
1、hadoop3.1.3 分布式集群搭建的详细教程
hadoop集群搭建教程
> hadoop知识背景
- hadoop的优势
(1)高可靠性:hadoop底层维护多个数据副本,所以即使hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
(2)高扩展性:在集群时间分配任务数据,可方便的扩展舒伊千计的节点。
(3)高效性:在MapReduce的思想下,hadoop是并行工作的,所以加快任务处理速度。
(4)高容错性:能够自动将失败的任务重新分配。

Hadoop 2和Hadoop 3的端口区别

Hadoop 3 HDFS集群架构

HDFS架构

YARN架构

MapReduce架构
MapReduce将计算过程分为两个阶段:Map和Reduce
(1)Map阶段并行处理输入数据
(2)Reduce阶段对Map结果进行汇总

1、创建虚拟机

扩展知识:
VMware虚拟机网络模式设置:
VMware虚拟机的网络模式 — 桥接模式、仅主机模式、NAT模式的特点和配置
某个虚拟机卡死解决方法:
VMware中某个虚拟机卡死,单独关闭某个虚拟机的办法
VMware虚拟机打开后经常黑屏
VMware虚拟机黑屏解决
2、用户登录过程中遇到的问题

扩展知识:
- 普通用户获取sudo权限问题:
xxx is not in the sudoers file.This incident will be reported.的解决方法 - root用户密码初始化问题:
linux root账户初始密码设置并切换至root账户
然后给用户添加sudo权限
root@ubuntu:/etc/apt# adduser hadoop sudo
Adding user `hadoop' to group `sudo' ...
Adding user hadoop to group sudo
Done.
- 用户和用户组的添加和删除方法:
Ubuntu基础命令(六)–添加和删除用户和用户组(删除后重启一下) - 登录界面只有游客身份问题:
Ubuntu16.04 只能以游客身份登录问题
2、修改镜像源为阿里云镜像
参考文章:ubuntu16.04更换镜像源为阿里云镜像源

更新apt-get
sudo apt-get update
参考文章:apt-get update和upgrade的区别
安装vim
sudo apt-get install vim
3、克隆两台虚拟机
参考文章:虚拟机的克隆(带图详解)
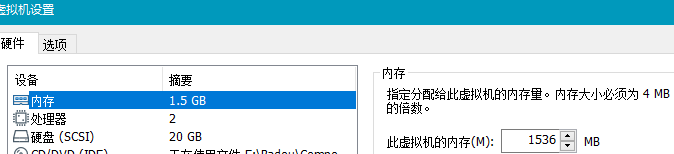
根据情况,更改新克隆出来虚拟机的配置
4、更改用户名和主机名
参考文章:Ubuntu下更改用户名和主机名
更改主机名:


规划三台主机的ip地址为:
192.168.xxx.xx1
192.168.xxx.xx2
192.168.xxx.xx3
在/etc/hosts中添加即可
192.168.xxx.xx1 hadoop101
192.168.xxx.xx2 hadoop102
192.168.xxx.xx3 hadoop103
规划第一台叫hadoop101其余的为hadoop102和hadoop103。
注意: 修改克隆后虚拟机的地址为上述规划的地址
通过点击编辑,进入虚拟网络编辑器再进入DHCP设置,再规划范围内设置三台主机的具体IP地址
5、安装配置hadoop开发环境
(1)安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
sudo apt-get install openssh-server
安装后,可以使用如下命令登陆本机:
ssh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。
SSH首次登陆提示

输入exit可以退出。
之后使用XShell软件进行远程连接

若已建立了多台虚拟机,想要进行连接
Linux主机之间相互登录方法:Linux之间配置SSH互信(SSH免密码登录)
首先,生成公钥和私钥
hadoop@hadoop101:~$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)。
再将公钥拷贝到要免密登录的目标机器上
hadoop@hadoop101:~/.ssh$ ssh-copy-id hadoop101
hadoop@hadoop101:~/.ssh$ ssh-copy-id hadoop102
hadoop@hadoop101:~/.ssh$ ssh-copy-id hadoop103
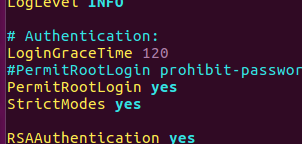
若想要配置root的无密登录,需要修改/etc/ssh/sshd_config文件,去掉注释
LoginGraceTime 120
PermitRootLogin yes
StrictModes yes
再输入
hadoop@hadoop101:~/.ssh$ service sshd restart
使其生效,然后再按上述拷贝给hadoop101、102、103的方式拷贝给对应的root用户下即可。

