85。但是这里又一个问题需要去解决那就是遮挡的问题,在MonoDepth2中是通过选取最小光度重构误差方式进行处理。而这篇文章中采用的是估计右视图的视差
d
t
r
d_t^r
dtr,之后进行前向映射判断映射之后的值是否满足判定条件来判定是否为遮挡区域(因为遮挡区域映射不过去嘛),这样就可以得到遮挡掩膜
O
t
l
,
d
i
s
p
∈
{
0
,
1
}
O_t^{l,disp}\in\{0,1\}
Otl,disp∈{0,1}(其中0代表未遮挡)。其实现代码可以参考该函数:
# losses.py#L85
def _adaptive_disocc_detection_disp(disp):
# # init
b, _, h, w, = disp.size()
mask = torch.ones(b, 1, h, w, dtype=disp.dtype, device=disp.device).float().requires_grad_(False)
flow = torch.zeros(b, 2, h, w, dtype=disp.dtype, device=disp.device).float().requires_grad_(False)
flow[:, 0:1, :, : ] = disp * w
flow = flow.transpose(1, 2).transpose(2, 3)
disocc = torch.clamp(forward_warp()(mask, flow), 0, 1)
disocc_map = (disocc > 0.5)
if disocc_map.float().sum() < (b * h * w / 2):
disocc_map = torch.ones(b, 1, h, w, dtype=torch.bool, device=disp.device).requires_grad_(False)
return disocc_map
那么对于光对一致性的约束添加了遮挡mask之后就可以描述为:
L
d
_
p
h
=
∑
p
(
1
−
O
t
l
,
d
i
s
p
(
p
)
)
⋅
ρ
(
I
t
l
(
p
)
,
I
^
t
l
,
d
(
p
)
)
∑
q
(
1
−
O
t
l
,
d
i
s
p
(
q
)
)
L_{d\_ph}=\frac{\sum_p(1-O_t^{l,disp}(p))\cdot\rho(I_t^l(p),\hat{I}_t^{l,d}(p))}{\sum_q(1-O_t^{l,disp}(q))}
Ld_ph=∑q(1−Otl,disp(q))∑p(1−Otl,disp(p))⋅ρ(Itl(p),I^tl,d(p))
此外,对于视差估计的结果也一样添加了平滑约束,不过这里的平滑约束是二阶的形式:
L
d
_
s
m
=
1
N
∑
p
∑
i
∈
{
x
,
y
}
∣
∇
i
2
d
t
l
(
p
)
∣
⋅
e
−
β
∣
∣
∇
i
I
t
l
(
p
)
∣
∣
1
L_{d\_sm}=\frac{1}{N}\sum_p\sum_{i\in\{x,y\}}|\nabla_i^2d_t^l(p)|\cdot e^{-\beta||\nabla_iI_t^l(p)||_1}
Ld_sm=N1p∑i∈{x,y}∑∣∇i2dtl(p)∣⋅e−β∣∣∇iItl(p)∣∣1
