
图片文字识别(一):tesseract-ocr-4.00的安装与初步进行图片文字识别
简介:
tesseract-ocr可以对图像文字进行识别,为图文转换的工作时省去了大量时间。我们还可以通过不断的训练字库,使图像转换文本的能力不断增强,也可以调试模型使图像文字进行程序的识别率更高,
一.tesseract4.0的安装与配置环境变量:
1、安装包地址: http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe
2、下载完之后,直接执行.exe文件进行安装,安装步骤:
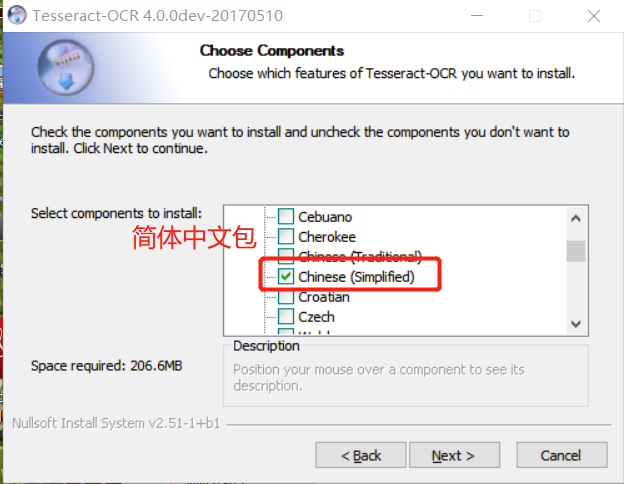
(1)选择语言包:
除了默认已经打钩的,再钩上数字公式常用包和简体中文包。

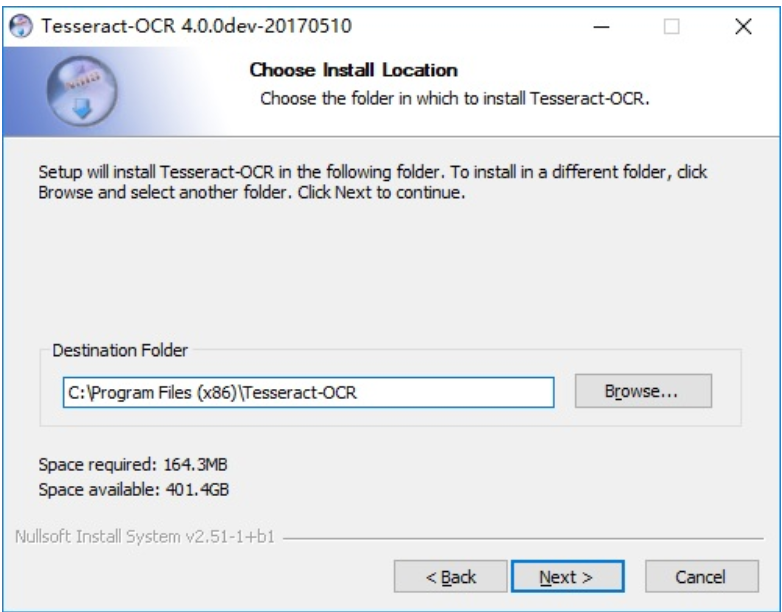
(2)选择安装路径:(需要记住自己的安装路径,后面配置需要用到)
我的安装路径是:D:\Tesseract\tesseract-ocr--4.00.00dev\Tesseract-OCR
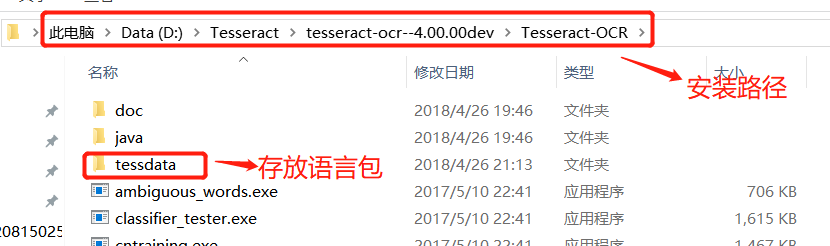
(3)目录结构:
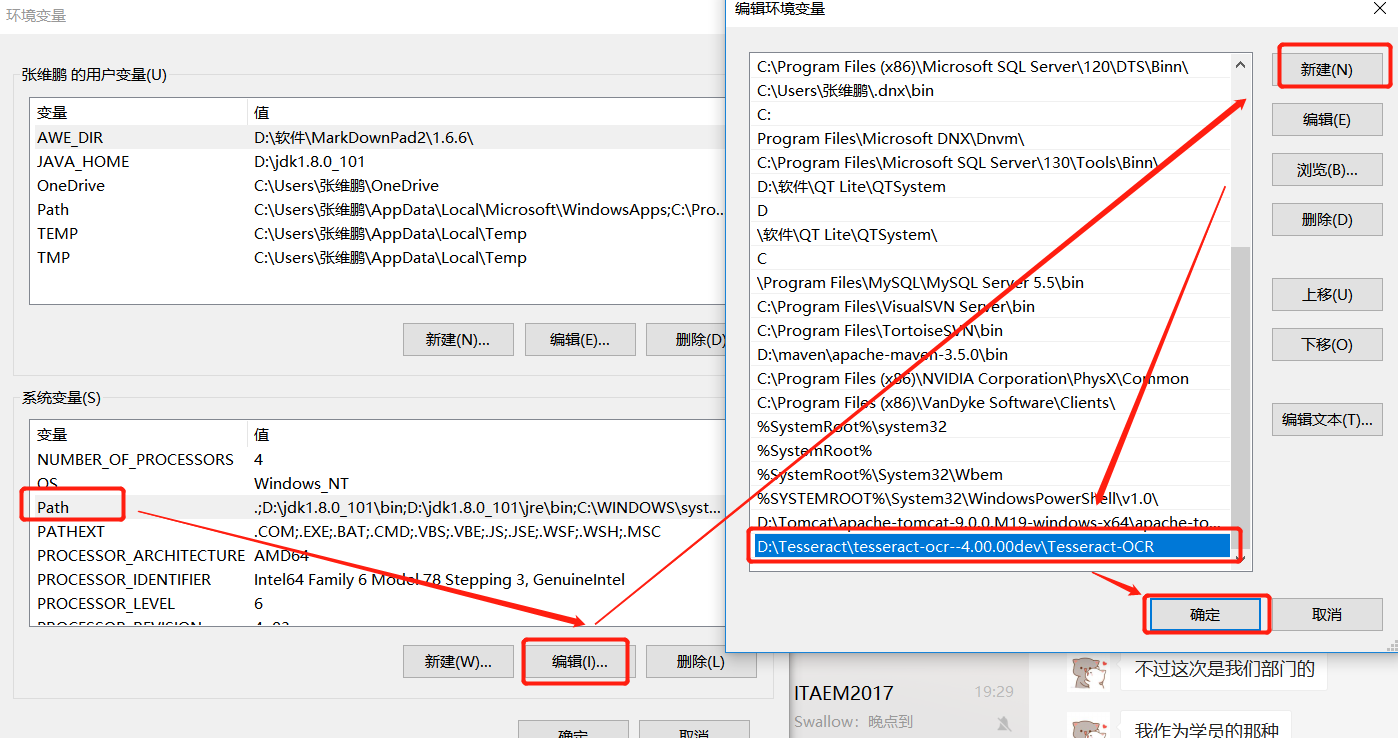
(4)配置环境变量:
第一步:在环境变量界面的系统变量中找到Path,点击编辑,新建一个D:\Tesseract\tesseract-ocr--4.00.00dev\Tesseract-OCR(你的安装目录),然后确定。
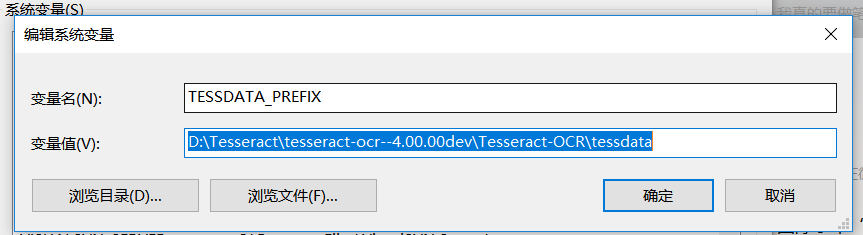
第二步:在系统变量下面新建一个变量,然后确定。
变量名:TESSDATA_PREFIX
变量值:D:\Tesseract\tesseract-ocr--4.00.00dev\Tesseract-OCR\tessdata(安装目录下的tessdata文件夹)
(5)检验环境变量是否配置成功:打开cmd命令行,在任意路径,输入“tesseract”,出现下面信息则表示配置成功。

