
MySQL索引优化
目录
MySql学习专栏
3. MySQL5.7开启binlog日志,及数据恢复简单示例
本文主要讨论MySQL索引的部分知识。将会从MySQL索引基础、索引优化实战和数据库索引背后的数据结构三部分相关内容。
以下讲解是居于数据库 5.7.32 版本
一、MySQL索引基础
首先,我们将从索引基础开始介绍一下什么是索引,分析索引的几种类型,并探讨一下如何创建索引以及索引设计的基本原则。
此部分用于测试索引创建的user表的结构如下:
desc user;
1. 什么是索引?
"索引(在MySQL中也叫“键key”)是存储引擎快速找到记录的一种数据结构。"
——《高性能MySQL》
我们需要知道索引其实是一种数据结构,其功能是帮助我们快速匹配查找到需要的数据行,是数据库性能优化最常用的工具之一。其作用相当于超市里的导购员、书本里的目录。
2. 索引类型
可以使用SHOW INDEX FROM table_name;查看索引详情:

主键索引 PRIMARY KEY:它是一种特殊的唯一索引,不允许有空值。一般是在建表的时候同时创建主键索引。注意:一个表只能有一个主键。
唯一索引 UNIQUE:唯一索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。可以通过ALTER TABLE table_name ADD UNIQUE (column);创建唯一索引:
ALTER TABLE user ADD UNIQUE u_phone (phone);
删除索引命令
DROP INDEX <索引名> ON <表名>
drop user index on idx_name_age_position;语法说明如下:
<索引名>:要删除的索引名。<表名>: 指定该索引所在的表名。
唯一组合索引命令
ALTER TABLE table_name ADD UNIQUE <索引名> (<列>,<列>)ALTER TABLE user ADD UNIQUE u_name_age (user_name,age);
普通索引 INDEX:这是最基本的索引,命令如下
ALTER TABLE <table_name> ADD INDEX <idx_name> (<column>);语法说明如下:
<idx_name>:要添加的索引名称<table_name>: 指定该索引所在的表名<column>: 指定要添加索引的列
alter table user add index idx_satus (status);
组合索引 INDEX:即一个索引包含多个列,多用于避免回表查询,命令如下
ALTER TABLE <table_name> ADD INDEX <idx_name> (<column1>,<column2>);语法说明如下:
<idx_name>:要添加的索引名称<table_name>: 指定该索引所在的表名<column1>: 指定要添加索引的列1<column2>: 指定要添加索引的列2
alter table user add index idx_user_age (user_name,age);
全文索引 FULLTEXT:也称全文检索,是目前搜索引擎使用的一种关键技术,命令如下
ALTER TABLE <table_name> ADD FULLTEXT <f_name> (<column>);语法说明如下:
<table_name>: 指定该索引所在的表名<f_name>: 要添加的索引名称<column>: 指定要添加索引的列

索引一经创建不能修改,如果要修改索引,只能删除重建。
3、索引设计的原则
- 适合索引的列是出现在where子句中的列,或者连接子句中指定的列;
- 基数较小的类,索引效果较差,没有必要在此列建立索引;
- 使用短索引,如果对长字符串列进行索引,应该指定一个前缀长度,这样能够节省大量索引空间;
- 不要过度索引。索引需要额外的磁盘空间,并降低写操作的性能。在修改表内容的时候,索引会进行更新甚至重构,索引列越多,这个时间就会越长。所以只保持需要的索引有利于查询即可。
二、MySQL索引优化实战
上面我们介绍了索引的基本内容,这部分我们介绍索引优化实战。在介绍索引优化实战之前,首先要介绍两个与索引相关的重要概念,这两个概念对于索引优化至关重要。
此部分用于测试的user表结构:

1、索引相关的重要概念
基数:单个列唯一键(distict_keys)的数量叫做基数。
select count(distinct user_name),count(distinct gender) from user;
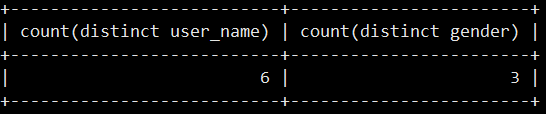
user表的总行数是6,gender列的基数是3,说明gender列里面有大量重复值,name列的基数等于总行数,说明name列没有重复值,相当于主键。
返回数据的比例:user表中共有6条数据:

查询满足性别为0(男)的记录数:

那么返回记录的比例数是:
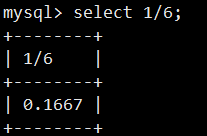
同理,查询name为'smile'的记录数:

