
《Relation Networks for Object Detection》论文笔记
代码地址:Relation-Networks-for-Object-Detection
1. 概述
一直以来都认为对检测目标之间的联系进行建模会帮助提升目标检测的性能,但是却没有实质性的证据表明这个猜想在现有的深度学习领域是可行的。现有的一些state-of-art的目标检测算法依赖于独立地识别目标,并没有在学习过程中考量他们之间的关系。
这篇文章受语言模型中attention的启发,提出了一个目标关联模块(object relation module),它通过目标的图像特征(appearance feature)与几何位置(geometry)生成连续的目标集合,这就能够对目标之间的关系进行建模。其实,这篇文章主要的思想是使用attention机制关联目标,并将attention机制引入到NMS中去提升检测器的性能。也就是对应文章中提到的instance recognition与NMS部分,文章这些改动嵌入到网络,且能够完成端到端训练。
Attention机制在语言模型与Image Caption中早已经有了广泛使用,但是在目标检测领域就很少使用了,这主要是对应的操作元素是不一样的。在检测中目标具有空间二维分布、不同的scale与ratio,并且它们的位置等几何特征相比语言模型中词的位置更复杂也更重要。
在这篇文章中为了适应目标检测任务,将原始的attention权重划分为两个部分:原始权重(original weight)与几何权重(geometry weight),后面一个权重用于建模检测目标之间的几何关系,由于只考虑了它们的几何关系使得该模块具有平移不变性。后面实验中也证明几何权重的重要性。
这篇文章提出的object relation module具有与传统上attention方法一样的性质,输入输出的维度是一致的,这就当做一个独立模块任意嵌入到网络中。在图1中展示了这个模块嵌入到类Faster R-CNN的目标检测算法中,在Instance Recognition与NMS步骤中发挥作用。

除了目标检测任务之外,这篇文章指出其还可以扩展到实例分割、工作识别等任务中去,扩展性比较强。
2. Object Relation Module
在attention机制中使用如下的关系对输入数据进行变换:
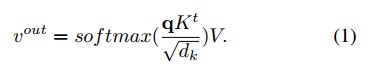
在这篇文章中使用
f
G
f_G
fG代表几何特征(geometry feature),也就是4维的目标框。
f
A
f_A
fA代表图像特征(appearance feature),这个需要根据任务而定,可以理解为对应的特征。给定一个包含
N
N
N个目标的集合
{
(
f
A
n
,
f
G
n
)
}
n
=
1
N
\{(f_A^n,f_G^n)\}_{n=1}^N
{(fAn,fGn)}n=1N,则
n
t
h
n^{th}
nth的目标对应整个目标集合的关联特征(relation feature)为
f
R
(
n
)
f_R(n)
fR(n),其表示为:
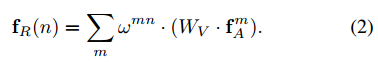
上面这个公式的输出是来自其它目标的图像特征的加权和,
W
V
W_V
WV是线性变换,对应公式1中的
V
V
V,
w
m
n
w^{mn}
wmn是其它目标对其的影响程度,对应公式1中的softmax,其是通过下面这个公式计算出来的:
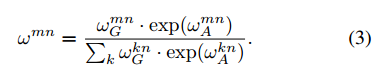
也就是归一化权值,其中
w
A
m
n
w_A^{mn}
wAmn是通过dot product操作得到的,与公式1类似:
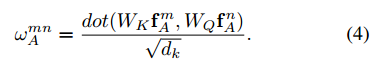
其中,
W
K
,
W
Q
W_K,W_Q
WK,WQ是矩阵与公式1中
K
,
Q
K,Q
K,Q类似。它们将图像特征
f
A
m
,
f
A
n
f_A^m,f_A^n
fAm,fAn映射到一个子空间去描述它们的相似度,映射之后的维度是
d
k
=
64
d_k=64
dk=64。
几何特征的权值是通过下面的公式计算得到的:
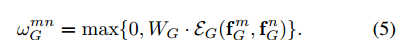
这个计算过程分为两步:
- 1)两个目标的几何特征被嵌入到高维表达中,描述为 E G \mathcal{E}_G EG,这是通过使用cos与sin函数会用不同的波长计算得到的,高纬度表达的维度为 d g = 64 d_g=64 dg=64。为了使得表达具有平移与尺度不变性,对每个维度的几何特征做了如下变换: ( l o g ( ∣ x m − x n ∣ w m ) , l o g ( ∣ y m − y n ∣ h m ) ) , l o g ( w n w m ) , l o g ( h n h m ) (log(\frac{|x_m-x_n|}{w_m}),log(\frac{|y_m-y_n|}{h_m})),log(\frac{w_n}{w_m}),log(\frac{h_n}{h_m}) (log(wm∣xm−xn∣),log(hm∣ym−yn∣)),log(wmwn),log(hmhn)。
- 2)完成嵌入的特征使用矩阵 W G W_G WG进行转换,作用于ReLU类似。
最后,将object relation module的特征整合到
N
r
N_r
Nr个(文章默认为16),这些整合的特征通过concat操作连接起来,再与
f
A
n
f_A^n
fAn相加,得到attention之后的特征。为了使特征维度匹配这里将
W
V
r
W_V^r
WVr的输出channel设置为输入特征
f
A
m
f_A^m
fAm的
1
N
r
\frac{1}{N_r}
Nr1。文章里面这样做的目的是为了减少计算量。
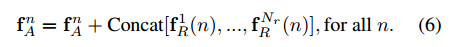
其整个过程归纳为算法1所示:

