
【Python】变量的进阶
目录
变量的高阶部分,主要是针对变量在内存中的存储方式,以及变量存储和在不同场景中的应用的原理。
变量引用
变量的引用的定义:
如a = 1,定义一个变量通常有两个部分,等号左边的变量名以及等号右边的数据,通过这两个部分就能完成一个变量的定义。定义好的变量在内存中的存储也将分为两个部分:变量名的存储和数据的存储。定义变量语句的右边是数据,它在内存中有一块独立的存储的空间,它存储的是数据;同时变量名也有一块内存的空间,只不过它存储的是数据存储的内存地址。所以我们将变量名记录数据内存地址的动作称为变量的引用。
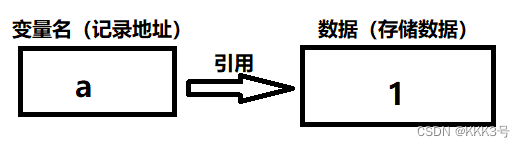
如果我们新创建一个变量名为b,而且给b的初值也赋予1,那么b变量名所指向的内存地址也将是变量a所指向的内存地址1。但当给a赋予新的数值后,a的引用将会发生改变,而b不会变。

变量引用在函数中的应用:
首先我们先来看我们向函数传递一个参数a时,我们传递的是变量名还是数据的问题。当我们向函数传递一个变量a时,我们实际上传递过去的是变量a的数据地址,即变量a引用的地址,结束的形参实际上就是接收到a所指向的数据地址,这点我们可以通过下面的代码1来验证。
知道了传递给函数的实参是以引用的方式传递后,我们再来看看函数返回值的传递方式:函数的返回值也是以引用的方式传递回去的,也就是说,如果我们用一个变量ret去接收函数的返回值,那么ret与函数中返回的数值这两个变量中所存储的地址都是相同的,如代码2所示。
代码1:
def func(a_func):
print(id(a_func))
a = 1
print(id(a))
func(a)

代码2:
def func(a_func):
print(id(a_func))
return a_func
a = 1
ret = func(a)
print(id(ret)) 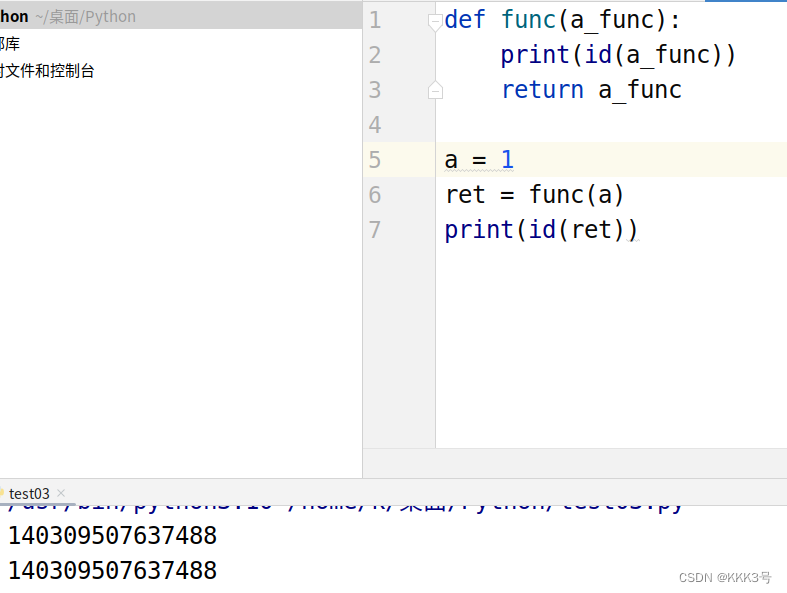
变量类型:
在Python中的变量除了按前面的分类方式以外,我们还可以将其分为可修改变量类型和不可修改变量类型。这里的所谓可修改和不可修改针对的是变量所引用的内存地址中的数据是否可以修改,而不是变量是否可以修改引用。换句话说,就是定义a = 1后,再定义a = 2,这叫做变量引用的修改,而本质上a所指向的无论是之前的1还是之后的2我们无法在内存中对这些数据进行修改(即这些数据还在内存中,没被修改,只不过是a没有引用它们罢了)。

其中我们最常见的不可修改变量类型是int、long、string、元组;而可修改数据类型是:字典和列表。这两个可修改的变量类型是直接通过它们提供的方法或者下标访问去直接修改它所引用的内存中的数据!
其中对于可变的数据类型如字典和列表等数据类型的数据修改是通过方法去修改的,如果我们通过赋值语句去修改就会改变变量名的引用!其中字典是有一个格外需要我们注意的地方,那就是它的键的数值必须是一个不可修改的数据类型,因为字典的键在字典定义后会被替换为一个哈希函数得出的特殊数值,而哈希函数的参数必须是一个不可修改的数据类型,所以我们不能够用字典或者列表作为字典的键。

