
PDF头部报错:Evaluation Warning : The document was created with Spire.PDF for Java.
2023-09-11 14:22:31 时间
问题描述
今天生成PDF缝骑章的时候遇到一个问题,那就是每一个文件第一页都会有这个错
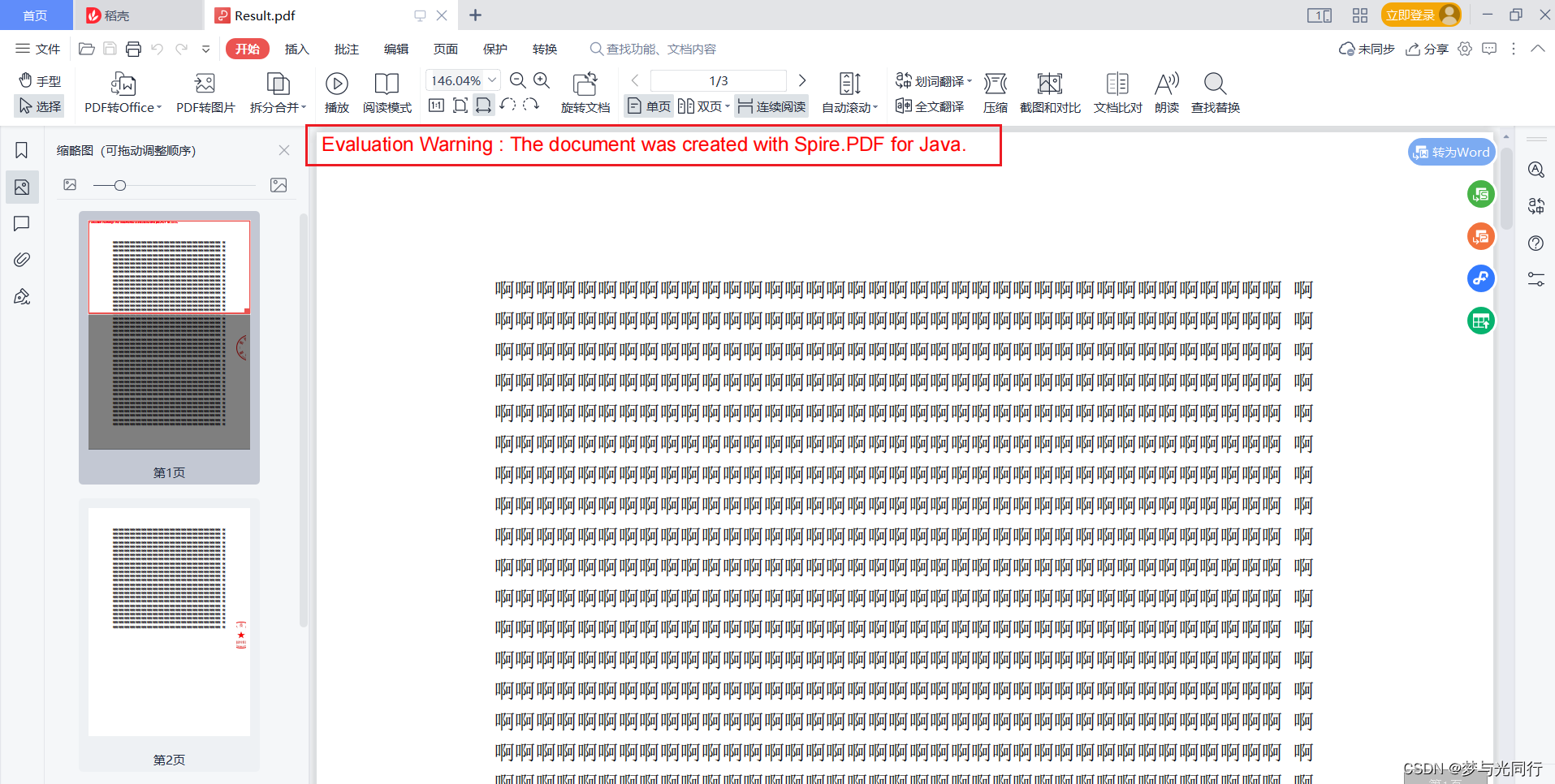
会在页面的第一页加上Evaluation Warning : The document was created with Spire.PDF for Java.一段文字
该备注只会标记再报表的第一页的顶部。我们可以新增一页,并删掉第一页即可
解决思路1
使用aspose的License去验证
需要引用aspose包,引入操作我写了一个博客,地址如下
https://blog.csdn.net/weixin_46713508/article/details/125495770?spm=1001.2014.3001.5502
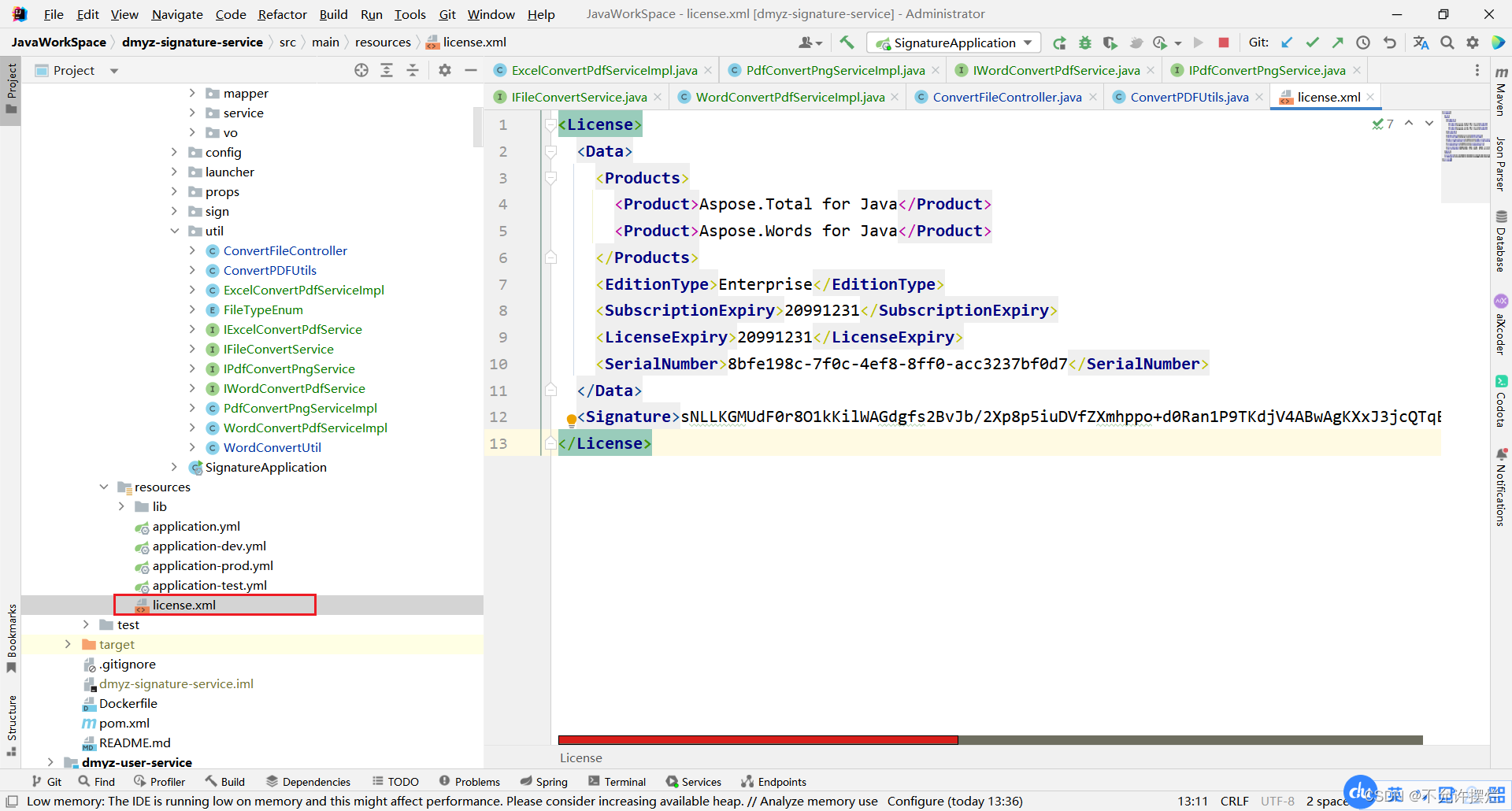
本地创建一个License.xml
<License>
<Data>
<Products>
<Product>Aspose.Total for Java</Product>
<Product>Aspose.Words for Java</Product>
</Products>
<EditionType>Enterprise</EditionType>
<SubscriptionExpiry>20991231</SubscriptionExpiry>
<LicenseExpiry>20991231</LicenseExpiry>
<SerialNumber>8bfe198c-7f0c-4ef8-8ff0-acc3237bf0d7</SerialNumber>
</Data>
<Signature>sNLLKGMUdF0r8O1kKilWAGdgfs2BvJb/2Xp8p5iuDVfZXmhppo+d0Ran1P9TKdjV4ABwAgKXxJ3jcQTqE/2IRfqwnPf8itN8aFZlV3TJPYeD3yWE7IT55Gz6EijUpC7aKeoohTb4w2fpox58wWoF3SNp6sK6jDfiAUGEHYJ9pjU=</Signature>
</License>
然后编写方法
public static boolean getLicense() {
boolean result = false;
try {
InputStream is = ConvertPDFUtils.class.getClassLoader().getResourceAsStream("\\license.xml");
License aposeLic = new License();
aposeLic.setLicense(is);
result = true;
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
在转换的方法里面加入这个方法,值得注意点是aopse里面有针对不同文件有不同的license,别引入错了
这是word的license
import com.aspose.words.License;
这是excel的license
import com.aspose.cells.License;
这是pdf的license
import com.aspose.pdf.License
比如下面这个word转pdf的例子
