
ODPS SQL费用估算与控制
ODPS老用户应该都了解过其计费方式,如果不清楚计费方式,可以参考阿里云文章:https://help.aliyun.com/document_detail/27989.html?spm=5176.doc27833.6.701.8vl39E 。阿里云本身提供了CU(固定资源)和计算两种计费方式,而我们公司在BI上云的过程中使用的是采云间,它仅支持SQL计算计费方式步支持CU方式,而保险行业又是一个基于数据才能工作的行业, 每个部门都有自己的数据需求,在数据仓库之上的数据用户和应用又是非常的多,这使得我们在ODPS SQL费用控制上遇到了很大的挑战。刚开始3个月,我们的ODPS费用都是差好几倍,这与我们的业务增长两完全不符合。 在使用ODPS的前四个月我们面对如此大的费用差距,而我们的SQL 每个月都有几万次执行次数,几乎无从下手。
1 遇到费用差距如此之大,
那我们就要去找到那些费用非常高的SQL, 我们根据阿里云提供的SQL 执行日志,发现很多SQL 运行一次要数千元, 很多都是LEFT JOIN没有做到分区过滤造成,比如:a left outer join b on a.id = b.id where a.pt= "${date}" and b.pt= "${date}",对于b表的分区过滤是失效的,造成sql的全表扫描,而需要将其改成: a left outer join (select * from b where b.pt= "${date}" ) b on a.id = b.id where pt where a.pt= "${date}" 这样写才能做到过滤分区
2 还有一些SQL 有数千条,都是100元以上的费用, 主要原因由于每个SQL都是从最明细的底层表去抽取,造成SQL 的复杂度和输入数据量都非常得高。
二 解决方案
对于这样局面我们提供了三种解决方案,来改进这样的局面。
方案一: SQL 签名大家用过ORACLE 应该都知道AWR报表,里面可以根据同一个SQL ID在不同时间维度下进行SQL执行次数、平均执行时长、耗CPU率来分析性能问题,同样这对ODPS SQL同样适用,如下:
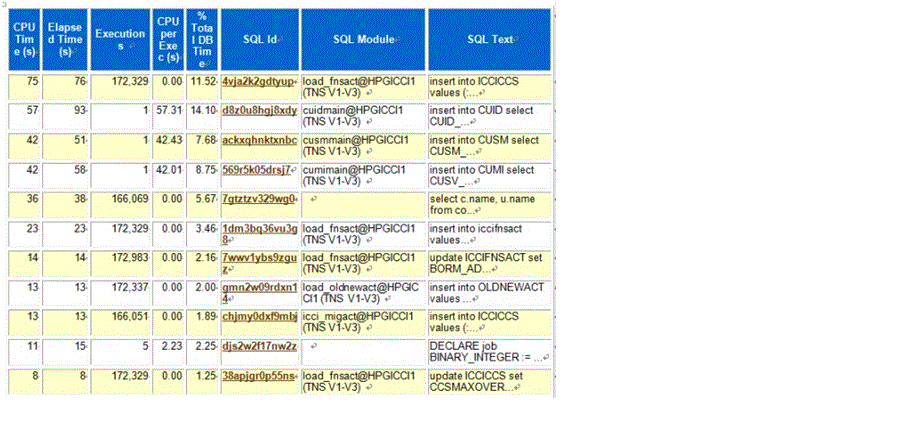
每个SQL都需要有一个唯一的签名才能做到, 我们的做法是用MD5算法进行哈希,生成一个128位的Hash Value,其中低32位作为HASH VALUE显示,SQL_ID则取了后64位,你可以用任何语言来实现。当这个SQL签名出来以后,我们很容易找到那些执行次数多, 数据量大,SQL复杂度高的SQL,给我们SQL 费用优化上带来了极大的便利。
方案二: SQL费用估算器接下来我们需要一个SQL估算器,我们每写完一个SQL都需要去估算下多少钱,我们才能上线,ODPS计算计费公式为:一次SQL计算费用 = 计算输入数据量 * SQL复杂度 * SQL价格, 那么我就需要用一个WEB界面来实现这个公式。 非常感觉阿里云提供了ODPS sdk,使得用户可以构建给予ODPS的SAAS服务。
下面是我的工程目录:

其中最核心的API调用如下,SqlCostTask 这个函数就能获取(计算输入数据量 * SQL复杂度 * SQL价格)这三个变量了:

估算界面:

方案三:在数据仓库之上构建汇总层
在我们知道哪些SQL费用比较高以后,我们就可以有针对性地优化, 最好的方式就是根据需求的共性在DW 层之上建立一层汇总层, 很报表和对帐MaxCompute最佳实践
ODPS SQL优化总结 ODPS(Open Data Processing Service)是一个海量数据处理平台,基于阿里巴巴自主研发的分布式操作系统(飞天)开发,是公司云计算整体解决方案中最核心的主力产品之一。本文结合作者多年的数仓开发经验,结合ODPS平台分享数据仓库中的SQL优化经验。
DataWorks开发ODPS SQL开发生产环境自动补全ProjectName DataWorks标准模式下,支持开发环境和生产环境隔离,开发环境和生产环境的数据库表命名有所区别,如果需要在开发环境访问生产环境的数据库表或者跨项目空间访问其他项目空间的表,需要根据projectA.tablename命名规范严格区分数据库表名,避免误操作生产环境。 开发环境SQL任务中需要使用【开发环境空间.表名】来使用表,发布到生产环境时,需要手动把开发环境空间改成生产环境空间名称才能发布。本文针对此类场景实现在DataWorks能够自动识别任务在开发环境使用开发环境的名称,在生产环境使用生产环境的名称。
浅谈ODPS SQL聚合计算与联结 本文针对ODPS SQL以及相应数据表开发进行介绍,主要topic为统计表聚合计算,涉及的内容包括:统计聚合计算样本代码示例,group by筛选痛点介绍,rank与dense_rank函数区别解析,结果输出时联结的运用join, left outer join, right outer join和full outer join的解析。
MaxCompute 费用暴涨之新增SQL分区裁剪失败 现象:因业务需求新增了SQL任务,这SQL扫描的表为分区表,且SQL条件里表只指定了一个分区,按指定的分区来看数据量并不大,但是SQL的费用非常高。费用比预想的结果相差几倍甚至10倍以上。 若只知道总体费用暴涨,但是没明确是什么任务暴涨,可以可以参考查看账单详情-使用记录文档,找出费用异常的记录。
相关文章
- 大话系统之权限控制
- JS实现input中输入数字,控制每四位加一个空格(银行卡号格式)
- 第5章流程控制语句
- 树莓派python 控制GPIO
- 【学习总结】SQL的学习-2-sql操作
- 【学习总结】SQL的学习-1-初识数据库与sql
- C#修改文件或文件夹的权限,为指定用户、用户组添加完全控制权限
- SQL SERVER服务器链接连接(即sql server的跨库连接)
- SQL SERVER服务器链接连接(即sql server的跨库连接)
- SQL SERVER服务器链接连接(即sql server的跨库连接)
- 怎样能写出性能优良的SQL语句 从sql语句提高数据库的性能
- 【无人机群】用于控制具有污染物云跟踪的模拟无人机群研究(Matlab代码实现)
- 基于阈值控制的一种改进鲸鱼算法-附代码
- 【SQL干货】一条sql按季度统计交易数据
- c# 控制职能运行单一实例,再次运行显示已经运行的实例
- Oracle PL/SQL中的循环处理(sql for循环)
- SQL注入 Sqli-labs-Less-21(笔记)——还是回显注入 使用union select即可 但是要注意sql括号闭合 也可以报错注入
- Linux【实操篇】—— Shell 编程入门、变量、运算符、条件判断、流程控制
- 全面分析 MySQL并发控制