
深度学习激活函数比较
一、Sigmoid函数
1)表达式
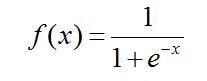

2)函数曲线

3)函数缺点
-
-
- 梯度饱和问题。先看一下反向传播计算过程:
-
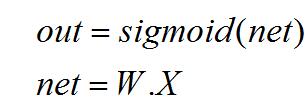
反向求导:
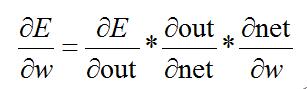
而其中:
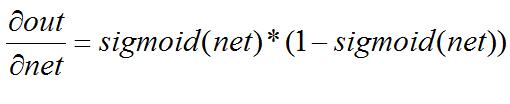
所以,由上述反向传播公式可以看出,当神经元数值无线接近1或者0的时候,在反向传播计算过程中,梯度也几乎为0,就导致模型参数几乎不更新了,对模型的学习贡献也几乎为零。也称为参数弥散问题或者梯度弥散问题。
同时,如果初始权重设置过大,会造成一开始就梯度接近为0,就导致模型从一开始就不会学习的严重问题。
-
-
- 函数不是关于原点中心对称的。
这个特性会导致后面网络层的输入也不是零中心的,也就是说经过sigmoid发出的值x只可能是正值,而不可能是负值,对于下一层的参数w的更新会有影响,因为下一层参数的更新需要用到这个值x,这个如果既可以为正值又可以为负值的话,那么参数w的更新就可以根据实际需要快速增大或者快速减小,很快收敛。如果激活函数是以零为中心,就可以既发出正值也可以发出负值。

- 函数不是关于原点中心对称的。
-
二、tanh函数
1)公式
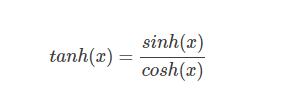
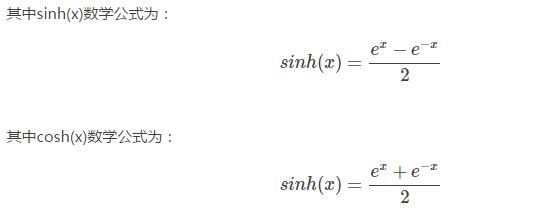
2) 导数
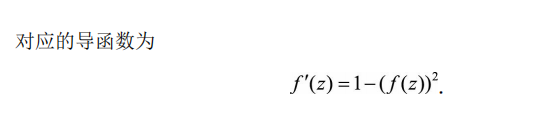
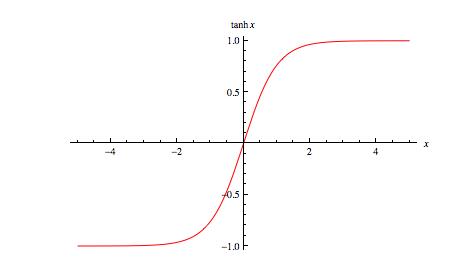
3)曲线
tanh(x)=2sigmoid(2x)-1
tanh 函数同样存在饱和问题,但它的输出是零中心的,因此实际中 tanh 比 sigmoid 更受欢迎。
三、ReLU函数
1)表达式
f(x)=max(0,x)
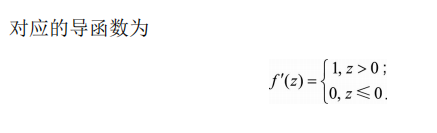
2)曲线
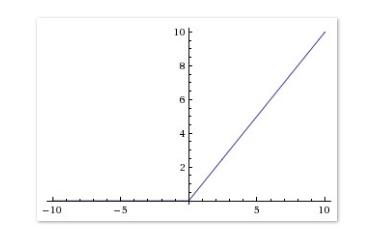
相较于 sigmoid 和 tanh 函数,ReLU 对于 SGD 的收敛有巨大的加速作用(Alex Krizhevsky 指出有 6 倍之多)。有人认为这是由它的线性、非饱和的公式导致的。我觉得最起码在右半轴ReLU函数的梯度是恒定的,不存在饱和情况,只是在左侧存在梯度硬饱和,sigmoid函数属于两端都软饱和,这可能是ReLU函数相对比较受欢迎的原因吧,最起码有一端比较完美了。
ReLU 的缺点是,它在训练时比较脆弱并且可能“死掉”,就是在梯度为0硬饱和的时候,容易出现这种死掉的情况。

局限性

3)改进


相关文章
- UFLDL 教程学习笔记(四)
- MySQL数据库学习笔记(四)----MySQL聚合函数、控制流程函数(含navicat软件的介绍)
- 使用函数计算三步实现深度学习 AI 推理在线服务
- python(五)常用模块学习
- Excel函数学习:HLOOKUP函数
- 数据结构和算法学习二,之循环和递归
- 《从零开始学Swift》学习笔记(Day 40)——析构函数
- ES6学习之路6----箭头函数
- 数学建模学习笔记(十四)神经网络——下:BP实战-非线性函数拟合
- c++模板学习06之类模板与函数模板区别
- ML之VI/PFI:机器学习可解释性之特征置换重要性之机器学习模型中哪些特征很重要?
- Python编程语言学习:利用open函数将文本内容追加写入到txt文件中(两种方法实现)
- Python编程语言学习:python中与数字相关的函数(取整等)、案例应用之详细攻略
- C++:C++编程语言学习之函数/结构体和类的简介、案例应用之详细攻略
- Python语言学习:三种随机函数random.seed()、numpy.random.seed()、set_random_seed()及random_normal的简介、使用方法(固定种子)详细攻略
- DL之AF:机器学习/深度学习中常用的激活函数(sigmoid、softmax等)简介、应用、计算图实现、代码实现详细攻略
- DL之AF:机器学习/深度学习中常用的激活函数(sigmoid、softmax等)简介、应用、计算图实现、代码实现详细攻略
- ML之ME/LF:机器学习中的模型评估指标/损失函数(连续型/离散型)的简介、损失函数/代价函数/目标函数之间区别、案例应用之详细攻略
- Python语言学习之字母C开头函数使用集锦:count用法之详细攻略
- 数学建模学习(89):交叉熵优化算法(CEM)对多元函数寻优
- 【阶段四】Python深度学习03篇:深度学习基础知识:神经网络可调超参数:激活函数、损失函数与评估指标
- Vue学习之--------编程式路由导航、缓存路由组件、新的钩子函数(4)(2022/9/5)
- Scala学习教程笔记二之函数式编程、Object对象、伴生对象、继承、Trait、
- swift学习一:介绍,开发文档下载
- 学习ARM开发(12)
- MOSFET 和 IGBT 栅极驱动器电路的基本原理学习笔记(六)变压器耦合栅极驱动
- 【Pytorch】第 6 章 :用函数逼近扩展学习
- 不懂数学可以学机器学习吗
- 学习经验分享【24】全网最简单标注数据集方法