
贪心优先搜索算法与A*算法python实现
2023-09-11 14:20:29 时间
贪心优先搜索算法与A*算法
贪心优先搜索算法与A*算法实现如下:
实现过程中,我们用到了两个数据集driving.csv和strightline.csv
数据集上传到我的资源里了,可以下载
两个csv文件生成的图如下:
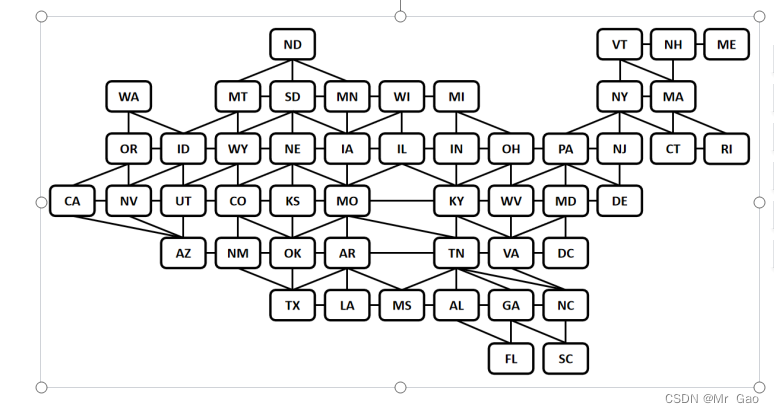
import codecs
import csv
import os
import numpy as np
import sys
import time
strline_dict={}
edges=[]
with codecs.open(r'C:\Users\gaoxi\Desktop\data\data\search\straightline.csv', encoding='utf-8-sig') as f:
z=0
for row in csv.DictReader(f, skipinitialspace=True):
p=0
key=''
for i in row.items():
if p==0:
strline_dict[i[1]]={}
p=p+1
key=i[1]
else:
# print(i)
strline_dict[key][i[0]]=float(i[1])
# print(strline_dict[key])
f.close()
#print(strline_dict)
with codecs.open(r'C:\Users\gaoxi\Desktop\data\data\search\driving.csv', encoding='utf-8-sig') as f:
z=0
for row in csv.DictReader(f, skipinitialspace=True):
p=0
key1=''
key2=''
# print(row)
for i in row.items():
if p==0:
p=p+1
key1=i[1]
else:
if i[1]!='-1':
# print(i)
key2=i[0]
edges.append((key1,key2,float(i[1])))
#print(edges)
#print(strline_dict)
def search_path():
arg=[]
try:
arg.append(sys.argv[1])
arg.append(sys.argv[2])
except:
print("ERROR: Not enough or too many input arguments.")
return 0
if len(arg)!=2:
print("ERROR: Not enough or too many input arguments.")
return 0
start=arg[0]
end=arg[1]
print("Last Name, First Name, AXXXXXXXX solution:")
print("Initial state:" ,start)
print("Goal state: ",end)
print()
straight_line=strline_dict[end]
#ca ar
# print(straight_line)
path = [] # 存储最优路线
path.append(start)
distance = [] # 存储最优路线的路线长度
temp_path='0'
temp_distance='0'
path_enpend=[]
path_enpend.append(start)
start_time = time.perf_counter() # 程序开始时间
visted_num=1
for i in range(100):
path1 = [] # path1中存储该节点的连接城市
distance1 = [] # distance1中存储该节点连接城市的距离
for a in range(len(edges)):
if edges[a][0] == path[-1]:
visted_num=visted_num+1
path1.append(edges[a][1])
distance1.append(edges[a][-1])
path_enpend.append(edges[a][1])
# 贪婪最优搜索
min_distance = 1000000
for b in range(len(path1)):
if straight_line[path1[b]] < min_distance:
min_distance = straight_line[path1[b]]
temp_distance = distance1[b]
temp_path = path1[b]
# print("temp_path",temp_path)
path.append(temp_path)
distance.append(temp_distance)
if temp_path == end:
break
# print(path)
X = ','.join(path)
Y = np.sum(distance)
end_time = time.perf_counter() # 程序结束时间
run_time = end_time - start_time # 程序的运行时间,单位为秒
# print(distance)
if path[-1]==end:
# print(visted_num)
print("Greedy Best First Search:")
print('Solution path: ', X)