那么,整体上对于深度估计部分的损失函数描述为:
L
d
=
L
d
p
h
+
λ
d
_
s
m
L
d
_
s
m
L_d=L_{d_ph}+\lambda_{d\_sm}L_{d\_sm}
Ld=Ldph+λd_smLd_sm
其中,
λ
d
_
s
m
=
0.1
\lambda_{d\_sm}=0.1
λd_sm=0.1。
2.3 场景流估计
对于给定的两张不同时刻的左视图
{
I
t
l
,
I
t
+
1
l
}
\{I_t^l,I_{t+1}^l\}
{Itl,It+1l},估计出来的前向和后向光流信息
{
s
f
w
l
,
I
b
w
l
}
\{s_{fw}^l,I_{bw}^l\}
{sfwl,Ibwl},估计出的左视图视差
{
d
t
l
,
d
t
+
1
l
}
\{d_t^l,d_{t+1}^l\}
{dtl,dt+1l}。那么在给定
{
I
t
+
1
l
,
d
t
l
,
I
f
w
l
}
\{I_{t+1}^l,d_t^l,I_{fw}^l\}
{It+1l,dtl,Ifwl}的情况下可以重建出
I
^
t
l
,
s
f
\hat{I}_t^{l,sf}
I^tl,sf。那么这个重建的过程可以通过光度重构误差的形式进行约束,也就是下面所示的形式:
L
s
f
_
p
h
=
∑
p
(
1
−
O
t
l
,
s
f
(
p
)
)
⋅
ρ
(
I
t
l
(
p
)
,
I
^
t
l
,
s
f
(
p
)
)
∑
q
(
1
−
O
t
l
,
s
f
(
q
)
)
L_{sf\_ph}=\frac{\sum_p(1-O_t^{l,sf}(p))\cdot\rho(I_t^l(p),\hat{I}_t^{l,sf}(p))}{\sum_q(1-O_t^{l,sf}(q))}
Lsf_ph=∑q(1−Otl,sf(q))∑p(1−Otl,sf(p))⋅ρ(Itl(p),I^tl,sf(p))
其中,遮挡部分描述掩膜
O
t
l
,
s
f
O_t^{l,sf}
Otl,sf是通过光流
s
b
w
l
s_{bw}^l
sbwl反向映射得到的。除了上述提到的光度重构误差以外,文章还在3D空间对光流和视差估计进行约束,其中对于图像
I
t
l
I_t^l
Itl中的点
p
p
p到图像
I
t
+
1
l
I_{t+1}^l
It+1l中的一点
p
′
p^{'}
p′的映射关系可以描述为(
K
K
K为内参矩阵):
p
′
=
K
(
d
^
t
l
⋅
K
−
1
p
+
s
f
w
l
(
p
)
)
p^{'}=K(\hat{d}_t^l\cdot K^{-1}p+s_{fw}^l(p))
p′=K(d^tl⋅K−1p+sfwl(p))
既然有了这样的关系,结合上述内容中的场景流、视差图就可以通过2D到3D的变换在3D空间维度进行约束,则其在3D空间的约束被描述为:
L
s
f
_
p
t
=
∑
p
(
1
−
O
t
l
,
s
f
(
p
)
)
⋅
∣
∣
P
t
′
−
P
t
+
1
′
∣
∣
2
∑
q
(
1
−
O
t
l
,
s
f
(
q
)
)
L_{sf\_pt}=\frac{\sum_p(1-O_t^{l,sf}(p))\cdot||P_t^{'}-P_{t+1}^{'}||_2}{\sum_q(1-O_t^{l,sf}(q))}
