
大数据学习——hive的sql练习
2023-09-11 14:18:37 时间
1新建一个数据库
create database db3;
2创建一个外部表
--外部表建表语句示例: create external table student_ext(Sno int,Sname string,Sex string,Sage int,Sdept string) row format delimited fields terminated by ',' location '/stu';
3添加数据
vi student.txt
95001,李勇,男,20,CS 95002,刘晨,女,19,IS 95003,王敏,女,22,MA 95004,张立,男,19,IS 95005,刘刚,男,18,MA 95006,孙庆,男,23,CS 95007,易思玲,女,19,MA 95008,李娜,女,18,CS 95009,梦圆圆,女,18,MA 95010,孔小涛,男,19,CS 95011,包小柏,男,18,MA 95012,孙花,女,20,CS 95013,冯伟,男,21,CS 95014,王小丽,女,19,CS 95015,王君,男,18,MA 95016,钱国,男,21,MA 95017,王风娟,女,18,IS 95018,王一,女,19,IS 95019,邢小丽,女,19,IS 95020,赵钱,男,21,IS 95021,周二,男,17,MA 95022,郑明,男,20,MA
hdfs dfs -put student.txt /stu;
4 查询
select * from student_ext where Sno=95022;
5 group by分组
select sex,count(1) from student_ext group by sex;
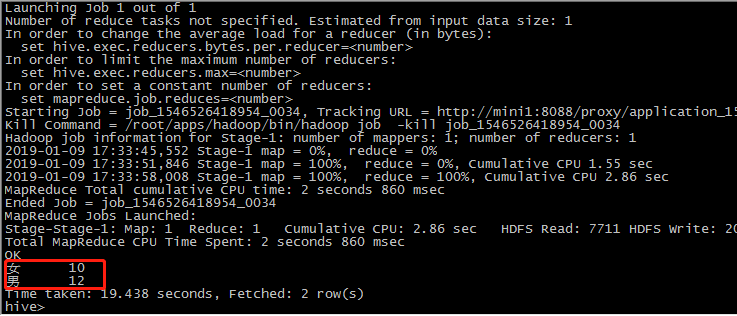
6 cluster by 分区,排序
set mapred.reduce.tasks=4;
select * from student_ext cluster by sno;
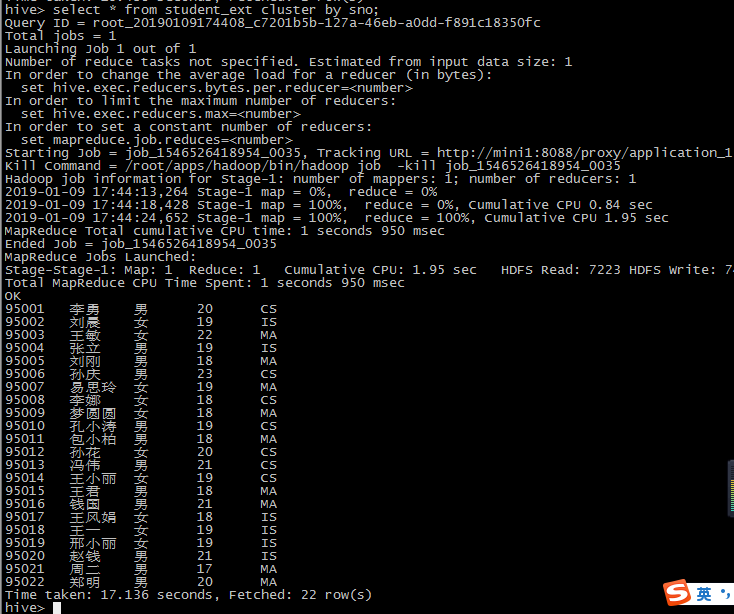
create table tt_1 as select * from student_ext cluster by sno;

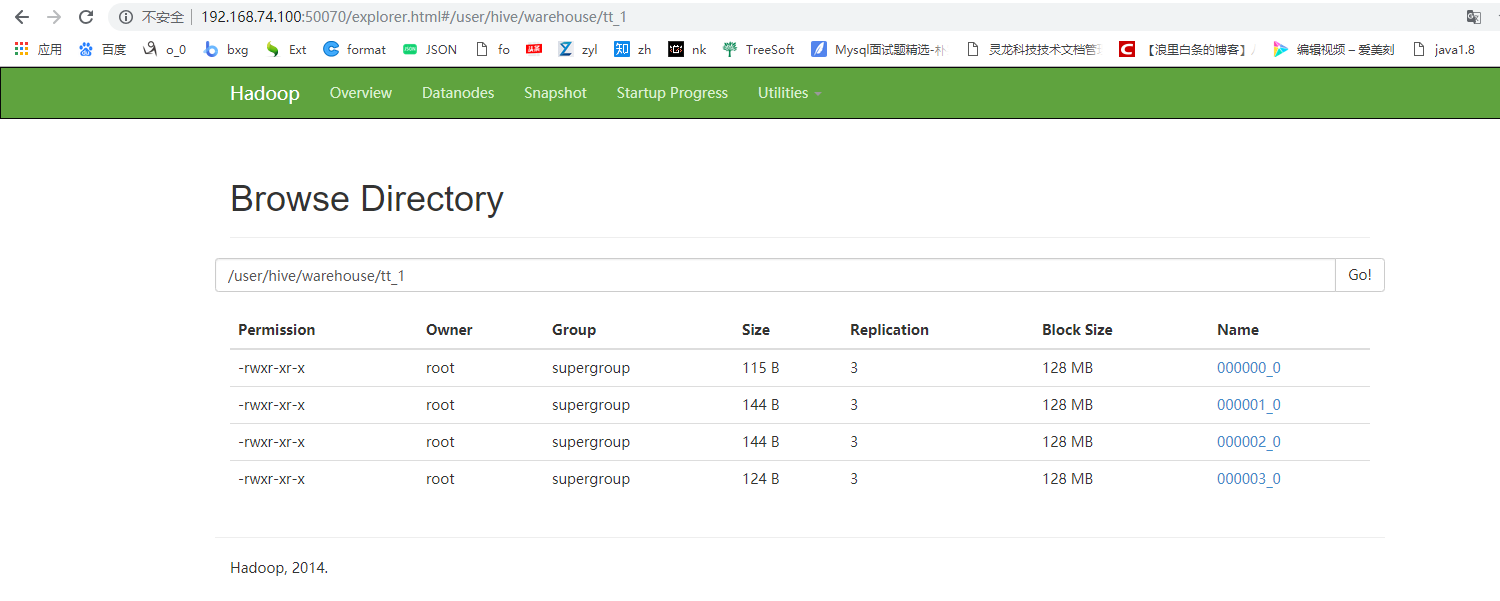
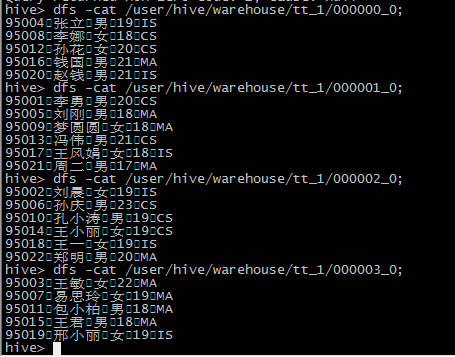