上述原理图,首先在A服务器上生成密钥对(公、私钥),然后A服务器将它的公钥发给服务器B。当A服务器用自己的私钥加密完信息后发送给B时,B可以通过查找授权key中找到公钥A来解密A发来的信息。当B服务器给A服务器发送信息时,可以采用A的公钥加密信息再进行发送,当服务器A收到该信息后,可以用自己的私钥进行解密,获取原码。
总结,ssh-key-gen生成的密钥对,即公钥和私钥,可以进行相互解密。
| 文件 | 功能 |
|---|---|
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放被授权过得无密登录服务器公钥 |
(2)使用FileZilla连接ubuntu
FileZilla连接不上ubuntu问题
解决方法:【详解—filezilla连接不上Ubuntu解决办法】

下载jdk8和hadoop3.1.3.,
hadoop官网下太慢了,还是得用国内镜像源:北京信息学院镜像网
然后使用FileZilla,将jdk和hadoop的jar包传输给ubuntu。
(3)配置jdk和hadoop环境
在/opt下创建文件夹moudle(放配置环境)和software(放安装包)
hadoop@hadop101:/$ cd opt
hadoop@hadop101:/$ sudo mkdir moudle software
hadoop@hadop101:/opt$ ll
total 16
drwxr-xr-x 4 root root 4096 Feb 27 22:59 ./
drwxr-xr-x 24 root root 4096 Feb 27 01:54 ../
drwxr-xr-x 2 root root 4096 Feb 27 22:59 module/
drwxr-xr-x 2 root root 4096 Feb 27 22:58 software/
由于权限所有者为root,为了开发方便,更改权限文件所有者为hadoop
hadoop@hadop101:/opt$ sudo chown hadoop:hadoop -R module
hadoop@hadop101:/opt$ sudo chown hadoop:hadoop -R software
hadoop@hadop101:/opt$ ll
total 16
drwxr-xr-x 4 root root 4096 Feb 27 23:04 ./
drwxr-xr-x 24 root root 4096 Feb 27 01:54 ../
drwxr-xr-x 2 hadoop hadoop 4096 Feb 27 22:59 module/
drwxr-xr-x 2 hadoop hadoop 4096 Feb 27 22:58 software/
参考文章:每天学一个linux命令——chown将指定文件的拥有者改为指定的用户或组
解压jdk到module,解压hadoop移动到software
hadoop@hadop101:/opt/software$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module
hadoop@hadop101:/opt/software$ tar -zxvf jdk-8u231-linux-x64.tar.gz -C /opt/module
配置/etc/profile文件
hadoop@hadop101:/opt/module/jdk1.8.0_231$ sudo vim /etc/profile
/etc/profile文件末尾加入
# JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_231
export PATH=$PATH:$JAVA_HOME/bin
# HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOP_HOME/sbin
生效文件
hadoop@hadop101~$ source /etc/profile
验证一下java
hadoop@hadop101:/opt/module/jdk1.8.0_231$ java -version
java version "1.8.0_231"
Java(TM) SE Runtime Environment (build 1.8.0_231-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.231-b11, mixed mode)
验证一下hadooop
hadoop@hadoop101:/opt$ hadoop version
Hadoop 3.1.3
成功。

| 目录 | 功能 |
|---|---|
| bin | 存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本 |
| etc | Hadoop的配置文件目录,存放Hadoop的配置文件 |
| lib | 存放Hadoop的本地库(对数据进行压缩解压缩功能) |
| sbin | 存放启动或停止Hadoop相关服务的脚本 |
| share | 存放Hadoop的依赖jar包、文档、和官方案例 |
(4)将配置文件共享到其他主机上
方法一:直接将配置好的虚拟机进行克隆
在虚拟机关闭的情况下,从虚拟机列表里,右键想克隆的虚拟机,移动到管理——》点击克隆。
已知点下一步,一直到这一步时