Lsf_pt=∑q(1−Otl,sf(q))∑p(1−Otl,sf(p))⋅∣∣Pt′−Pt+1′∣∣2
其中,分别来自图
{
I
t
l
,
I
t
+
1
l
}
\{I_t^l,I_{t+1}^l\}
{Itl,It+1l}的3D点计算为:
P
t
′
=
d
^
t
l
(
p
)
⋅
K
−
1
p
+
s
f
w
l
(
p
)
P_t^{'}=\hat{d}_t^l(p)\cdot K^{-1}p+s_{fw}^l(p)
Pt′=d^tl(p)⋅K−1p+sfwl(p)
P
t
+
1
′
=
d
^
t
+
1
l
(
p
′
)
⋅
K
−
1
p
′
P_{t+1}^{'}=\hat{d}_{t+1}^l(p^{'})\cdot K^{-1}p^{'}
Pt+1′=d^t+1l(p′)⋅K−1p′
对于3D空间的约束其实可以使用下图的场景进行描述,目的就是通过3D空间的约束使得视差和场景流估计更加准确。
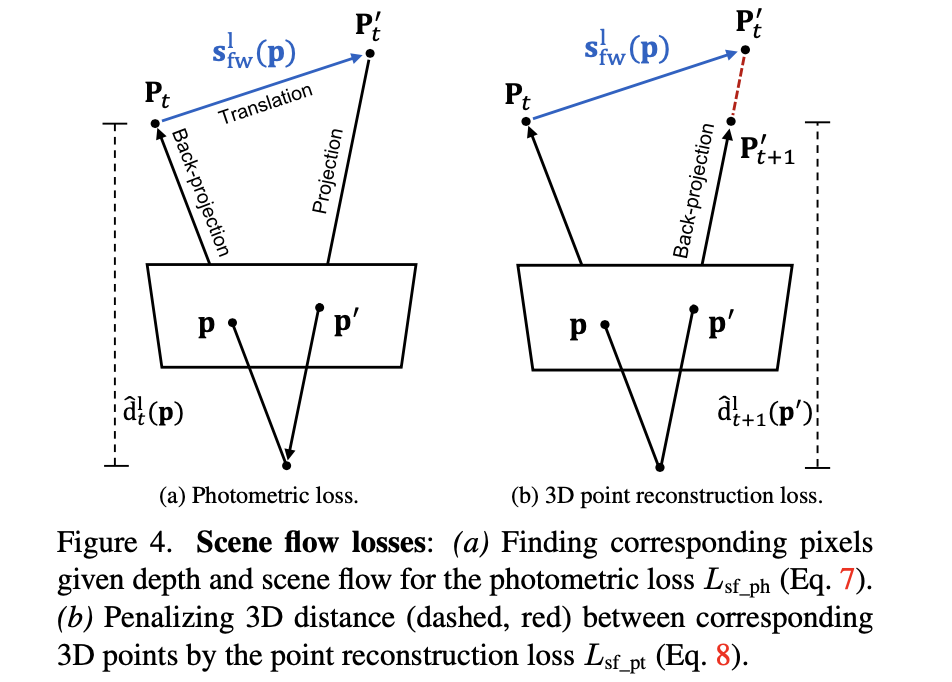
同样的也需要对场景流进行平滑约束:
L
s
f
_
s
m
=
1
N
∑
p
∑
i
∈
{
x
,
y
}
∣
∇
i
2
s
f
w
l
(
p
)
∣
⋅
e
−
β
∣
∣
∇
i
I
t
l
(
p
)
∣
∣
1
L_{sf\_sm}=\frac{1}{N}\sum_p\sum_{i\in\{x,y\}}|\nabla_i^2s_{fw}^l(p)|\cdot e^{-\beta||\nabla_iI_t^l(p)||_1}
Lsf_sm=N1p∑i∈{x,y}∑∣∇i2sfwl(p)∣⋅e−β∣∣∇iItl(p)∣∣1
那么,场景流部分的整体损失函数描述为:
L
s
f
=
L
s
f
_
p
h
+
λ
s
f
_
p
t
L
s
f
_
p
t
+
λ
s
f
_
s
m
L
s
f
_
s
m
L_{sf}=L_{sf\_ph}+\lambda_{sf\_pt}L_{sf\_pt}+\lambda_{sf\_sm}L_{sf\_sm}
Lsf=Lsf_ph+λsf_ptLsf_pt+λsf_smLsf_sm
其中,
λ
s
f
_
p
t
=
0.2
,
λ
s
f
_
s
m
=
200
\lambda_{sf\_pt}=0.2,\lambda_{sf\_sm}=200
λsf_pt=0.2,λsf_sm=200。则总结上文文章的全部损失函数为:
L
t
o
t
a
l
=
L
d
+
λ
s
f
L
s
f
L_{total}=L_d+\lambda_{sf}L_{sf}
Ltotal=Ld+λsfLsf
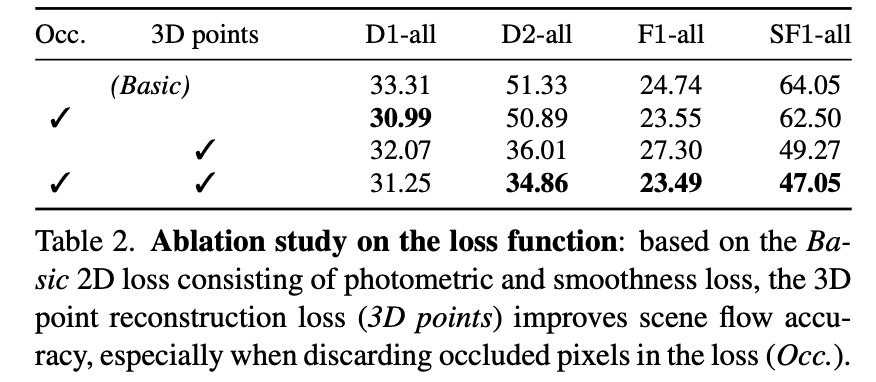
上述提到的遮挡检测和3D点约束对性能的影响见下表:
2.4 数据增广与Cam-Conv
在这篇文章中采用的数据增广包含:random scales、cropping、resizing、horizontal image flip。同时为了避免数据增广之后相机内参改变对深度估计性能带来影响,这里引入Cam-Conv替换原有卷积网络。并将这两个变量消融实验得到下表:
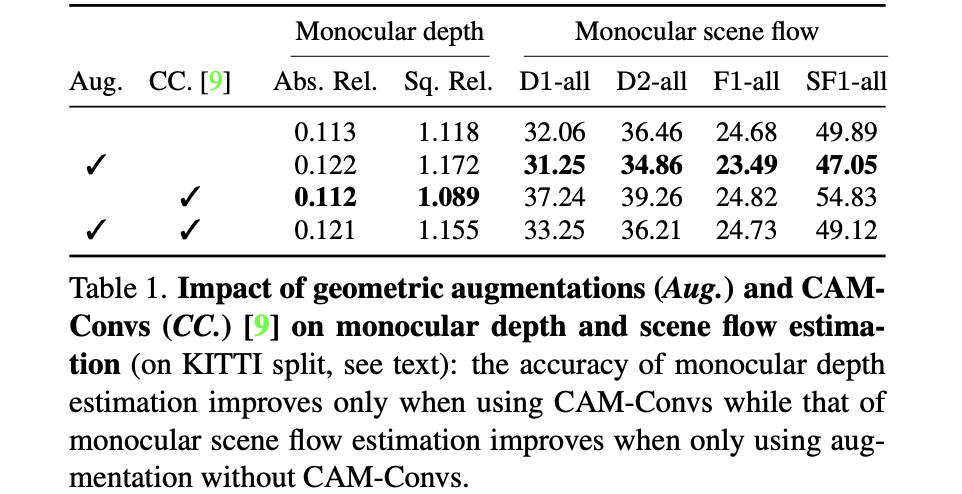
结合上表可以看到Cam-Conv和scene flow任务是存在一定的冲突的。
3. 实验结果

