
INS/GNSS组合导航(四)卡尔曼滤波比较之KF/EKF/UKF/PF
1.摘要
卡尔曼滤波自1960年代发表至今,在各个时间序列估计领域尤其是位置估计、惯性导航等得到了广泛的应用,后续逐渐演化出EKF、UKF以及PF,本文重点对比KF、EKF与UKF及PF的差异及演化来历。
2.卡尔曼滤波由来
卡尔曼滤波(Kalman Filter)是一种高效的自回归滤波器,它能在诸多不确定性情况的组合信息中估计动态系统的状态,是一种强大的且通用性极强的工具。由鲁道夫.E.卡尔曼于1961年前后首次提出,并首先应用于阿波罗计划的轨道预测。
3.卡尔曼滤波器原理
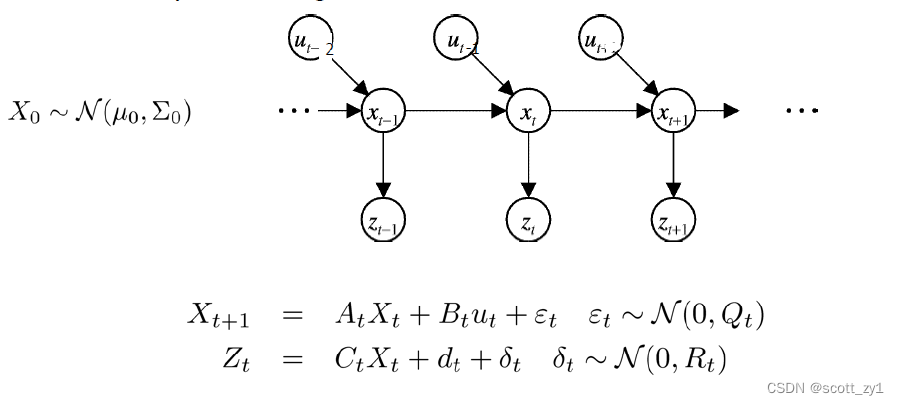
卡尔曼滤波模型假设k时刻的真实状态是从(k − 1)时刻的状态演化而来,符合下式:
其中
是作用在
上的状态变换模型(变换矩阵)。
是作用在控制器向量
上的输入-控制模型。
是过程噪声,并假定其符合均值为零,协方差矩阵为
的多元正态分布。
时刻k,对真实状态 的一个测量
满足下式:
其中是观测模型,它把真实状态空间映射成观测空间,
是观测噪声,其均值为零,协方差矩阵为
,且服从正态分布。
初始状态以及每一时刻的噪声都认为是互相独立的,即协方差矩阵非对角元素全部为0。
实际上,很多真实世界的动态系统都并不确切的符合这个模型;但由于卡尔曼滤波器被设计在有噪声的情况下工作,一个近似的符合已经可以使这个滤波器非常有用了,实际应用发现,对于并不完全符合上述模型的动态系统也能得到较好的近似效果。更多其它更复杂的卡尔曼滤波器的变种,在下边讨论中会有具体描述。
4.EKF与UKF到PF
4.1 算法差异推导
4.1.1 从 KF 到 EKF
对于KF,本质上来说,它是贝叶斯滤波器的一个特例,即这个滤波器是动力学模型和测量模型的一个线性组合。



通过上述对比可知,KF模型的状态转移矩阵具有线性化特点,体现在系数矩阵,
而对于EKF模型来说,状态转移对应下一时刻的状态量是上一时刻的非线性函数,不能直接得到,需对
采用一阶Taylor系列展开式来近似。

4.1.2 从 EKF 到 UKF
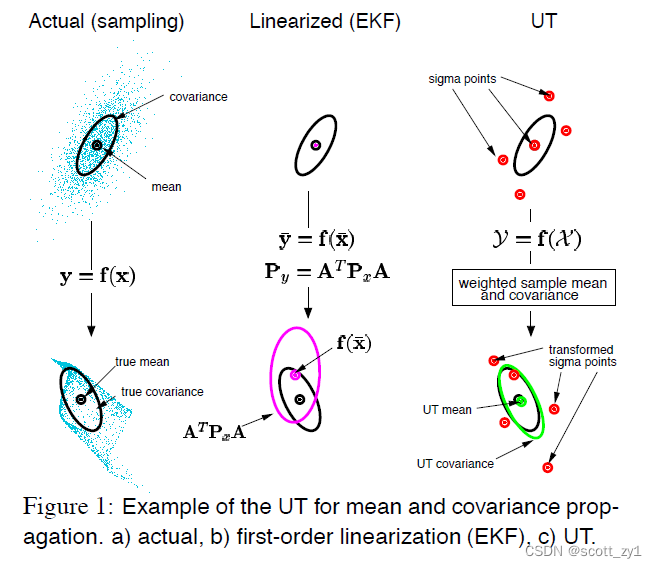
上述EKF中通过非线性函数的一阶Taylor展开式实现线性化,而在UKF则不再采用这种简单的一阶线性化,原因在于对于高度非线性系统,这种舍去二阶以上的线性化处理并不合适,那么从EKF到UKF,最终使得效果好于EKF的直觉在哪里呢?具体可见如下的对比。
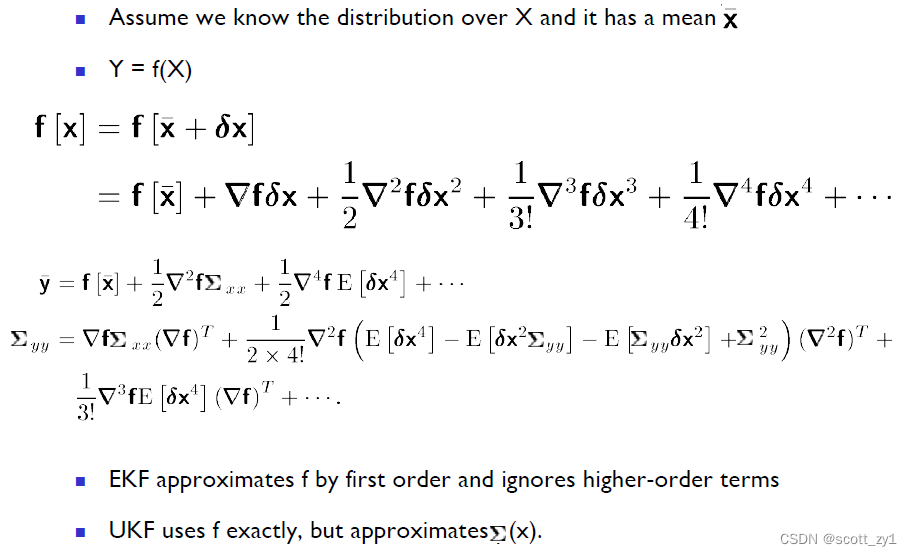
由上可知,在UKF中,不再使用函数的线性近似,而是直接使用了函数本身,但是对函数的自变量也就是数据点的协方差进行近似。直观对比EKF与UKF在算法实现上的差异如下:

对于UKF的均值与协方差的更新过程详细步骤如下:

上述详细算法步骤第12步对应的推导过程如下:
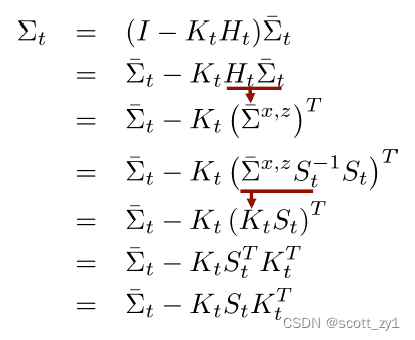
UKF vs. EKF
