
apache开源项目--hadoop
2023-09-11 14:21:33 时间
Hadoop 是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有着高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以流的形式访问(streaming access)文件系统中的数据。
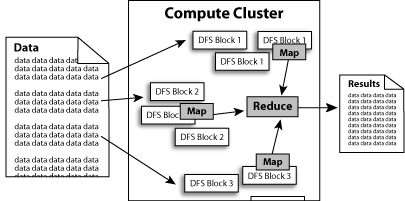
下图是Hadoop的体系结构:
相关文章
- hbase shell中执行list命令报错:ERROR: org.apache.hadoop.hbase.PleaseHoldException: Master is initializing
- Exception in thread "main" java.io.IOException: Mkdirs failed to create /var/folders/q0/1wg8sw1x0dg08cmm5m59sy8r0000gn/T/hadoop-unjar6090005653875084137/META-INF/license at org.apache.hadoop.util.Run
- java.lang.ClassNotFoundException: org.apache.commons.lang.exception.NestableRuntimeException
- Hadoop操作HDFSAPI 错误org.apache.hadoop.ipc.RemoteException(java.io.IOException)
- 在 Apache、NGINX 和 Lighttpd 上启用 HTTP 公钥固定扩展(HPKP)
- Practice: Process logs with Apache Hadoop
- Pig Apache Hadoop
- Apache HttpComponents POST提交带参数提交
- 【Hadoop】新建hadoop用户以及用户组,给予sudo权限(转)
- 《PHP、MySQL和Apache入门经典(第5版)》一一2.6 安装故障排除
- 《PHP、MySQL和Apache入门经典(第5版)》一2.11 实践练习
- Flink Table Store 独立孵化启动 , Apache Paimon 诞生
- 《Spark与Hadoop大数据分析》一一第2章 Apache Hadoop和Apache Spark入门
- Hadoop学习---Ubuntu中hadoop完全分布式安装教程
- Hadoop Serialization -- hadoop序列化具体解释 (2)【Text,BytesWritable,NullWritable】
- Apache 配置两个域名匹配的文件夹和配置多个Web站点
- Apache Hadoop YARN – NodeManager--转载
- Apache Shiro Architecture--官方文档
- apache kafka技术分享系列(目录索引)--转载
- 在 Web 项目中应用 Apache Shiro
- Class org.apache.hadoop.mapred.ShuffleHandler not found
- java.lang.NoClassDefFoundError: org/apache/flink/api/common/functions/FlatMapFunction