
k8s部署kube-prometheus
前言
环境:centos7.9、k8s-v1.22.6、kube-prometheus-release-0.10.zip
说明
我们采用prometheus-operator的方式在k8s集群上安装prometheus监控软件,这个项目的软件在GitHub上面;
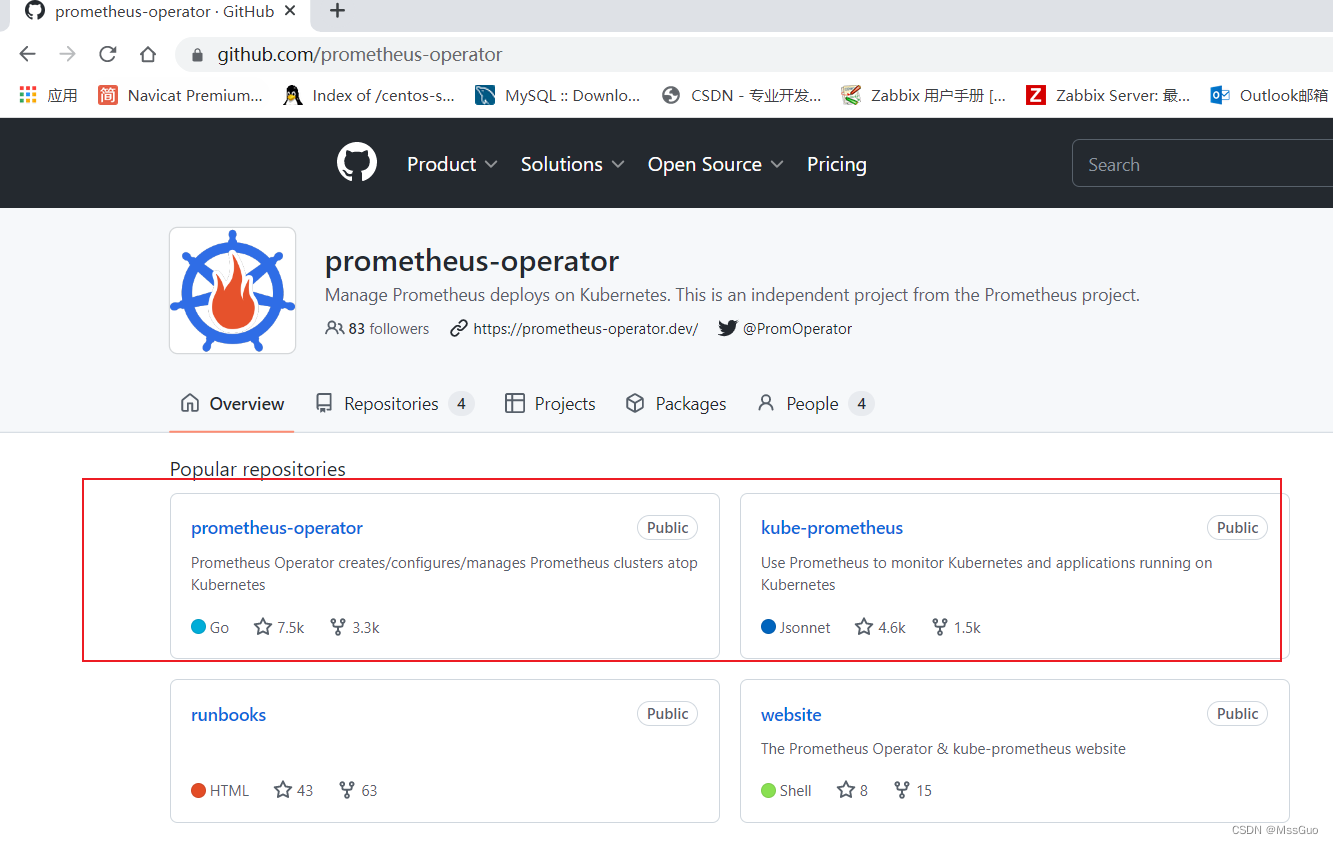
github 上 coreos 下有两个项目:kube-prometheus 和 prometheus-operator,两者都可以实现 prometheus 的创建及管理。
需要注意的是,kube-prometheus 上的配置操作也是基于 prometheus-operator 的,并提供了大量的默认配置,故这里使用的是 kube-prometheus 项目的配置。
另外使用前需注意 k8s 版本要求,找到对应的 kube-prometheus 版本。
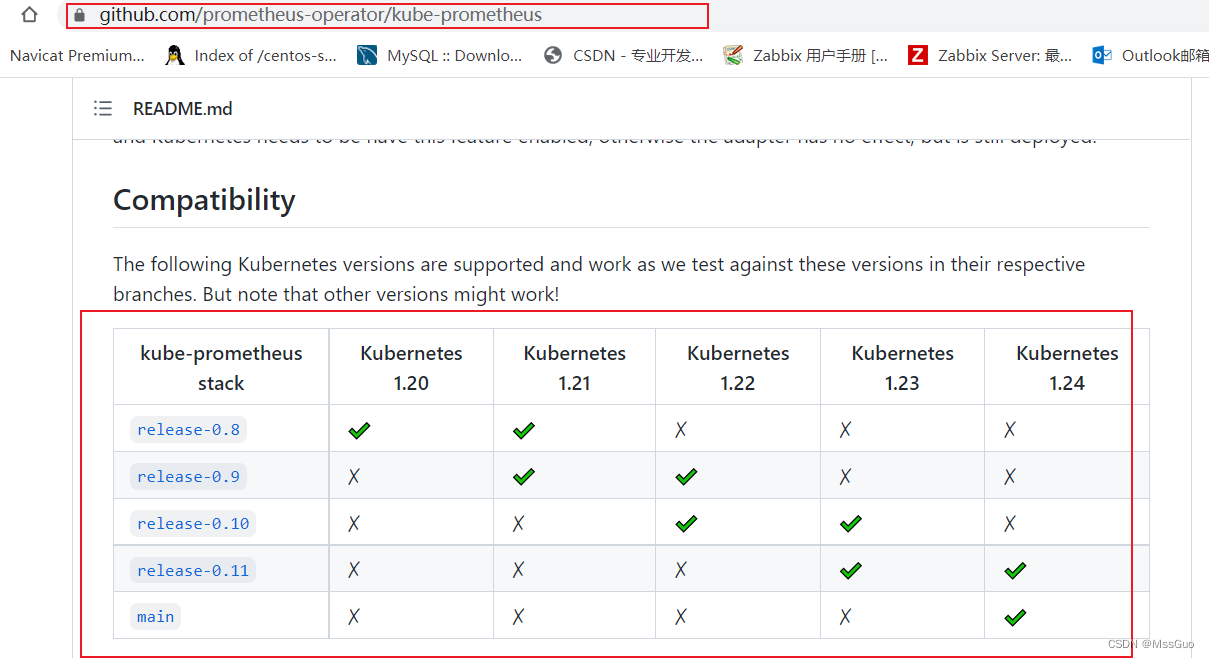
下载 kube-prometheus 安装包
去https://github.com/prometheus-operator/kube-prometheus/tree/release-0.10下载 kube-prometheus-release-0.10.zip压缩包,上传到服务器。
mkdir /root/kube-prometheus
cd /root/kube-prometheus
unzip kube-prometheus-release-0.10.zip
cd /root/kube-prometheus/kube-prometheus-release-0.10
#查看这些yaml文件都是需要哪些镜像
[root@master kube-prometheus-release-0.10]# find ./manifests -type f | xargs grep 'image: '|sort|uniq |awk '{print $3}'|grep ^[a-zA-Z]grep -Evw
