
【哈工大李治军】操作系统课程笔记4:CPU和多进程 + 【实验 4】进程运行轨迹的跟踪与统计实验
操作系统在管理CPU的时候引出了多进程图像,通过多进程图像操作系统管理明白了CPU,CPU管理明白了别的硬件自然而然的就跟着带动起来了,所以多进程图像是操作系统的核心图像。
因为多进程的引入是为了管理好CPU,所以我们就先介绍CPU的管理方法。
1、CPU的工作原理

如图中所示,当PC=50时,CPU就会发出取址指令,把50放在地址总线上,当内存接收到信号后,就会将把位于地址50里的指令通过总线再传送给CPU。CPU得到该指令后,就会根据指令中的内容执行。
总结: 自动地取址、执行(PC自动累加)

CPU的管理方法就是把PC的初值设置为一段程序的开始地址,之后PC就会自动地累加工作,进行取值执行。

上图中的程序中,有I/O指令执行一条语句再比上没有I/O指令执行一条语句大约的比值是
1
0
6
10^6
106。
I/O指令会涉及磁盘的存取,因此I/O指令相对于其他计算指令来说执行起来会非常慢。如果CPU一直在等待I/O完成后,才去继续工作就会造成CPU的利用率非常的低。所以,为了提高CPU的利用率,可以在电脑进行I/O操作时,让CPU先去执行其他任务,当I/O操作完成后,再回来执行对应的后续操作。

当多个程序在内存中,通过切换程序,来减少CPU的空闲时间,提高CPU的利用率。

多道程序交替执行就会让CPU忙碌起来。
某一设备的利用率=某一设备使用时间 / 全部程序的执行时间

多道程序交替执行就成为了管理CPU的核心。一个CPU上交替的执行多个程序,就引入了并发的概念。实现的方式就是在适当的时候让PC进行切换。

在切换前,要记录好之前所执行程序的相关信息(程序执行到哪里、执行的样子等等),即程序在当前时刻下执行时的样子。此时运行的程序和静态程序不一样了。

因为静态程序和运行的程序情况不一样了,我们就单独把运行的程序拿出来当作一个事物,而这个事物用传统的观念不能很方便的去描述解决,就引入“进程”(这个概念去刻画这个新事物。
进程是进行(执行)中的程序。 这些与静态程序不一样的地方都存放在了一个新的数据结构PCB当中。
当CPU开始跑多个进程,而不是按顺序执行静态程序时,就大大提高了CPU的利用率。多个进程向前跑的样子,就是管理CPU的核心样子。
2、多进程图像


操作系统从刚开机时就形成了多进程图像,直到关机为止。
if(!fork()) { init(); }使用fork()创建了一个进程,该进程执行了init(),启动了一个shell。
其中shell的核心代码就是while(1)循环中,当用户再输入一句命令后,又会创建一个新的子进程并根据输入的命令进行执行。(用户执行任务也是创建一个进程,用于完成用户指定的任务)
实际上,用户启用计算机就是启用一堆进程,用户管理计算机就是管理一堆进程。
(1)如何组织多进程

PCB帮助操作系统感知和形成进程。使用PCB来形成一些队列,来组织多进程。多个进程所对应的PCB分别放置在不同的地方,通过队列连接起来。操作系统拥有它们的存储位置信息,可到对应位置进行获取。

把进程根据状态来区分开来,便于操作系统的管理。
区分阻塞态和就绪态:
(1)阻塞态:进程停止,缺必要的资源,给CPU调度机会也不能运行。
- 事件:
- 等待资源(临界资源、临界区)
- 信息交换(I/O输入输出、读写内存)
- 进程同步(停下来等待其他进程)
(2)就绪态:进程停止,资源都不缺,只缺CPU调度,给CPU调度就能运行
- 事件:
- 阻塞的进程获得等待的资源或信号 (阻塞态 —> 就绪态)
- 时间片轮转的情况下,进程的时间片用完了 (运行态 —> 就绪态)
- CPU调度给优先级更高的进程 (运行态 —> 就绪态)
(2)如何切换多进程
1)队列操作

保存现场状态,将进程放到阻塞队列或就绪队列中,再根据调度规则从就绪队列中调度一个进程来执行。
3)调度

3)切换

假设正在执行进程为p1,对应PCB1,要切换到的进程为p2,对应PCB2。
当要进行进程切换时,先通过赋值的方式,将当前CPU里的信息保存到PCB1之中。然后再将PCB2中的信息,赋值给CPU,从而完成了从p1进程到p2进程的切换。
(3)如何解决多进程交替时的相互影响?

当多个进程同时存在于内存时,可能会出现访问统一资源并对该资源进行改写的问题。这时,就需要限制对该资源对应的地址的读写操作。

通过映射表来实现地址空间的分离。
映射表是内存管理的核心!

进程1访问100地址时,经过映射表后得到的物理内存地址是782,进程2访问100地址时,得到的物理内存地址时1260,实现了多个进程各自只能访问各自的内存空间而互不影响,从而实现了多进程共存。而只有共存的进程,才可以进程交替执行,也就相当于进程共存为进程的交替执行提供了条件。
(4)如何让多进程合作?

进程1和进程2合作执行时,可能会出现同时修改7地址这个位置。



想要完成多进程的合作,核心在于进程同步(合理的推进顺序),在使用临界资源时将其上锁。
(5)总结

总结
进程的四个任务
(1)PCB是OS中最重要的结构,贯穿始终,解决了如何组织多进程。
(2)写调度程序,解决了如何调度多进程(调度规则)。
(3)操作寄存器完成切换,解决如何切换多进程(PCB与CPU信息)。
(4)进程同步与合作,要有地址映射,解决了如何解决多进程相互的影响与合作。(映射表、同步与互斥)
[实验 4]:进程运行轨迹的跟踪与统计
(1)使用fork()编写process.c
实现如下功能: + 所有子进程都并行运行,每个子进程的实际运行时间一般不超过 30 秒; + 父进程向标准输出打印所有子进程的 id,并在所有子进程都退出后才退出;




