
各式各样的attention改进
多头注意力机制,各式各样的attention改进,Transformer模型架构.刷到一个『awesome-fast-attention』大列表,整理了一系列关于attention的高效改进文章,包括论文、引用量、源码实现、算法复杂度以及关键亮点。其中一部分论文,我们在之前的『Transformer Assemble』系列文章中也都有作过解.
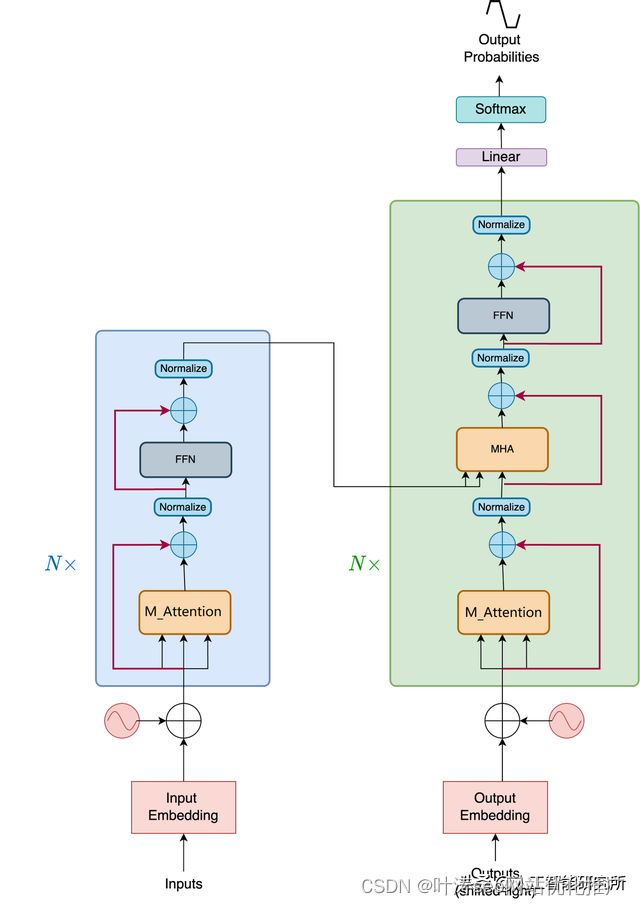
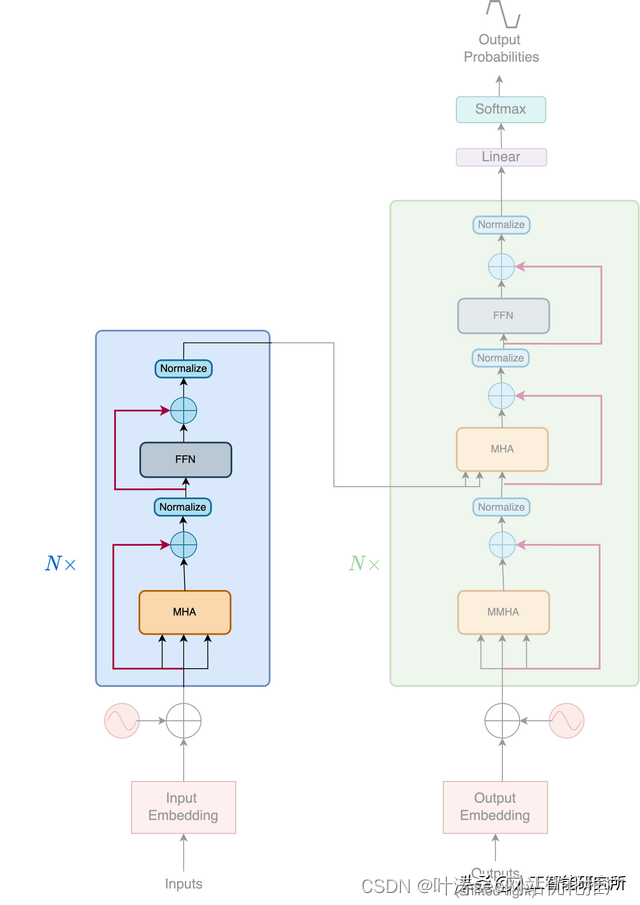
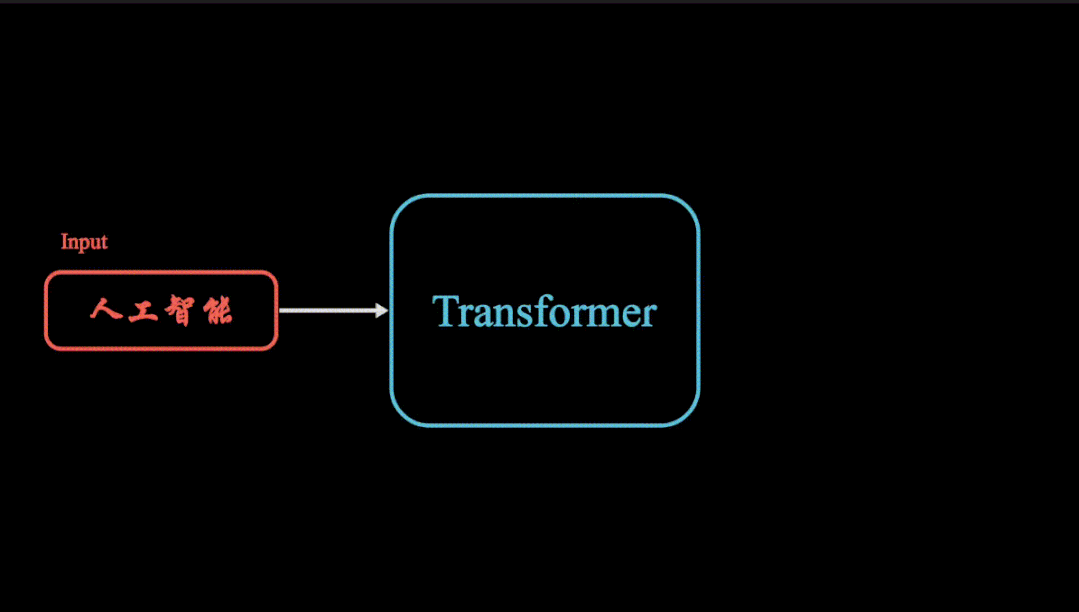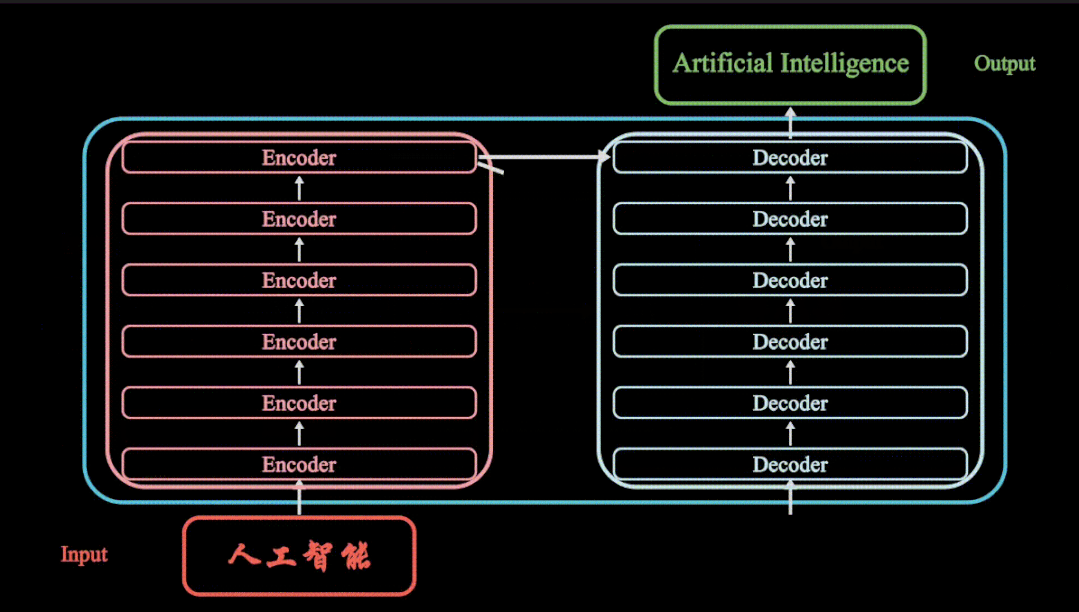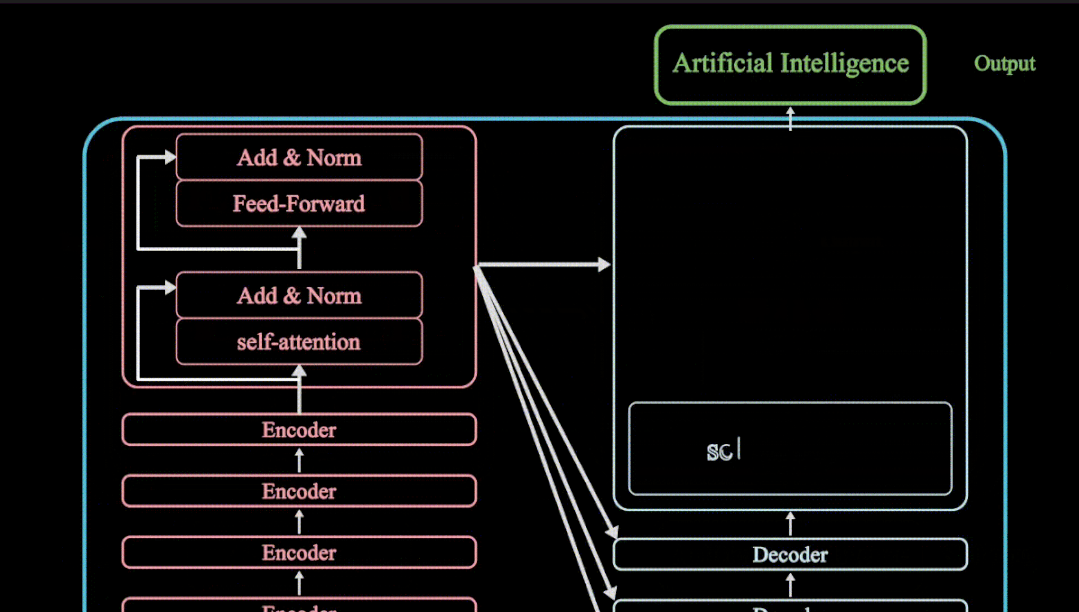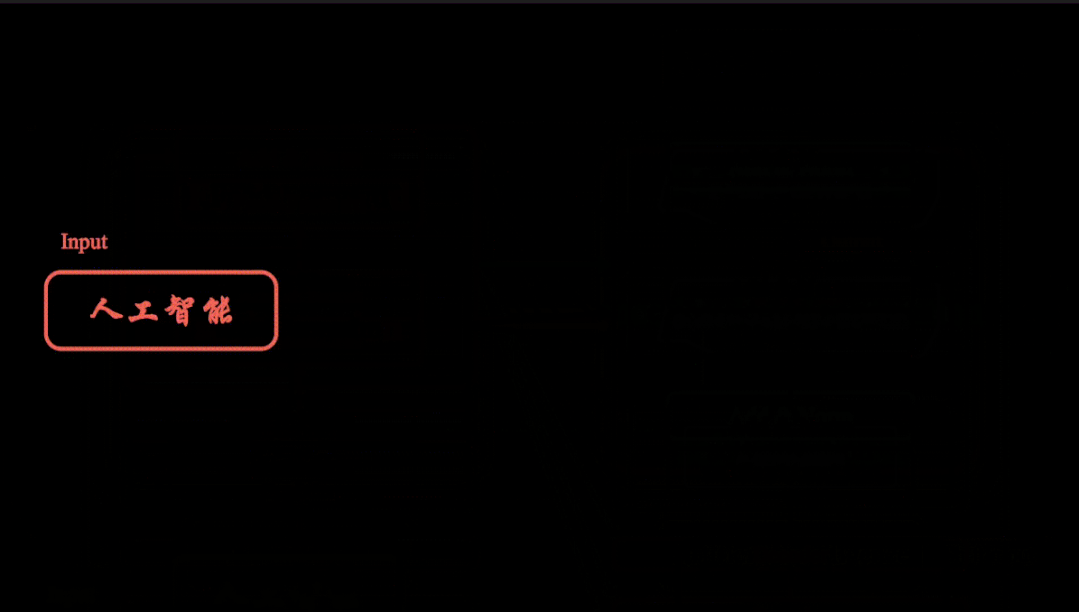
Transformer 由两个独立的模块组成,即Encoder和Decoder
Transformer
Encoder
编码器是一个堆叠N个相同的层。每层由两个子层组成,第一个是多头自注意力机制,第二个是简单的全连接的前馈神经网络。论文的作者还使用了ADD&Norm的残差连接与归一化操作
Encoder