quay.io/prometheus/alertmanager:v0.23.0
jimmidyson/configmap-reload:v0.5.0
quay.io/brancz/kube-rbac-proxy:v0.11.0
quay.io/prometheus/blackbox-exporter:v0.19.0
grafana/grafana:8.3.3
k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.3.0
quay.io/brancz/kube-rbac-proxy:v0.11.0
quay.io/brancz/kube-rbac-proxy:v0.11.0
quay.io/prometheus/node-exporter:v1.3.1
k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1
quay.io/brancz/kube-rbac-proxy:v0.11.0
quay.io/prometheus-operator/prometheus-operator:v0.53.1
quay.io/prometheus/prometheus:v2.32.1
[root@master kube-prometheus-release-0.10]#
# 可以先下载镜像,发现其中有2个镜像一直拉取不下来,所以找了下面的方法解决:
# 失败的镜像
k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1
k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.3.0
# 平替镜像
docker pull lbbi/prometheus-adapter:v0.9.1
docker pull bitnami/kube-state-metrics
# 打标签替换
docker tag lbbi/prometheus-adapter:v0.9.1 k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1
docker tag bitnami/kube-state-metrics:latest k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.3.0
#正式安装
kubectl apply --server-side -f manifests/setup
kubectl wait \
--for condition=Established \
--all CustomResourceDefinition \
--namespace=monitoring
kubectl apply -f manifests/
修改Prometheus的端口
安装好prometheus的service是ClusterIP类型,所以为了能从外网访问,这里简单的已修改为NodePort类型(生产环境根据实际情况将端口暴露出去),然后从浏览器访问:
kubectl edit svc prometheus-k8s -n monitoring
kubectl edit svc grafana -n monitoring
kubectl edit svc alertmanager-main -n monitoring
查看service暴露的NodePort端口:
[root@master ingress-nginx]# kubectl get svc -n monitoring | grep -i nodeport
alertmanager-main NodePort 10.103.67.119 <none> 9093:31206/TCP,8080:30476/TCP 3h22m
grafana NodePort 10.101.101.176 <none> 3000:31757/TCP 3h22m
prometheus-k8s NodePort 10.108.174.80 <none> 9090:32539/TCP,8080:32353/TCP 3h22m
[root@master ingress-nginx]#
访问prometheus
http://192.168.118.133:32539 #访问prometheus
