
《A Simple Baseline for BEV Perception Without LiDAR》论文笔记
参考代码:bev_baseline
project page:A Simple Baseline for BEV Perception Without LiDAR
1. 概述
介绍:在这篇文章中提出了一种特别简单但效果不错的bev特征提取方法,也就是通过在构建的bev grid中向图像特征进行反向投影,并在投影点处对图像特征进行双线性插值采样得到图像模态下的bev特征。同时对于lidar和radar这些其它模态的传感器信息输入(若有),直接在编码之后与之前bev特征进行concat操作融合,以此来构建多模态bev特征。除开使用该方式进行bev特征构建之外,文章还仔细分析了在网络训练中batchsize、image augmentation、image resolution等超参数给网络性能带来的影响,并对这些变量做了对应消融实验,可为后续模型训练引入参考。此外,之前radar的结果在bev特征构建过程中是不那么重要的,相比lidar确实差挺多的,但是有好歹聊胜于无。在文章的实验结果中也证实了这些数据都是对bev感知效果提升是有用的。另外,文章的backbone为ResNet-101。
首先对bev特征构建的过程进行回顾,这里作者分析了几种bev构建的方案:
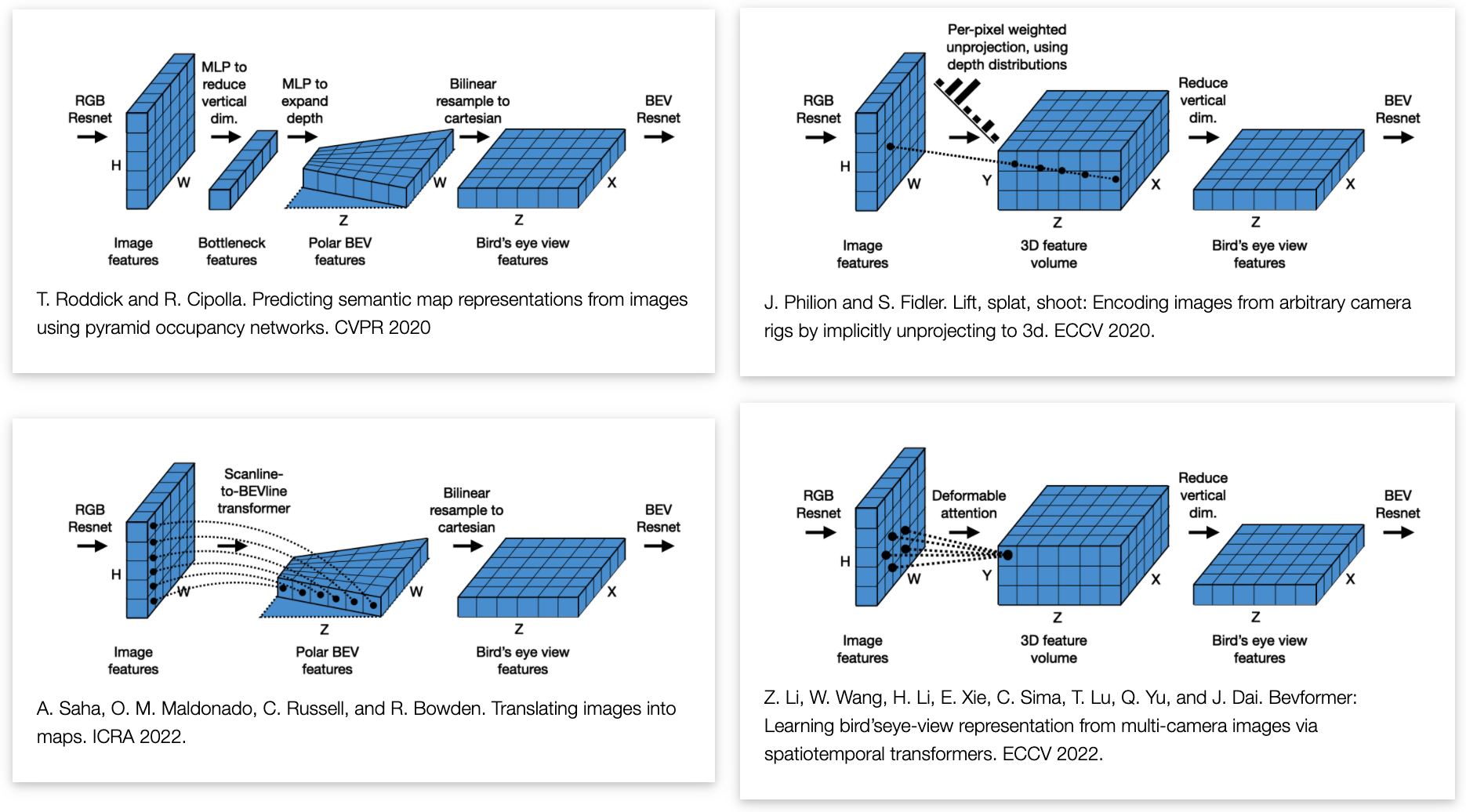
- 1)对网络提取金字塔特征(也就是不同cnn网络不同stage输出特征)通过网络映射实现在不同深度范围上bev特征映射,其方法也就是左上角的图,实现可以参考:pyramid.py;