当然,输入数据需要经过word-embedding与位置编码后,然后再传递给多头注意力机制,当然关于位置编码与详细的word-embedding操作可以参考如下动画视频教程,使用矩阵变化动画来讲解位置编码与word-embedding
Decoder
解码器层与编码器类似,都是堆叠N个相同的层,但是解码器每层有三个子层组成
除了编码器层中的两个子层之外,解码器还插入了第三个子层,该子层对编码器的输出执行多头注意力机制,当然解码器还有三个ADD与Norm的残差与归一化层,这里需要注意一下,其解码器的输入的第一个子层是带掩码的多头注意力机制,为何需要掩码,掩码如何操作?pad mask与sequence mask的作用是什么?如下视频教程都有详细的讲解
transformer模型视频教程
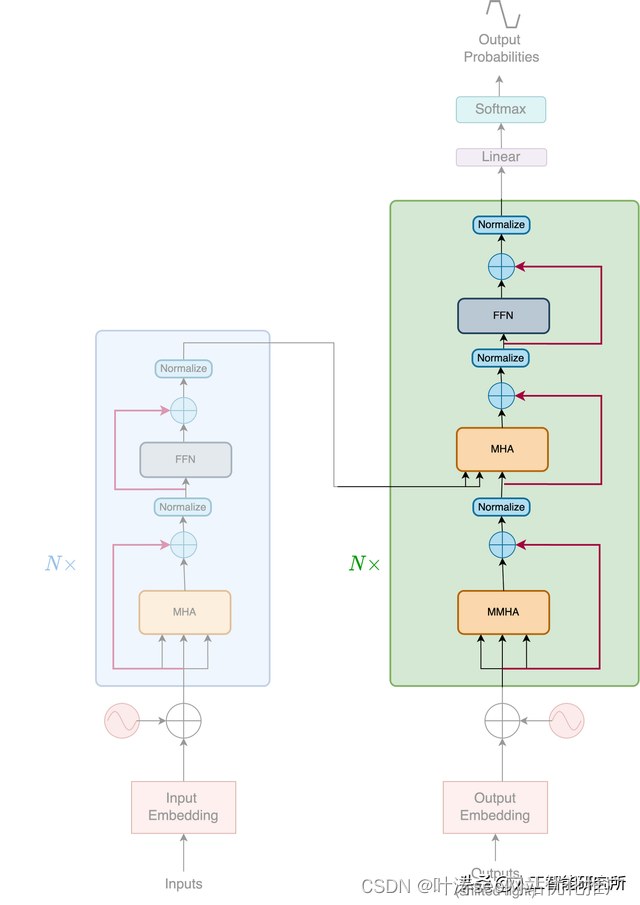
Decoder
其输入部分与编码器一致,都是需要word-embedding与位置编码后传递给多头注意力机制
编码器和解码器是围绕一个称为多头注意力模块的中心部分构建的。它将 Transformers 置于深度学习食物链的顶端。一经发布,Transformers模型便横扫了很多大的模型,特别是NLP领域大杀四方。
其实,在Transformers发布前,也有类似的模型结构,我们来演变一下Transformer模型的注意力机制
——2——
Transformers模型版本1
