
linux 软中断 和 tasklet
中断的分类
中断分为硬中断和软中断,其分类依据是实现机制,而不是触发机制,比如CPU硬中断,它是由CPU这个硬件实现的中断机制,但它的触发可以通过外部硬件(比如GPIO),软件的 INT 指令,或者CPU执行检测(访问非法地址、除法异常)。一些资料会把以上三种方式做区分,把INT n这种方式叫做软件中断,因为是由软件程序主动触发的,把中断和异常叫做硬件中断,因为他们都是硬件自动触发的。关于硬中断的具体实现,就是 CPU 在每一条指令周期的最后,都会留一个CPU时钟周期去查看是否有中断,如果有,就把中断号取出,去中断向量表中寻找中断处理程序,然后跳过去执行。
类似地,软中断是由软件实现的中断,是纯粹由软件实现的一种类似中断的机制,实际上是模仿硬件,在内存中存储着一组软中断的标志位,然后由内核的一个进程检查这些标志位,如果有哪个标志位有效,则再去执行这个软中断对应的中断处理程序。
软中断
Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部:
- 上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。
- 下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。
上半部会打断CPU正在执行的任务,然后立即执行中断处理程序。而下半部以内核线程的方式执行,并且每个CPU对应一个软中断内核线程,名字为“ksoftirqd/CPU编号”,比如说, 0 号 CPU 对应的软中断内核线程的名字就是 ksoftirqd/0。可以并发运行在多个CPU上(即使同一类型的也可以),所以软中断必须设计为可重入的函数(允许多个CPU同时操作),因此也需要使用自旋锁来保其数据结构。
软中断不只包括了硬件设备中断处理程序的下半部,一些内核自定义的事件也属于软中断,比如内核调度和 RCU 锁等
proc 文件系统。它是一种内核空间和用户空间进行通信的机制,可以用来查看内核的数据结构,或者用来动态修改内核的配置。其中:
- /proc/softirqs提供了软中断的运行情况;
- /proc/interrupts 提供看硬中断的运行情况。
软中断(softirq) 之所以性能高的原因,在 SMP 系统下多个 cpu 同时并发处理,并且软中断上下文不会调用任何阻塞接口。如网卡的 fifo 半满中断触发,被 cpu0 处理,cpu0 会在关闭中断后,将数据从网卡的 fifo 拷贝到 ram 之后触发软中断,再打开中断,基于谁触发谁处理原则,cpu0 会继续执行软中断服务函数。若网卡的 fifo 全满中断有再次触发,就会被 cpu1 处理,同样是关闭中断后拷贝数据再开启中断,再去触发和执行软中断进行网卡数据包处理。若此时 cpu0\cpu1 都还在软中断处理数据,网卡再次产生中断,那么 cpu2 就会继续相同的流程。由此可见,软中断充分利用的多 cpu 进行并发处理,因此性能非常高,但也同时因为并发的存在,就需要考虑临界区的问题。
内核代码分析
软中断类型
enum { HI_SOFTIRQ=0, TIMER_SOFTIRQ, NET_TX_SOFTIRQ, NET_RX_SOFTIRQ, BLOCK_SOFTIRQ, IRQ_POLL_SOFTIRQ, TASKLET_SOFTIRQ, SCHED_SOFTIRQ, HRTIMER_SOFTIRQ, RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */ NR_SOFTIRQS };
软中断模块的初始化,默认开启 HI_SOFTIRQ 和 TASKLET_SOFTIRQ 的软中断
void __init softirq_init(void) { int cpu; for_each_possible_cpu(cpu) { per_cpu(tasklet_vec, cpu).tail = &per_cpu(tasklet_vec, cpu).head; per_cpu(tasklet_hi_vec, cpu).tail = &per_cpu(tasklet_hi_vec, cpu).head; } open_softirq(TASKLET_SOFTIRQ, tasklet_action); open_softirq(HI_SOFTIRQ, tasklet_hi_action); }
开启特定类型的软中断
void open_softirq(int nr, void (*action)(struct softirq_action *)) { softirq_vec[nr].action = action; }
触发软中断
void raise_softirq(unsigned int nr) { unsigned long flags; local_irq_save(flags); raise_softirq_irqoff(nr); local_irq_restore(flags); }
实际上即以软中断类型nr作为偏移量置位每cpu变量irq_stat[cpu_id]的成员变量__softirq_pending,这也是同一类型软中断可以在多个cpu上并行运行的根本原因。
static struct smp_hotplug_thread softirq_threads = { .store = &ksoftirqd, .thread_should_run = ksoftirqd_should_run, .thread_fn = run_ksoftirqd, .thread_comm = "ksoftirqd/%u", };