现在问题来了,假设name、age 列都有索引,那么SELECT * FROM user WHERE age = 28 ;
SELECT * FROM user WHERE name = 'smile';都能命中索引吗?
user表的索引详情:

SELECT * FROM user WHERE age = 28;没有命中索引,注意filtered的值就是上面我们计算的返回记录的比例数。
EXPLAIN select * from user where age = 28;

SELECT * FROM user WHERE name = 'smile';命中了索引index_name,因为走索引直接就能找到要查询的记录,所以filtered的值为100。

组合索引底层还是使用B+树索引,并且还是只有一棵树,只是此时的排序会:首先按照第一个索引排序,在第一个索引相同的情况下,再按第二个索引排序,依次类推。
这也是为什么有“最佳左前缀原则”的原因,因为右边(后面)的索引都是在左边(前面)的索引排序的基础上进行排序的,如果没有左边的索引,单独看右边的索引,其实是无序的。
还是以字典为例,我们如果要查第2个字母为 k 的,通过目录是无法快速找的,因为首字母 A - Z 里面都可能包含第2个字母为 k 的。
回表:当对一个列创建索引之后,索引会包含该列的键值及键值对应行所在的rowid。通过索引中记录的rowid访问表中的数据就叫回表。回表次数太多会严重影响SQL性能,如果回表次数太多,就不应该走索引扫描,应该直接走全表扫描。
EXPLAIN命令结果中的Using Index意味着不会回表,通过索引就可以获得主要的数据。Using Where则意味着需要回表取数据。
三、 索引优化实战
有些时候虽然数据库有索引,但是并不被优化器选择使用。我们可以通过' SHOW STATUS LIKE 'Handler_read% ';查看索引的使用情况:

Handler_read_key:如果索引正在工作,Handler_read_key的值将很高。
Handler_read_rnd_next:数据文件中读取下一行的请求数,如果正在进行大量的表扫描,值将较高,则说明索引利用不理想。
索引优化规则:
1)如果MySQL估计使用索引比全表扫描还慢,则不会使用索引。
返回数据的比例是重要的指标,比例越低越容易命中索引。记住这个范围值——30%,后面所讲的内容都是建立在返回数据的比例在30%以内的基础上。
2)前导模糊查询不能命中索引。
EXPLAIN SELECT * FROM user WHERE user_name LIKE '%s%'; 
非前导模糊查询则可以使用索引,可优化为使用非前导模糊查询:
EXPLAIN SELECT * FROM user WHERE user_name name LIKE 's%';
3)数据类型出现隐式转换的时候不会命中索引,特别是当列类型是字符串,一定要将字符常量值用引号引起来。
EXPLAIN SELECT * FROM user WHERE user_name = 1;
EXPLAIN SELECT * FROM user WHERE user_name = '1';
4)union 能够命中索引,建议使用union。in、or不能命中索引
union:
EXPLAIN SELECT*FROM user WHERE status =1
UNION ALL
SELECT*FROM user WHERE status = 2;
in:
EXPLAIN SELECT * FROM user WHERE status IN (1,2); 
or:
EXPLAIN SELECT * FROM user WHERE status=1 OR status=2; 
如上图,实际上并没有走索引,为什么?
为什么where条件中使用or索引不起作用?where条件中使用or,索引就会失效,会造成全表扫描 是误区!!!
一,要求使用的所有字段,都必须建立索引。
二,数据量太少,制定执行计划时发现全表扫描比索引查找更快。

5)负向条件查询不能使用索引,可以优化为in查询。
负向条件有:!=、<>、not in、not exists、not like等。
负向条件不能命中缓存:
EXPLAIN SELECT * FROM user WHERE status !=1 AND status != 2;

可以优化为in查询,但是前提是区分度要高,返回数据的比例在30%以内:

8)范围条件查询可以命中索引。范围条件有:<、<=、>、>=、between等。
status,age列分别创建索引
user表索引详情:

范围条件查询可以命中索引:
EXPLAIN SELECT * FROM user WHERE status > 5;
范围列可以用到索引(联合索引必须是最左前缀),但是范围列后面的列无法用到索引,索引最多用于一个范围列,如果查询条件中有两个范围列则无法全用到索引:
EXPLAIN SELECT * FROM user WHERE status>5 AND age<24;
如果是范围查询和等值查询同时存在,优先匹配等值查询列的索引:
EXPLAIN SELECT * FROM user WHERE status>5 AND age = 28;
8)数据库执行计算不会命中索引。
EXPLAIN SELECT * FROM user WHERE age>24;