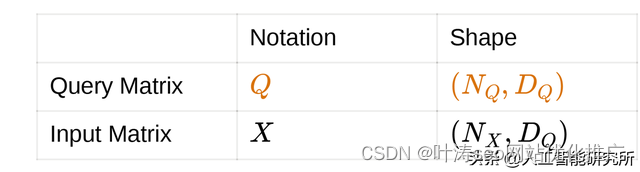
为了直觉的理解注意力,我们从输入矩阵X与查询矩阵Q开始,我们来计算输入矩阵与查询矩阵的相似度,得到相似度分数后,我们将输入矩阵转换为输出向量,输出向量是输入矩阵的加权求和。直观地说,加权求和得到的矩阵应该比原始矩阵的信息更丰富,其示意图如下
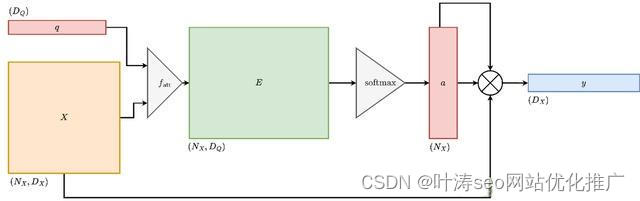
Transformers模型版本1
输入:

输入:
相似函数: fatt是一个**前馈网络**。前馈网络接受Q与X矩阵,并将它们都投影到维度DE.
输出:

输出
——3——
Transformers模型版本2
版本2的改进点是使用点积操作来替换前馈神经网络,事实证明,这是十分有效的,并且效果明显
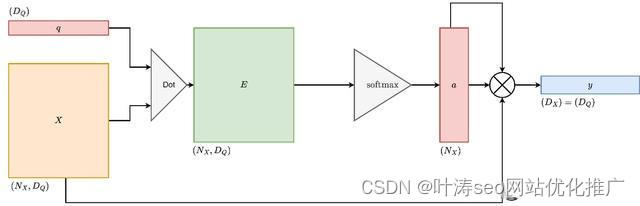
Transformers模型版本2
输入:

输入:
相似函数:点积操作
输出

输出
——4——
Transformers模型版本3
版本三的改进,也是transformer模型提出的一个概念,缩放点积,而不是正常的点积操作,这里的点积与标准的点积操作完全一致,只是作者提出了一个缩放系数的概念,缩放比例一般是1/根号下dim.
注意力机制的问题:
梯度消失问题:神经网络的权重与损失的梯度成比例地更新。问题是,在某些情况下,梯度会很小,有效地阻止了权重更新。这反过来又阻止了神经网络的训练。这通常被称为梯度消失问题。
