
9. ubuntu16.04安装配置confluent平台并使用Kafka、KSQL进行流式操作
前置环境配置
通过与Confluent Schema Registry集成,ksqlDB可以以Avro格式读写消息 。ksqlDB会根据需要自动检索(读取)和注册(写入)Avro模式,这使您不必手动在SQL中定义列和数据类型以及与Schema Registry进行手动交互。
操作指南
I. 单机搭建
参考文章:
Confluent Platform安装配置和常用操作详细教程
II. 集群搭建
1、创建数据存储目录
由于/tmp目录存在删除风险,自建一个目录
mkdir <confluent-path>/data
cd ./data
mkdir <confluent-path>/data/zookeeper
mkdir <confluent-path>/data/kafka
mkdir <confluent-path>/data/control-center
2、配置zookeeper
vim etc/kafka/zookeeper.server
更改配置文件
tickTime=2000
dataDir=<confluent-path>/data/zookeeper
clientPort=2181
initLimit=5
syncLimit=2
server.1=host1:2888:3888
server.2=host2:2888:3888
server.3=host3:2888:3888
autopurge.snapRetainCount=3
autopurge.purgeInterval=24
initLimit和syncLimit控制followingZooKeeper服务器初始化当前leader需要多长时间和leader不同步的时间需要多长时间。
autopurge.snapRetainCount和autopurge.purgeInterval被设置为每24小时清除3个snapshots之外的所有快照。
server.<myid>=<hostname>:<leaderport>:<electionport>
其中每个机器上的<myid>与下方的相同,hsotname为对应机器的IP地址
导航到ZooKeeper日志目录(例如<confluent-path>/datazookeeper)并创建一个名为myid的文件。myid文件由一行组成,其中在<machine-id>中包含有格式为的机器ID。当ZooKeeper服务器启动时,它通过引用myid文件知道它是哪个服务器。例如,服务器1的myid值为1。
具体详情可参考:
6、多节点集群环境下Kafka的Confluent Platform的下载安装配置手册
启动
./bin/zookeeper-server-start etc/kafka/zookeeper.properties
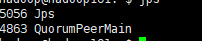
启动成功
3、配置Kafka
vim etc/kafka/server.properties
更改配置文件
# The ID of the broker. This must be set to a unique integer for each broker.
#broker.id=0
broker.id.generation.enable=true
log.dirs=<confluent-path>/data/kafka
zookeeper.connect=host1:2181,host2:2181,host3:2181
advertised.listeners=PLAINTEXT://本机IP:9092
num.partitions=1
##备份因子数<=kafka节点数,若大于会报错
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
listeners与advertised.listeners可以只配一个,与当前机器网卡有关系,请注意。advertised.listeners可能通用性更强,值为当前机器的ip与端口,其他机器ip无需配置
启动
./bin/kafka-server-start etc/kafka/server.properties`
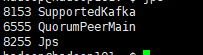
启动成功
若出现以下错误:
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c0000000, 1073741824, 0) failed; error='Not enough space' (errno=12)
#
#There is insufficient memory for the Java Runtime Environment to continue.
#Native memory allocation (mmap) failed to map 1073741824 bytes for committing reserved memory.
#An error report file with more information is saved as:# /home/hadoop/confluent/confluent-5.2.3/hs_err_pid8070.log
这是由于内存不足导致,解决方法:
ava HotSpot™ 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c0000000, 1073741824, 0) failed; error=‘Cannot allocate memory’ (errno=12)
4、配置Schema-registry
vim etc/schema-registry/schema-registry.properties
更改配置文件
kafkastore.connection.url=host1:2181,host2:2181,host3:2181
启动
bin/schema-registry-start etc/schema-registry/schema-registry.properties
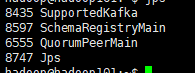
成功启动
5、配置ksql
vim etc/ksql/ksql-server.properties
更改配置文件
bootstrap.servers=host1:9092,host2:9092,host3:9092
listeners=http://0.0.0.0:8088
ksql.schema.registry.url=http://host1:8081,http://host2:8081,http://host3:8081
启动服务
bin/ksql-server-start etc/ksql/ksql-server.properties
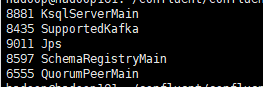
启动ksql
bin/ksql http://10.205.151.145:8088
或者直接
bin/ksql

启动成功
其余参考文章:
Kafka Confluent安装部署
相关文章
- kafka安装配置
- kafka安装配置
- kafka学习之-雅虎开源管理工具Kafka Manager
- 利用flume+kafka+storm+mysql构建大数据实时系统
- Kafka压测— 搞垮kafka的方法(转)
- Windows平台整合SpringBoot+KAFKA__第2部分_代码编写前传
- centos8安装kafka(单机方式)
- 大数据基础之Flume(2)应用之kafka-kudu
- 大数据基础之Kafka(1)简介、安装及使用
- docker安装kafka及使用
- kafka 第一次小整理(草稿篇)————演变[二]
- kafka安装、配置、启动、常用命令及shell启动脚本编写
- kafka安装(版本kafka_2.11-0.11.0.0)
- kafka详解一、Kafka简介
- kafka详解三:开发Kafka应用
- KAFKA EAGLE 监控MRS kafka之操作实践
- 来吧,1分钟带你玩转Kafka
- kafka.common.KafkaException: Failed to acquire lock on file .lock in /tmp/kafka-logs. A Kafka instance in another process or thread is using this directory.
- 【云原生 | Kubernetes 系列】---Kafka 集群安装配置手册
- linux下安装kafka
- docker-搭建单机 kafka+zookeeper
- centos7安装kafka 转
- Linux安装Kafka
- linux 下安装 php kafka 扩展
- 大数据Hadoop之——Kafka鉴权认证(Kafka kerberos认证+kafka账号密码认证+CDH Kerberos认证)
- Python kafka操作实例(kafka-python)
- Kafka 消息不丢失
- 解开Kafka神秘的面纱(四):kafka stream及interceptor
- 部署ELK+Kafka+Filebeat日志收集分析系统