
【深度学习】——模型评估指标MAP计算&实例计算
目录
7)分别对每一个类别进行ap曲线的绘制,这里以一类为例讲解,以类别1为例
问题2:怎么求解不同置信度阈值下的precision,recall值
一、知识储备:
睿智的目标检测20——利用mAP计算目标检测精确度 https://blog.csdn.net/weixin_44791964/article/details/104695264?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162156782416780262569069%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=162156782416780262569069&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~baidu_landing_v2~default-1-104695264.pc_search_result_hbase_insert&utm_term=map%E8%AE%A1%E7%AE%97&spm=1018.2226.3001.4187
https://blog.csdn.net/weixin_44791964/article/details/104695264?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162156782416780262569069%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=162156782416780262569069&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~baidu_landing_v2~default-1-104695264.pc_search_result_hbase_insert&utm_term=map%E8%AE%A1%E7%AE%97&spm=1018.2226.3001.4187
IOU、FP、TP、TP、FN、Precision、recall
1、IOU——交集面积与并集面积之比
IOU(交并比)就是两个bounding box的交集与并集之比
理解目标检测当中的mAP_hsqyc的博客-CSDN博客_目标检测map![]() https://blog.csdn.net/hsqyc/article/details/81702437
https://blog.csdn.net/hsqyc/article/details/81702437


def box_iou(b1, b2):
'''b1,b2均为[x1,y1,x2,y2],左上角点,右下角点坐标'''
x1_1, y1_1, x2_1, y2_1 = b1
x1_2, y1_2, x2_2, y2_2 = b2
x1 = max(x1_1, x1_2) # 取左上角点最大
y1 = max(y1_1, y1_2)
x2 = min(x2_1, x2_2)
y2 = min(y2_1, y2_2)
if x2 - x1 + 1 <= 0 or y2 - y1 + 1 <= 0:
return 0
else:
inter = (x2 - x1 + 1) * (y2 - y1 + 1)
union = (x2_1 - x1_1 + 1) * (y2_1 - y1_1 + 1) + (x2_2 - x1_2 + 1) * (y2_2 - y1_2 + 1) - inter
iou = inter / union
return iou
if __name__ == '__main__':
b1 = [0,0,4,4]
b2 = [1,1,5,5]
print(box_iou(b1,b2))
b1 = [1,1,4,4]
b2 = [2,0,5,5]
print(box_iou(b1, b2))
b1 = [0,0,2,2]
b2 = [3,3,4,4]
print(box_iou(b1,b2))
0.47058823529411764
0.42857142857142855
0
2、混淆矩阵(TP、FP、FN、TN)
TP TN FP FN里面一共出现了4个字母,分别是T F P N。
T是True;
F是False;
P是Positive;
N是Negative。T或者F代表的是该样本 是否被正确分类。
P或者N代表的是该样本 被预测成了正样本还是负样本。TP(True Positives)意思就是被分为了正样本,而且分对了。
TN(True Negatives)意思就是被分为了负样本,而且分对了。
FP(False Positives)意思是被分为了正样本,但是分错了(事实上这个样本是负样本)。
FN(False Negatives)意思是被分为了负样本,但是分错(事实上这个样本是正样本)。
注意:对于多目标检测中,每一个类别都会有一个混淆矩阵。因此每一个类别都会产生一个ap曲线

问题1:上面的TP等具体是如何计算得到的?