1. fork功能特点:
fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
1)在父进程中,fork返回新创建子进程的进程ID;
2)在子进程中,fork返回0;
3)如果出现错误,fork返回一个负值;
在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。在子进程中,fork函数返回0,在父进程中,fork返回新创建子进程的进程ID。
我们可以通过fork返回的值来判断当前进程是子进程还是父进程。
2. fork出错可能有两种原因:
1)当前的进程数已经达到了系统规定的上限,这时errno的值被设置为EAGAIN。
2)系统内存不足,这时errno的值被设置为ENOMEM。
创建新进程成功后,系统中出现两个基本完全相同的进程,这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略。
*问题一:fork()返回两个不同值的原因:
首先必须有一点要清楚,函数的返回值是储存在寄存器eax中的。其次,当fork返回时,新进程会返回0是因为在初始化任务结构时,将eax设置为0。将eax设置为0的作用是为了让子进程执行if(!fork())里的语句,从而实现父子进程的分离,各自执行各自的代码。而父进程里的eax值,则为子进程的id。同时,进程的id一定不会为0,若返回0,则也可用来区分子进程和父进程,可谓是一举两得。
3. N个循环创建子进程
生成的父子进程满足如下图中的的树状关系:

一生二、二生四…
printf()输出的数量满足
2
∗
(
1
+
2
2
+
2
3
+
.
.
.
+
2
n
−
1
)
=
2
+
2
2
+
2
3
+
.
.
.
+
2
n
2*(1 + 2^2 + 2^3 + ... + 2^{n-1}) = 2 + 2^2 + 2^3 + ... +2^n
2∗(1+22+23+...+2n−1)=2+22+23+...+2n 这个等比数列的关系。
修改process.c
#include <stdio.h>
#include <unistd.h>
#include <time.h>
#include <sys/times.h>
#define HZ 100
void cpuio_bound(int last, int cpu_time, int io_time);
int main(int argc, char * argv[])
{
int i, j, n = 3;
time_t stime, etime;
pid_t n_proc;
for(i = 0; i < n; i++) {
n_proc = fork();
if(n_proc == 0) {
time(&stime);
cpuio_bound(20, 8*i, 20-8*i);
time(&etime);
printf("I am a son. i:%d pid:%d ppid:%d , Run the CPU and I/O for %d\n", i, getpid(), getppid(), etime - stime);
}else if(n_proc > 0) {
printf("I am a parent. i:%d pid:%d ppid:%d cip:%d \n", i, getpid(), getppid(), n_proc);
/*等待所有子进程完成*/
wait(&j); /*Linux 0.11 上 gcc要求必须有一个参数, gcc3.4+则不需要*/
}else if(n_proc < 0) {
printf("Failed to fork child process i:%d pid:%d\n", i, n_proc);
}
}
return 0;
}
/*
* 此函数按照参数占用CPU和I/O时间
* last: 函数实际占用CPU和I/O的总时间,不含在就绪队列中的时间,>=0是必须的
* cpu_time: 一次连续占用CPU的时间,>=0是必须的
* io_time: 一次I/O消耗的时间,>=0是必须的
* 如果last > cpu_time + io_time,则往复多次占用CPU和I/O
* 所有时间的单位为秒
*/
void cpuio_bound(int last, int cpu_time, int io_time)
{
struct tms start_time, current_time;
clock_t utime, stime;
int sleep_time;
while (last > 0)
{
/* CPU Burst */
times(&start_time);
/* 其实只有t.tms_utime才是真正的CPU时间。但我们是在模拟一个
* 只在用户状态运行的CPU大户,就像“for(;;);”。所以把t.tms_stime
* 加上很合理。*/
do
{
times(¤t_time);
utime = current_time.tms_utime - start_time.tms_utime;
stime = current_time.tms_stime - start_time.tms_stime;
} while ( ( (utime + stime) / HZ ) < cpu_time );
last -= cpu_time;
if (last <= 0 )
break;
/* IO Burst */
/* 用sleep(1)模拟1秒钟的I/O操作 */
sleep_time=0;
while (sleep_time < io_time)
{
sleep(1);
sleep_time++;
}
last -= sleep_time;
}
}
注: 对 wait() 的调用会阻止调用进程,直到它的一个子进程退出或收到信号为止。子进程终止后,父进程在wait系统调用指令后继续执行。
如果不加wait(),父进程没有等待子进程执行结束就会自动退出,就会出现如下情况

父进程先执行完毕后,还未结束的子进程会成为孤儿进程,而被pid=2655的进程给收养。
当加入wait()后,会得到我们想要的结果

每次循环时父进程会创建一个子进程,然后子进程会拷贝父进程之前的代码信息,比如i的值,而继续往下循环作为父进程而创建自己的子进程。
可发现pid=103077和ppid=31455的进程,都是程序刚开始执行父进程产生的信息。
当注释掉父进程中时间统计信息和子进程中输出信息后,再次执行
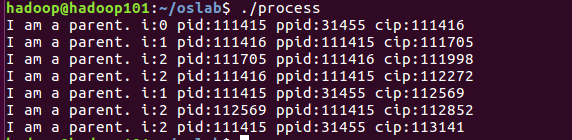
得到实验要求输出每个父进程的子进程信息。
在linux0.11下执行

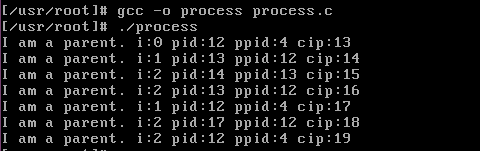
CPU时间 = 用户CPU时间 + 系统CPU时间,即命令占用CPU执行的时间总和。实际时间要大于CPU时间,因为Linux是多任务操作系统,往往在执行一条命令时,系统还要处理其他任务。另一个需要注意的问题是即使每次执行相同的命令,所花费的时间也不一定相同,因为其花费的时间与系统运行相关。
(2)使用log记录进程状态
在 Linux0.11 上实现进程运行轨迹的跟踪。 + 基本任务是在内核中维护一个日志文件 /var/process.log,把从操作系统启动到系统关机过程中所有进程的运行轨迹都记录在这一 log 文件中。
规定进程的状态为N,J,R,W和E中的一个
- N 创建
- J 就绪态
- R 运行态
- W 阻塞态
- E 退出
1)main.c解析
main.c实现了以下功能:
- 使用
setup.s获得系统参数进行内核初始化,完成初始化后,内核将执行权切换到了用户模式,即CPU从0特权级到第3特权级; main.c先对内核进行初始化,完成后把自己“手工”移动到了任务0中,然后系统第一次调用fork()函数创建出一个用于运行init()的子进程创建出进程1(init进程);