如果选择第一个,则会构建一个链接此虚拟机的新虚拟机,该虚拟机依赖于被克隆的虚拟机,需要保证被克隆虚拟机在开启的情况下,才可以保证新虚拟机正常运行,原理类似于docker的层结构。优点是占用存储空间小,缺点是依赖于被克隆的虚拟机。
如果选择第二个,会完全拷贝此虚拟机,从而创建一个独立的虚拟机,优点是完全独立,灵活性高,缺点是占用存储空间大。
可根据你的自己需求来进行选择。
克隆完成之后,就和第一台虚拟机拥有相同的环境配置了。
注:记得在关机情况下克隆,如果在开机克隆的话,会记录被克隆机器的开启时状态,导致占用过多内存。
方法二:编写xsync脚本进行集群发布
> 前提准备:
1、另外两台虚拟机;2、按照上述基础配置;3、按照上述ssh那部分配置root的登录连接
由于在实际分布式开发中,会对数量庞大的分布式主机去实时修改配置,因此可进行编写脚本来进行分发。
a. scp(security copy)安全拷贝命令
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
基本语法
(a)在hadop101上,将hadop101中/opt/module目录下的软件拷贝到hadop102上。(推push)
scp -r /opt/module hadoop@hadop102:/opt/module
命令 递归 要拷贝的文件路径/名称 目标用户@主机:目标路径/名称
注:实际中目标路径的文件要注意文件的所有者是root还是普通用户,如果为root上述目标用户就不为hadoop而是root
然后输入yes,再输入密码即可。
(b)在hadoop102上,将hadoop102服务器上的/opt/module目录下的软件拷贝到hadoop101上。(拉pull)
scp -r hadoop@hadop101:/opt/software /opt/software
命令 递归 来源用户@主机:来源路径/名称 要存放的文件路径/名称
(c)完全输写用户及路径
scp -r root@hadop101:/etc/profile root@hadop102:/etc/profile
命令 递归 来源用户@主机:来源路径/名称 目标用户@主机:目标路径/名称
总结:其实就是正规格式应该都包括用户名@主机:/文件路径,但如果是在来源主机或目标主机上,就可以省略对应位置的“用户名@主机名:”。
扩展知识:
遇到使用scp传输root用户权限问题:
Linux的远程传输文件scp及出现Permission denied (publickey).lost connection问题解决方法
使用scp传输文件给linux服务器,出现Permission denied(publickey) 的解决办法
主机名写错导致无法找到ip映射:
ssh: Could not resolve hostname hadoop002: Name or service not known
ssh的秘钥不匹配问题:
ssh scp 报错Host key verification failed
SSH服务器端/etc/ssh/sshd_conf配置文件详解