Unnormalized softmax:考虑一个正态分布。分布的 softmax 值在很大程度上取决于它的标准差。由于标准偏差很大,softmax 只存在一个峰值,其他全部为0。我们可以随机生成一些数据来可视化这个问题
import torch
import numpy as np
import torch.nn as nn
import matplotlib.pyplot as plt
a = np.random.normal(0,100,size=(20000))
plt.hist(a)
plt.show()
创建均值为 0、标准差为 100 的正态分布
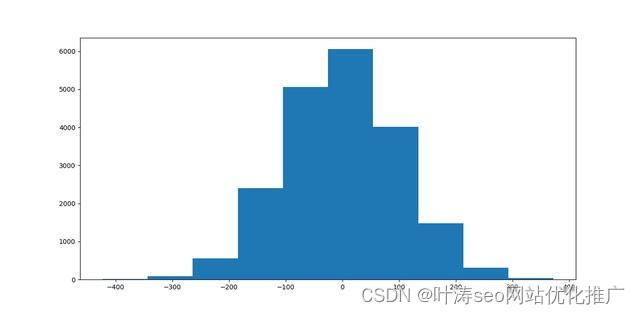
正态分布的直方图
import torch
import numpy as np
import torch.nn as nn
import matplotlib.pyplot as plt
#import tensorflow as tf
a = np.random.normal(0,100,size=(20000))
#plt.hist(a)
#plt.show()
#attn = tf.nn.softmax(a)
attn = nn.Softmax(dim=-1)(torch.from_numpy(a))
plt.plot(attn)