在整个内核完成初始化后,内核将执行权切换到了用户模式(任务0),也就是CPU从0特权级切换到了第3特权级。此时main.c的主程序就工作在任务0中。然后,系统第一次调用进程创建函数fork(),创建出一个用于运行init()的子进程(通常被称为init进程)


init()函数的功能可分为4个部分:- 安装根文件系统;
- 显示系统信息;
- 运行系统初始化资源配置文件rc中的命令;
- 执行用户登录shell程序。









init()




2)在main.c中添加文件描述符与关联log文件


Linux将所有内核对象当做文件来处理,系统用一个size_t类型来表示一个文件对象,比如对于文件描述符0就表示系统的标准输入设备STDIN,通常情况下STDIN的值为键盘,如read命令就默认从STDIN读取数据,当然STDIN的值是可以改变的,比如将其改成其他文件,这样的话想read等命令就会默认从相应的文件读取数据了。
简单地说,一个文件描述符可以和一个文件挂钩,一旦挂钩就可以通过取地址运算符&获得该文件的句柄,比如&0就可以获得STDIN设备在内存中的句柄(设备在系统中也被当做文件处理),可以这样理解,如果是一个shell中的普通变量var,可以通过$var的形式获得该变量所代表的值,而对于一个文件描述符fd,则可以通过&fd的形式获得文件描述符指向的文件的句柄,而这个句柄可以简单地理解成该文件的路径。
每个进程启动时默认都会有三个标准的文件描述符:
stdin 0 号描述符, 代表输入设备, 进程从它读入数据;stdout 1 号描述符, 进程往其中写入数据;stderr 2 号描述符, 进程会往其中写入错误信息。
这三个描述符默认是对应同一个 tty 设备, 这样我们便可以在终端中输入数据和获取进程的输出。
Linux中的文件描述符是什么,Bash中文件描述符的详细介绍

//……
move_to_user_mode();
/***************添加开始***************/
setup((void *) &drive_info);
// 建立文件描述符0和/dev/tty0的关联
(void) open("/dev/tty0",O_RDWR,0);
//文件描述符1也和/dev/tty0关联
(void) dup(0);
// 文件描述符2也和/dev/tty0关联
(void) dup(0);
// 建立文件描述符3和/var/process.log的关联
(void) open("/var/process.log",O_CREAT|O_TRUNC|O_WRONLY,0666);
/***************添加结束***************/
if (!fork()) { /* we count on this going ok */
init();
}
//……
打开 log 文件的参数的含义是建立只写文件,如果文件已存在则清空已有内容。文件的权限是所有人可读可写。
这样,文件描述符 0、1、2 和 3 就在进程 0 中建立了。根据 fork() 的原理,进程 1 会继承这些文件描述符,所以 init() 中就不必再 open() 它们。此后所有新建的进程都是进程 1 的子孙,也会继承它们。 但实际上,init() 的后续代码和 /bin/sh 都会重新初始化它们。所以只有进程 0 和进程 1 的文件描述符肯定关联着 log 文件,这一点在接下来的写 log 中很重要。
文件描述符拓展资料:
文件描述符stdin,stdout,stderr,重定向
在~/oslab/linux-0.11/init/main.c的main()中添加内容

同时,也要把init()里的打开文件描述符注释掉

3)在kernel/printk.c中添加写函数
log 文件将被用来记录进程的状态转移轨迹。所有的状态转移都是在内核进行的。
在内核状态下,write() 功能失效,其原理等同于《系统调用》实验中不能在内核状态调用 printf(),只能调用 printk()。编写可在内核调用的 write() 的难度较大,所以这里直接给出源码。它主要参考了 printk() 和 sys_write() 而写成的:
#include "linux/sched.h"
#include "sys/stat.h"
static char logbuf[1024];
int fprintk(int fd, const char *fmt, ...)
{
va_list args;
int count;
struct file *file;
struct m_inode *inode;
va_start(args, fmt);
count = vsprintf(logbuf, fmt, args);
va_end(args);
if (fd < 3) /* 如果输出到stdout或stderr,直接调用sys_write即可 */
{
__asm__("push %%fs\n\t"
"push %%ds\n\t"
"pop %%fs\n\t"
"pushl %0\n\t"
"pushl $logbuf\n\t"
"pushl %1\n\t"
"call sys_write\n\t"
"addl $8, %%esp\n\t"
"popl %0\n\t"
"pop %%fs"
::"r" (count), "r" (fd)
:"ax", "cx", "dx");
}
else /* 假定>=3的描述符都与文件关联。事实上,还存在很多其他情况,这里并没有考虑 */
{
if (!(file=task[0]->filp[fd])) /* 从进程0的文件描述符表中得到文件句柄 */
return 0;
inode = file->f_inode;
__asm__("push %%fs\n\t"
"push %%ds\n\t"
"pop %%fs\n\t"
"pushl %0\n\t"
"pushl $logbuf\n\t"
"pushl %1\n\t"
"pushl %2\n\t"
"call file_write\n\t"
"addl $12, %%esp\n\t"
"popl %0\n\t"
"pop %%fs"
::"r" (count), "r" (file), "r" (inode)
:"ax", "cx", "dx");
}
return count;
}
因为和 printk 的功能近似,建议将此函数放入到 ~/oslab/linux-0.11/kernel/printk.c 中。


fprintk() 的使用方式类同与 C 标准库函数 fprintf(),唯一的区别是第一个参数是文件描述符,而不是文件指针。
例如:
// 向stdout打印正在运行的进程的ID
fprintk(1, "The ID of running process is %ld", current->pid);
// 向log文件输出跟踪进程运行轨迹
fprintk(3, "%ld\t%c\t%ld\n", current->pid, 'R', jiffies);
4)kernel/sched.c解析