- 2)将深度信息隐式编码到网络特征图中构建视锥,从而得到bev特征图,以LSS方法为代表,见右上角图;
- 3)将bev特征构建任务转换为width-wise的投影任务,见左下角图;
- 4)首先构建bev grid,并以此作为transformer的queris,从而通过attention的方式得到最后bev特征;
2. 方法设计
2.1 pipeline
文章的方法如下:
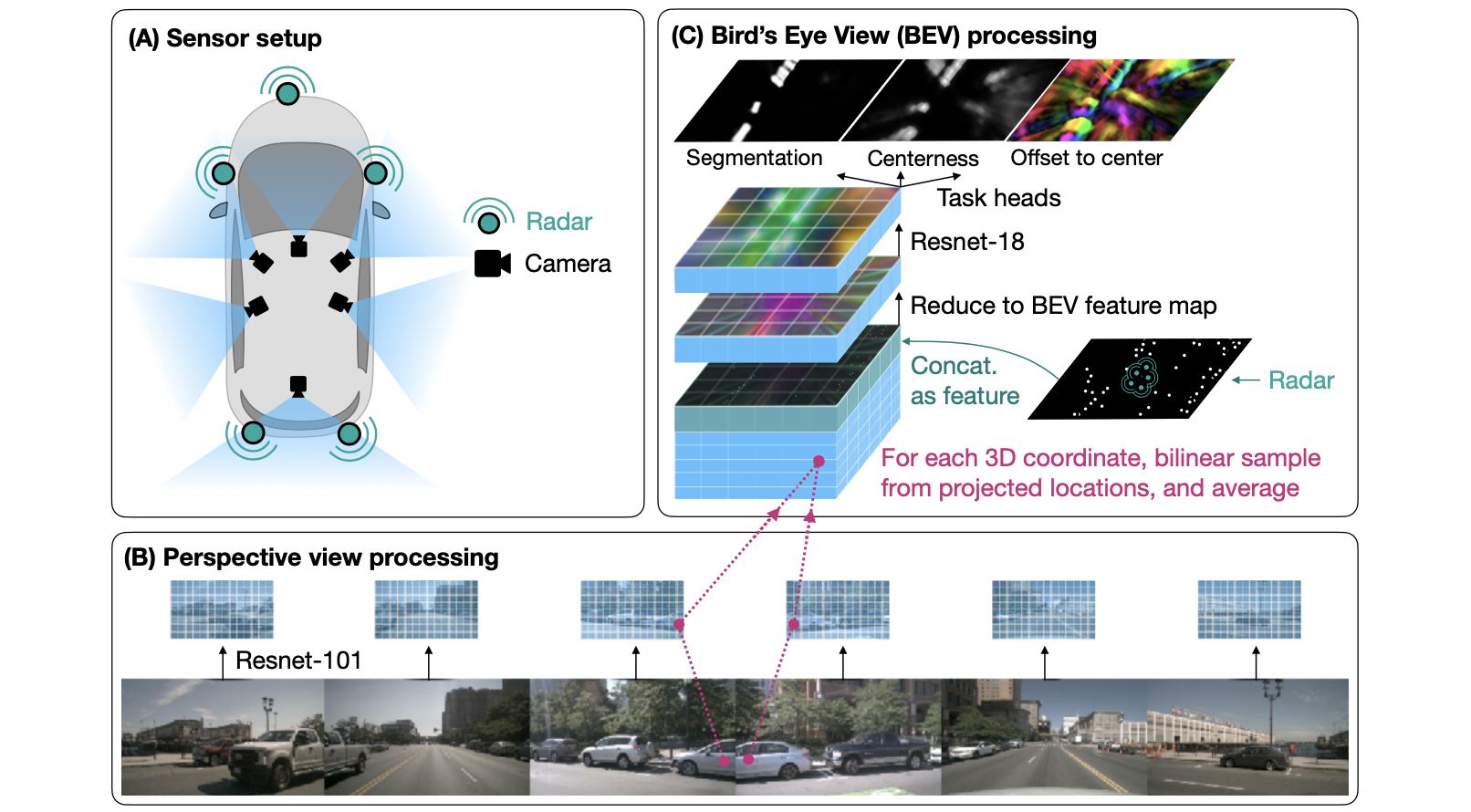
输入的是多模态传感器,这些传感器的信息经过编码之后会统一准还到bev特征下,之后这些特征使用concat进行融合,从而得到完整bev特征。在此基础上对bev解码器进行优化,这里在进行bev特征优化之前会对bev特征在Y维度上进行压缩投影,从而将一个4D特征变换为3D特征,方便后续CNN网络运算。那么对于特征优化过程使用一个resnet-18网络构建一个U型结构去refine bev特征,之后通过不同的预测头实现bev预测。
对于构建bev特征的过程文章使用的是投影之后双线性采样的形式,也就是如下图中所示:
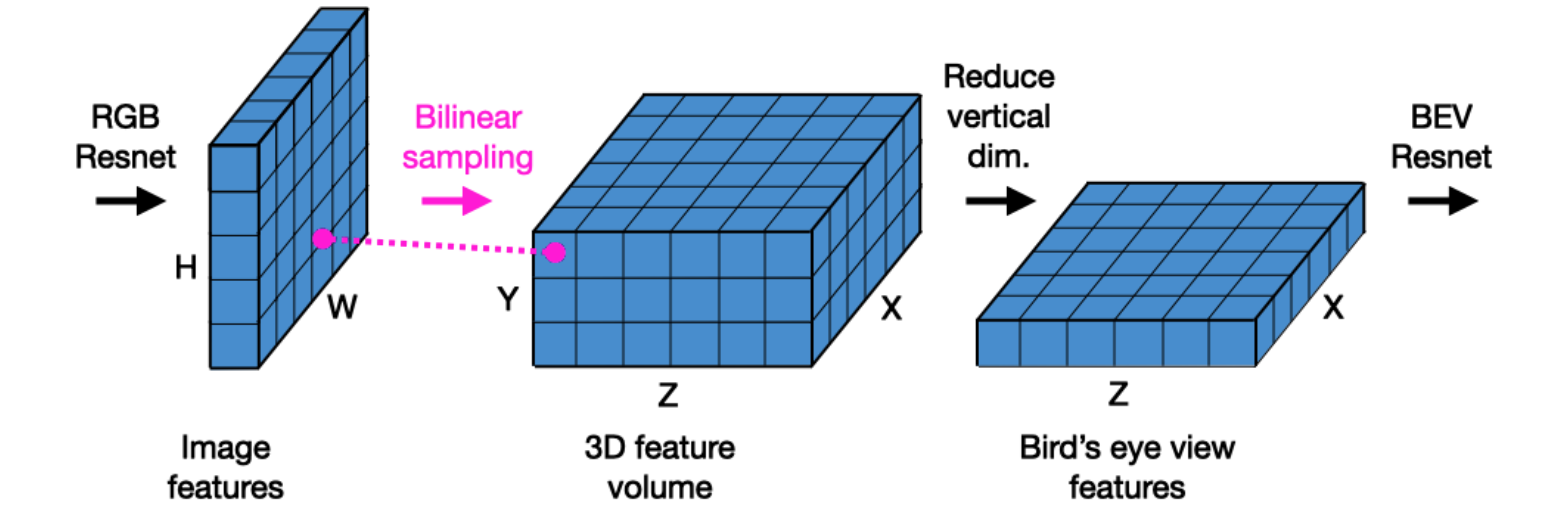
2.2 bev投影过程
这部分的核心是较为独立的空间坐标变换操作:
# utils/vox.py#291
def unproject_image_to_mem(self, rgb_camB, pixB_T_camA, camB_T_camA, Z, Y, X, assert_cube=False):