相关文章
- 学习索引结构的一些案例——Jeff Dean在SystemML会议上发布的论文(中)
- Online Object Tracking: A Benchmark 论文笔记(转)
- 2018年3月17日论文阅读
- 论文笔记(7):Constrained Convolutional Neural Networks for Weakly Supervised Segmentation
- 论文笔记(3):STC: A Simple to Complex Framework for Weakly-supervised Semantic Segmentation
- 论文笔记(6):Weakly-and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation
- 论文笔记(2):Deep Crisp Boundaries: From Boundaries to Higher-level Tasks
- 机器学习笔记 - U-Net论文解读
- 机器学习笔记 - Transformer/Attention论文解读
- 谷歌Borg论文阅读笔记(一)——分布式架构
- 谷歌Borg论文阅读笔记(二)——任务混部的解决
- DL之GAN&DCGNN&cGAN:GAN&DCGNN&cGAN算法思路、关键步骤的相关配图和论文集合
- 解读顶会ICDE’21论文:利用DAEMON算法解决多维时序异常检测问题
- 【论文笔记】一种有效攻击BERT等模型的方法
- 论文笔记:目标追踪-CVPR2014-Adaptive Color Attributes for Real-time Visual Tracking
- 毕业设计 Spring Boot 电影院在线售票管理系统系统(源码+论文)
- 论文解读《Automatically discovering and learning new visual categories with ranking statistics》
- 论文解读(GGD)《Rethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with Group Discrimination》
- 论文解读(PCL)《Prototypical Contrastive Learning of Unsupervised Representations》
- NLP模型笔记2022-07:一种联合中文分词和依存分析的统一模型训练CTB5数据集【论文复现+源码+数据集下载】
- 读书与写论文的引导书——leo鉴书60
- 【讲座笔记】科研论文的构思、规划和写作--中南大帅词俊
- 论文投稿指南——中文核心期刊推荐(石油、天然气工业 3)
- 论文笔记系列:经典主干网络(二)-- ResNet
- 《论文阅读》MOJITALK: Generating Emotional Responses at Scale
- 美团外卖——物流论文小笔记(Python实现)
- 论文笔记:高精度室内定位研究评述及未来演进展望
- 论文笔记:Adaptive event detection for Representative Load Signature Extraction
- 论文笔记:一种适用于NILM的暂态事件检测算法(滑动窗双边CUSUM)