public boolean wordConvertPdf(MultipartFile file, String outPath) throws Exception {
// 验证License
if (!getLicense()) {
return false;
}
try {
// 原始word路径
Document doc = new Document(file.getInputStream());
// 输出路径
File pdfFile = new File(outPath);
// 文件输出流
FileOutputStream fileOS = new FileOutputStream(pdfFile);
doc.save(fileOS, SaveFormat.PDF);
fileOS.close();
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
解决思路2
通过网上找例子找到了解决办法,因为这段文字只出现在第一页,所以这里的处理方式是在文档创建时先添加一个空白页,最后再把空白页去掉
代码实现
核心代码
//添加一个空白页,目的为了删除jar包添加的水印,后面再移除这一页
pdf.getPages().add();
//创建字体
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("宋体", Font.PLAIN, 10),true);
//遍历文档中的页
for (int i = 0; i < pdf.getPages().getCount(); i++) {
Dimension2D pageSize = pdf.getPages().get(i).getSize();
float y = (float) pageSize.getHeight() - 40;
//初始化页码域
PdfPageNumberField number = new PdfPageNumberField();
//初始化总页数域
PdfPageCountField count = new PdfPageCountField();
//创建复合域
PdfCompositeField compositeField = new PdfCompositeField(font, PdfBrushes.getBlack(), "第{0}页 共{1}页", number, count);
//设置复合域内文字对齐方式
compositeField.setStringFormat(new PdfStringFormat(PdfTextAlignment.Right, PdfVerticalAlignment.Top));
//测量文字大小
Dimension2D textSize = font.measureString(compositeField.getText());
//设置复合域的在PDF页面上的位置及大小
compositeField.setBounds(new Rectangle2D.Float(((float) pageSize.getWidth() - (float) textSize.getWidth())/2, y, (float) textSize.getWidth(), (float) textSize.getHeight()));
//将复合域添加到PDF页面
compositeField.draw(pdf.getPages().get(i).getCanvas());
}
//移除第一个页
pdf.getPages().remove(pdf.getPages().get(pdf.getPages().getCount()-1));
完整代码
package dmyz.util;