plt.show()
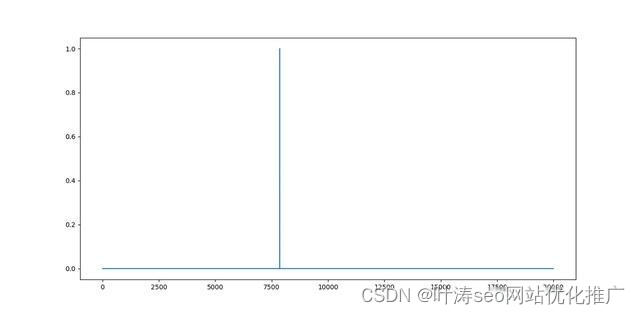
Softmax 可视化
导致梯度消失的非归一化 softmax
我们可以考虑使用logits的方法来进行softmax操作,这样我们就得到了数据的交叉熵,softmax的错误输出,将会被反向传播,那么就跟我们以上得到的数据,经过softmax后,只存在一个数据为1的值,其他地方全部是0 ,那么数据为1的值会被神经网络反向传播,而其他地方的数据并不会得到训练,这样就产生了梯度消失的问题
解决方案
为了解决由于未归一化的 softmax 导致的梯度消失问题,我们需要找到一种方法来获得更好的 softmax 输出。事实证明,分布的标准差很大程度上影响了 softmax 输出,我们依然初始化一个数据
import torch
import numpy as np
import torch.nn as nn
import matplotlib.pyplot as plt
#import tensorflow as tf
a = np.random.normal(0,100,size=(20000))
b = a/100
plt.hist(a)
plt.show()
plt.hist(b)
plt.show()
#plt.show()
#attn = tf.nn.softmax(a)