EXPLAIN SELECT * FROM user WHERE age+1>24;

计算逻辑应该尽量放到业务层处理,节省数据库的CPU的同时最大限度的命中索引。
9)利用覆盖索引进行查询,避免回表。
被查询的列,数据能从索引中取得,而不用通过行定位符row-locator再到row上获取,即“被查询列要被所建的索引覆盖”,这能够加速查询速度。
user表的索引详情:

因为status字段是索引列,所以直接从索引中就可以获取值,不必回表查询:
Using Index代表从索引中查询:
EXPLAIN SELECT status FROM user where status=1;

当查询其他列时,就需要回表查询,这也是为什么要避免SELECT*的原因之一:
EXPLAIN SELECT * FROM user where status=1;

10)建立索引的列,不允许为null。
单列索引不存null值,复合索引不存全为null的值,如果列允许为null,可能会得到“不符合预期”的结果集,所以,请使用not null约束以及默认值。
remark列建立索引:
ALTER TABLE user ADD INDEX index_remark (remark);

IS NULL可以命中索引:
EXPLAIN SELECT * FROM user WHERE remark IS NULL;

IS NOT NULL不能命中索引:
EXPLAIN SELECT * FROM user WHERE remark IS NOT NULL;

虽然IS NULL可以命中索引,但是NULL本身就不是一种好的数据库设计,应该使用NOT NULL约束以及默认值。
a. 更新十分频繁的字段上不宜建立索引:因为更新操作会变更B+树,重建索引。这个过程是十分消耗数据库性能的。
b. 区分度不大的字段上不宜建立索引:类似于性别这种区分度不大的字段,建立索引的意义不大。因为不能有效过滤数据,性能和全表扫描相当。另外返回数据的比例在30%以外的情况下,优化器不会选择使用索引。
c. 业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引。虽然唯一索引会影响insert速度,但是对于查询的速度提升是非常明显的。另外,即使在应用层做了非常完善的校验控制,只要没有唯一索引,在并发的情况下,依然有脏数据产生。
d. 多表关联时,要保证关联字段上一定有索引。
e. 创建索引时避免以下错误观念:索引越多越好,认为一个查询就需要建一个索引;宁缺勿滥,认为索引会消耗空间、严重拖慢更新和新增速度;抵制唯一索引,认为业务的唯一性一律需要在应用层通过“先查后插”方式解决;过早优化,在不了解系统的情况下就开始优化。
3. 小结
对于自己编写的SQL查询语句,要尽量使用EXPLAIN命令分析一下,做一个对SQL性能有追求的程序员。衡量一个程序员是否靠谱,SQL能力是一个重要的指标。作为后端程序员,深以为然。
参考文档
相关文章
- MySQL如何利用索引优化ORDER BY排序语句
- Navicat Premium连接MySQL 1251错误和Mysql初始化root密码和允许远程访问
- mysql索引合并:一条sql可以使用多个索引
- Linux - mysql 异常: ERROR! MySQL is not running, but lock file (/var/lock/subsys/mysql) exists
- mysql:联合索引及优化
- XtraBackup出现 Can't connect to local MySQL server through socket '/tmp/mysql.sock'
- MySQL索引背后的数据结构及算法原理(转)
- mysql数据库-索引-长期维护
- mysql 重新整理——索引优化explain字段介绍一 [九]
- mysql 重新整理——索引优化一个简单的案例 [十一]
- mysql 重新整理——索引优化explain字段介绍一 [九]
- mysql 重新整理——索引优化explain简单介绍 [八]
- MYSQL避免全表扫描__如何查看sql查询是否用到索引(mysql)
- Mysql索引数据结构有多个选择,为什么一定要是B+树呢?_面试 (MySQL 索引为啥要选择 B+ 树)
- MySQL索引背后的数据结构及算法原理
- 012-MySQL 索引添加以及优化说明
- mysql 添加索引
- Groonga开源搜索引擎——列存储做聚合,没有内建分布式,分片和副本是随mysql或者postgreSQL作为存储引擎由MySQL自身来做分片和副本的
- 数据结构与算法_48 _ B+树:MySQL数据库索引是如何实现的
- MySQL 索引与性能调优
- golang操作mysql数据库(Go-SQL-Driver/MySQL)
- MySQL高级篇(SQL优化、索引优化、锁机制、主从复制)
- MySQL索引优化