在目标检测中,混淆矩阵是针对一个类别来说的,利用训练模型对测试集进行预测,此时会得到预测框和标签框。每个预测框会有置信度、预测标签、boxes(坐标)等信息;
1、若这个预测框被预测为正样本计算这个预测框和真实标签等于这个预测框的预测标签的所有标签框的IOU值:
1)当最大的iou值大于设定的阈值时,此时这个预测框就认为属于TP样本(预测和实际一致);
2)若iou最大值小于设定的阈值,则认为这个预测框为FP样本(预测为该类的正样本,实际不是);
2、若这个预测框被预测为负样本,即背景框,计算这个预测框和所有标签框的IOU值:
3)若iou值最大值小于阈值,则说明被正确预测为负样本,即TN
4)若iou值最大值大于阈值,则说明被错误预测为负样本,即FN
注意:在计算每一类ap的时候,一般只考虑预测为当前类的所有样本,不考虑预测为背景的样本
3、精度precision&召回率recall
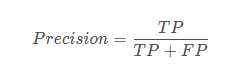
TP是分类器认为是正样本而且确实是正样本的例子,FP是分类器认为是正样本但实际上不是正样本的例子,Precision翻译成中文就是“分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例”。
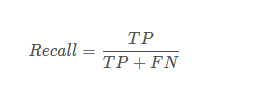
TP是分类器认为是正样本而且确实是正样本的例子,FN是分类器认为是负样本但实际上不是负样本的例子,Recall翻译成中文就是“分类器认为是正类并且确实是正类的部分占所有确实是正类的比例”。
二、ap计算实战
1、计算流程
准备数据:
- 测试集数据集(带标签框)、训练好的深度学习模型、nms算法(iou阈值)(两个重叠框iou大于阈值将低分的预测框去掉)
获取预测框:
- 将测试数据集输入到训练好的深度学习模型当中,得到每张图像的预测框,再利用nms算法去掉重复和重叠大的框后,记录剩下预测框的信息(坐标信息——对角顶点坐标、类别、置信度)(boxes,label,confidence)——未排序
获取标签框:
- 根据测试数据集的xml文件得到真实标签框的信息(groudtruth),包含每张图像的标签框信息(boxes,label),如下表所示:这里以两类为例,标签1,2表示不同的两个目标类,0表示背景
序号(id) 对角顶点坐标(boxes) 真实类别(label) 1 【x1_1*,y1_1*,x1_2*,y1_2*】 1 2 【x2_1*,y2_1*,x2_2*,y2_2*】 1 3 【x3_1*,y3_1*,x3_2*,y3_2*】 2 4 【x4_1*,y4_1*,x4_2*,y4_2*】 2
根据置信度对预测框排序:
- 对每张图像的预测框每一个类别按照置信度(分类得分)从高到低分别排序,得到类似与下列表格的信息
序号(id) 对角顶点坐标(boxes) 置信度(confidence) 预测类别(label) 1 【x1_1,y1_1,x1_2,y1_2】 0.98 2 2 【x2_1,y2_1,x2_2,y2_2】 0.90 1 3 【x3_1,y3_1,x3_2,y3_2】 0.88 1 4 【x4_1,y4_1,x4_2,y4_2】 0.86 2 5 【x5_1,y5_1,x5_2,y5_2】 0.67 1 6 【x6_1,y6_1,x6_2,y6_2】 0.51 2 预测为类别1:
序号(id) 对角顶点坐标(boxes) 置信度(confidence) 预测类别(label) 2 【x2_1,y2_1,x2_2,y2_2】 0.90 1 3 【x3_1,y3_1,x3_2,y3_2】 0.88 1 5 【x5_1,y5_1,x5_2,y5_2】 0.67 1 预测为类别2:
序号(id) 对角顶点坐标(boxes) 置信度(confidence) 预测类别(label) 1 【x1_1,y1_1,x1_2,y1_2】 0.98 2 4 【x4_1,y4_1,x4_2,y4_2】 0.86 2 6 【x6_1,y6_1,x6_2,y6_2】 0.51 2
统计TP和FP个数:
- 对每张图像中的每一类进行TP和FP个数统计,假设一个预测框预测为类别2,则计算这个预测框和该图像中所有类别为2的标签框的iou,若iou大于设定的阈值(一般默认阈值为0.5),则认为该预测框为TP,否则认为是FP,以下以一张图像中的类别为例:(gtid表示序号为id的标签框,preid表示序号为id的预测框),maxiou(preid,gtid(3,4))表示序号为id的预测框和所有类别为2的标签框的最大iou值,tp/fp表示预测框预测的正确与否,正确则为tp,否则为fp,为了方便,这里tp记为1,fp记为0
序号id max iou(preid,gtid(3,4)) 置信度 预测label tp/fp 1 0.65 0.98 2 1 4 0.68 0.86 2 1 6 0.45 0.51 2 0 序号id max iou(preid,gtid(1,2)) 置信度 预测label tp/fp 2 0.51 0.90 1 1 3 0.4 0.88 1 0 5 0.9 0.67 1 1 由上表可以看到,在类别2预测框当中,2个预测正确,1个预测错误,在类别1预测框当中,2个预测正确,1个预测错误。
- 对单张图像的每一类进行TP,FP统计,最后汇总到成一张表格,别处摘的图,这里是3类
参考:目标检测中的AP计算_lppfwl的博客-CSDN博客_目标检测ap计算
对整个测试集上的每一张图像的每一类进行TP,FP统计
- 最后汇总到成一张表格,表格和上面表格一样,只是数量上增加了而已,为了方便讲解这里以一张图像的为例进行讲解
分别对每一个类别进行ap曲线的绘制,这里以一类为例讲解,以类别1为例
计算不同置信度下的precision和recall
--------------------------------------------------------------------------------------------------------------------------
问题2:怎么求解不同置信度阈值下的precision,recall值
答:假设置信度阈值为thre,则当预测框的置信度大于等于thre时,将预测框视为正样本,小于阈值thre时,将预测框视为负样本。前面利用iou得到的tp/fp则作为当前预测框的真实标签,1表示实际为正样本,0表示实际为负样本。这样又有预测框的真实标签、预测标签、置信度、置信度阈值就可以求解出当前类的TP.FP.FN.TN,进而求解precision和recall
问题3:出现的两次预测有什么区别?
