
Kaggle竞赛入门(三):用Python处理过拟合和欠拟合,得到最佳模型
本文翻译自kaggle learn,也就是kaggle官方最快入门kaggle竞赛的教程,强调python编程实践和数学思想(而没有涉及数学细节),笔者在不影响算法和程序理解的基础上删除了一些不必要的废话,毕竟英文有的时候比较啰嗦。
一.什么是过拟合和欠拟合?
过拟合的含义就是当前模型十分符合训练集,十分精确,用这个模型去预测目前的训练集残差非常小,也可以说真实值减去预测值的大小的平均值非常小,但是用这个模型去预测新的数据误差就非常大了,因为这个模型仅适合当前的训练集。什么是欠拟合呢?欠拟合也就正好和过拟合相反,也就是当前模型不太和训练集想符合,我们如何找到一个既不过拟合也不欠拟合的模型呢?
下面这幅图非常直观,表示了哪一个点是最佳点,能够得到我们最佳的模型:
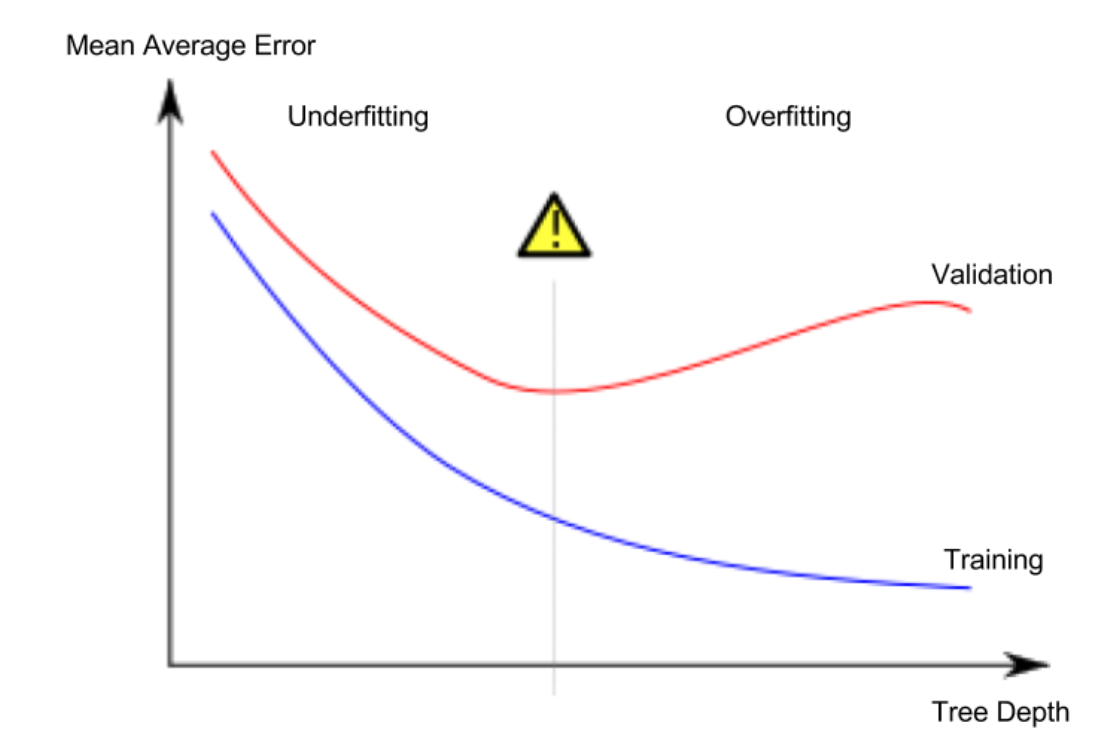
这张图的横坐标是Tree Depth,可以理解为我们模型符合训练集的程度,蓝色线条代表训练集的Error,也就是平均误差,红色线条代表验证集的平均误差。可以看到中间这条灰色的感叹号线这里验证集的平均误差是最小的,我们最终拟合出来的模型是为了能够让新的数据在这个模型上表现更好,而不是让训练集,因此红色线得到的最小值就是我们的最好模型所在点。模型越符合训练集,那么训练集的平均误差就会越来越小,反之,验证集则会先减小后增大,因为模型最开始欠拟合,超过一定限度就是过拟合了,这也比较符合逻辑。那么我们如何用代码来选取在验证集最小处的最佳模型呢?