# rgb_camB is B x C x H x W camera特征
# pixB_T_camA is B x 4 x 4 到相机坐标到图像坐标——内参
# pixB_T_camA is B x 4 x 4 世界坐标到相机坐标转换——平移和旋转矩阵
# rgb lives in B pixel coords
# we want everything in A memory coords
# this puts each C-dim pixel in the rgb_camB
# along a ray in the voxelgrid
B, C, H, W = list(rgb_camB.shape)
xyz_memA = utils.basic.gridcloud3d(B, Z, Y, X, norm=False, device=pixB_T_camA.device) # 构建3D空间网格[B,N,3]
xyz_camA = self.Mem2Ref(xyz_memA, Z, Y, X, assert_cube=assert_cube) # 将3D空间点映射到图像对应相机坐标维度
xyz_camB = utils.geom.apply_4x4(camB_T_camA, xyz_camA)
z = xyz_camB[:,:,2]
xyz_pixB = utils.geom.apply_4x4(pixB_T_camA, xyz_camA) # 相机坐标3D空间点到图像特征的映射
normalizer = torch.unsqueeze(xyz_pixB[:,:,2], 2)
EPS=1e-6
# z = xyz_pixB[:,:,2]
xy_pixB = xyz_pixB[:,:,:2]/torch.clamp(normalizer, min=EPS) # 除以深度信息得到XY平面坐标