static int smpboot_thread_fn(void *data) { struct smpboot_thread_data *td = data; struct smp_hotplug_thread *ht = td->ht; while (1) { set_current_state(TASK_INTERRUPTIBLE); preempt_disable(); ...if (!ht->thread_should_run(td->cpu)) { preempt_enable_no_resched(); schedule(); } else { __set_current_state(TASK_RUNNING); preempt_enable(); ht->thread_fn(td->cpu); } } }
asmlinkage __visible void __softirq_entry __do_softirq(void) { unsigned long end = jiffies + MAX_SOFTIRQ_TIME; unsigned long old_flags = current->flags; int max_restart = MAX_SOFTIRQ_RESTART; ... current->flags &= ~PF_MEMALLOC; pending = local_softirq_pending(); softirq_handle_begin(); in_hardirq = lockdep_softirq_start(); account_softirq_enter(current); restart: /* Reset the pending bitmask before enabling irqs */... while ((softirq_bit = ffs(pending))) { ... h->action(h); // 执行特定软中断对应的中断服务函数 ... h++; pending >>= softirq_bit; } ... pending = local_softirq_pending(); if (pending) { // 检查是否在上面代码执行期间,软中断被重新置位 if (time_before(jiffies, end) && !need_resched() && --max_restart) // 检查函数执行时间未超时,并且次数未超次数,重新执行中断服务函数 goto restart; wakeup_softirqd(); } ... }
__do_softirq 会遍历执行每个置位的软中断的中断服务函数,执行完后,再次判断是否有在执行中断服务函数期间重新置位的软中断,在 __do_softirq 执行时间未超时,执行次数未超次数的情况下,会再次遍历执行每个置位的软中断的中断服务函数。否则执行wakeup_softirqd,放置到就绪进程的列表末尾,等待调度器下次调度。
tasklet
使用示例模版
#include <linux/module.h> #include <linux/init.h> #include <linux/kernel.h> #include <linux/interrupt.h> static struct tasklet_struct my_tasklet; static void my_tasklet_handle(unsigned long data) { printk("tasklet handle running...\n"); } static irqreturn_t xxx_interrupt(int irq, void *dev_id) { // 调度 tasklet tasklet_schedule(&my_tasklet); } static int __init demo_driver_init(void) { // 初始化一个 tasklet ,关联处理函数 tasklet_init(&my_tasklet, my_tasklet_handle, 0); request_irq(xxx, xxx_interrupt, IRQF_SHARED, xxx, xxx); return 0; } static void __exit demo_driver_exit(void) { tasklet_kill(&my_tasklet); return ; } module_init(demo_driver_init); module_exit(demo_driver_exit); MODULE_LICENSE("GPL v2");
软中断和 tasklet 的关系:
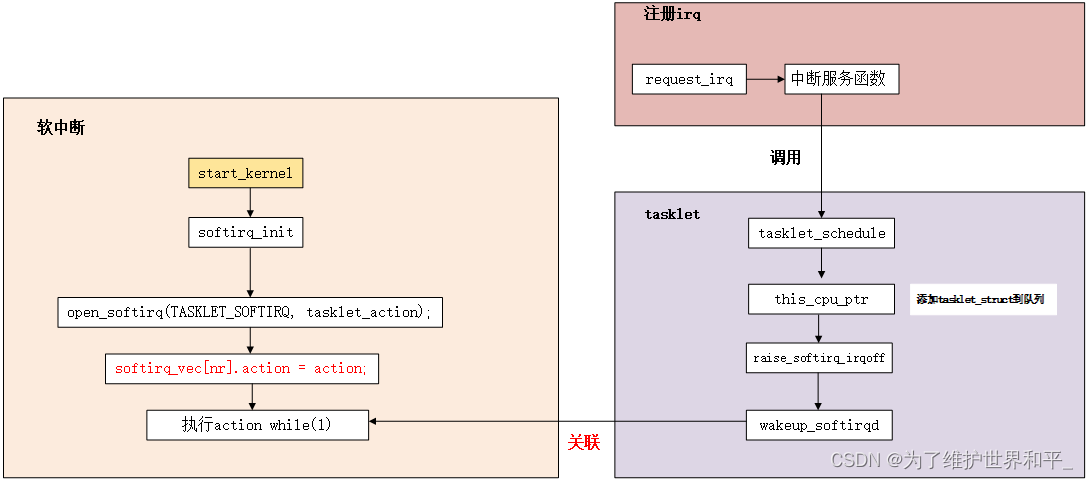
由于软中断必须使用可重入函数,这就导致设计上的复杂度变高,临界区必须用自旋锁保护。因为多个处理器可以同时且独立地处理软中断,同一个软中断的处理程序例程可以在几个 CPU 上同时运行。作为设备驱动程序的开发者来说,增加了负担。而如果某种应用并不需要在多个CPU上并行执行,那么软中断其实是没有必要的。tasklet具有以下特性:
- 一种特定类型的tasklet只能运行在一个CPU上,不能并行,只能串行执行。
- 多个不同类型的tasklet可以并行在多个CPU上。
- 从软中断的实现机制可知,软中断是静态分配的,在内核编译好之后,就不能改变。但tasklet就灵活许多,可以在运行时改变(比如添加模块时)。
tasklet是在两种软中断类型的基础上实现的,如果不需要软中断的并行特性,tasklet就是最好的选择。也就是说tasklet是软中断的一种特殊用法,即延迟情况下的串行执行。
内核源码分析
