
实战案例:Sql client使用sql操作FlinkCDC2Hudi、支持从savepoint恢复hudi作业
Flink从1.13版本开始支持在SQL Client从savepoint恢复作业。flink-savepoint介绍
接下来我们从Flink SQL Client构建一个mysql cdc数据经kafka入hudi数据湖的例子。整体流程如下:
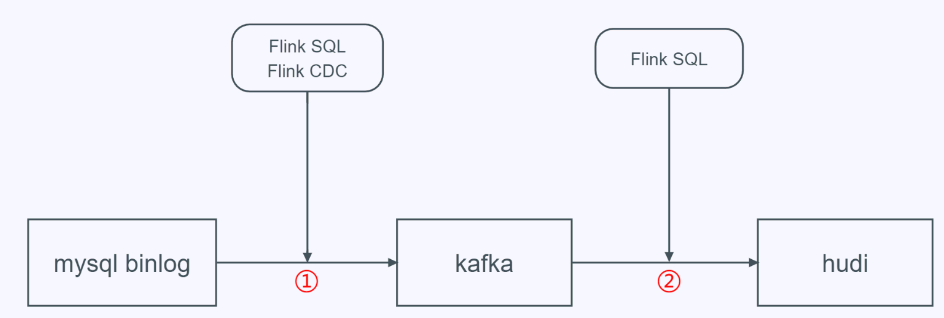
在上述第二步中,我们通过手工停止kafka→hudi的Flink任务,然后在Flink SQL Client从savepoint进行恢复。
下述工作类似于Flink SQL Client实战CDC数据入湖只是本文的flink版本为1.13.1,可参考其完成本文验证。
环境依赖
hadoop 3.2.0 zookeeper 3.6.3 kafka 2.8.0 mysql 5.7.35 flink 1.13.1-scala_2.12 flink cdc 1.4 hudi 0.10.0-SNAPSHOT datafaker 0.7.6
操作指南
使用datafaker将测试数据导入mysql
在数据库中新建stu8表
mysql -u root -p create database test; use test; create table stu8 ( id int unsigned auto_increment primary key COMMENT '自增id', name varchar(20) not null comment '学生名字', school varchar(20) not null comment '学校名字', nickname varchar(20) not null comment '学生小名', age int not null comment '学生年龄', score decimal(4,2) not null comment '成绩', class_num int not null comment '班级人数', phone bigint not null comment '电话号码', email varchar(64) comment '家庭网络邮箱', ip varchar(32) comment 'IP地址' ) engine=InnoDB default charset=utf8;
新建meta.txt文件,文件内容为:
id||int||自增id[:inc(id,1)] name||varchar(20)||学生名字 school||varchar(20)||学校名字[:enum(qinghua,beida,shanghaijiaoda,fudan,xidian,zhongda)] nickname||varchar(20)||学生小名[:enum(tom,tony,mick,rich,jasper)] age||int||学生年龄[:age] score||decimal(4,2)||成绩[:decimal(4,2,1)] class_num||int||班级人数[:int(10, 100)] phone||bigint||电话号码[:phone_number] email||varchar(64)||家庭网络邮箱[:email] ip||varchar(32)||IP地址[:ipv4]
生成1000000条数据并写入到mysql中的test.stu8表(将数据设置尽量大,让写入hudi的任务能够不断进行)
datafaker rdb mysql+mysqldb://root:Pass-123-root@hadoop:3306/test?charset=utf8 stu8 1000000 --meta meta.txt
hudi、flink-mysql-cdc、flink-kafka相关jar包下载
本文提供编译好的hudi-flink-bundle_2.12-0.10.0-SNAPSHOT.jar,如果你想自己编译hudi那么直接clone master分支进行编译即可。(注意指定hadoop版本)
将jar包下载到flink的lib目录下
cd flink-1.13.1/lib wget https://obs-githubhelper.obs.cn-east-3.myhuaweicloud.com/blog-images/category/bigdata/flink/flink-sql-client-savepoint-example/hudi-flink-bundle_2.12-0.10.0-SNAPSHOT.jar wget https://repo1.maven.org/maven2/com/alibaba/ververica/flink-sql-connector-mysql-cdc/1.4.0/flink-sql-connector-mysql-cdc-1.4.0.jar wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.12/1.13.1/flink-sql-connector-kafka_2.12-1.13.1.jar