b. rsync远程同步命令(仅修改差异部分)
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
基本语法
hadoop机器上root用户的/opt目录同步到另一台hadoop服务器的hadoop用户下的/opt目录
rsync -rvl hadoop@master:/opt/module /opt/module
选项参数
| 选项 | 功能 |
|---|---|
| -r | 递归 |
| -v | 显示复制过程 |
| -l | 拷贝符号连接 |
编写xsync集群分发脚本
1. 需求:循环复制文件到所有节点的相同目录下
2. 需求分析:
- rsync命令原始拷贝:
rsync -rvl /opt/module hadoop@hadoop102:/opt/
- 期望脚本:
xsync要同步的文件名称 - 说明:在/home/hadoop/bin这个目录下存放的脚本,hadoop用户可以在系统任何地方直接执行。(配置环境)
3.脚本实现
- 在/home/hadoop目录下创建bin目录,并在bin目录下xsync创建文件,文件内容如下:
hadoop@hadop101:~$ mkdir bin
hadoop@hadop101:~$ cd bin/
hadoop@hadop101:~$ touch xsync
hadoop@hadop101:~$ vim xsync
在该文件中编写如下代码
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=101; host<104; host++)); do
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
- 修改脚本 xsync 具有执行权限
chmod 777 xsync
- 修改环境变量/etc/profile
#XSYNC_HOME
export XSYNC_HOME=/home/hadoop
export PATH=$PATH:$XSYNC_HOME/bin
source /etc/profile
生效
- 调用脚本形式:xsync 文件名称
xsync /home/hadoop/bin
注意:如果将xsync放到/home/hadoop/bin目录下仍然不能实现全局使用,可以将xsync移动到/usr/local/bin目录下。
拓展知识:
linux的whoami, who指令
- cd -P命令:在处理“…”前处理软链接,即打开硬链接。软连接相当于Windows上的快捷方式(构建一个链接,链接到物理磁盘上),硬链接是对物理磁盘操作,直接将存储文件写在磁盘上。
软连接 硬链接 与cp -p
Linux 软连接与硬连接
6、hadoop集群配置
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
- 默认配置文件
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-2.7.2.jar/ core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-2.7.2.jar/ hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-2.7.2.jar/ yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-2.7.2.jar/ mapred-default.xml |
- 自定义配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
(1)集群部署规划
| \ | hadoop101 | hadoop102 | hadoop103 |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | ResourceManager、NodeManager | NodeManager |
(2)配置集群
注:hadoop2和hadoop3的配置内容基本相同,但有一些细微差别
参考文章:hadoop3 提交任务出错(找不到类)
⒈ 核心配置文件
配置core-site.xml
hadoop@hadoop101:/opt/module/hadoop-3.1.3/etc/hadoop$ vim core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data/tmp</value>
</property>
⒉ HDFS配置文件
配置hadoop-env.sh
hadoop@hadoop101:/opt/module/hadoop-3.1.3/etc/hadoop$ vim hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_231/
<!--hadoop3配置以下内容-->
export HADOOP_HOME=/opt/module/hadoop-3.1.3
配置hdfs-site.xml
hadoop@hadoop103:/opt/module/hadoop-3.1.3/etc/hadoop$ vim hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:50090</value>
</property>
⒊ YARN配置文件
配置yarn-site.xml
hadoop@hadoop101:/opt/module/hadoop-3.1.3/etc/hadoop$ vim yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
⒋ MapReduce配置文件
配置mapred-site.xml
hadoop@hadoop101:/opt/module/hadoop-3.1.3/etc/hadoop$ vim mapred-site.xml
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--hadoop3配置以下内容-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
如果报错情况一:
说明没添加
<!-- 如果报错Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster需要添加以下配置-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
如果报错情况二:
2020-03-07 06:15:43,533 INFO conf.Configuration: resource-types.xml not found
2020-03-07 06:15:43,534 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
说明没添加
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
(3)在集群上分发配置好的Hadoop配置文件
hadoop@hadoop101:/opt/module/hadoop-3.1.3/etc/hadoop$ xsync /opt/module/hadoop-3.1.3/
(4)查看文件分发情况
hadoop@hadoop101:/opt/module/hadoop-3.1.3/etc/hadoop$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
7、集群单点启动
如果文件在/opt/module/hadoop-3.1.3下有,要先删除/data/和/logs/,保证在之后新启动的集群id配置都相同。
rm -rf logs/ data/
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
(1)如果第一次启动集群需格式化NameNode
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ hdfs namenode -format
注:要保证过程中不报错
(2)启动Namenode
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ hdfs --daemon start namenode
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ jps
5489 NameNode
5524 Jps
注:一个集群只有一个Namenode
(3)启动Datanode和secondarynamenode
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ hdfs --daemon start datanode
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ jps
5489 NameNode
5636 Jps
5604 DataNode
hadoop@hadoop102:/opt/module/hadoop-3.1.3$ hdfs --daemon start datanode
hadoop@hadoop102:/opt/module/hadoop-3.1.3$ jps
3888 Jps
3872 DataNode
hadoop@hadoop103:/opt/module/hadoop-3.1.3$ hdfs --daemon start datanode
hadoop@hadoop103:/opt/module/hadoop-3.1.3$ jps
3246 DataNode
3262 Jps
hadoop@hadoop103:/opt/module/hadoop-3.1.3$ hdfs --daemon start secondarynamenode
hadoop@hadoop103:/opt/module/hadoop-3.1.3$ jps
4118 SecondaryNameNode
4137 Jps
3402 DataNode
访问网站查看一下:
hadoop101:9870
注:3.0以后的版本端口号换成了9870,不是50070了。
参考文章:hadoop3.X localhost:50070/ 打不开、hadoop 3.X端口变动