7 sort by
create table tt_2 as select * from student_ext distribute by sno sort by sno;
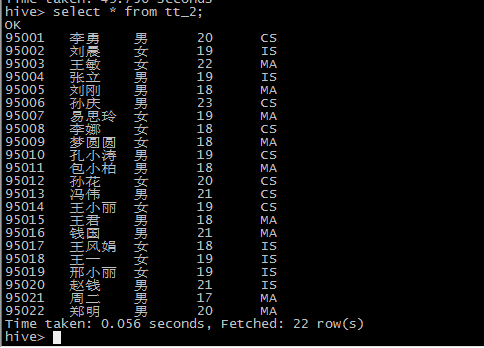
create table tt_3 as select * from student_ext distribute by sno sort by sage;

8 桶表
桶表添加数据时不能通过load的形式,
#指定开启分桶
set hive.enforce.bucketing = true;
set mapreduce.job.reduces=4;
create table stu_buck(Sno int,Sname string,Sex string,Sage int,Sdept string) clustered by(Sno) sorted by(Sno DESC) into 4 buckets row format delimited fields terminated by ',';
load方式上传数据
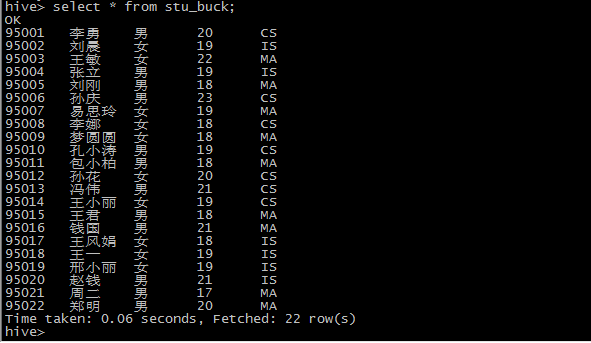
清除表数据,表结构还在
truncate table stu_buck;
通过下面这种方式给桶表添加数据
insert overwrite table stu_buck select * from student_ext;
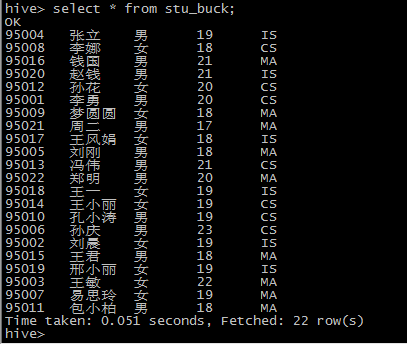
上面的数据还是没有规律的,桶表只是表示可以保存某个格式的数据,要在查出数据添加的时候就添加上查询条件
清除表数据
truncate table stu_buck;
添加带查询条件的数据
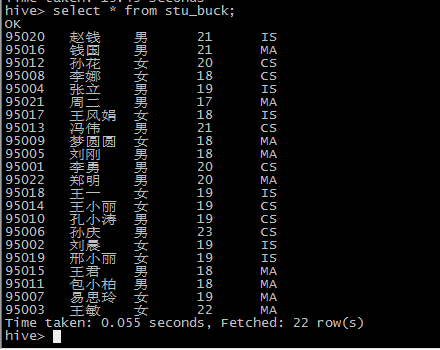
insert overwrite table stu_buck select * from student_ext distribute by sno sort by sno desc;
最终结果
9桶表抽样查询
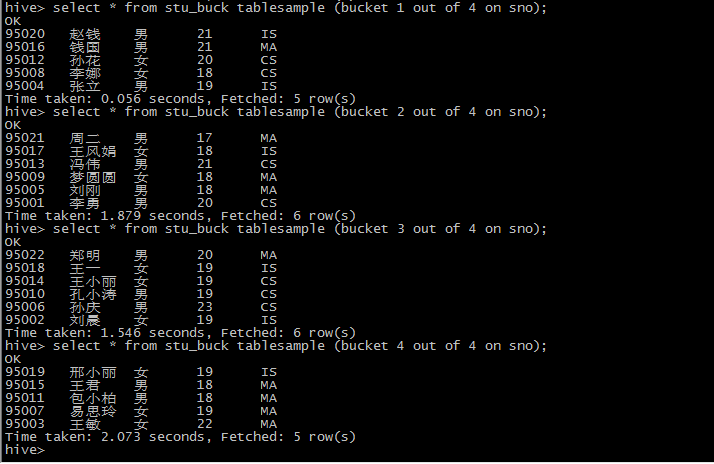
10 把表或者分区组织成桶的理由
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,
可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。