—— Same results as EKF for linear models
—— Better approximation than EKF for non-linear models—— Differences often “somewhat small”
—— No Jacobians needed for the UKF
—— Same complexity class
—— Slightly slower than the EKF
—— Still requires Gaussian distributions
4.1.3 从 UKF 到 PF
粒子滤波器(PF:Particle Filter)的思想是基于蒙特卡罗方法,它使用粒子集来表示概率,可以用于任何形式的状态空间模型。核心思想是通过从后验概率中提取随机状态粒子来表达其分布。它是一种顺序重要性采样方法(Sequential Importance Sampling)。
具体来说,引入PF算法,按照如下几个步骤:
a)根据先验概率得到N个初始化粒子。在机器人定位中,粒子的初始分布可设定为均匀分布或高斯分布,协方差矩阵和均值等根据实际情况人为设定。
b)根据机器人的车轮运动速度或者里程对粒子进行状态转移,即将粒子的信息带入机器人的运动模型中,加入控制噪声并产生新的粒子。
c)通过观测模型得到机器人当前的观测位姿。
d)根据观测得到的位姿计算每个粒子的权值。 ,其中
是k时刻第i个粒子的权值,
是k-1时刻第i个粒子的权值,
是k时刻第i个粒子在这个位置时获得当前观测值的概率。而前一时刻每个粒子的权值在经过重采样之后等于
。
e)输出滤波结果。对每个粒子加权求和即可。
(f) 根据粒子当前权值进行重采样。重采样的方式有多种,例如系统重采样、多项式重采样、残差重采样、轮盘赌(独立随机重采样)等。

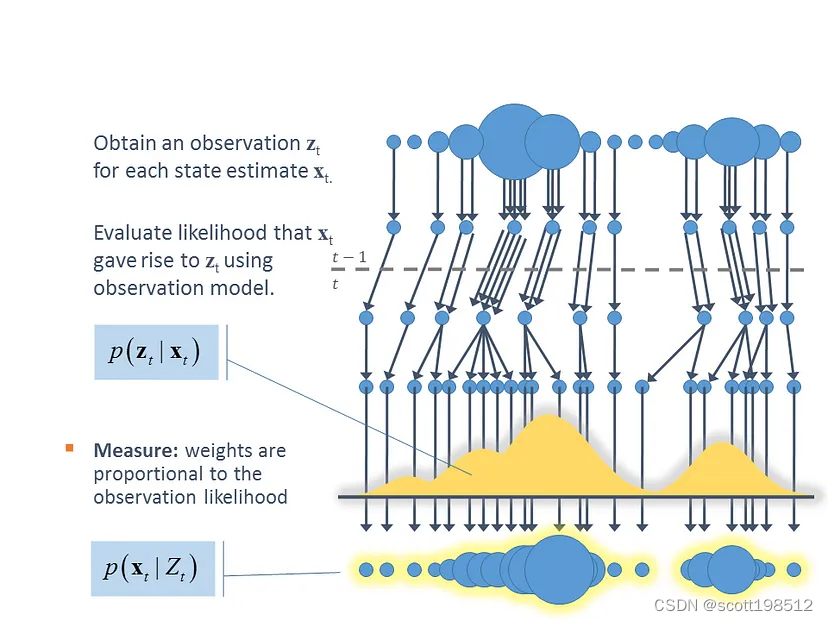

简单来说,粒子滤波法是指通过寻找一组在状态空间中传播的随机样本来逼近概率密度函数,并用样本均值代替积分运算,从而得到状态最小方差分布的过程。
这里的样本指的是粒子,当样本数时,可以逼近任意形式的概率密度分布。
虽然算法中的概率分布只是对真实分布的近似,但由于非参数的特点,可以摆脱求解非线性滤波问题时随机量必须满足高斯分布的约束,可以表示分布比高斯模型更广泛。 它还具有更强的建模可变参数的非线性特性的能力。因此,粒子滤波可以准确地表达基于观测和控制量的后验概率分布,通常可以用来解决SLAM问题。
4.2综合对比
对于KF、EKF、UKF、PF的主要差异,通俗一点说,主要如下:
1)卡尔曼滤波器 KF 是一种用作最小二乘误差优化器的滤波器,为了使其工作,在滤波器内部考虑的系统必须是线性的,即基于线性系统的前提假设。
2)为了使用KF对非线性系统进行状态估计或参数估计,一种可能的方法是围绕其当前状态对正在研究的系统进行线性化,并强制滤波器使用系统的这个线性化版本作为模型. 这是Extended Kalman Filter,或简称为EKF。