在schedule()中设置三个指针的目的是实现当前进程进入阻塞状态,让tmp指向原等待任务队列的对头,用原等待任务的头指针p指向当前进程,让current指向新任务进行执行。直至,使用wake_up()时,唤醒原被阻塞的当前进程(变为就绪态)。





5)jiffies解析




6)寻找状态切换点
我们来理一下思路:
首先,修改了初始化文件main.c,让系统一启动就会创建一个process.log,这个文件的路径在~/oslab/hdc/var/(需要挂载虚拟机才看得到);
然后,我们往内核中添加了一个fprintk()函数,使得系统可以向process.log文件进行打印输出。
因此,最后一步,我们需要去寻找系统内核代码的合适位置,插入fprintk(),打印出我们想要的进程状态。
总的来说,Linux 0.11 支持四种进程状态的转移:
就绪到运行、运行到就绪、运行到睡眠和睡眠到就绪,此外还有新建和退出两种情况。

例子 1:记录一个进程生命期的开始 copy_process

kernel/system_call.s

fork.c







TASK_RUNNING : 表示 执行状态 或 就绪状态 ;
该进程可以执行 , 或者已经准备就绪 , 随时开始执行 ;
Linux 内核中 , 没有对执行状态 / 就绪状态 进行明确的区分 ;

这里要输出两种状态,分别是“N(新建)”和“J(就绪)”。
修改kenel/fork.c中copy_process
/* ... */
p->start_time = jiffies;
/*因为更新了启动时间,这里就是一个进程的新建*/
fprintk(3, "%ld\t%c\t%ld\n", p->pid, 'N', jiffies);
/* ... */
p->state = TASK_RUNNING; /* do this last, just in case */
/*上述语句,将一个新建态的进程变为了就绪态的进程,向log文件输出*/
fprintk(3, "%ld\t%c\t%ld\n", p->pid, 'J', jiffies);



拓展资料:
例子 2:记录进入睡眠态的时间 sleep_on()和interruptible_sleep_on()

/* TASK_UNINTERRUPTIBLE和TASK_INTERRUPTIBLE的区别在于不可中断的睡眠
* 只能由wake_up()显式唤醒,再由上面的 schedule()语句后的
*
* if (tmp) tmp->state=0;
*
* 依次唤醒,所以不可中断的睡眠进程一定是按严格从“队列”(一个依靠
* 放在进程内核栈中的指针变量tmp维护的队列)的首部进行唤醒。而对于可
* 中断的进程,除了用wake_up唤醒以外,也可以用信号(给进程发送一个信
* 号,实际上就是将进程PCB中维护的一个向量的某一位置位,进程需要在合
* 适的时候处理这一位。感兴趣的实验者可以阅读有关代码)来唤醒,如在
* schedule()中:
*
* for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
* if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&
* (*p)->state==TASK_INTERRUPTIBLE)
* (*p)->state=TASK_RUNNING;//唤醒
*
* 就是当进程是可中断睡眠时,如果遇到一些信号就将其唤醒。这样的唤醒会
* 出现一个问题,那就是可能会唤醒等待队列中间的某个进程,此时这个链就
* 需要进行适当调整。interruptible_sleep_on和sleep_on函数的主要区别就
* 在这里。
*/
void interruptible_sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
…
tmp=*p;
*p=current;
repeat: current->state = TASK_INTERRUPTIBLE;
schedule();
// 如果队列头进程和刚唤醒的进程 current 不是一个,
// 说明从队列中间唤醒了一个进程,需要处理
if (*p && *p != current) {
// 将队列头唤醒,并通过 goto repeat 让自己再去睡眠
(**p).state=0;
goto repeat;
}
*p=NULL;
//作用和 sleep_on 函数中的一样
if (tmp)
tmp->state=0;
}
sleep_on()


修改kenel/sched.c中sleep_on()
void sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
if (!p)
return;
if (current == &(init_task.task))
panic("task[0] trying to sleep");
tmp = *p;
*p = current;
current->state = TASK_UNINTERRUPTIBLE;
/* sleep_on函数,让进程从运行到睡眠,也就是进入到堵塞(W)*/
fprintk(3, "%ld\t%c\t%ld\n", current->pid, 'W', jiffies);
schedule();
if (tmp)
{
tmp->state = 0;
/* 将原等待队列中的第一个进程唤醒(就绪)*/
fprintk(3, "%ld\t%c\t%ld\n", tmp->pid, 'J', jiffies);
}
}

interruptible_sleep_on()


修改kenel/sched.c中interruptible_sleep_on()
void interruptible_sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
if (!p)
return;
if (current == &(init_task.task))
panic("task[0] trying to sleep");
tmp = *p;
*p = current;
repeat:
current->state = TASK_INTERRUPTIBLE;
/* 将当前进程置为可中断睡眠状态,变为阻塞态 */
fprintk(3, "%ld\t%c\t%ld\n", current->pid, 'W', jiffies);
schedule();
if (*p && *p != current) /* 如果队列头进程和刚唤醒的进程current不是一个,说明有新任务被插入了队列头中,刚才是从队列中间唤醒了一个进程,需要处理 */
{
(**p).state = 0; /* 将队列头唤醒,并通过goto repeat让自己再去睡眠 */
/* 将队列头的进程变为就绪态 */
fprintk(3, "%ld\t%c\t%ld\n", (*p)->pid,'J',jiffies);
goto repeat; /* 再跳转,让自己在睡眠 */
}
*p = NULL;
if (tmp)
{
tmp->state = 0;
/* 和slep_on中作用一样,唤醒队列中的上一个(tmp)睡眠进程 */
fprintk(3, "%ld\t%c\t%ld\n", tmp->pid, 'J', jiffies);
}
}

