
梯度消失与梯度爆炸
一、产生原因
假设我们使用的激活函数为sigmoid函数。其导数为g(x)*(1-g(x)),图像如下:

也就是sigmoid函数导数最大值为0.25。
当我们根据链式法则进行反向求导的时候,公式最终是权重和sigmoid导数的连乘形式,如下:
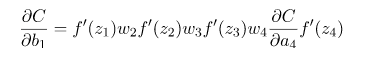
如果使用一个均值0标准差为1的高斯分布来初始化权值,所有的权重通常会满足 |w|<1,而激活函数f的导数也是0-1之间的数,其连乘后,结果会变的很小,导致梯度消失。若我们初始化的w是很大的数,w大到乘以激活函数的导数都大于1,即abs(w)>4,那么连乘后,可能会导致求导的结果很大,形成梯度爆炸。
二、解决办法
1. 重新设计网络模型
在深度神经网络中,梯度爆炸可以通过重新设计层数更少的网络来解决。
使用更小的批尺寸对网络训练也有好处。另外也许是学习率的原因,学习率过大导致的问题,减小学习率。
在循环神经网络中,训练过程中在更少的先前时间步上进行更新(沿时间的截断反向传播,truncated Backpropagation through time)可以缓解梯度爆炸问题。
2. 使用 ReLU 激活函数
在深度多层感知机神经网络中,梯度爆炸的发生可能是因为激活函数,如之前很流行的 Sigmoid 和 Tanh 函数。
使用 ReLU 激活函数可以减少梯度爆炸。采用 ReLU 激活函数是最适合隐藏层的新实践,Relu同样可以防止梯度消失。
3. 使用长短期记忆网络
在循环神经网络中,梯度爆炸的发生可能是因为某种网络的训练本身就存在不稳定性,如随时间的反向传播本质上将循环网络转换成深度多层感知机神经网络。
使用长短期记忆(LSTM)单元和相关的门类型神经元结构可以减少梯度爆炸问题,也能减少梯度消失。
采用 LSTM 单元是适合循环神经网络的序列预测的最新最好实践。
4. 使用梯度截断(Gradient Clipping)
在非常深且批尺寸较大的多层感知机网络和输入序列较长的 LSTM 中,仍然有可能出现梯度爆炸。如果梯度爆炸仍然出现,你可以在训练过程中检查和限制梯度的大小。这就是梯度截断。
5. 使用权重正则化(Weight Regularization)
如果梯度爆炸仍然存在,可以尝试另一种方法,即检查网络权重的大小,并惩罚产生较大权重值的损失函数。该过程被称为权重正则化,通常使用的是 L1 惩罚项(权重绝对值)或 L2 惩罚项(权重平方)。