import com.spire.pdf.*;
import com.spire.pdf.automaticfields.PdfCompositeField;
import com.spire.pdf.automaticfields.PdfPageCountField;
import com.spire.pdf.automaticfields.PdfPageNumberField;
import com.spire.pdf.graphics.*;
import javax.imageio.ImageIO;
import java.awt.*;
import java.awt.geom.Dimension2D;
import java.awt.geom.Point2D;
import java.awt.geom.Rectangle2D;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
/**
* @Author 魏一鹤
* @Description 骑缝章生成
* @Date 17:03 2022/6/27
**/
public class AcrossPageSeal {
public static void main(String[] args) throws IOException {
//要生成的文件模板
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("D:\\File\\test\\wyh\\3页.pdf");
//添加一个空白页,目的为了删除jar包添加的水印,后面再移除这一页
pdf.getPages().add();
//创建字体
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("宋体", Font.PLAIN, 10),true);
//遍历文档中的页
for (int i = 0; i < pdf.getPages().getCount(); i++) {
Dimension2D pageSize = pdf.getPages().get(i).getSize();
float y = (float) pageSize.getHeight() - 40;
//初始化页码域
PdfPageNumberField number = new PdfPageNumberField();
//初始化总页数域
PdfPageCountField count = new PdfPageCountField();
//创建复合域
PdfCompositeField compositeField = new PdfCompositeField(font, PdfBrushes.getBlack(), "第{0}页 共{1}页", number, count);
//设置复合域内文字对齐方式
compositeField.setStringFormat(new PdfStringFormat(PdfTextAlignment.Right, PdfVerticalAlignment.Top));
//测量文字大小
Dimension2D textSize = font.measureString(compositeField.getText());
//设置复合域的在PDF页面上的位置及大小
compositeField.setBounds(new Rectangle2D.Float(((float) pageSize.getWidth() - (float) textSize.getWidth())/2, y, (float) textSize.getWidth(), (float) textSize.getHeight()));