关闭各节点
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ hdfs --daemon stop namenode
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ hdfs --daemon stop datanode
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ jps
6221 Jps
hadoop@hadoop102:/opt/module/hadoop-3.1.3$ hdfs --daemon stop datanode
hadoop@hadoop102:/opt/module/hadoop-3.1.3$ jps
4467 Jps
hadoop@hadoop103:/opt/module/hadoop-3.1.3$ hdfs --daemon stop secondarynamenode
hadoop@hadoop103:/opt/module/hadoop-3.1.3$ jps
4631 Jps
8、群起集群
(1)配置workers(3.0之前的叫slaves)
hadoop@hadoop101:/opt/module/hadoop-3.1.3/etc/hadoop$ vim workers
将其改为
hadoop101
hadoop102
hadoop103
注意:因为会进行脚本解析执行,为避免误判,所以该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
然后,同步节点配置文件
hadoop@hadoop101:/opt/module/hadoop-3.1.3/etc/hadoop$ xsync workers
(2)启动集群
注:如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
启动HDFS
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ start-dfs.sh
Starting namenodes on [hadoop101]
Starting datanodes
Starting secondary namenodes [hadoop103]
看一下
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ jps
6913 Jps
6508 NameNode
6637 DataNode
hadoop@hadoop102:/opt/module/hadoop-3.1.3$ jps
4642 DataNode
4722 Jps
hadoop@hadoop103:/opt/module/hadoop-3.1.3/etc/hadoop$ jps
5009 DataNode
5158 Jps
5130 SecondaryNameNode
(3)启动YARN
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
hadoop@hadoop102:/opt/module/hadoop-3.1.3$ sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers
看一下
hadoop@hadoop101:/opt/module/hadoop-3.1.3/etc/hadoop$ jps
8097 NodeManager
8197 Jps
7704 DataNode
7564 NameNode
hadoop@hadoop102:/opt/module/hadoop-3.1.3$ jps
5431 Jps
5112 ResourceManager
4891 DataNode
5244 NodeManager
hadoop@hadoop103:/opt/module/hadoop-3.1.3/etc/hadoop$ jps
5009 DataNode
5382 Jps
5291 NodeManager
访问网站查看一下:
hadoop102:8088

(4)文件传输测试
HDFS界面:http://hadoop101:50070
查看NameNode状态;
该端口的定义位于core-default.xml中,可以在hdfs-site.xml 中修改;
如果通过该端口看着这个页面,以为着NameNode节点是存活的
⒈ 上传文件到集群
构建一个测试文本和HDFS存储目录
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ mkdir testinput
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ cd testinput
hadoop@hadoop101:/opt/module/hadoop-3.1.3/test_context$ touch test.input
hadoop@hadoop101:/opt/module/hadoop-3.1.3/test_context$ vim test.input
hadoop@hadoop101:/opt/module/hadoop-3.1.3/test_context$ cat test.input
hello,hadoop!
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ mkdir /home/hadoop/input
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ hdfs dfs -mkdir -p /home/hadoop/input
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ hdfs dfs -ls /
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2020-02-29 00:11 /home
创建HDFS目录在/home/hadoop/input下
如果不想要可以用rm删除,hdfs dfs命令之后附加的命令和Linux下常用命令基本相同。

可以查看到。
⒉ 将测试文件上传到文件系统
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ bin/hdfs dfs -put testinput/test.input /home/hadoop/input/
⒊ 查看上传的文件是否正确
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ bin/hdfs dfs -ls /home/hadoop/input
Found 1 items
-rw-r--r-- 3 hadoop supergroup 14 2020-02-29 00:14 /home/hadoop/input/test.input
hadoop@hadoop101:/opt/module/hadoop-3.1.3$ bin/hdfs dfs -cat /home/hadoop/input/test.input
2020-02-29 00:16:37,209 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
hello,hadoop!
同时查看网页内情况

