
kubectl 命令 --save-config 将部署信息添加到注解,防止deploy或webhook通过注释添加到集群 --record 记录下当前的版本信息为了回滚
1、--save-config
为什么需要使用kubctl apply保存配置?
kubectl apply <file.yaml> --save-config创建或更新部署,并将部署另存为元数据。
文件上说
--save-config[=false]:如果为true,则当前对象的配置将保存在其注释中。当您将来要对此对象执行kubectl apply时,这非常有用。
为什么我需要save-config?如果不使用--save-config,我仍然可以使用kubectl apply更新部署。
kubectl apply
kubectl apply使用注解kubectl.kubernetes.io/last-applied-configuration中的数据来查看自上次应用以来是否有任何字段被删除。这是必要的,因为某些字段或注释可能已通过控制器或变异的webhook实时添加到集群中。
例如,请参见了解Kubectl Apply命令
如果我不--save-config,我仍然可以使用kubectl apply更新部署
是的,--save-config仅在从命令式工作流迁移时使用。详见下文。以下kubectl apply命令不需要--save-config标志,因为注释已经存在。
kubectl工作流
使用Kubernetes的配置时,可以通过多种方式完成,它们都是命令式或声明式的:
- Managing Kubernetes Objects Using Imperative Commands
- Kubernetes Objects Using配置文件的强制管理
- Kubernetes Objects Using配置文件的声明式管理
kubectl apply用于声明性配置管理。
从命令式到声明式配置管理的迁移
将kubectl与--save-config标志一起使用是一种向kubectl apply使用的注释kubectl.kubernetes.io/last-applied-configuration写入配置的方法。这在从命令式工作流迁移到声明式工作流时非常有用。
- 从命令式命令管理迁移到声明式对象配置
- 从命令式对象配置迁移到声明式对象配置
2、--record
k8s的应用回滚--record
kubectl apply 每次更新应用时 Kubernetes 都会记录下当前的配置,保存为一个 revision(版次),这样就可以回滚到某个特定 revision。
默认配置下,Kubernetes 只会保留最近的几个 revision,可以在 Deployment 配置文件中通过 revisionHistoryLimit 属性增加 revision 数量。
使用也很简单,在更新的时候加上--record就可以了。
命令
记录版本kubectl apply -f xxx.yaml --record
查看 revisonkubectl rollout history deployment $dp_name -n $namespaces
回滚kubectl rollout undo deployment $dp_name --to-revision=1
注意:
record类似一个栈,先执行的apply会放到记录的最下端。也就是说你的上一个版本一定是2.
record记录的是apply的命令,所以如果每次执行的命令是一样的话,会覆盖掉。
实验
1、如下做三个httpd的yaml,分别为httpd.v1.yml,httpd.v2.yml 和 httpd.v3.yml,分别对应不同的 httpd 镜像 2.4.16,2.4.17 和 2.4.18:
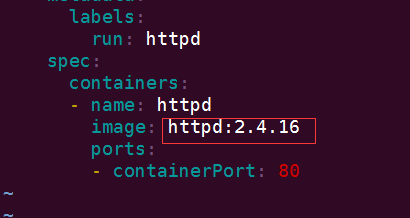
2、通过 kubectl apply 更新应用
-
kubectl apply -f httpd.v1.yml --record
-
kubectl apply -f httpd.v2.yml --record
-
kubectl apply -f httpd.v3.yml --record
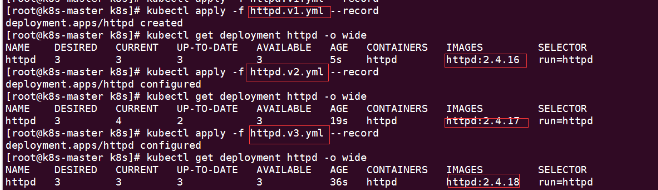
3、查看版本
kubectl rollout history deployment httpd
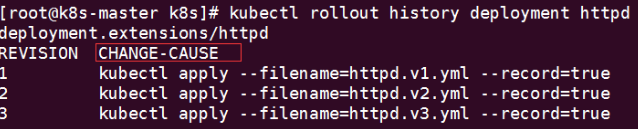
4、回滚kubectl rollout undo deployment httpd --to-revision=1
相关文章
- Redis集群的部署
- 三天100元从零开始搭建Hadoop集群
- Centos7 RKE部署高可用k8s集群
- Redis集群持久化
- Kubernetes kubectl config 对集群做配置
- K8S通过rook部署rook ceph集群、配置dashboard访问并创建pvc
- hadoop大数据集群完全分布式部署实操篇:HDFS2.9.2、HBASE2.2.6、YARN2.9.2、SPARK2.4.7,ZOOKEEPER3.6.2
- zookeeper集群搭建
- 如何搭建Hadoop集群环境
- E-MapReduce的HBase集群使用Hue
- hadoop3.1 分布式集群部署
- k59.第二章 基于二进制包安装kubernetes v1.23 --集群部署
- 【云原生之kubernetes】在kubernetes集群下的映射外部服务—Eendpoint
- 【云原生之kubernetes】kubernetes集群高级资源对象statefulesets
- ceph集群状态持续监控
- 如何在Spark集群的work节点上启动多个Executor?
- 微服务Consul系列之集群搭建
- Ubuntu构建LVS+Keepalived高可用负载均衡集群【生产环境部署】
- 云原生|docker|基于docker部署高可用keepalived集群
- OceanBase社区版之OBD方式部署分布式集群
- hadoop入门(六):集群测试
- s25.基于 Kubernetes v1.25 (二进制) 和 Containerd部署高可用集群
- 【Docker系列】1.docker-compose部署zk集群+kafka集群
- ClickHouse管理工具—ckman教程(3)从ckman源码分析部署集群时的主要步骤
- 猿创征文 | 国产数据库之在k8s环境下部署RadonDB MySQL集群
- 部署kibana分析系统并连接elasticsearch集群展现索引数据(八)
- Redis哨兵集群工作原理及架构部署(八)