3)然而,由于EKF 不是很稳定,而且很多时候,当它确实收敛到“正确”解时,其收敛过程会非常缓慢。为了改进这个滤波器的固有不足,一些作者开始使用 Unscented Transformation,而不是使用线性化来预测被研究系统的行为。因此,具有 Unscented 变换(无迹变换)的 Kalman 滤波器称为 Unscented Kalman Filter,或简称为 UKF。
4)与 EKF 相比,UKF具有一些优势,因为 Unscented 变换在某种程度上比线性化更好地描述了非线性系统,因此该滤波器更迅速地收敛到正确的解。而使用 EKF,这个滤波器可能会变得不稳定,结果可能会出现偏差。
5)UKF没有采用线性化过程,这使得许多人认为它的适用性更广,能够对不可导的函数进行应用,然而实际在许多分段函数模型比如censored measurement model (审查量测模型)中,sigma的选点会导致不连续附近输出的均值和协方差产生偏差,同时初始统计结果也不再适用,进一步会导致结果的发散和有偏。这也就是现在诞生了很多加窗滤波和强跟踪滤波的原因。
6) 相比于UKF,PF即粒子滤波,指通过寻找一组在状态空间传播的随机样本的概率密度函数进行近似,以样本均值代替积分运算,从而获得状态最小方差分布的过程。这种特殊的随机样本就称为“粒子”。PF算法采用这些带有权值的随机样本(特殊样本粒子)来表示所需要的后验概率密度。
7)PF其实是一种蒙特卡罗方法对采样求数值解的过程。这个方法可以求解一般无法通过解析方法求解的方程积分。PF本质上是贝叶斯滤波器采用蒙特卡罗积分后进行数值积分得到的一个特例。
8)相比于KF/EKF/UKF等方法都有高斯分布假设,PF无论计算精度和计算速度都不可与UKF和EKF相比,它更像是为了解决非高斯滤波等假设局限性受制而采取的备选方案。
核心差异总结如下:
KF:线性化假设,求解线性系统,对应的是线性模型
EKF:求解对象是非线性系统,通过Taylor展开式,舍去高阶项,基于线性化思想来近似线性化
UKF:采用线性化近似很多高度非线性系统不合时宜,基于无迹变换,求解得到高斯分布来规避了线性化的行为,UKF的实现具体可分为以下几个步骤:
a) 计算一系列的sigma点
b)给每个sigma点分配一个权重
c)采用非线性变换得到一个点
d根据带权重的点计算一个高斯分布
PF 采用蒙特卡罗积分,适用于非高斯分布。PF属于无参数滤波,它没有具体的后验概率函数,其思路是利用粒子集近似系统的状态分布。所以它可以近似任何系统状态分布。这样的特性,不同于卡尔曼滤波很难实现全局定位,KF/EKF/UKF它主要用于位置追踪。PF则处理全局定位和机器人绑定问题奠定了基础。
PF的主要步骤如下:
1)用运动模型更新粒子集的预测状态。
2)用观测模型计算每个粒子的权重。
3)重采样粒子,使粒子集向权重大的粒子靠拢。
4)用粒子集的均值状态量来表征机器人的状态。
PF的主要问题:a) 粒子退化;b) 粒子枯竭