# this is B x N x 2
# this is the (floating point) pixel coordinate of each voxel
x, y = xy_pixB[:,:,0], xy_pixB[:,:,1]
# these are B x N
x_valid = (x>-0.5).bool() & (x<float(W-0.5)).bool() # 计算投影之后XY平面坐标的有效性
y_valid = (y>-0.5).bool() & (y<float(H-0.5)).bool()
z_valid = (z>0.0).bool()
valid_mem = (x_valid & y_valid & z_valid).reshape(B, 1, Z, Y, X).float()
if (0):
# handwritten version
values = torch.zeros([B, C, Z*Y*X], dtype=torch.float32)
for b in list(range(B)):
values[b] = utils.samp.bilinear_sample_single(rgb_camB[b], x_pixB[b], y_pixB[b])
else: # 实现在图像特征上双线性插值采样
# native pytorch version
y_pixB, x_pixB = utils.basic.normalize_grid2d(y, x, H, W)
# since we want a 3d output, we need 5d tensors
z_pixB = torch.zeros_like(x)
xyz_pixB = torch.stack([x_pixB, y_pixB, z_pixB], axis=2)
rgb_camB = rgb_camB.unsqueeze(2)
xyz_pixB = torch.reshape(xyz_pixB, [B, Z, Y, X, 3])
values = F.grid_sample(rgb_camB, xyz_pixB, align_corners=False)
values = torch.reshape(values, (B, C, Z, Y, X)) # raw 4D的bev特征
values = values * valid_mem
return values
2.3 影响性能的一些方面
2.3.1 数据增广
对于数据增广操作,文章对图片颜色、对比度、模糊这些增广操作进行实验,发现其并不像分类任务中那么有效,甚至会带来负面影响。
2.3.2 输入图像分辨率
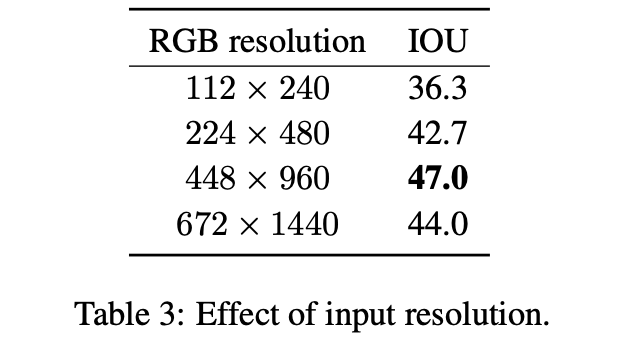
对于分辨率并不是呈现单调线型变化关系,文章给出的解释是ResNet-101是在COCO上做过object detection预训练的,其适应了该数据集下的目标尺寸,因而对bev任务在分辨率上存在一定的先验性。
2.3.3 batchsize
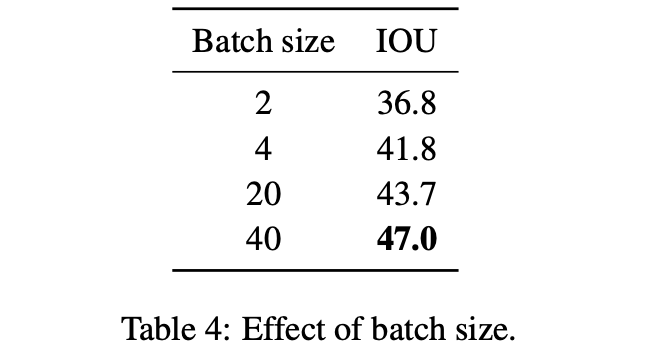
从上表中看出batchsize和性能之间存在着单调正向关联,这篇文章的代码中也通过了梯度累加的形式增大batch。
# train_nuscenes.py#L405
for internal_step in range(grad_acc):
...