二.例子
我们用决策树算法作为一个例子,在拟合决策树模型时,里面有一个参数叫做max_leaf_nodes,也就是决策树当中的最大树叶的深度,它能够很好的对过拟合和欠拟合进行控制,这个参数越大那么模型就越符合训练集。这个参数就是上图当中的Tree dapth,我们可以写一个函数来返回平均误差的值,代码如下:
from sklearn.metrics import mean_absolute_error from sklearn.tree import DecisionTreeRegressor def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y): model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0) model.fit(train_X, train_y) preds_val = model.predict(val_X) mae = mean_absolute_error(val_y, preds_val) return(mae)
这样就得到了决策树算法的平均误差,之后将我们的数据分解得到训练集和验证集:
# Data Loading Code Runs At This Point import pandas as pd # Load data melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv' melbourne_data = pd.read_csv(melbourne_file_path) # Filter rows with missing values filtered_melbourne_data = melbourne_data.dropna(axis=0) # Choose target and features y = filtered_melbourne_data.Price melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'BuildingArea', 'YearBuilt', 'Lattitude', 'Longtitude'] X = filtered_melbourne_data[melbourne_features] from sklearn.model_selection import train_test_split # split data into training and validation data, for both features and target train_X, val_X, train_y, val_y = train_test_split(X, y,random_state = 0)
我们最后可以用一个循环来比较不同max_leaf_nodes下模型的准确度,代码如下:
# compare MAE with differing values of max_leaf_nodes for max_leaf_nodes in [5, 50, 500, 5000]: my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y) print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))
输出:
Max leaf nodes: 5 Mean Absolute Error: 347380 Max leaf nodes: 50 Mean Absolute Error: 258171 Max leaf nodes: 500 Mean Absolute Error: 243495 Max leaf nodes: 5000 Mean Absolute Error: 254983
因此可见,当max_leaf_nodes等于500的时候,模型最准确,误差最小。当然我们这里仅选取了四个值,实际上需要遍历所有的值才能够得到最小的值,这里方便大家理解就只遍历这几个值了。
相关文章
- [python] LDA处理文档主题分布代码入门笔记
- python数据结构之二叉树的统计与转换实例
- python入门-分类和回归各种初级算法
- python:ERROR: No matching distribution found for Pillow==9.1.0的处理(Python 3.6.8)
- 小白学 Python 爬虫(39): JavaScript 渲染服务 scrapy-splash 入门
- 【Python 20】BMR计算器4.0(异常处理)
- Python 字符串_python 字符串截取_python 字符串替换_python 字符串连接
- python初步入门
- python:pip升级pip本身和setuptools(Python 3.7.15)
- nodejs,python,sublime和Eclipse的包管理器
- Atitit nlp自然语言处理类库(java python nodejs c#net) 目录 1.1. Python snownlp1 1.2. NLP.js一个nodejs/javascri
- Python入门只需20分钟:从安装到数据抓取、存储这么简单
- Python:利用python编程将上海十六区,2020年5月份房价实时地图(数据来源房天下)进行柱状图、热图可视化
- Python语言学习:python语言代码调试—异常处理之详细攻略
- Python之tkinter:动态演示调用python库的tkinter带你进入GUI世界(Button展示图片事件)
- Python语言学习之双下划线那些事:python和双下划线使用方法之详细攻略
- 已解决2.Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and wi
- 〖Python接口自动化测试实战篇⑬〗- 实战 - unittest框架之测试套件应用
- python界面开发案例:制作一个计算器软件
- 从零开始学python | 什么是Python JSON?
- python selenium 三种等待方式详解
- Python编程:查看python环境支持的whl
- Python——用正则求时间差
- 60集Python入门视频PPT整理 | Python过程型程序设计快速入门
- python web py入门(61)- jQuery - 使用keyup()和keydown()函数
- python web py入门(2)-URL处理
- python web py入门(39)- javascript的while循环语句
- python web py入门(31)- javascript的逻辑处理
- python MLP 神经网络使用 MinMaxScaler 没有 StandardScaler效果好
- rethinkDB python入门
- Python-MNIST机器学习入门
- Python: 爬虫入门-python爬虫入门教程(非常详细)
- Python(6):集合