http://192.168.118.133:31757 #访问grafana,默认已经监控起来k8s集群了,默认账号密码 admin/admin
http://192.168.118.133:31206 #访问alertmanager
问题处理
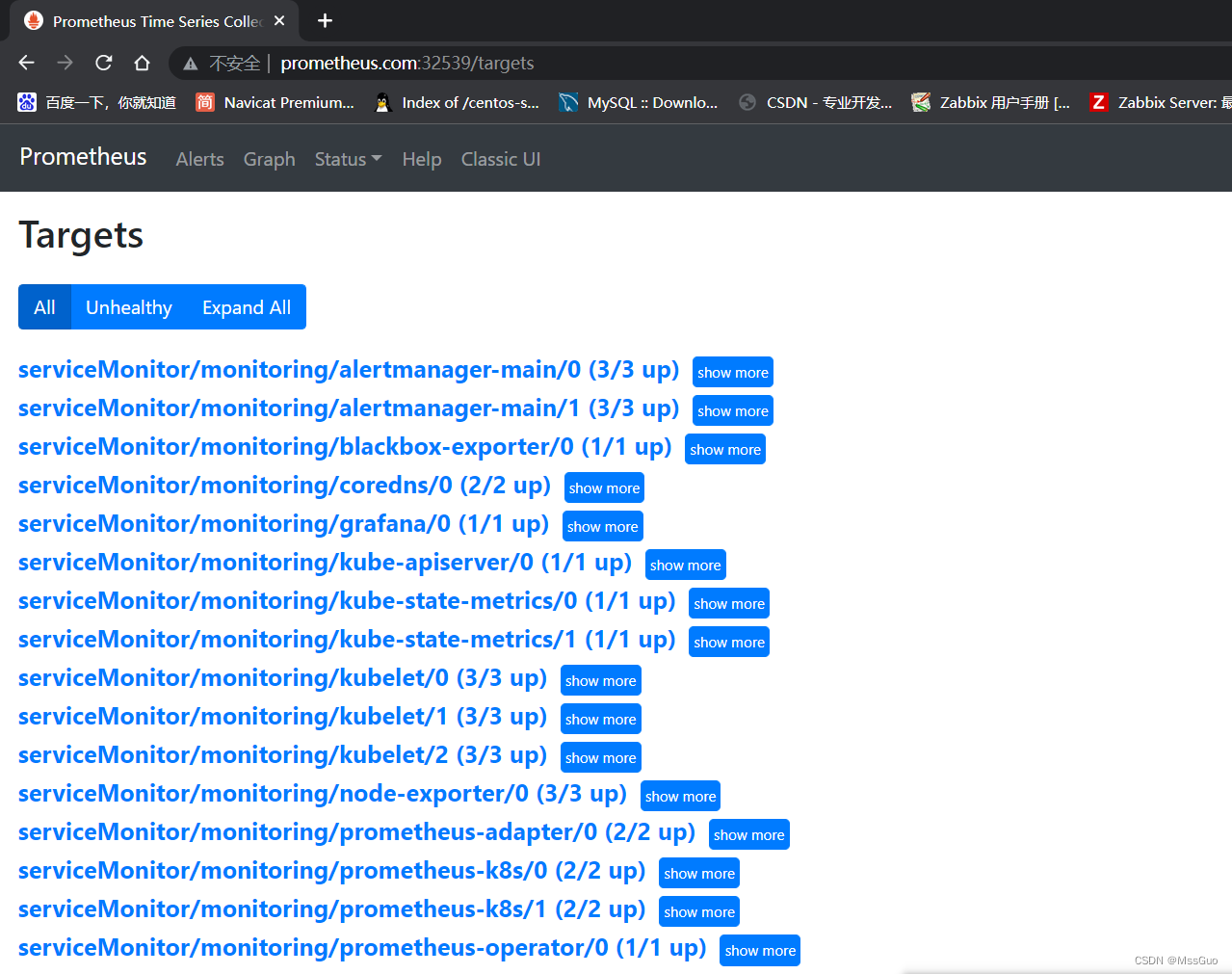
访问下面这个url,发现没有kube-controller-manager和kube-schedule 。
进入我们的http://192.168.118.133:31757 ,访问grafana,发现grafana也是没有监控到kube-controller-manager和kube-schedule 这两个集群组件。
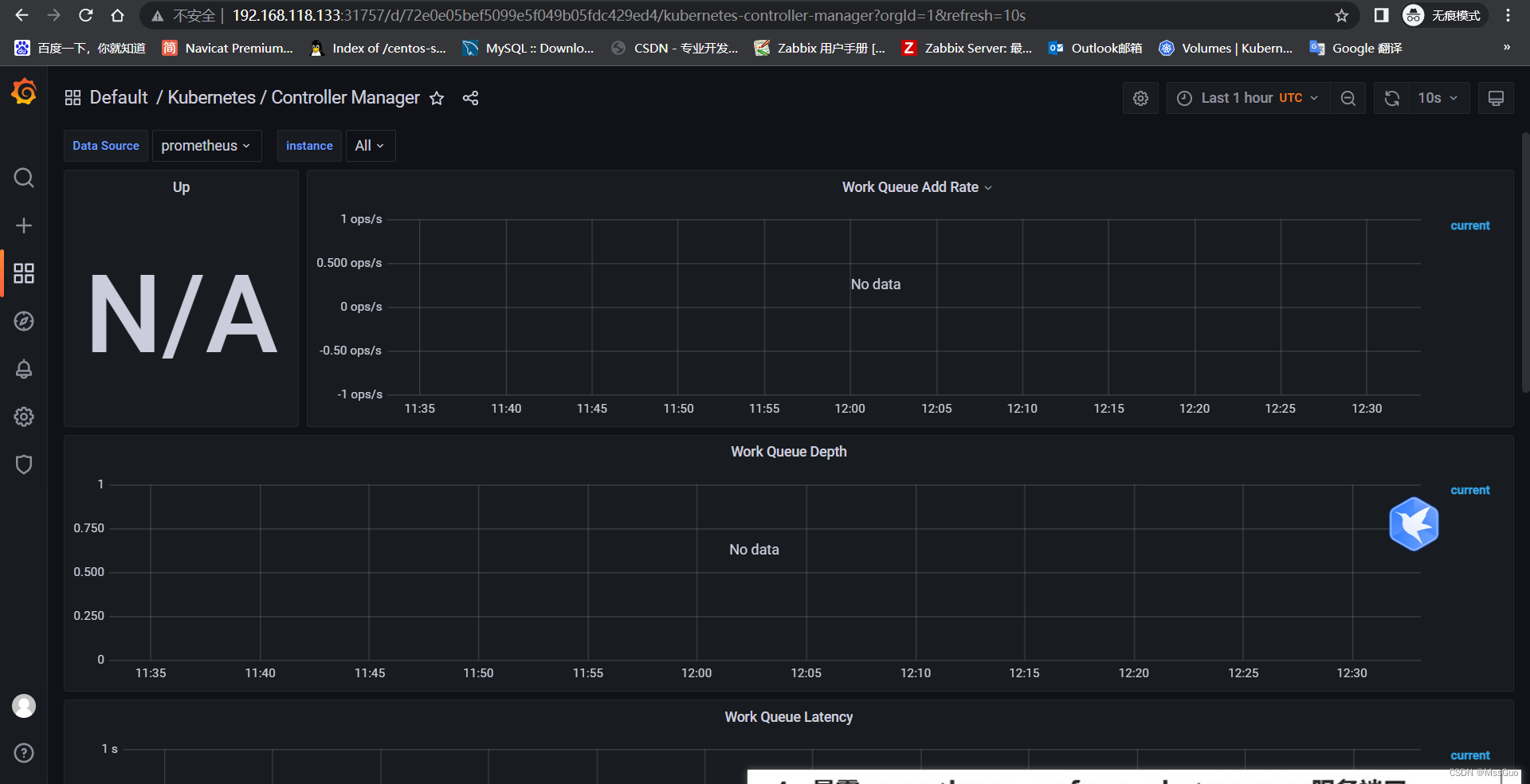
解决prometheus没有监控到kube-controller-manager和kube-schedule 的问题
原因分析:
和prometheus定义的ServiceMonitor的资源有关。
我们查看安装目录下的资源清单文件,kube-scheduler组件对应的资源清单发现:
#进入到我们安装prometheus的目录下
[root@master ~]# cd /root/kube-prometheus/kube-prometheus-release-0.10/manifests
#查看这个kubernetesControlPlane-serviceMonitorKubeScheduler.yaml资源清单
# 这种prometheus自定义资源ServiceMonitor类型,其标签选择器是一个svc
[root@master manifests]# cat kubernetesControlPlane-serviceMonitorKubeScheduler.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/name: kube-scheduler
app.kubernetes.io/part-of: kube-prometheus
name: kube-scheduler
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s
port: https-metrics
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
namespaceSelector: #命名空间选择器
matchNames:
- kube-system
selector: #标签选择器
matchLabels:
app.kubernetes.io/name: kube-scheduler
#发现上面定义的命名空间下的标签选择器,根本就没有匹配的上的对应的svc
[root@master manifests]# kubectl get svc -l app.kubernetes.io/name=kube-scheduler -n kube-system
No resources found in kube-system namespace. #没有svc资源匹配的上
[root@master manifests]#
#我们再来查看对应的controller-manager资源清单看看,也是同样的问题,没有svc资源匹配的上
[root@master manifests]# tail kubernetesControlPlane-serviceMonitorKubeControllerManager.yaml
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
app.kubernetes.io/name: kube-controller-manager
#发现根本就没有对应的service
[root@master manifests]# kubectl get svc -l app.kubernetes.io/name=kube-controller-manager -n kube-system
No resources found in kube-system namespace.