创建一个均值为 0,标准差为 100 的正态分布。并将标准差缩放到1。
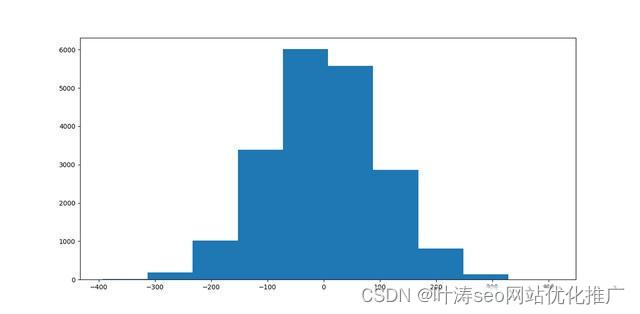
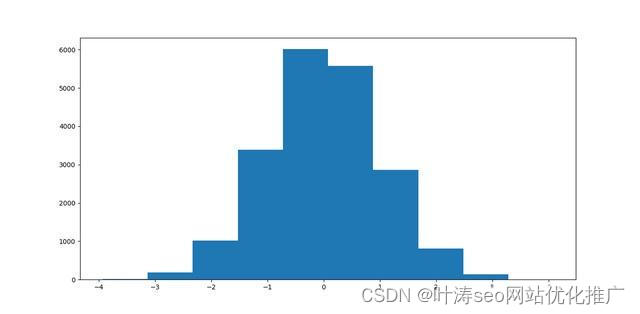
2种分布的直方图计划完全一致,只是数据的标准差一个是100,另一个是1,那么我们来看一下2种数据的softmax值
attn = nn.Softmax(dim=-1)(torch.from_numpy(a))
plt.plot(attn)
plt.show()
attn_b = nn.Softmax(dim=-1)(torch.from_numpy(b))
plt.plot(attn_b)
plt.show()
将 softmax 应用于两个分布
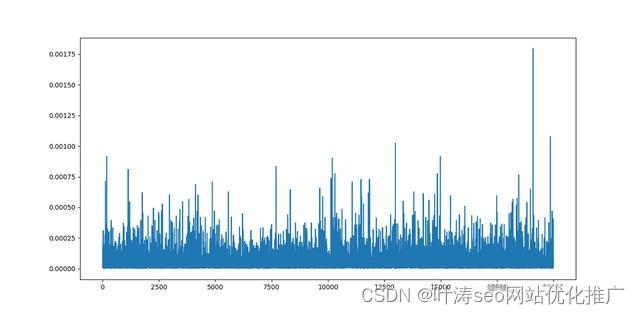
经过缩放的softmax
可以看到,经过缩放的softmax的分布比较分散,符合神经网络训练的要求,此时便可以让梯度进行反向传播,避免模型出现崩溃问题,这就是为什么transformer使用缩放点积。
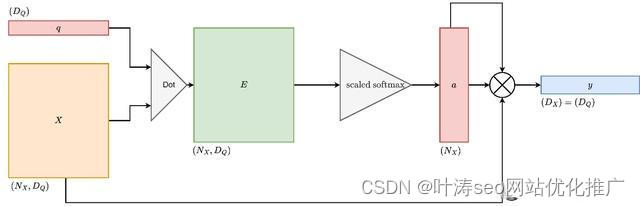
Transformers模型版本3
输入

输入
相似函数:点积

输出
——5——
Transformers模型版本4
前面的版本只有一个Q查询向量,我们把此向量扩展到多个查询向量,我们来计算输入矩阵与多个查询向量的相似性