//将复合域添加到PDF页面
compositeField.draw(pdf.getPages().get(i).getCanvas());
}
//移除第一个页
pdf.getPages().remove(pdf.getPages().get(pdf.getPages().getCount()-1));
//获取分割后的印章图片
BufferedImage[] images = GetImage(pdf.getPages().getCount());
float x = 0;
float y = 0;
//实例化PdfUnitConvertor类
PdfUnitConvertor convert = new PdfUnitConvertor();
PdfPageBase pageBase;
//将图片绘制到PDF页面上的指定位置
for (int i = 0; i < pdf.getPages().getCount(); i++)
{
BufferedImage image= images[ i ];
pageBase = pdf.getPages().get(i);
x = (float)pageBase.getSize().getWidth() - convert.convertUnits(image.getWidth(), PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel) + 40;
y = (float) pageBase.getSize().getHeight()/ 2;
pageBase.getCanvas().drawImage(PdfImage.fromImage(image), new Point2D.Float(x, y));
}
System.out.println("x = " + x);
System.out.println("y = " + y);
//最终生成缝骑章 的结果
pdf.saveToFile("D:\\File\\test\\wyh\\Result.pdf");
}
//定义GetImage方法,根据PDF页数分割印章图片
static BufferedImage[] GetImage(int num) throws IOException {
String originalImg = "D:\\File\\test\\wyh\\魏一鹤的测试印章.png";
BufferedImage image = ImageIO.read(new File(originalImg));
int rows = 1;
int cols = num;
int chunks = rows * cols;
int chunkWidth = image.getWidth() / cols;
int chunkHeight = image.getHeight() / rows;
int count = 0;
BufferedImage[] imgs = new BufferedImage[ chunks ];
for (int x = 0; x < rows; x++) {
for (int y = 0; y < cols; y++) {
imgs[ count ] = new BufferedImage(chunkWidth, chunkHeight, image.getType());
Graphics2D gr = imgs[ count++ ].createGraphics();