变量类型
局部变量和全局变量:
所谓全局变量就是在程序中位于函数外的变量,它是一个可供所有该文件下的函数使用的变量;而局部变量就是位于函数内部的变量,它只供当前函数的使用,而其它的函数不能使用这个变量。所以我们不难看出,局部变量的生命周期比较短,它会在函数完成后被释放,而全局变量的生命周期更长。如下面的例子中:a和b都是局部变量,即a不能再func2函数中使用,b也不能在func1函数中使用。c是全局变量,c可以在任意位置使用,并且func1和func2中的局部变量没有任何关系。
def func1():
a = 10
def func2():
b = 20
c = 100
func1()
func2()关于全局变量,在Python中也有一个特性,那就是全局变量不允许在函数中进行修改,也就是说如果出现了在函数中修改全局变量的情况,那么系统会默认这个语句是在函数中去定义一个新的局部变量而不是修改全局变量。由下面的图就可以知道,在调试func1函数的过程中,发现func1函数体内的语句a = 20系统默认是一个定义语句而不是赋值语句。

全局变量的修改:
由上面的问题,我们需要考虑全局变量要如何在函数体内对其进行修改的问题。在Python中提供了一个关键字global来对变量进行声明,声明其为一个全局变量,具体的用法是在变量修改语句前加上一句声明语句,声明要修改的变量为一个全局变量。我们可以通过下面的程序来进行修改全局变量a的数值:
a = 20
def func1():
global a
a = 10
print("未修改前:", a)
func1()
print("修改后:", a)得到的结果也是能够证明对a进行了修改:

代码结构:
考虑到全局变量和函数之间的一些关系,即如果我们函数内部需要使用到某个全局变量,那么我们必须要保证这个全局变量是在函数调用之前就被定义的,否则会出现未定义的变量。正因为有这类问题,所以我们必须要规划好我们代码的结构:

函数参数与返回值
函数返回值:
在Python中,因为有很多高级的变量容器,所以我们函数的返回值也会很丰富,可以一次性返回多个数据的集合体。这个常用的数据集合体是元组,即当我们想返回多个数据时,我们可以将这些数据打包到一个元组中,然后直接返回这个元组即可,其中这个元组的括号可以省略。
def func():
a = 10
b = 20
return a, b
get_a, get_b = func()
函数参数:
当我们向一个函数中传递参数时,接收的形参实际上是在内存中开辟一块新的空间去引用与实参相同的数据地址。所以当我们向形参中传递数据后,又在函数内部修改了形参,那么本质上相当于我们修改了形参的引用,而实参的引用则不会发生任何变化。

但是可变的数据类型就有点意外,当我们传递的是字典或者列表时,如果我们在函数内部使用了方法(注意,是使用了方法去修改,而不是赋值)去修改这个字典或者列表,那么这个字典或者列表的实参内容也会发生变化,这种变化就类似于我们传递的是一个指针,指针指向的内容发生了变化,那么原来的内容也会变化。(这里要特别注意一个点是列表中的+=代表的不是相加再赋值,而是调用extend方法,所以列表使用+=是会改变实参的!!!)