答:仔细看可以发现,在前面出现了两次预测框的标签预测,
1)第一次确定预测框的预测类别是否正确。根据预测框和当前预测类的所有标签框进行iou计算,然后判断是否预测成功,这里其实就是将预测为同一类的预测框分为两类,预测正确和不正确两类,正确为1,不正确为0,这个就作为这个预测框在预测类中的真实标签;
2)第二次是人为划分了置信度阈值,根据阈值来决定预测框的正负性,当预测框的置信度大于等于thre时,将预测框视为正样本,小于阈值thre时,将预测框视为负样本。这个作为当前置信度阈值下的预测标签。
根据预测标签和真实标签就能够计算在当前置信度阈值下的混淆矩阵,从而得到precision和recall
--------------------------------------------------------------------------------------------------------------------------
序号id 置信度conference 预测标签 tp/fp 5 0.66 1 1 10 0.55 1 0 2 0.45 1 1 8 0.34 1 0 1 0.23 1 0 将置信度从1到0依次取点会得到一系列的(precision,recall)的坐标点,初始坐标点为(0,1),结束点为(1,0),置信度的取点我们可以根据预测框的置信度进行取点,比如conferences = 【0.66,0.55,0.45,0.34,0.23】,当置信度阈值分别等于这些值时,precision和recall取值是不一样的
序号id 置信度conference 置信度阈值 tp/fp precision recall 5 0.66 0.66 1 1/(1+0) = 1 1/(1+1)=1/2 10 0.55 0.55 0 1/(1+1)=1/2 1/(1+1)=1/2 2 0.45 0.45 1 2/(2+1) = 2/3 2/(2+0) = 1 8 0.34 0.34 0 2/(2+2) = 1/2 2/(2+0) = 1 1 0.23 0.23 0 2/(2+3) = 2/5 2/(2+0) = 1 由上表可以看出,这样我们就得到了precision和recall的点对,注意,当一个recall对应多个precision时,取最大的precision即可,例如在recall=1时,对应precision=2/3、1/2、2/5、0,这时候我们取2/3即可
点对如下:(recall,precision)
【(0,1),(1/2,1),(1,2/3),(1,1/2),(1,2/5),(1,0)】最终根据这些点就可以绘制出ap曲线图
计算AP
AP(average precision)= 曲线面积
比如上图:
AP = 1/2 + (1/2+2/3)*1/2*1/2 = 19/24
计算map
map指的就是所有类的平均ap值,map = (ap1+ap2+...+apn)/n,其中n为标签类别号
三、学习笔记

相关文章
- Marching squares & Marching cubes
- Android 自己主动化測试(3)<monkeyrunner> 依据ID查找对象&touch&type (python)
- Oracle 远程访问配置 在 Windows Forms 和 WPF 应用中使用 FontAwesome 图标 C#反序列化XML异常:在 XML文档(0, 0)中有一个错误“缺少根元素” C#[Win32&WinCE&WM]应用程序只能运行一个实例:MutexHelper Decimal类型截取保留N位小数向上取, Decimal类型截取保留N位小数并且不进行四舍五入操作
- 从头认识Spring-1.16 SpEl对集合的操作(1)-建立集合以及訪问集合的元素,以<util:list/>为例
- 跨域问题解决方式(HttpClient安全跨域 & jsonp跨域)
- <IDEA 使用小技巧&&常用键联合操作>
- vite&vue3中使用批量导入 import.meta.glob import.meta.globEager
- 《C++ AMP:用Visual C++加速大规模并行计算》——1.3 C++ AMP方法
- SwiftUI 将代办事件添加到日历和提醒(remander & Calendar)教程含源码
- 前端JS的服务订阅&服务发布
- 高通与AT&T将测试4G网络无人机,将它飞得更远
- hdoj-1164-Eddy's research I【分解质因数】
- Ubuntu14 中安装 VMware10 Tools工具<2>
- JavaScript 格式化字符串 & 需要转义的正则表达式