例子 3:记录就绪态变成运行态的时间 schedule()



schedule() 找到的 next 进程是接下来要运行的进程(注意,一定要分析清楚 next 是什么)。如果 next 恰好是当前正处于运行态的进程,switch_to(next) 也会被调用。这种情况下相当于当前进程的状态没变。
对于可中断的进程,除了用wake_up唤醒以外,也可以用信号(给进程发送一个信号,实际上就是将进程PCB中维护的一个向量的某一位置位,进程需要在合适的时候处理这一位。在schedule()中:
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&
(*p)->state==TASK_INTERRUPTIBLE)
(*p)->state=TASK_RUNNING;//唤醒
在kenel\sched.c中修改schedule()
void schedule(void)
{
int i, next, c;
struct task_struct **p;
/* check alarm, wake up any interruptible tasks that have got a signal */
for (p = &LAST_TASK; p > &FIRST_TASK; --p)
if (*p)
{
if ((*p)->alarm && (*p)->alarm < jiffies)
{
(*p)->signal |= (1 << (SIGALRM - 1));
(*p)->alarm = 0;
}
if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&
(*p)->state == TASK_INTERRUPTIBLE)
{
(*p)->state = TASK_RUNNING;
/*从可中断态转换成就绪态*/
fprintk(3, "%ld\t%c\t%ld\n", (*p)->pid, 'J', jiffies);
}
}
/* this is the scheduler proper: */
while (1)
{
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i)
{
if (!*--p)
continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
if (c)
break;
for (p = &LAST_TASK; p > &FIRST_TASK; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) +
(*p)->priority;
}
/* 切换到相同的进程不输出 */
if(current->pid != task[next] ->pid) {
/* 新建修改--时间片到时程序 => 就绪 */
if(current->state == TASK_RUNNING)
fprintk(3, "%ld\t%c\t%ld\n", current->pid, 'J', jiffies);
/* 所选的进程设置为运行状态 */
fprintk(3, "%ld\t%c\t%ld\n", task[next]->pid, 'R', jiffies);
}
/* 切换到 next 进程 */
switch_to(next); /*switch_to是一个宏*/
}
注: schedule() 找到的 next 进程是接下来要运行的进程(注意,一定要分析清楚 next 是什么)。如果 next 恰好是当前正处于运行态的进程,swith_to(next) 也会被调用。这种情况下相当于当前进程的状态没变!
所以,需要加入if(current->pid != task[next] ->pid)来确定切换到的是另外的进程时,才输出进程切换信息。


例子4:记录进程主动睡眠的时间 sys_pause()和sys_waitpid()
进程主动睡觉的系统调用 sys_pause() 和 sys_waitpid()。
sys_pause()


修改kernel/sched.c中的sys_pause()
int sys_pause(void)
{
current->state = TASK_INTERRUPTIBLE;
/*
* 系统无事可做的时候,进程0会不停地调用sys_pause(),以激活调度算法。此时它的状态可以是等待态,
* 等待有其他可运行的进程;也可以是运行态,因为它是唯一一个在CPU上运行的进程,只不过运行的效果是等待。
*/
if (current->pid != 0) {
/* 让当前非0号进程主动睡眠 */
fprintk(3, "%ld\t%c\t%ld\n", current->pid, 'W', jiffies);
}
schedule();
return 0;
}

sys_waitpid()





修改include/exit.c中的sys_waitpid
int sys_waitpid(pid_t pid,unsigned long * stat_addr, int options)
{
......
if (flag) {
if (options & WNOHANG)
return 0;
current->state=TASK_INTERRUPTIBLE;
/* 当前进程进入睡眠变为阻塞状态 */
fprintk(3, "%ld\t%c\t%ld\n", current->pid, 'W', jiffies);
schedule();
if (!(current->signal &= ~(1<<(SIGCHLD-1))))
goto repeat;
else
return -EINTR;
}
return -ECHILD;
}

例子5:记录睡眠到就绪态的转移时间 wake_up

修改kernel/sched.c中wake_up()
void wake_up(struct task_struct **p)
{
if (p && *p)
{
(**p).state = 0;
/* 从睡眠中唤醒变为就绪态*/
fprintk(3, "%ld\t%c\t%ld\n", (*p)->pid, 'J', jiffies);
*p = NULL;
}
}

例子6:记录退出时间 exit






修改kernel/exit.c中的do_exit()
int do_exit(long code)
{
int i;
free_page_tables(get_base(current->ldt[1]),get_limit(0x0f));
free_page_tables(get_base(current->ldt[2]),get_limit(0x17));
for (i=0 ; i<NR_TASKS ; i++)
if (task[i] && task[i]->father == current->pid) {
task[i]->father = 1;
if (task[i]->state == TASK_ZOMBIE)
/* assumption task[1] is always init */
(void) send_sig(SIGCHLD, task[1], 1);
}
for (i=0 ; i<NR_OPEN ; i++)
if (current->filp[i])
sys_close(i);
iput(current->pwd);
current->pwd=NULL;
iput(current->root);
current->root=NULL;
iput(current->executable);
current->executable=NULL;
if (current->leader && current->tty >= 0)
tty_table[current->tty].pgrp = 0;
if (last_task_used_math == current)
last_task_used_math = NULL;
if (current->leader)
kill_session();
current->state = TASK_ZOMBIE;
/* TASK_ZOMBIE表示进程处于僵死,进程变为退出 */
fprintk(3, "%ld\t%c\t%ld\n", current->pid, 'E', jiffies);
current->exit_code = code;
tell_father(current->father);
schedule();
return (-1); /* just to suppress warnings */
}