缺省参数:
缺省参数也就是我们调用函数时,有的参数已经有默认的数值,此时我们就可以不需要再像这个参数传递实参,这就叫做缺省参数。如果我们不向缺省参数传递实参,那么这个参数默认为它的默认值;如果我们传递实参,则以实参为主。通常情况下,我们应该选择常用的选项作为缺省参数的默认值。
缺省参数的两点注意事项:
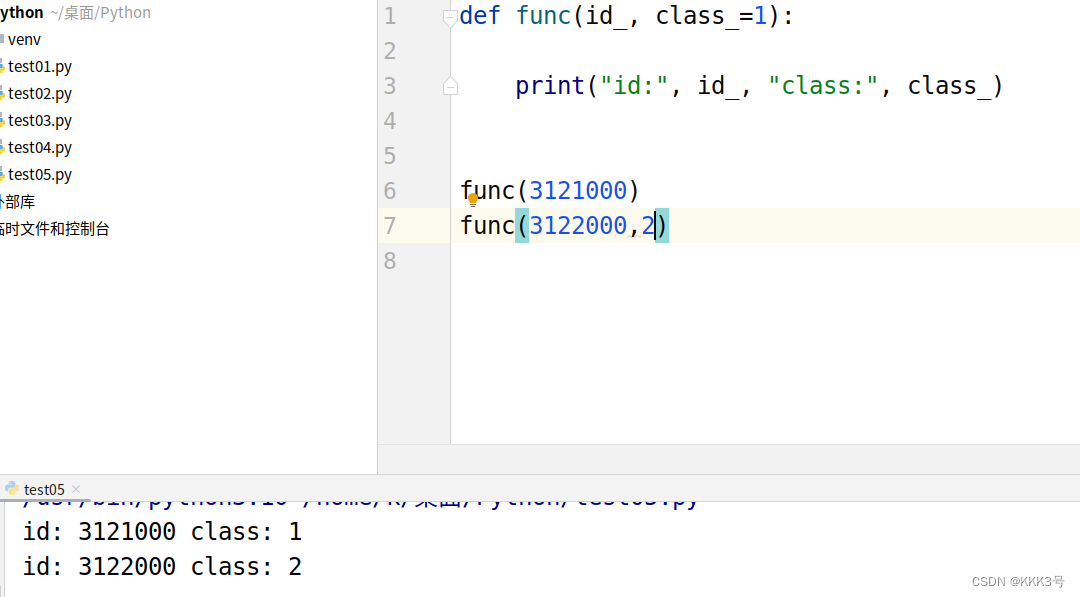
1、指定某个缺省参数的值:当我们一个函数中有多个缺省参数,而我们又只想向其中某个缺省参数传递数值,此时我们可以通过形参名 = 数值的方式来指定某个特定的缺省参数的数值。
def func(id_, class_=1, nation_="China"):
print("id:", id_, "class:", class_, "nation:",nation_)
func(3121001,nation_="Japan")2、缺省参数必须位于不缺省参数的后面:这也就说明缺省参数的形参排序的位置要在接受实参的参数后面,而不能有缺省参数的位置位于不缺省参数的形参前。也就是说下图是错误的,因为它的缺省参数位于其它正常参数前。
def func(id_, class_=1, nation_):
print("id:", id_, "class:", class_, "nation:",nation_)
多值参数:
多值参数就是函数的参数可以不确定。之前我们所写的代码中的函数的参数都是有指定的形参类型和形参数量的。而多值参数更具有灵活性,它的实参可以接收多数量的变量以及任意一种类型的数据。多值参数的实现往往是在元组和字典来实现的。因为元组可以接收不指定数量的数据值,字典则可以接收不指定数量的数据对。 多值参数的使用方法是将函数形参定义前加上 *(星号)代表其可以接收数据存储到元组中;以及将函数形参定义前加上**(两个星号)代表其可以接受数据存入字典中。
定义方式:def func(*args, **kwargs):
接收参数为元组的格式:func(1, 2, 3, 5, 4, 6, 8, 6, 6)(任意多的数据)
接收参数为字典的格式:func(name="kkk")(任意多的”变量 = 数据“形式)
def func(*args, **kwargs):
print(args)
print(kwargs)
func(1, 2, 3, 5, 4, 6, 8, 6, 6)
func(name="kkk")
拆包:
在上面的多值函数基础上,如果我们传递的参数本身就是一个元组和一个字典,此时编译器也会默认将它们当作独立的两个变量传递给 *args,而不会把字典中的内容传递给**kwargs,要想将字典中的内容独立传递给**kwargs,我们需要在传递参数时就将定义好的元组前加上*,定义好的字典前加上**,这样编译器就会默认将我们的元组和字典中的每一个参数都拿出来传递,这个操作就是拆包。


相关文章
- 【Python成长之路】python 基础篇 -- global/nonlocal关键字使用
- python之simplejson,Python版的简单、 快速、 可扩展 JSON 编码器/解码器
- python函数——形参中的:*args和**kwargs
- 【Python实战】python中含有中文字符无法运行
- Python 日期和时间_python 当前日期时间_python日期格式化
- python处理xml文件
- python: 安装DeOldify库:黑白图片上色(Python 3.7.15)
- 强化学习笔记:基于价值的学习之价值计算(python实现)
- Python:更改默认启动的python程序及其对应的安装包路径(更改pip的默认安装包的路径)图文教程之详细攻略
- Python之matplotlib:基于matplotlib库利用python语言实现一张画布显示多张图的多种方法
- Python编程语言学习:包导入和模块搜索路径(包路径)简介、使用方法(python系统环境路径的查询与添加)之详细攻略
- Python编程语言学习:python的列表的特殊应用之一行命令实现if判断中的两类判断
- Python可视化数据分析01、python环境搭建
- python副业推荐以及渠道介绍,接单注意事项,超详细
- Python常用语法有哪些 如何快速入门Python开发
- 〖Python语法进阶篇㉑〗- 综合实战 - 抽奖系统之优化补充
- 〖Python 数据库开发实战 - Python与Redis交互篇⑥〗- redis-py 的事务函数
- Python不用理解进程,线程实现多任务就是这么简单
- 【Python成长之路】python 基础篇 -- 装饰器【华为云分享】
- 10个Python实战编程项目,有趣又好玩
- 智联招聘获取python岗位的数据
- 【华为OD机试Python实现】HJ33 整数与IP地址间的转换(中等)
- 【华为机试真题 Python实现】成绩的及格线
- 【华为OD机试 2023】 数组合并(C++ Java JavaScript Python)
- python pandas数据分析操作
- python之使用paho实现mqtt客户端(亲测可用)
- C++调用C++项目中的Python脚本中的函数和类。,在,工程,python
- A guide to analyzing Python performance
- python基础===Python 迭代器模块 itertools 简介
- 【Leetcode刷题Python】剑指 Offer 11. 旋转数组的最小数字
- 【异常】前端ERR! stack Error: Can‘t find Python executable “python“, you can set the PYTHON env variable.