gr.drawImage(image, 0, 0, chunkWidth, chunkHeight,
chunkWidth * y, chunkHeight * x,
chunkWidth * y + chunkWidth, chunkHeight * x + chunkHeight, Color.WHITE,null);
gr.dispose();
}
}
return imgs;
}
}
处理前
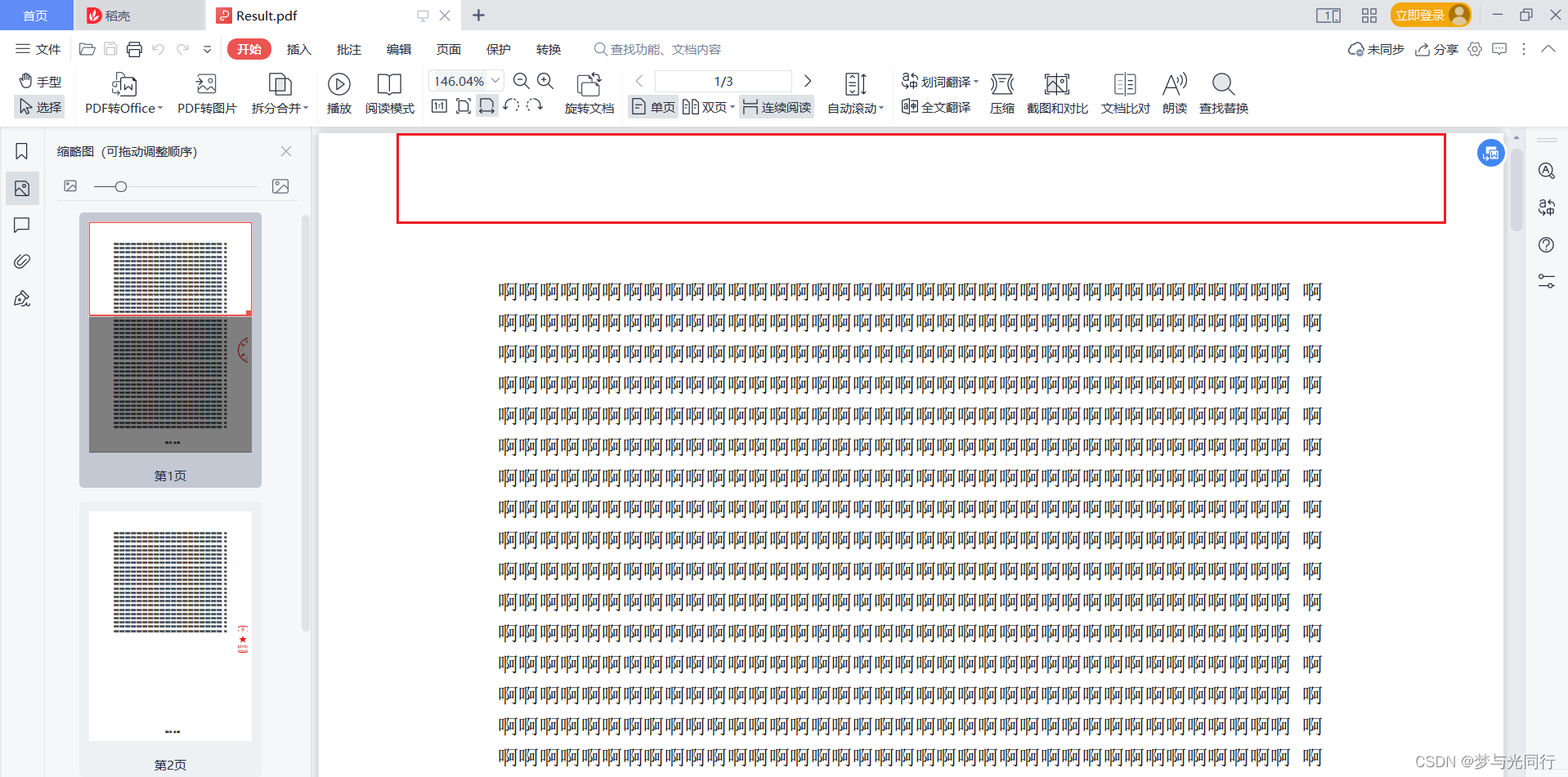
处理后
错误已经消息
相关文章
- Java入门系列之字符串特性
- Java基础——Statement与PrepareStatement
- 在软件测试领域,Java和Python哪个更适合做自动化测试?
- java安装1.8和1.7,报错:Error: Registry key 'SoftwareJavaSoftJava Runtime Environment'CurrentVers
- Linux离线安装java
- Word处理控件Aspose.Words功能演示:使用 Java 将 RTF 转换为 PDF
- 【java细节】Java代码忽略https证书:No subject alternative names present
- Java并发JUC(java.util.concurrent)JMM内存模型
- GitHub上标星75k+超牛的《Java面试突击版》,分享PDF离线版
- Java高并发与多线程理解
- 【Java】怎么回答java垃圾回收机制
- 系统学习JAVA第一天(计算机组成,软件,JDK,JAVA语言特点)
- 第39节:Java当中的IO
- 【HarmonyOS】【JAVA UI】鸿蒙 自定义折线图
- Java 通过JDBC查询数据库表结构(字段名称,类型,长度等)
- java自定义注解学习
- java.lang.OutOfMemoryError: Java heap space
- java读取txt/pdf/xls/xlsx/doc/docx/ppt/pptx
- java.lang.OutOfMemoryError: Java heap space解决方法
- linux java中使用POI将word转为PDF时无法显示文字
- 你应当知道的7个Java工具
- Java_java动态编译整个项目,解决jar包找不到问题
- Java_解决java.security.cert.CertificateException: Certificates does not conform to algorithm constraints
- 浅析Java对集合进行操作时报java.util.ConcurrentModificationException并发修改异常问题:产生原因、单线程/多线程环境解决、CopyOnWriteArrayList线程安全的ArrayList、fail-fast快速失败机制防止多线程修改集合造成并发问题
- Java学习---Java面试基础考核·
- JAVA学习(三):Java基础语法(变量、常量、数据类型、运算符与数据类型转换)
- 实操代码研究各种Java技术-java.toutiao.im
- How to improve Java's I/O performance( 提升 java i/o 性能)
- 什么是Java序列化,如何实现java序列化
- 关于java的参数传递(值传递、引用传递和传值、传引用等)
- Java面向对象三大特征之封装
- 多种方式解决Java控制台报错 java.util.LinkedHashMap cannot be cast to.....