
Pandas(四) 数据清洗
2023-09-11 14:21:25 时间

很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要对使数据分析更加准确,就需要对这些没有用的数据进行处理。数据清洗是对一些没有用的数据进行处理的过程。
1、Pandas清洗空值
使用dropna()方法,语法格式如下:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
how:默认为 'any' 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how='all' 一行(或列)都是 NA 才去掉这整行。
thresh:设置需要多少非空值的数据才可以保留下来的。
subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
测试数据使用excel,如下:
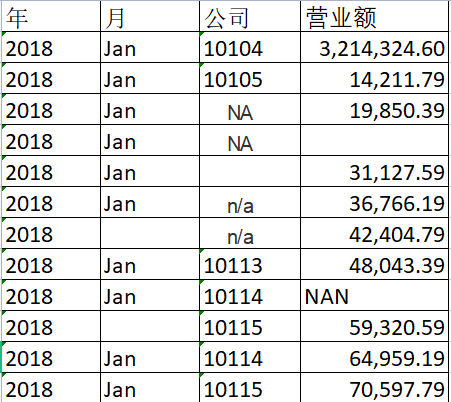
excel数据中包含了空,NAN, NA,n/a等等
实例:
import pandas as pd
missing_values = ["n/a", "na", "--","NAN"]
df = pd.read_excel(r"E:/python.xlsx", sheet_name="Sheet1", na_values=missing_values)
print(df.dropna(axis=0, how='any'))
输出:
年 月 公司 营业额
0 2018 Jan 10104.0 3214324.60
1 2018 Jan 10105.0 14211.79
7 2018 Jan 10113.0 48043.39
10 2018 Jan 10114.0 64959.19
11 2018 Jan 10115.0 70597.791.1 使用 isnull() 判断单元格是否为空
实例:
import pandas as pd
missing_values = ["n/a", "na", "--","NAN"]
df = pd.read_excel(r"E:/python.xlsx", sheet_name="Sheet1", na_values=missing_values)
print(df["营业额"].isnull())
输出:
0 False
1 False
2 False
3 True
4 False
5 False
6 False
7 False
8 True
9 False
10 False
11 False
Name: 营业额, dtype: bool1.2 使用 fillna() 方法来替换一些空字段 或者 指定某列空数据替换
实例:
# 使用12345 替换空字段
import pandas as pd
df3 = pd.read_excel(r"E:/python.xlsx", sheet_name="Sheet1")
df3.fillna(12345,inplace=True)
print(df3)
输出:
年 月 公司 营业额
0 2018 Jan 10104.0 3214324.6
1 2018 Jan 10105.0 14211.79
2 2018 Jan 12345.0 19850.39
3 2018 Jan 12345.0 12345
4 2018 Jan 12345.0 31127.59
5 2018 Jan 12345.0 36766.19
6 2018 12345 12345.0 42404.79
7 2018 Jan 10113.0 48043.39
8 2018 Jan 10114.0 NAN
9 2018 12345 10115.0 59320.59
10 2018 Jan 10114.0 64959.19
11 2018 Jan 10115.0 70597.79
# 使用北京分公司 替换公司为空字段
import pandas as pd
df3 = pd.read_excel(r"E:/python.xlsx", sheet_name="Sheet1")
df3["公司"].fillna("北京分公司",inplace=True)
print(df3.to_string())
输出:
年 月 公司 营业额
0 2018 Jan 10104.0 3214324.6
1 2018 Jan 10105.0 14211.79
2 2018 Jan 北京分公司 19850.39
3 2018 Jan 北京分公司 NaN
4 2018 Jan 北京分公司 31127.59
5 2018 Jan 北京分公司 36766.19
6 2018 NaN 北京分公司 42404.79
7 2018 Jan 10113.0 48043.39
8 2018 Jan 10114.0 NAN
9 2018 NaN 10115.0 59320.59
10 2018 Jan 10114.0 64959.19
11 2018 Jan 10115.0 70597.792、Pandas清洗错误数据
数据错误也是很常见,可以通过替换方式
实例:
import pandas as pd
dic = {
"季节": ["春", "夏", "秋", "123"], # 123错误
"月份": [2, 4, 8, 12]
}
df = pd.DataFrame(dic)
print("原始数据输出:\n",df)
df.loc[3, "季节"] = "冬" # 修改数据,替换错误数据
print("修改后输出:\n",df.to_string())
输出:
原始数据输出:
季节 月份
0 春 2
1 夏 4
2 秋 8
3 123 12
修改后输出:
季节 月份
0 春 2
1 夏 4
2 秋 8
3 冬 12
相关文章
- pandas学习(数据分组与分组运算、离散化处理、数据合并)
- 在Python-Pandas中循环或遍历数据框的所有或某些列
- 用Python的pandas框架操作Excel文件中的数据教程
- pandas拆分指定数量的excel
- pandas判断excel列名是否正确
- Python之pandas:对dataframe数据的索引简介、应用大全(输出索引/重命名索引列/字段去重/设置复合索引/根据列名获取对应索引)、指定某字段为索引列等详细攻略
- Py之pandas:利用where、replace等函数对dataframe格式数据按照条件进行数据替换
- ML之FE:数据预处理中基于pandas实现类别型字段数据编码(包括自定义编码映射字典)、目标变量布尔类型化且同时输出raw_df和df数据之代码实现攻略
- 100天精通Python(数据分析篇)——第68天:Pandas数据清洗函数大全(判断缺失、删除空值、填补空值、替换元素、分割元素)
- 【阶段二】Python数据分析Pandas工具使用10篇:探索性数据分析:数据的检验:正态性检验
- 【阶段二】Python数据分析Pandas工具使用02篇:数据读取:文本文件读取、电子表格读取与数据预处理:数据概览与清洗
- 使用pandas进行数据清洗
- pandas+sqlalchemy 保存数据到mysql
- Python数据科学:Pandas Cheat Sheet
- Pandas -- SettingwithCopyWarning 原理和解决方案(转)
- pandas apply lamba
- pandas合并
- Pandas-常用统计分析方法 describe、quantile、sum、mean、median、count、max、min、idxmax、idxmin、mad、var、std、cumsum
- 【pandas】教程:7-调整表格数据的布局
- 【pandas】教程:4-显示数据
- 【pandas】教程:2-读写表格数据
- 【pandas】教程:1-处理什么样的数据
- pandas groupby基本用法