具体来说,PF算法中采用序贯重要性采样,会出现的一个常见问题就是粒子退化现象,即经过若干次迭代之后,除了少数几个粒子,大部分其他粒子的权值将小到可以忽略不计。粒子退化现象的原因在于,重要性权值的方差将随时间的推移而增加。因此,粒子退化问题的存在意味着大量的计算工作将浪费在更新那些对几乎为0的粒子上,严重是表现为粒子枯竭。
针对上述粒子退化和枯竭,对应的主要缓解措施:
1)重要性函数的选择
2)重采样
| 模型 | 适用对象 | 求解方法 | 计算复杂度/计算速度 | 应用广泛度 |
| KF | 线性系统与线性模型、 高斯分布 | 直接求解 | 容易/快 | 较多 |
| EKF | 一般非线性系统、 高斯分布 | Taylor展开式 | 一般/略慢于KF | 最多 |
| UKF | 高度非线性系统、 高斯分布 | 无迹变换 | 复杂/略慢于EKF | 很少 |
| PF | 高度非线性系统、 非高斯分布 | 蒙特卡罗积分 | 非常慢 | 一般 |
注意:因为多数系统可以近似为一般非线性,当系统非线性强度不大时,EKF算法和PF算法的估计精度相差不大,但PF算法计算复杂,跟踪时间长,实时性差。
UKF相比于EKF的适应性差,相比于PF处理高度非线性系统效果差,使得该方法的优势比较鸡肋,属于比EKF优势不明显,比PF又有不足,目前很少实用。
4.3 KF、EKF、UKF、PF算法实现总结
5. 完整推导
6. 参考文献
1.Applied Mathematics in Integrated Navigation Systems 3rd-AIAA
2.Strapdown Inertial Navigation Technology,2nd.
3.Principles of GNSS, Inertial, and Multisensor Integrated Navigation Systems,(2008)
4.Optimal Estimation of Dynamic Systems, Second Edition
5. A New Extension of the Kalman Filter to Nonlinear Systems
6. Probabilistic Robotics
7.The Unscented Kalman Filter for Nonlinear Estimation
相关文章
- Java 字符串与对象进行比较 compareTo()
- 数据库函数--nvl、coalesce、decode比较
- 《Python密码学编程》——2.8 使用在线比较工具检查输入的代码
- JSTL时间比较,jstl日期比较,jsp比较时间
- (数据科学学习手札05)Python与R数据读入存出方式的总结与比较
- Dynamic CRM 2013学习笔记(十)客户端几种查询数据方式比较
- RPC框架性能基本比较测试
- Bigdecimal 比较equals与compareTo
- MariaDB和MySQL性能测试比较
- 比较Activiti中三种不同的表单及其应用
- jodatime 时间比较
- 【笔记】每次开机后,第一次打开一个程序,比如浏览器或播放器,会比较慢。但关掉后第二次或第三次打开的话就会比较快了,这是为什么?