二、初步使用tesseract4.0进行简单的图片文字识别:
1、先准备一张图片素材(图片命名是wenzi.png),内容如下图:

2、打开cmd命令行,进入素材图片所在的目录,输入以下命令,就会生成一个test.txt文档,该文档的内容为图片识别后的文字:
tesseract wenzi.png test -l chi_sim+equ+eng其中,wenzi.png是素材的名字,test是识别后生成的文档的名字,-l是指定使用包(注意:是小写英文字母l,不是阿拉伯数字1),chi_sim是中文识别包,equ是数字公式包,eng是英文包。

识别后的test.txt的文字内容:

3、至此,使用tesseract4.0进行简单的文字识别就完成,虽然识别的成功不高,但是我们可以通过训练字库的方法提高tesseract的识别率,训练tesseract字库的方法在下篇博客再写。
相关文章
- Yii2给数据库表添加字段后对应模型无法识别到该属性的原因和解决办法
- SAS信用评分之番外篇异常值的识别
- android 手势识别学习
- Atitit 语音识别的技术原理
- atitit.验证码识别step4--------图形二值化 灰度化
- TF之NN:利用DNN算法(SGD+softmax+cross_entropy)对mnist手写数字图片识别训练集(TF自带函数下载)实现87.4%识别
- 已解决pip正确安装ddddocr验证码识别模块
- 【智能算法】基于带动量项的BP神经网络语音识别
- 中文ocr识别通过crnn
- 跑道防侵入,华为云ModelArts平台助力航空器识别AI模型开发
- 玩转百度语音识别,就是这么简单
- 数据预处理-异常值识别
- 【youcans 的 OpenCV 例程200篇】121. 击中-击不中用于特征识别
- 动作识别0-04:mmaction2(SlowFast)-白话给你讲论文-翻译无死角(2)
- 【C++ 科学计算】基于C++深度学习CNN车辆识别(亲测)
- r去掉向量中的空字符串 在R里如何去掉字符串矩阵中的空字符串 r r 识别字符串中的双引号 识别字符串中的双引号 str_detect