对于kernel/exit.c中的sys_waitpid()中,因为之前已对TASK_ZOMBIN的进程记录过,所以不需要再添加对release(*p)再次添加log记录了。
sys_waitpid()中的完整代码如下
int sys_waitpid(pid_t pid,unsigned long * stat_addr, int options)
{
int flag, code;
struct task_struct ** p;
verify_area(stat_addr,4);
repeat:
flag=0;
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p) {
if (!*p || *p == current)
continue;
if ((*p)->father != current->pid)
continue;
if (pid>0) {
if ((*p)->pid != pid)
continue;
} else if (!pid) {
if ((*p)->pgrp != current->pgrp)
continue;
} else if (pid != -1) {
if ((*p)->pgrp != -pid)
continue;
}
switch ((*p)->state) {
case TASK_STOPPED:
if (!(options & WUNTRACED))
continue;
put_fs_long(0x7f,stat_addr);
return (*p)->pid;
case TASK_ZOMBIE:
current->cutime += (*p)->utime;
current->cstime += (*p)->stime;
flag = (*p)->pid;
code = (*p)->exit_code;
/* 由于已对标记过TASK_ZOMEBIE的进程删除过信息,因此此处不需要再次输出到log里了 */
release(*p); /* 释放处于僵尸状态的子进程 */
put_fs_long(code,stat_addr);
return flag;
default:
flag=1;
continue;
}
}
if (flag) {
if (options & WNOHANG)
return 0;
current->state=TASK_INTERRUPTIBLE;
/* 当前进程进入睡眠变为阻塞状态 */
fprintk(3, "%ld\t%c\t%ld\n", current->pid, 'W', jiffies);
schedule();
if (!(current->signal &= ~(1<<(SIGCHLD-1))))
goto repeat;
else
return -EINTR;
}
return -ECHILD;
}
(3)测试
使用以下命令,重新编译内核
/*确保卸载虚拟机挂载*/
cd ~/oslab/
sudo umount hdc
/*重新编译内核*/
cd ~/oslab/linux-0.11/
make all
使用以下命令,进入bochs:
cd ~/oslab/
./run
进入bochs后,查看log文件是否创建成功
ls -l /var

发现process.log文件以写入
运行process文件,让log记录下来过程
./process
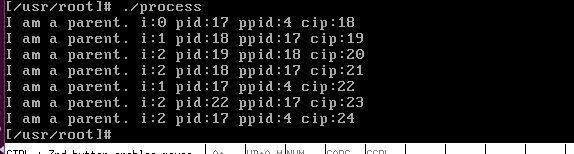
每次关闭 bochs 前都要执行一下 sync 命令,它会刷新 cache,确保文件确实写入了磁盘。
sync
退出后,打开挂载模式,将process.log拷贝到Ubuntu上查看
sudo ./mount-hdc
cp hdc/var/process.log ~/oslab
gedit process.log

写入成功!
1 N 48 // 进程1被新建(init()进程)。
1 J 48 // 进程1被创建后进入就绪队列
0 J 48 // 进程0从运行->就绪,让出CPU
1 R 49 // 进程1开始运行
2 N 49 // 进程1建立进程2。2会运行/etc/rc脚本,然后退出
2 J 49 // 进程2进入就绪队列
1 W 49 // 进程1从运行->阻塞,开始等待(等待进程2退出)
2 R 49 // 进程2开始运行
3 N 63 // 进程2建立进程3。3是/bin/sh建立的运行脚本的子进程
3 J 64 // 进程3进入就绪队列
2 J 64 // 进程2从运行->就绪,让出CPU
3 R 64 // 进程3开始运行
3 W 68 // 进程3从运行->阻塞,开始等待
2 R 68 // 进程2开始运行
2 E 73 // 进程2不等进程3退出,就先走了一步
1 J 73 // 进程1此前在等待进程2退出,被阻塞。进程2退出后,重新进入就绪队列
1 R 73 // 进程1运行
4 N 74 // 进程1建立进程4,即shell
4 J 74 // 进程4进入就绪队列
1 W 74 // 进程1从运行->阻塞,让出CPU
4 R 74 // 进程4开始运行
5 N 106 // 进程5被shell所建立,不清楚是做什么的进程
5 J 106 // 进程5进入就绪队列
4 W 107 // 进程4从运行->阻塞,等待进程5的退出
5 R 107 // 进程5开始运行
4 J 109 // 进程4从阻塞->就绪,等待被调用
5 E 109 // 进程5退出
// 下面就开始了时间片轮转,从4到0,从0到4
4 R 109 // 进程4开始运行
4 W 115 // 进程4从运行->阻塞态,让出CPU
0 R 115 // 进程0开始运行
4 J 398 // 进程4从阻塞->就绪,进入就绪队列
4 R 398 // 进程4开始运行
4 W 398 // 进程4从运行->阻塞,让出CPU
0 R 398 // 进程0开始运行
4 J 451 // 进程4从阻塞->就绪,进入就绪队列
4 R 451 // 进程4从就绪->运行,开始运行
4 W 451 // 进程4从运行->阻塞
0 R 451 // 进程0开始运行
......
// process执行
4 R 18108
11 N 18110
11 J 18110
4 W 18111
11 R 18111
12 N 18115
12 J 18115
11 W 18116
12 R 18116
12 E 18167
11 J 18167
11 R 18167
13 N 18168
13 J 18168
11 W 18168
13 R 18168
13 E 18266
11 J 18266
11 R 18266
14 N 18267
14 J 18267
11 W 18268
14 R 18268
14 E 18293
...
下面是其他博主加入执行函数标记的分析,这张很展示很清楚的展示了过程

HIT-Linux-0.11/3-processTrack/picture/process_log-functions.png
{kind=link}
(4)数据统计