那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
相关文章
- SQL Pretty Printer sql 格式化
- SQL Server: Difference between PARTITION BY and GROUP BY
- Sql Server 里的向上取整、向下取整、四舍五入取整的实例!
- Python:利用pymssql模块操作SQL server数据库
- MySQL——company、dep、person SQL查询
- java.sql.SQLException: No operations allowed after statement closed.
- SQL学习笔记1-初识SQL
- MVC3学习:Sql Server2005中时间类型DateTime的显示
- 《机器学习与数据科学(基于R的统计学习方法)》——2.11 R中的SQL等价表述
- sql语言实践之自学SQL网(SQL Lesson8,9)
- 大数据学习——sql练习
- 大数据学习——hive的sql练习题
- gen_grant_sel.sql oracle 数据库如何获取用户的DDL 所有权限
- 学习SQL 最佳书籍推荐2022年版
- SQL教程之 掌握 SQL GROUP BY 的 5 个实用 SQL 示例(含完整sql与测试数据)
- 学习如何看懂SQL Server执行计划(三)——连接查询篇
- SQL索引一步到位
- 学习笔记:启动对特定用户的会话的sql跟踪
- SQL查询刚開始学习的人指南读书笔记(一)关系数据库和SQL介绍
- kali linux 网络渗透测试学习笔记(二)OWASP ZAP工具扫描SQL injection漏洞失败
- sql server该账户当前被锁定,所以用户'sa'登录失败。系统管理员无法将该账户解锁。(Microsoft SQL Server,错误:18486),登录错误18456
- (1.2)sql server for linux 开启代理服务(SQL AGENT),使用T-SQL新建作业
- SQL Server Cpu 100% 的常见原因及优化
- SQL SERVER 自带系统存储过程分类
- 用 ArcMap 发布 ArcGIS Server Feature Server Feature Access 服务 SQL Server版
- SQL学习之数据列去空格函数
- SQL学习之高级数据过滤