softirq_init 执行时,为 TASKLET_SOFTIRQ 软中断与 tasklet_action() 建立关联的关系,因此软中断触发时,就会调用 tasklet_action()。
通过将 struct tasklet_struct 实例添加到链表,执行实例对应的函数
struct tasklet_struct { struct tasklet_struct *next; unsigned long state; atomic_t count; bool use_callback; union { void (*func)(unsigned long data); void (*callback)(struct tasklet_struct *t); }; unsigned long data; };
- next: 指向下一个tasklet的指针
- state: 定义了这个tasklet的当前状态。这一个32位的无符号长整数,当前只使用了bit[TASKLET_STATE_RUN]和bit[TASKLET_STATE_SCHED]两个状态位。其中,bit[TASKLET_STATE_RUN]=1表示这个tasklet当前正在某个CPU上被执行,它仅对SMP系统才有意义,其作用就是为了防止多个CPU同时执行一个tasklet的情形出现;bit[TASKLET_STATE_SCHED]=1表示这个tasklet已经被调度(使用)等待被执行了。
- count: 只有当count等于0时,tasklet代码段才能执行;如果count非零,则这个tasklet是被禁止的
- func: 该 tasklet 对应的函数
- data: func 的入参
当调用 tasklet_schedule() 时,如果该 tasklet 没有被设置 TASKLET_STATE_SCHED 标记时,才会加入链表内,如果已经设置了 TASKLET_STATE_SCHED 了,那么就会忽略此次的 tasklet _schedule(),之后会通过 raise_softirq_irqoff() 启用 TASKLET_SOFTIRQ 软中断。
static inline void tasklet_schedule(struct tasklet_struct *t) { if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state)) __tasklet_schedule(t); } void __tasklet_schedule(struct tasklet_struct *t) { __tasklet_schedule_common(t, &tasklet_vec, TASKLET_SOFTIRQ); } static void __tasklet_schedule_common(struct tasklet_struct *t, struct tasklet_head __percpu *headp, unsigned int softirq_nr) { struct tasklet_head *head; unsigned long flags; local_irq_save(flags); head = this_cpu_ptr(headp); t->next = NULL; *head->tail = t; head->tail = &(t->next); raise_softirq_irqoff(softirq_nr); local_irq_restore(flags); }
tasklet_schedule 的 if 判断分支保证,tasklet 被添加到某个 cpu 的链表后,未执行 tasklet 对应的函数前不会再被添加到某个 cpu 的链表
执行 __tasklet_schedule_common,tasklet 只会加入到当前 cpu 的 tasklet 链表内,添加到链表的过程如下:

添加完链表,就执行该软中断类型对应的中断服务函数
static __latent_entropy void tasklet_action(struct softirq_action *a) { tasklet_action_common(a, this_cpu_ptr(&tasklet_vec), TASKLET_SOFTIRQ); } static void tasklet_action_common(struct softirq_action *a, struct tasklet_head *tl_head, unsigned int softirq_nr) { struct tasklet_struct *list; local_irq_disable(); list = tl_head->head; // 获取 tasklet 链表 tl_head->head = NULL; // 清空 tasklet 链表,即 tasklet_vec tl_head->tail = &tl_head->head; local_irq_enable(); while (list) { struct tasklet_struct *t = list; list = list->next; // TASKLET_STATE_SCHED: 表示该 tasklet 已经被挂接到某个 CPU 上
// TASKLET_STATE_RUN: 表示该 tasklet 正在某个 CPU 上执行