stat_log.py
#!/usr/bin/python
import sys
import copy
P_NULL = 0
P_NEW = 1
P_READY = 2
P_RUNNING = 4
P_WAITING = 8
P_EXIT = 16
S_STATE = 0
S_TIME = 1
HZ = 100
graph_title = r"""
-----===< COOL GRAPHIC OF SCHEDULER >===-----
[Symbol] [Meaning]
~~~~~~~~~~~~~~~~~~~~~~~~~~~
number PID or tick
"-" New or Exit
"#" Running
"|" Ready
":" Waiting
/ Running with
"+" -| Ready
\and/or Waiting
-----===< !!!!!!!!!!!!!!!!!!!!!!!!! >===-----
"""
usage = """
Usage:
%s /path/to/process.log [PID1] [PID2] ... [-x PID1 [PID2] ... ] [-m] [-g]
Example:
# Include process 6, 7, 8 and 9 in statistics only. (Unit: tick)
%s /path/to/process.log 6 7 8 9
# Exclude process 0 and 1 from statistics. (Unit: tick)
%s /path/to/process.log -x 0 1
# Include process 6 and 7 only and print a COOL "graphic"! (Unit: millisecond)
%s /path/to/process.log 6 7 -m -g
# Include all processes and print a COOL "graphic"! (Unit: tick)
%s /path/to/process.log -g
"""
class MyError(Exception):
pass
class DuplicateNew(MyError):
def __init__(self, pid):
args = "More than one 'N' for process %d." % pid
MyError.__init__(self, args)
class UnknownState(MyError):
def __init__(self, state):
args = "Unknown state '%s' found." % state
MyError.__init__(self, args)
class BadTime(MyError):
def __init__(self, time):
args = "The time '%d' is bad. It should >= previous line's time." % time
MyError.__init__(self, args)
class TaskHasExited(MyError):
def __init__(self, state):
args = "The process has exited. Why it enter '%s' state again?" % state
MyError.__init__(self, args)
class BadFormat(MyError):
def __init__(self):
args = "Bad log format"
MyError.__init__(self, args)
class RepeatState(MyError):
def __init__(self, pid):
args = "Previous state of process %d is identical with this line." % (pid)
MyError.__init__(self, args)
class SameLine(MyError):
def __init__(self):
args = "It is a clone of previous line."
MyError.__init__(self, args)
class NoNew(MyError):
def __init__(self, pid, state):
args = "The first state of process %d is '%s'. Why not 'N'?" % (pid, state)
MyError.__init__(self, args)
class statistics:
def __init__(self, pool, include, exclude):
if include:
self.pool = process_pool()
for process in pool:
if process.getpid() in include:
self.pool.add(process)
else:
self.pool = copy.copy(pool)
if exclude:
for pid in exclude:
if self.pool.get_process(pid):
self.pool.remove(pid)
def list_pid(self):
l = []
for process in self.pool:
l.append(process.getpid())
return l
def average_turnaround(self):
if len(self.pool) == 0:
return 0
sum = 0
for process in self.pool:
sum += process.turnaround_time()
return float(sum) / len(self.pool)
def average_waiting(self):
if len(self.pool) == 0:
return 0
sum = 0
for process in self.pool:
sum += process.waiting_time()
return float(sum) / len(self.pool)
def begin_time(self):
begin = 0xEFFFFF
for p in self.pool:
if p.begin_time() < begin:
begin = p.begin_time()
return begin
def end_time(self):
end = 0
for p in self.pool:
if p.end_time() > end:
end = p.end_time()
return end
def throughput(self):
return len(self.pool) * HZ / float(self.end_time() - self.begin_time())
def print_graphic(self):
begin = self.begin_time()
end = self.end_time()
print graph_title
for i in range(begin, end+1):
line = "%5d " % i
for p in self.pool:
state = p.get_state(i)
if state & P_NEW:
line += "-"
elif state == P_READY or state == P_READY | P_WAITING:
line += "|"
elif state == P_RUNNING:
line += "#"
elif state == P_WAITING:
line += ":"
elif state & P_EXIT:
line += "-"
elif state == P_NULL:
line += " "
elif state & P_RUNNING:
line += "+"
else:
assert False
if p.get_state(i-1) != state and state != P_NULL:
line += "%-3d" % p.getpid()
else:
line += " "
print line
class process_pool:
def __init__(self):
self.list = []
def get_process(self, pid):
for process in self.list:
if process.getpid() == pid:
return process
return None
def remove(self, pid):
for process in self.list:
if process.getpid() == pid:
self.list.remove(process)
def new(self, pid, time):
p = self.get_process(pid)
if p:
if pid != 0:
raise DuplicateNew(pid)
else:
p.states=[(P_NEW, time)]
else:
p = process(pid, time)
self.list.append(p)
return p
def add(self, p):
self.list.append(p)
def __len__(self):
return len(self.list)
def __iter__(self):
return iter(self.list)
class process:
def __init__(self, pid, time):
self.pid = pid
self.states = [(P_NEW, time)]
def getpid(self):
return self.pid
def change_state(self, state, time):
last_state, last_time = self.states[-1]
if state == P_NEW:
raise DuplicateNew(pid)
if time < last_time:
raise BadTime(time)
if last_state == P_EXIT:
raise TaskHasExited(state)
if last_state == state and self.pid != 0: # task 0 can have duplicate state
raise RepeatState(self.pid)
self.states.append((state, time))
def get_state(self, time):
rval = P_NULL
combo = P_NULL
if self.begin_time() <= time <= self.end_time():
for state, s_time in self.states:
if s_time < time:
rval = state
elif s_time == time:
combo |= state
else:
break
if combo:
rval = combo
return rval
def turnaround_time(self):
return self.states[-1][S_TIME] - self.states[0][S_TIME]
def waiting_time(self):
return self.state_last_time(P_READY)
def cpu_time(self):
return self.state_last_time(P_RUNNING)
def io_time(self):
return self.state_last_time(P_WAITING)
def state_last_time(self, state):
time = 0
state_begin = 0
for s,t in self.states:
if s == state:
state_begin = t
elif state_begin != 0:
assert state_begin <= t
time += t - state_begin
state_begin = 0
return time
def begin_time(self):
return self.states[0][S_TIME]
def end_time(self):
return self.states[-1][S_TIME]
# Enter point
if len(sys.argv) < 2:
print usage.replace("%s", sys.argv[0])
sys.exit(0)
# parse arguments
include = []
exclude = []
unit_ms = False
graphic = False
ex_mark = False
try:
for arg in sys.argv[2:]:
if arg == '-m':
unit_ms = True
continue
if arg == '-g':
graphic = True
continue
if not ex_mark:
if arg == '-x':
ex_mark = True
else:
include.append(int(arg))
else:
exclude.append(int(arg))
except ValueError:
print "Bad argument '%s'" % arg
sys.exit(-1)
# parse log file and construct processes
processes = process_pool()
f = open(sys.argv[1], "r")
# Patch process 0's New & Run state
processes.new(0, 40).change_state(P_RUNNING, 40)
try:
prev_time = 0
prev_line = ""
for lineno, line in enumerate(f):
if line == prev_line:
raise SameLine
prev_line = line
fields = line.split("\t")
if len(fields) != 3:
raise BadFormat
pid = int(fields[0])
s = fields[1].upper()
time = int(fields[2])
if time < prev_time:
raise BadTime(time)
prev_time = time
p = processes.get_process(pid)
state = P_NULL
if s == 'N':
processes.new(pid, time)
elif s == 'J':
state = P_READY
elif s == 'R':
state = P_RUNNING
elif s == 'W':
state = P_WAITING
elif s == 'E':
state = P_EXIT
else:
raise UnknownState(s)
if state != P_NULL:
if not p:
raise NoNew(pid, s)
p.change_state(state, time)
except MyError, err:
print "Error at line %d: %s" % (lineno+1, err)
sys.exit(0)
# Stats
stats = statistics(processes, include, exclude)
att = stats.average_turnaround()
awt = stats.average_waiting()
if unit_ms:
unit = "ms"
att *= 1000/HZ
awt *= 1000/HZ
else:
unit = "tick"
print "(Unit: %s)" % unit
print "Process Turnaround Waiting CPU Burst I/O Burst"
for pid in stats.list_pid():
p = processes.get_process(pid)
tt = p.turnaround_time()
wt = p.waiting_time()
cpu = p.cpu_time()
io = p.io_time()
if unit_ms:
print "%7d %10d %7d %9d %9d" % (pid, tt*1000/HZ, wt*1000/HZ, cpu*1000/HZ, io*1000/HZ)
else:
print "%7d %10d %7d %9d %9d" % (pid, tt, wt, cpu, io)
print "Average: %10.2f %7.2f" % (att, awt)
print "Throughout: %.2f/s" % (stats.throughput())
if graphic:
stats.print_graphic()
再赋予文件权限+x变成绿色可执行文件
chmod +x stat_log.py
此程序必须在命令行下加参数执行,直接运行会打印使用说明。
Usage:
./stat_log.py /path/to/process.log [PID1] [PID2] ... [-x PID1 [PID2] ... ] [-m] [-g]
Example:
# Include process 6, 7, 8 and 9 in statistics only. (Unit: tick)
./stat_log.py /path/to/process.log 6 7 8 9
# Exclude process 0 and 1 from statistics. (Unit: tick)
./stat_log.py /path/to/process.log -x 0 1
# Include process 6 and 7 only. (Unit: millisecond)
./stat_log.py /path/to/process.log 6 7 -m
# Include all processes and print a COOL "graphic"! (Unit: tick)
./stat_log.py /path/to/process.log -g
运行 ./stat_log.py process.log 0 1 2 3 4 5 -g(只统计 PID 为 0、1、2、3、4 和 5 的进程)的输出示例:
(Unit: tick)
Process Turnaround Waiting CPU Burst I/O Burst
0 75 67 8 0
1 2518 0 1 2517
2 25 4 21 0
3 3003 0 4 2999
4 5317 6 51 5260
5 3 0 3 0
Average: 1823.50 12.83
Throughout: 0.11/s
-----===< COOL GRAPHIC OF SCHEDULER >===-----
[Symbol] [Meaning]
~~~~~~~~~~~~~~~~~~~~~~~~~~~
number PID or tick
"-" New or Exit
"#" Running
"|" Ready
":" Waiting
/ Running with
"+" -| Ready
\and/or Waiting
-----===< !!!!!!!!!!!!!!!!!!!!!!!!! >===-----
40 -0
41 #0
42 #
43 #
44 #
45 #
46 #
47 #
48 |0 -1
49 | :1 -2
50 | : #2
51 | : #
52 | : #
53 | : #
54 | : #
55 | : #
56 | : #
57 | : #
58 | : #
59 | : #
60 | : #
61 | : #
62 | : #
63 | : #
64 | : |2 -3
65 | : | #3
66 | : | #
67 | : | #
…………
小技巧:如果命令行程序输出过多,可以用 command arguments | more (command arguments 需要替换为脚本执行的命令)的方式运行,结果会一屏一屏地显示。
“more” 在 Linux 和 Windows 下都有。Linux 下还有一个 “less”,和 “more” 类似,但功能更强,可以上下翻页、搜索。
还可以将数据存到文件里
./stat_log.py process.log 0 1 2 3 4 5 6 7 9 -g > test.txt
查看文件
gedit test.txt