Size为当前大小,Block Size为一个存储块最大的存储容量为128M。

可从网站上进行下载,如果上传的文件容量大于规定的128M,将会把此文件分成两个块进行存储。同时,也可找到该文件存储目录下对应的blk_id,自行按顺序进行拼接后,可还原成原始文件。
例如,分块后的文件名为
-rw-rw-r--. 1 atguigu atguigu 134217728 5月 23 16:01 blk_1073741836
-rw-rw-r--. 1 atguigu atguigu 1048583 5月 23 16:01 blk_1073741836_1012.meta
-rw-rw-r--. 1 atguigu atguigu 63439959 5月 23 16:01 blk_1073741837
-rw-rw-r--. 1 atguigu atguigu 495635 5月 23 16:01 blk_1073741837_1013.meta
创建tmp.file用来存放文件内容,开始拼接
$ cat blk_1073741836>>tmp.file
$ cat blk_1073741837>>tmp.file
进行相应检查,可发现tmp.file中的内容还原成了原始文件。
参考教程:尚硅谷hadoop教程
9、集群时间同步
> 前置知识
Ubuntu下crontab的安装和使用
ubuntu如何更改crontab的默认编辑器




注:以下为centos6系统的配置方式
- 时间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间。
配置时间同步具体实操:
- 时间服务器配置(必须root用户)
(1)检查ntp是否安装
[root@hadoop102 桌面]# rpm -qa|grep ntp
ntp-4.2.6p5-10.el6.centos.x86_64
fontpackages-filesystem-1.41-1.1.el6.noarch
ntpdate-4.2.6p5-10.el6.centos.x86_64
(2)修改ntp配置文件
[root@hadoop102 桌面]# vi /etc/ntp.conf
修改内容如下
a)修改1(授权192.168.1.0-192.168.1.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap为
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
b)修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)修改/etc/sysconfig/ntpd 文件
[root@hadoop102 桌面]# vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
(4)重新启动ntpd服务
[root@hadoop102 桌面]# service ntpd status
ntpd 已停
[root@hadoop102 桌面]# service ntpd start
正在启动 ntpd: [确定]
(5)设置ntpd服务开机启动
[root@hadoop102 桌面]# chkconfig ntpd on
- 其他机器配置(必须root用户)
(1)在其他机器配置10分钟与时间服务器同步一次
[root@hadoop103桌面]# crontab -e
编写定时任务如下:
*/10 * * * * /usr/sbin/ntpdate hadoop102
(2)修改任意机器时间
[root@hadoop103桌面]# date -s "2017-9-11 11:11:11"
(3)十分钟后查看机器是否与时间服务器同步
[root@hadoop103桌面]# date
说明:测试的时候可以将10分钟调整为1分钟,节省时间。
相关文章
- Python 脚手架Cookiecutter使用教程
- Jinja2 教程 - 第 1 部分 - 介绍和变量替换
- 【Oracle 集群】11G RAC 知识图文详细教程之RAC在LINUX上使用NFS安装前准备(六)
- 【Oracle 集群】ORACLE DATABASE 11G RAC 知识图文详细教程之缓存融合技术和主要后台进程(四)
- Android Studio 系列教程(转载)
- 【PyTorch】教程:torch.nn.RReLU
- ROS1 noetic + depthai_ros教程
- openshift介绍及centos7安装单节点openshift、Redhat安装openshift集群完全教程
- SAP UI5 初学者教程之五:视图控制器初探 试读版
- SAP UI5 应用开发教程之三十六 - 使用 Chrome 开发者工具 Elements 标签动态修改 CSS 类试读版
- 全网最全的Gitlab CI/CD自动化部署的介绍和教程,使用GitLab CI/CD自动化热部署SpringBoot或maven项目,GitLab CI/CD的Kubernetes集群的集成
- (2022版)一套教程搞定k8s安装到实战 | K8s集群安装(Kubeadm)
- (2022版)一套教程搞定k8s安装到实战 | ConfiMap
- Kubernetes集群方方面面实战教程学习线路指南
- 电脑一键在线重装win7系统教程
- 自编Ps教程—我的ps图片赞赏
- 并发压测 jmeter使用教程
- 计算机视觉最全方向专栏教程总结
- 【pandas】教程:2-读写表格数据
- openshift介绍及centos7安装单节点openshift、Redhat安装openshift集群完全教程