而且这样的步骤可以很容易通过一些基础的网络模块实现,其结构见图2所示:

3. Relation Networks For Object Detection
在之前的内容中提到文章将attention运用于instance recognition与NMS操作中,接下来的内容就是围绕两点展开,说明它们是怎么在网络中工作起来的。
3.1 Relation for Instance Recognition
对于Faster RCNN系列的算法使用RoI Pooling操作产生
n
t
h
n^{th}
nth个目标提取,之后使用线性层去预测结果,其过程可以总结如下:
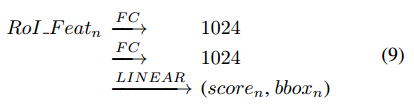
那么,这里使用这篇文章的object relation module接在fc层的后面,由于这个模块的输入输出维度是相同的,因而并不会改变特征维度,也可以堆叠任意多次,每个fc后面接一个object relation module的结构见下图所示:
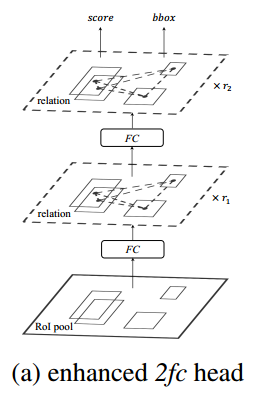
其处理过程如下:
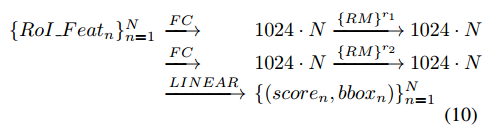
3.2 Relation for Duplicate Remova
这部分内容是对原有NMS操作的改进,在其中加入了attention机制。文章将去除重复检测框的问题转换为二分类问题,也就是一个GT只与一个检测结果对应,其余的全是负样本。完成这部分功能的结构见下图所示:

这个模块的输入有3个分别是分类置信度、1024维度的特征与预测框,输出是一个2分类,分别代表是否要去除对应的检测框。最后的分类置信度是
s
0
,
s
1
s_0,s_1
s0,s1的乘积。这个模块的计算过程可以分为3个步骤:
- 1)分类置信度经过排序之后通过 w f g w_{fg} wfg映射到128维度,1024维度的特征经过 w f w_f wf也被映射到128维度,之后两个特征融合;
- 2)预测结果与融合之后的特征进行attention操作;
- 3)attention之后的结果使用线性变换 w s w_s ws与sigmoid完成二分类;
4. 实验结果
性能表现:

网络中模块对性能的影响:

instance中各变量对性能的影响:

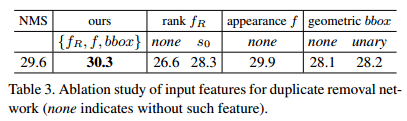
NMS中各变量对性能的影响:
NMS中阈值对性能的影响:

相关文章
- Bag of Tricks for Image Classification with Convolutional Neural Networks论文笔记
- 论文笔记(6):Weakly-and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation
- 论文笔记(1):From Image-level to Pixel-level Labeling with Convolutional Networks
- 论文笔记(3):STC: A Simple to Complex Framework for Weakly-supervised Semantic Segmentation
- 论文笔记(6):Weakly-and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation
- 论文笔记(2):Deep Crisp Boundaries: From Boundaries to Higher-level Tasks
- 谷歌Borg论文阅读笔记(一)——分布式架构
- 论文分享丨Holistic Evaluation of Language Models
- 毕业设计 Spring Boot的在线课堂学习系统(含源码+论文)
- 论文解读(Moco v3)《An Empirical Study of Training Self-Supervised Vision Transformers》
- 论文解读(DAGNN)《Towards Deeper Graph Neural Networks》
- 论文笔记系列:轻量级网络(一)-- RepVGG
- 论文笔记系列:经典主干网络(二)-- DenseNet
- 《论文阅读》开放域对话系统——外部信息融入对话的方法
- 《论文阅读》Emotional Chatting Machine: Emotional Conversation Generation with Internal and External Memor
- GAN全套学习笔记/论文
- 论文理解与笔记【CVPR_2022.6】Region-Aware Face Swapping
- 论文笔记:A Low-Complexity I/Q Imbalance compensation Algorithm
- 论文笔记:基于特征选择与增量学习的非侵入式电动自行车充电辨识方法
- 论文笔记:基于复合滑动窗的CUSUM暂态事件检测算法
- NILM论文笔记:R.Reddy, et al: A feature fusion technique for improved NILM
- SCI论文解读复现【NO.1】基于Transformer-YOLOv5的侧扫声纳图像水下海洋目标实时检测