(5)修改时间片




1)修改时间片的初始值
在~/oslab/linux-0.11/include/linux/sched.h中修改INIT_TASK

将其改为10,然后再编译make all之后,进入linux0.11运行process并将log文件保存再磁盘上。
再使用py文件进行统计分析,得到如下结果。

再分别将时间片改为 5、20、25进行对比,所有的对比如下所示。


时间片变小,进程因时间片到时产生的进程调度次数变多,该进程等待时间越长。
然而随着时间片增大,进程因中断或者睡眠进入的进程调度次数也增多,等待时间随之变长。
故而需要设置合理的时间片,既不能过大,也不能过小。
参考资料:
(浓缩+精华)哈工大-操作系统-MOOC-李治军教授-实验3-进程运行轨迹的跟踪与统计
相关文章
- 循环录(输)入 java 课的学生成绩(5个学生),统计分数大于等于 80 分的学生
- Java实现蓝桥杯日志统计
- IDEA使用Statistic插件统计代码数量
- Linux统计某文件夹下文件、文件夹的个数
- linux 统计命令执行后的行数或者统计目录下文件数目
- pclpy 统计滤波器
- Linux中进程内存RSS与cgroup内存的RSS统计 - 差异
- ZZNUOJ_用C语言编写程序实现1228:字符统计(附完整源码)
- 线段树区间更新,区间统计+离散化 POJ 2528 Mayor's posters
- 练习 1-8 编写一个统计空格、制表符与换行符个数的程序。// C语言
- ThreadLocal 应用:封装一个好用的代码执行耗时统计工具