2.3.4 reference camera和camera nums对性能的影响

从上表证实reference camera变换会带来涨点,使用全量camera也能带来涨点。
2.3.5 radar超参数带来的影响

3. 实验结果
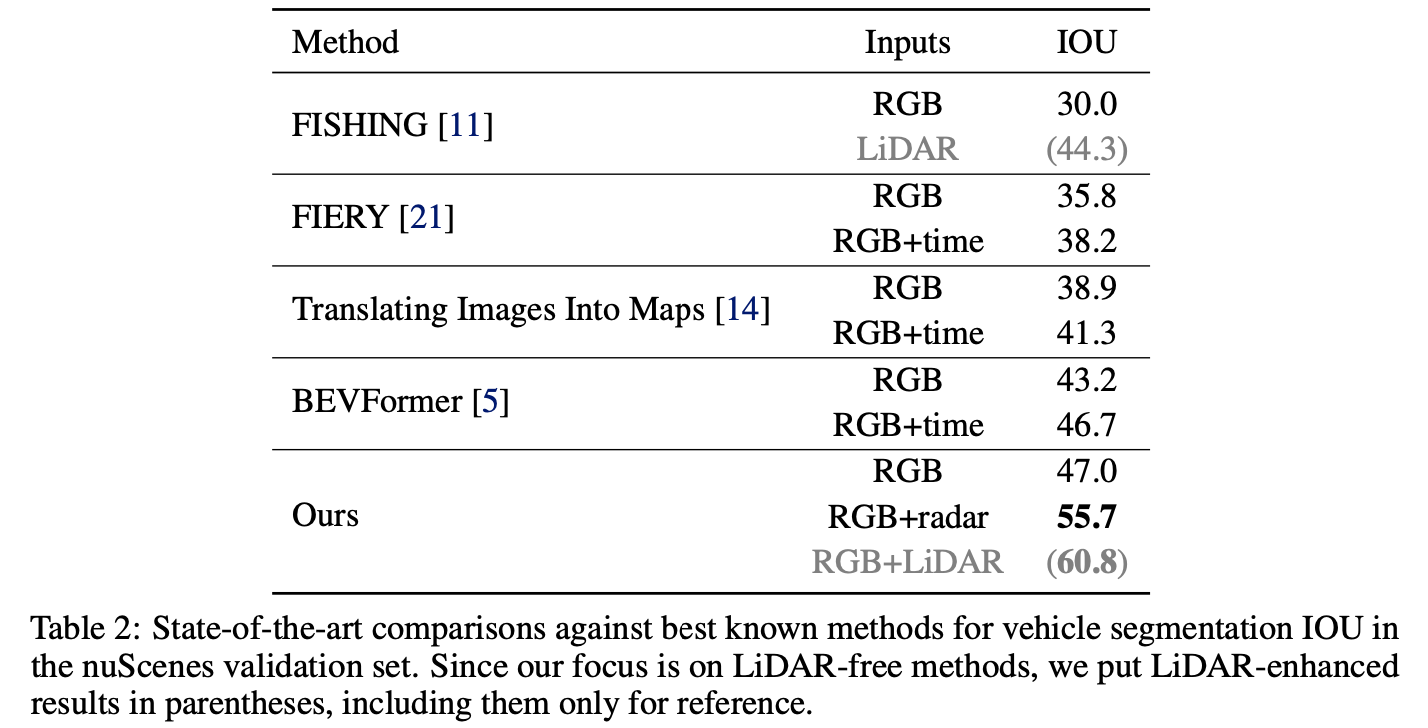
vehicle segmentation on nuScenes:

时序与传感器数据类型对性能的影响:
相关文章
- 论文笔记多任务学习
- 《Translating Images into Maps》论文笔记
- 《Boosting Monocular Depth Estimation Models to High-Resolution ...》论文笔记
- 《AutoFlow:Learning a Better Training Set for Optical Flow》论文笔记
- 《PWC-Net:CNNs for Optical Flow Using Pyramid,Warping,and Cost Volume》论文笔记
- 《U^2-Net:Going Deeper with Nested U-Structure for Salient Object Detection》论文笔记
- 《R3Det:Refined Single-Stage Detector with Feature Refinement for Rotating Object》论文笔记
- 《EfficientNetV2:Smaller Models and Faster Training》论文笔记
- 《Non-local Neural Networks》论文笔记
- 《Look More Than Once(LOMO):An Accurate Detector for Text of Arbitrary Shapes》论文笔记
- 《IoU-Net: Acquisition of Localization Confidence for Accurate Object Detection》论文笔记
- 《Context Encoding for Semantic Segmentation》论文笔记
- 《DANet:Dual Attention Network for Scene Segmentation》论文笔记
- 《RVOS:End-to-End Recurrent Network for Video Object Segmentation》论文笔记
- 《ICNet for Real-Time Semantic Segmentation on High-Resolution Images》论文笔记
- 《RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation》论文笔记
- 《Dynamic Network Surgery for Efficient DNNs》论文笔记