print('Number of expanded nodes: ', len(set(path_enpend)))
print('Path cost: ', Y)
print("Execution time: ",run_time," seconds")
else:
print('Greedy Best First Search:\nSolution path: FAILURE: NO PATH FOUND\nNumber of states on a path: 0\nPath cost: 0\nExecution time: T3 seconds')
path = [] # 存储最优路线
path.append(start)
distance = [] # 存储最优路线的路线长度
temp_path='0'
temp_distance='0'
path_enpend=[]
path_enpend.append(start)
start_time = time.perf_counter() # 程序开始时间
visted_num=1
for i in range(100):
path1 = [] # path1中存储该节点的连接城市
distance1 = [] # distance1中存储该节点连接城市的距离
for a in range(len(edges)):
if edges[a][0] == path[-1] and edges[a][1]!=path[-1]:
path_enpend.append(edges[a][1])
path1.append(edges[a][1])
distance1.append(edges[a][-1])
visted_num=visted_num+1
# A*搜索
fxx = 10000000
# print(path1)
# path1=list(set(path1))
for b in range(len(path1)):
fxx_min = straight_line[path1[b]] + distance1[b]
if fxx_min < fxx:
fxx = fxx_min
temp_distance = distance1[b]
temp_path = path1[b]
path.append(temp_path)
distance.append(temp_distance)
if temp_path == end:
break
X = ','.join(path)
Y = np.sum(distance)
# print(distance)
print()
end_time = time.perf_counter() # 程序结束时间
run_time = end_time - start_time # 程序的运行时间,单位为秒
if path[-1]==end:
# print(visted_num)
print("A* Search:")
print('Solution path: ', X)
print('Number of expanded nodes: ', len(set(path_enpend)))
print('Path cost: ', Y)
print("Execution time: ",run_time," seconds")
else:
print('A* Search:\nSolution path: FAILURE: NO PATH FOUND\nNumber of states on a path: 0\nPath cost: 0\nExecution time: T3 seconds')
search_path()
os.system("pause")
实验过程中我们有如下发现
在实验过程中我们发现,如果起点和终点之间有路径,贪婪最佳优先搜索和A搜索相比,可能会沿着一条无限的路径走下去而不回来做其他的选择尝试,因此无法找到一条路径,而A算法一定可以搜索出一条路径。
另外对于Number of expanded nodes、Path cost、Average search time in secon两种算法跑出的结果并没有明显差异,从性能上来说,有时A更好,有时A最好。
相关文章
- 【机器学习算法-python实现】协同过滤(cf)的三种方法实现
- 【Python】自动化抢勾,python软件安装教程
- python模块——hashlib模块(简单文件摘要算法实现)
- python之os模块
- python实现线性排序算法-计数排序
- 【21天学习经典算法】插入排序(附Python完整代码)
- Python 实现插入排序算法
- 【Python 八股文】- 常见的排序算法
- TF-IDF的算法原理以及Python实现
- 机器学习算法与Python实践之(四)支持向量机(SVM)实现
- 华为OD机试 - 篮球比赛(Python) | 机试题+算法思路+考点+代码解析 【2023】
- 华为OD机试 - 求数组中最大n个数和最小n个数的和(Python) | 机试题+算法思路+考点+代码解析 【2023】
- 华为OD机试 - 判断牌型(Python) | 机试题+算法思路+考点+代码解析 【2023】
- 华为OD机试 - 勾股数(Python) | 机试题+算法思路+考点+代码解析 【2023】
- 最小均方算法(lsm)-python代码实现
- Python数据结构与算法(4)--递归
- Python 基础 之 python 协程知识点整理,并实现一个简单 gevent 的协程并发图片下载的应用
- 数据结构和算法:Python实现二分查找(Binary_search)
- Python编程基础:实验3——字典及集合的使用