在yarn上启动flink session集群
首先确保已经配置好HADOOP_CLASSPATH,对于开源版本hadoop3.2.0,可通过如下方式设置:
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HADOOP_HOME/share/hadoop/client/*:$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/tools/*:$HADOOP_HOME/share/hadoop/yarn/*:$HADOOP_HOME/etc/hadoop/*
flink需要开启checkpoint,和配置savepoint目录,修改flink-conf.yaml配置文件
execution.checkpointing.interval: 150000ms state.backend: rocksdb state.checkpoints.dir: hdfs://hadoop:9000/flink-chk state.backend.rocksdb.localdir: /tmp/rocksdb state.savepoints.dir: hdfs://hadoop:9000/flink-1.13-savepoints
启动flink session集群
cd flink-1.13.1 bin/yarn-session.sh -s 4 -jm 2048 -tm 2048 -nm flink-hudi-test -d
启动flink sql client
cd flink-1.13.1 bin/sql-client.sh embedded -s yarn-session -j ./lib/hudi-flink-bundle_2.12-0.10.0-SNAPSHOT.jar shell
flink读取mysql binlog并写入kafka
创建mysql源表
create table stu8_binlog( id bigint not null, name string, school string, nickname string, age int not null, score decimal(4,2) not null, class_num int not null, phone bigint not null, email string, ip string ) with ( 'connector' = 'mysql-cdc', 'hostname' = 'hadoop', 'port' = '3306', 'username' = 'root', 'password' = 'Pass-123-root', 'database-name' = 'test', 'table-name' = 'stu8' );
创建kafka目标表
create table stu8_binlog_sink_kafka( id bigint not null, name string, school string, nickname string, age int not null, score decimal(4,2) not null, class_num int not null, phone bigint not null, email string, ip string, primary key (id) not enforced ) with ( 'connector' = 'kafka' ,'topic' = 'cdc_mysql_test_stu8_sink' ,'properties.zookeeper.connect' = 'hadoop1:2181' ,'properties.bootstrap.servers' = 'hadoop1:9092' ,'format' = 'debezium-json' );
创建任务将mysql binlog日志写入kafka
insert into stu8_binlog_sink_kafka select * from stu8_binlog;
flink读取kafka数据并写入hudi数据湖
创建kafka源表
create table stu8_binlog_source_kafka( id bigint not null, name string, school string, nickname string, age int not null, score decimal(4,2) not null, class_num int not null, phone bigint not null, email string, ip string ) with ( 'connector' = 'kafka', 'topic' = 'cdc_mysql_test_stu8_sink', 'properties.bootstrap.servers' = 'hadoop1:9092', 'format' = 'debezium-json', 'scan.startup.mode' = 'earliest-offset', 'properties.group.id' = 'testGroup' );