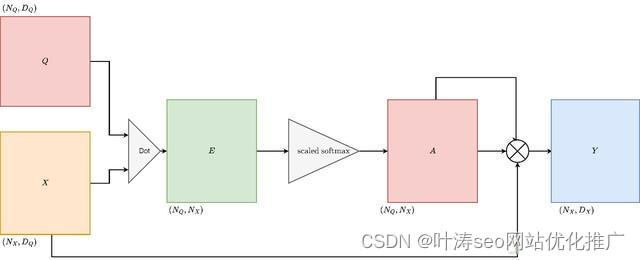
Transformers模型版本4
输入
相似函数:点积
输出:

——6——
Transformers模型版本5,交叉注意力
为了建立交叉注意力,我们做了一些改变。这些更改特定于输入矩阵。我们已经知道,注意力需要一个输入矩阵和一个查询矩阵。假设我们将输入矩阵投影成一对矩阵,即K矩阵和V矩阵。这样做是为了解耦复杂性。输入矩阵现在可以有一个更好的投影矩阵,负责建立注意力权重和更好的输出矩阵。Cross Attention的可视化如下
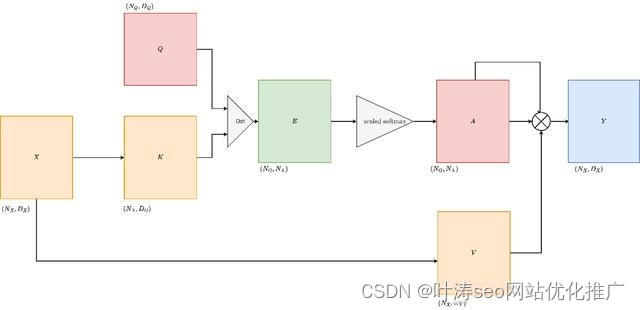
Cross Attention
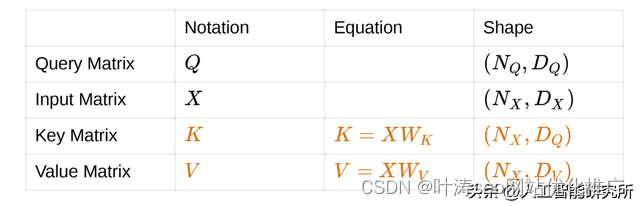

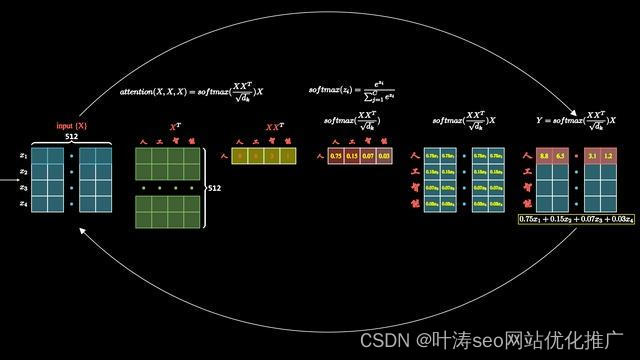
这就是我们所说的自注意力机制。它构成了 Transformer 模型的架构基础。Self-Attention 的可视化,从这里就便是我们重点讲解的transformer模型的自注意力机制了,如何来做注意力机制
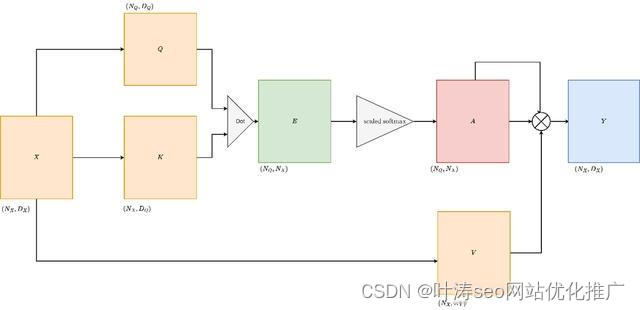
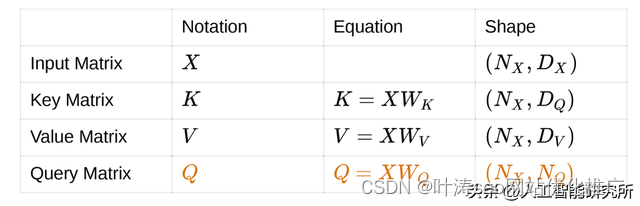