// 检查并设置 TASKLET_STATE_RUN 标记,返回 1: 表示 tasklet 没有被执行 返回 0: 表示 tasklet 已经被执行 if (tasklet_trylock(t)) { if (!atomic_read(&t->count)) { // 如果当前 tasklet 没有被 tasklet_disable() if (tasklet_clear_sched(t)) { // 清除 TASKLET_STATE_SCHED 状态,便于该 tasklet 可以再次被添加到某个 cpu 的链表中
// 这期间,该 tasklet 可以被 tasklet_schedule()并添加到某个 cpu 的链表中,从而引出下面第二种情况 if (t->use_callback) t->callback(t); else t->func(t->data); // 如果没有执行且没有 disable 则执行 } tasklet_unlock(t); // 清理 TASKLET_STATE_RUN 标记 continue; // 继续下一个 tasklet } tasklet_unlock(t);// 如果当前已经被 disable 了,那就清理 TASKLET_STATE_RUN 标记 }
// 有两种情况下,会将该 tasklet 再挂接回链表内,并重新触发,等待下一次执行的机会
// 1. 如果没有被执行,但是被调用 tasklet_disable() 接口 disable 了
// 2. 当前 tasklet 正在某 CPU 执行 func,这时候 tasklet 又被挂到某个 cpu 的
// 链表中并准备执行 tasklet 对应的函数,为了满足同一个 tasklet 只能在一个 CPU 上执行的设计原则
// 因此此次不执行 tasklet,挂入链表后等待下一次被执行的时机执行
local_irq_disable(); t->next = NULL; *tl_head->tail = t; tl_head->tail = &t->next; __raise_softirq_irqoff(softirq_nr); local_irq_enable(); } }
tasklet_kill() 主要实现是尽可能快的让 tasklet 得到执行,等待执行完成后再退出
void tasklet_kill(struct tasklet_struct *t) { if (in_interrupt()) pr_notice("Attempt to kill tasklet from interrupt\n"); while (test_and_set_bit(TASKLET_STATE_SCHED, &t->state)) wait_var_event(&t->state, !test_bit(TASKLET_STATE_SCHED, &t->state)); tasklet_unlock_wait(t); tasklet_clear_sched(t); } void tasklet_unlock_wait(struct tasklet_struct *t) { wait_var_event(&t->state, !test_bit(TASKLET_STATE_RUN, &t->state)); }
tasklet 机制总结
1. 每颗 cpu 都有自己的 tasklet 链表,这样可以将 tasklet 分布在各个 cpu 上,可实现并发不同的 tasklet。
2. 相同的 tasklet 只能在某一颗 cpu 上串行执行,其它 cpu 会暂时避让,在此情况下,不需要考虑并发问题(即不需要加锁)。
3. tasklet_schedule() 接口调用时,如果 tasklet 还未被执行,或者处于 disable 期间,指定的 tasklet 不会被加入链表内,即该请求不会被受理。
4. tasklet_disable() 接口只是暂时停止指定的 tasklet 执行,依然会被加回待执行链表内。而在 disable 期间,相同的 tasklet 将无法被加入链表调度。
相关文章
- Linux 典型应用之缓存服务
- linux Python-安装sasl包的错误
- Linux安装 微信开发者工具(deepin linux ubt)
- 用linux mail命令发送邮件[Linux]
- 12款Linux终端替代品
- Linux 有问必答: 如何在红帽系linux中编译Ixgbe驱动
- 10 条真心有趣的 Linux 命令
- 【Linux】linux中自动定时备份mysql数据
- linux 结束某个进程,并且结束子进程
- 《嵌入式Linux开发实用教程》——1.3 arm-linux交叉编译链
- 《树莓派渗透测试实战》——第1章 树莓派和Kali Linux基础知识 1.1 购买树莓派
- 配置Linux内核
- Linux应用开发(八)——中断体系结构
- linux字符设备概念
- linux内核中socket的创建过程源码分析(详细分析)
- 【Linux编辑神器:vim】
- Linux基础:文件基础属性及如何更改文件属性、文件与目录管理、linux软硬链接的理解、linux用户和用户组管理
- Linux基础:系统启动过程(5个阶段)、linux关机正确流程及常用实例命令、linux目录结构(常见目录解释及目录的分类介绍)
- Linux曝新漏洞 按住Enter键70秒可触发
- Linux下区分物理CPU、逻辑CPU和CPU核数
- Linux学习笔记(25)linux批量管理
- Linux学习笔记(19)linux定时任务(crontab)
- Linux学习笔记(10)linux网络管理与配置之一——主机名与IP地址,DNS解析与本地hosts解析(1-4)
- 如何看linux是32位还是64位--转
- 国产化项目Debian系Linux离线安装docker