创建hudi目标表
create table stu8_binlog_sink_hudi( id bigint not null, name string, `school` string, nickname string, age int not null, score decimal(4,2) not null, class_num int not null, phone bigint not null, email string, ip string, primary key (id) not enforced ) partitioned by (`school`) with ( 'connector' = 'hudi', 'path' = 'hdfs://hadoop:9000/tmp/test_stu8_binlog_sink_hudi', 'table.type' = 'MERGE_ON_READ', 'write.precombine.field' = 'school' );
创建任务将kafka数据写入到hudi中
insert into stu8_binlog_sink_hudi select * from stu8_binlog_source_kafka;
待任务运行一段时间后,我们手动保存hudi作业并停止任务
bin/flink stop --savepointPath hdfs://hadoop:9000/flink-1.13-savepoint/ 0128b183276022367e15b017cb682d61 -yid application_1633660054258_0001
从savepoint恢复任务:(在Flink SQL Client执行)
SET execution.savepoint.path=hdfs://hadoop:9000/flink-1.13-savepoint/savepoint-0128b1-8970a7371adb
insert into stu8_binlog_sink_hudi select * from stu8_binlog_source_kafka;
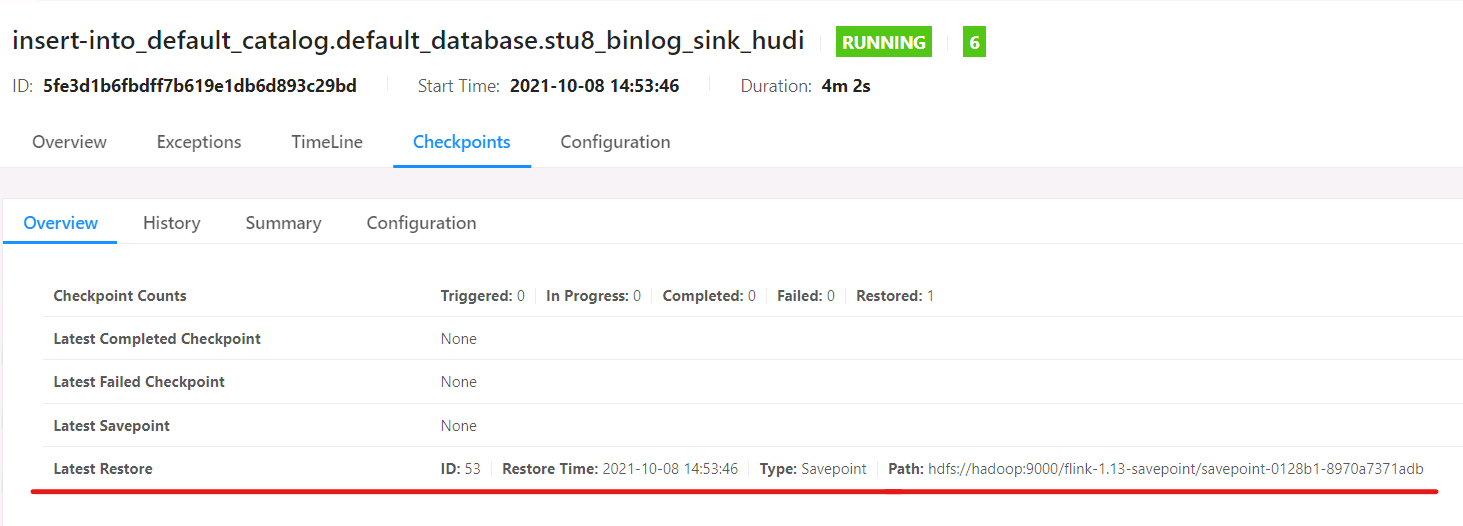
可以看到该任务从上述检查点恢复:
原文链接:https://blog.csdn.net/weixin_39636364/article/details/120652618
相关文章
- js调用Webservice接口案例
- SQL SERVER CHAR ( integer_expression )各版本返回值差异的案例
- java.sql.SQLException: The SQL statement must not be null or empty.这个错误
- 【学习总结】SQL的学习-1-初识数据库与sql
- 八大案例,带你参透SQL Server优化
- 【学习总结】SQL的学习-1-初识数据库与sql
- SQL SERVER服务器链接连接(即sql server的跨库连接)
- Atitit 读取数据库的api orm SQL Builder sql对比 目录 1.1. 提高生产效率的 ORM 和 SQL Builder1 1.2. SQL Builder 在 SQL
- VB.net:VB.net编程语言学习之ADO.net基本名称空间与类的简介、案例应用(实现与SQL数据库编程案例)之详细攻略
- Database之SQLSever:SQL命令实现查询之多表查询、嵌套查询、分页复杂查询,删除表内重复记录数据、连接(join、left join和right join简介及其区别)等案例之详细攻略
- Database之SQL:自定义创建数据库的各种表demo集合(以方便理解和分析sql的各种增删改查语法的具体用法)
- Database之SQL:SQL命令实现理解外键、约束(非空约束/唯一性约束/CHECK约束/主键约束/外键约束/查询约束)的概念及其相关案例之详细攻略
- 【sql优化】(大表小技巧)有时候 2 小时的 SQL 操作,可能只要 1 分钟
- 〖Python 数据库开发实战 - Python与Redis交互篇⑮〗- 综合案例 - 新闻管理系统 - 更新所编辑新闻状态(根据输入内容进行保存操作)
- sql 精读(三) 标准 SQL 中的编号函数示例
- sql 精读(二) 标准 SQL 中的编号函数
- 分享11个web前端开发实战项目案例+源码
- 文件及目录实际案例