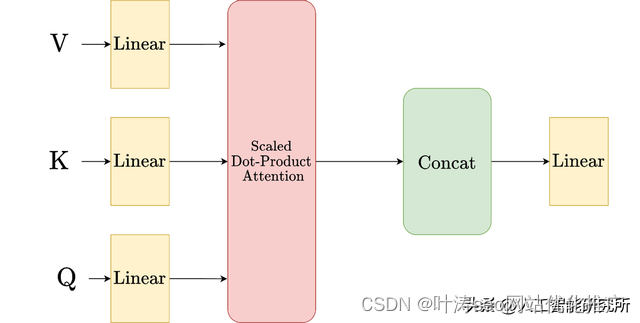
多头注意力机制
相信看到这里,你对注意力以及多头注意力有了清晰的认识,以上的每个版本的注意力,都在上一版本的基础上进行了改进
相关文章
- ThinkPad的挑战:不惧苹果 平板需要改进
- 改进了一下这个游戏的输出及思路,是不是好玩多了??:)
- Atitit.swift 的新特性 以及与java的对比 改进方向attilax 总结
- 通用的改进遗传算法求解带约束的优化问题(MATLAB代码)
- 改进粒子滤波的无人机三维航迹预测方法(基于Matlab代码实现)
- 负荷预测|一种改进支持向量机的电力负荷预测方法研究(Matlab代码实现)
- 基于人工势场法的二维平面内无人机的路径规划的matlab仿真,并通过对势场法改进避免了无人机陷入极值的问题
- 基于正交对立学习的改进麻雀搜索算法-附代码
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
- 操作数改进
- 全网独家首发|极致版YOLOv7改进大提升(推荐)网络配置文件仅24层!更清晰更方便更快的改进YOLOv7网络模型
- 改进YOLOv5系列:20.添加GAMAttention注意力机制
- 改进YOLOv5系列:21.添加CBAM注意力机制
- [YOLOv7/YOLOv5系列算法改进NO.34]更换激活函数为FReLU等十余种激活函数