[root@master manifests]#
解决办法:手动创建对应的svc,让prometheus定义的ServiceMonitor资源有对应的service,而service又通过标签选择器关联着pod
#所以现在我们需要主动给它创建一个svc来让他能监控到kube-scheduler
[root@master ~]# cd /root/kube-prometheus/kube-prometheus-release-0.10/manifests/repair-prometheus
[root@master repair-prometheus]# cat kubeSchedulerService.yaml
apiVersion: v1
kind: Service
metadata:
labels: #定义这个service的标签,因为kubernetesControlPlane-serviceMonitorKubeScheduler.yaml里面定义了这个标签
app.kubernetes.io/name: kube-scheduler
name: kube-scheduler
namespace: kube-system #名称空间是kube-system
spec:
selector: #这个标签选择器表示我们要关联到kube-scheduler的pod上
component: kube-scheduler # kubectl get pods kube-scheduler-master -n kube-system --show-labels
ports:
- name: https-metrics #service端口名称,这个名称要与ServiceMonitor的port名称一致
port: 10259
targetPort: 10259 #kube-scheduler-master的端口
[root@master repair-prometheus]#
#同理,我们也需要主动给它创建一个svc来让他能监控到controller-manager
[root@master repair-prometheus]# cat kubeControllermanagerService.yaml
apiVersion: v1
kind: Service
metadata:
labels: #定义这个service的标签,因为kubernetesControlPlane-serviceMonitorKubeControllerManager.yaml里面定义了这个标签
app.kubernetes.io/name: kube-controller-manager
name: kube-controller-manager
namespace: kube-system #名称空间是kube-system
spec:
selector: #这个标签选择器表示我们要关联到kube-controller-manager-master的pod上
component: kube-controller-manager #kubectl get pods kube-controller-manager-master -n kube-system --show-labels
ports:
- name: https-metrics #service端口名称,这个名称要与ServiceMonitor的port名称一致
port: 10257
targetPort: 10257 # kube-controller-manager-master的pod的端口
[root@master repair-prometheus]#
# 创建上面两个service
[root@master repair-prometheus]# kubectl apply -f kubeSchedulerService.yaml -f kubeControllermanagerService.yaml
创建service之后,我们发现grafana的界面还是没有监控到Scheduler和Controllermanager服务,还有一步:
#还有一点,kube-scheduler-master和kube-controller-manager这2个pod启动的时候默认绑定的地址是127.0.0.1,所以普罗米修斯通过ip去访问
# 就会被拒绝,所以需要修改一下,我们知道这2个系统组件是是以静态pod的方式启动的,所以进入到master节点的静态pod目录
# 如果我们不指定静态pod目录时在哪里,可以通过kubelet查看
[root@master manifests]# systemctl status kubelet.service | grep '\-\-config'
└─429488 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.5
[root@master manifests]# grep static /var/lib/kubelet/config.yaml
staticPodPath: /etc/kubernetes/manifests #这就是静态pod的目录
[root@master manifests]#
[root@master ~]# cd /etc/kubernetes/manifests
[root@master manifests]# grep 192 kube-scheduler.yaml
- --bind-address=192.168.118.131 #修改127.0.0.1为主机的ip,修改为0.0.0.0也行
host: 192.168.118.131 #其实保持默认127.0.0.1也行
host: 192.168.118.131 #其实保持默认127.0.0.1也行
[root@master manifests]#
[root@master manifests]# vim kube-controller-manager.yaml
- --bind-address=192.168.118.131 #修改127.0.0.1为主机的ip,修改为0.0.0.0也行
host: 192.168.118.131 #其实保持默认127.0.0.1也行
host: 192.168.118.131 #其实保持默认127.0.0.1也行
[root@master manifests]#
#发现修改后scheduler和controller-manager pod消失了,一直也没有重新创建pod
#所以重启kubelet后pod都正常了
[root@master manifests]# systemctl restart kubelet.service
现在查看grafana的界面已经监控到Scheduler和Controllermanager服务了。
卸载kube-prometheus
如果不需要kube-prometheus了直接delete掉对应的资源清单创建的资源即可:
[root@master ~]# cd /root/kube-prometheus/kube-prometheus-release-0.10/
[root@master ~]# kubectl delete -f manifests/
[root@master ~]# kubectl delete -f manifests/setup/
至此,所有的系统组件都已经被kube-prometheus监控起来的,kube-prometheus搭建完成。
kube-prometheus监控nginx-ingress
nginx-ingress是流量的入口,很重要,我们需要监控nginx-ingress,默认 kube-prometheus并没有监控nginx-ingress,我们需要自己创建serviceMonitor监控nginx-ingress。
[root@master ~]# kubectl get ds ingress-nginx-controller -n ingress-nginx
[root@master ~]# kubectl get pods -n ingress-nginx
NAME READY STATUS RESTARTS AGE
ingress-nginx-controller-g7vmn 1/1 Running 5 (26m ago) 16h
ingress-nginx-controller-sg2kq 1/1 Running 0 16h
[root@master ~]# kubectl get pods ingress-nginx-controller-g7vmn -n ingress-nginx -oyaml #通过查看yaml可以得知pod暴露10254这个指标端口
[root@master ~]# curl 192.168.118.132:10254/metrics #查看pod端口10254暴露的指标,有输出一大堆内容
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 4.5143e-05
go_gc_duration_seconds{quantile="0.25"} 0.000105286
go_gc_duration_seconds{quantile="0.5"} 0.000160581
..............
