
Scrapy返回空列表问题的解决办法
2023-09-11 14:19:30 时间
今天学习Scrapy框架时,调用下面的方法发送请求时返回的居然是一个空列表。
import scrapy
class Test01Spider(scrapy.Spider):
name = "test01"
allowed_domains = ["https://baike.baidu.com/item/%E7%99%BE%E5%BA%A6/6699?fromModule=lemma_search-box"]
start_urls = ["https://baike.baidu.com/item/%E7%99%BE%E5%BA%A6/6699?fromModule=lemma_search-box"]
def parse(self, response):
pass
get_text = response.xpath("/html/body/div[3]/div[2]/div/div[1]/div[4]/div[3]/text()").extract()
print(get_text)在我尝试很多遍,并且检查发现xpath没错的情况下还是返回空列表。

后面上网搜了很多解决方案,发现是头信息里的cookie没有设置,Scrapy默认用了它内部设置的头信息。于是对setting里面的内容进行修改就可以了 :
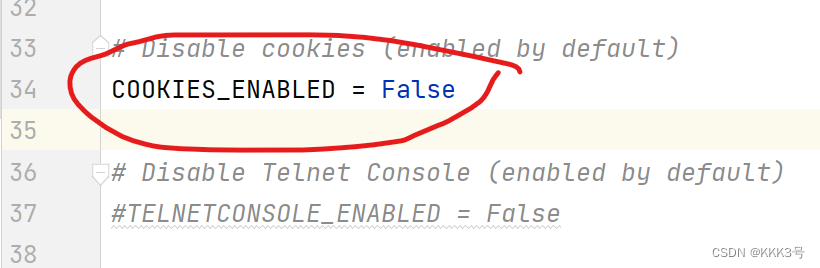
1、取消注释COOKIES_ENABLE = False:
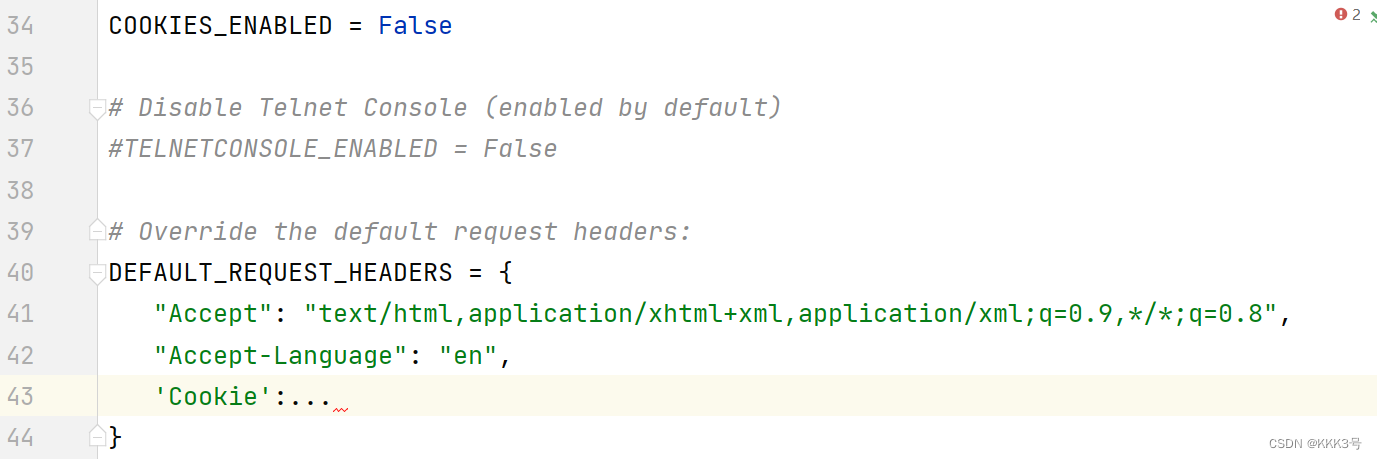
2、取消注释DEFAULT_REQUEST_HEADERS并且增加Cookie信息:
这样再请求就可以获取到相应的信息了:

相关文章
- python中lambda 表达式(无参数、一个参数、默认参数、可变参数(*args、**kwargs)、带判断的lambda、列表使用lambda)
- 《Nmap渗透测试指南》—第2章2.10节扫描列表
- SwiftUI iOS 完整项目之网络请求文章并列表显示JSON
- 高德地图实现地址检索获取结果列表和坐标
- 简单jQuery实现选项框中列表项的选择
- python之使用heapq()函数计算列表中数值大小
- 164、【动态规划】leetcode ——213. 打家劫舍 II:环形列表线性化(C++版本)
- 关于flutter列表的性能优化,你必须要了解的
- dart - 如何从Dart中的列表中找到最小值和最大值
- 9-1散列表源代码
- python使用列表实现移动平均
- lambda 匿名函数在列表推导式中的应用
- 一行代码求多个列表中的最大值
- Python编程基础:实验2——列表及元组的使用