go_goroutines 91
#创建servicemonitors来监控nginx-ingress
[root@master ~]# kubectl get servicemonitors coredns -n monitoring -oyaml #随便拿一个servicemonitor来改造一下
#创建nginx-ingress的servicemonitors
[root@master servicemonitor-nginx-ingress]# vim servicemonitor-nginx-ingress.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/name: ingress-nginx
name: ingress-nginx
namespace: monitoring
spec:
endpoints:
- path: /metrics
interval: 15s
port: metrics
jobLabel: app.kubernetes.io/name
namespaceSelector:
matchNames:
- ingress-nginx
selector:
matchLabels:
app.kubernetes.io/name: ingress-nginx
[root@master servicemonitor-nginx-ingress]#
#创建service
#我们发现已经有对应的标签的service,但是这个service里面并没有名称叫做metrics的端口
[root@master ~]# kubectl get svc -n ingress-nginx -l app.kubernetes.io/name=ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller-admission ClusterIP 10.102.72.255 <none> 443/TCP 245d
[root@master ~]# kubectl edit svc ingress-nginx-controller-admission -n ingress-nginx
ports:
- appProtocol: https
name: https-webhook
port: 443
protocol: TCP
targetPort: webhook
- name: metrics #追加这一段,表示在service上启动一个10245的端口,对应的pod的10245端口
port: 10254
protocol: TCP
targetPort: 10254
[root@master ~]# curl 10.102.72.255:10254/metrics #这时我们通过service的10254端口就能读取到metrics指标了
我们发现prometheus页面上targets(http://192.168.118.131:32539/targets )里面还是没有显示nginx-ingress,查prometheus-k8s-0这个pod 看到报错:
#查看prometheus-k8s-0这个pod 看到报错了,forbidden权限不足
[root@master servicemonitor-nginx-ingress]# kubectl logs -n monitoring prometheus-k8s-0 -c prometheus
ts=2022-10-21T04:57:14.829Z caller=klog.go:116 level=error component=k8s_client_runtime func=ErrorDepth msg="pkg/mod/k8s.io/client-go@v0.22.4/tools/cache/reflector.go:167: Failed to watch *v1.Service: failed to list *v1.Service: services is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list resource \"services\" in API group \"\" in the namespace \"ingress-nginx\""
# 查看prometheus创建的集群角色
[root@master ~]# kubectl get clusterroles prometheus-k8s -oyaml
apiVersion: rbac.authorization.k8s.io/v1
........
rules: #默认权限太少了
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
# 修改集群角色的权限
[root@master ~]# kubectl edit clusterroles prometheus-k8s
rules: #添加权限
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
这是,我们发现prometheus页面上targets(http://192.168.118.131:32539/targets )有显示nginx-ingress了,说明已经监控起来了。
相关文章
- 如何通过minio operator在k8s中部署minio租户(tenant)集群
- k8s集群中部署和访问Dashboard服务
- milvus k8s部署后一键查看节点日志
- K8s部署笔记一
- 使用Kubeadm创建k8s集群之部署规划(三十)
- K8s 应用管理之道 - 升级篇(一)
- K8s环境 nfs 服务器,动态存储卷nfs-client-provisioner部署
- k8s CKS 2021【25】---系统加固减少攻击面
- k8s 【策略】【资源管理】ResourceQuota
- k8s 准入控制器【4】--编写和部署准入控制器 Webhook--以非root运行pod
- 微服务容器化迁移——在K8s中部署Spring Cloud
- K8S二进制部署实践-1.15.5
- k8s安装eureka集群
- K8S容器探针
- k8s服务端二进制部署-kube-apiserver
- k8s部署etcd数据库集群
- k8s 部署 traefik1.7
- 二、K8S镜像问题
- k8s 各个版本的差别
- 在K8S部署中,有时候容器启动顺序因为我们业务需要是有要求的,比如业务服务可能需要在 配置中心、注册的中心 启动后才启动,那么该如何呢?
- k8s的容器存储空间资源限制ephemeral-storage
- k8s集群etcd数据库常用命令
- k8s图形化工具dashboard的安装、k8s图形化工具kubeoard的安装