
YOLOV5学习笔记(七)——训练自己数据集
2023-09-11 14:18:27 时间
目录
一、数据集介绍
根据YOLOV5学习笔记六所设计的轻量化小目标检测网络,本节将用tibnet制作的数据集进行训练测试,该数据集是用来检测空中无人机的,可以看到无人机十分的小。该数据集的labels文件是用labelme软件进行标注的xml形式。

<annotation>
<folder>0829_5JPEGImages</folder>
<filename>0829_5092.jpg</filename>
<path>C:\Users\lsq\Desktop\图片\0829_5JPEGImages\0829_5092.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>960</width>
<height>540</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>uav</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>477</xmin>
<ymin>259</ymin>
<xmax>499</xmax>
<ymax>279</ymax>
</bndbox>
</object>
</annotation>二、数据集转化
2.1 xml转txt
xml文件的标注格式是一个框的四个点的x,y范围,而yolov5使用的格式是框的中心点加上宽高,所以需要进行格式的转化,将xml文件转化为txt文件,代码如下。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir , getcwd
from os.path import join
import glob
classes = ["uav"]
def convert(size, box):
dw = 1.0/size[0]
dh = 1.0/size[1]
x = (box[0]+box[1])/2.0
y = (box[2]+box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_name):
in_file = open('./Annotations/'+image_name[:-3]+'xml') #xml文件路径
out_file = open('./labels/'+image_name[:-3]+'txt', 'w') #转换后的txt文件存放路径
f = open('./Annotations/'+image_name[:-3]+'xml')
xml_text = f.read()
root = ET.fromstring(xml_text)
f.close()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
print(cls)
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
if __name__ == '__main__':
for image_path in glob.glob("./JPEGImages/*.jpg"): #每一张图片都对应一个xml文件这里写xml对应的图片的路径
image_name = image_path.split('/')[-1]
convert_annotation(image_name)转化后的格式如下,第一个0代表类别,之后是框的中心点坐标和宽高
转化完后一定要检查一下txt中是否有值,不知道什么原因,有时会转化为空值
0 0.47890625 0.3597222222222222 0.0296875 0.052777777777777782.2 制作VOC数据集
选取三分之二的数据作为train,剩下的三分之一作为val,数据集的目录如上图
三、yaml文件修改
3.1 数据集yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC by University of Oxford
# Example usage: python train.py --data VOC.yaml
# parent
# ├── yolov5
# └── datasets
# └── VOC ← downloads here
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
train: /home/cxl/ros_yolov5/src/yolov5/data/VOCdevkit/images/train/
val: /home/cxl/ros_yolov5/src/yolov5/data/VOCdevkit/images/val/
# Classes
nc: 1 # number of classes
names: ['uav'] # class names3.2 模型yaml
主要修改类别,因为就无人机一类,所以nc改为1
# Parameters
nc: 1 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [2,2, 6,8, 10,14] #4
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
四、训练评估
4.1 训练
python train.py --data data/VOC.yaml --cfg models/yolov5s-tiny.yaml --weights weights/yolov5stiny.pt --batch-size 16 --epochs 100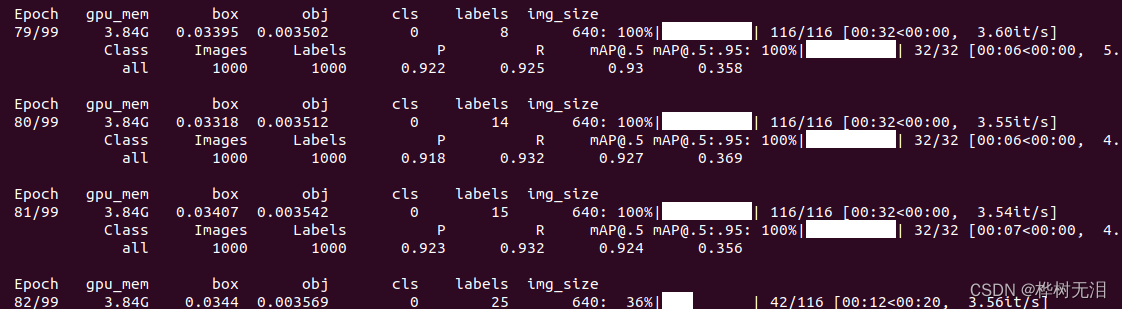
查看训练过程
tensorboard --logdir=./runs4.2 评估
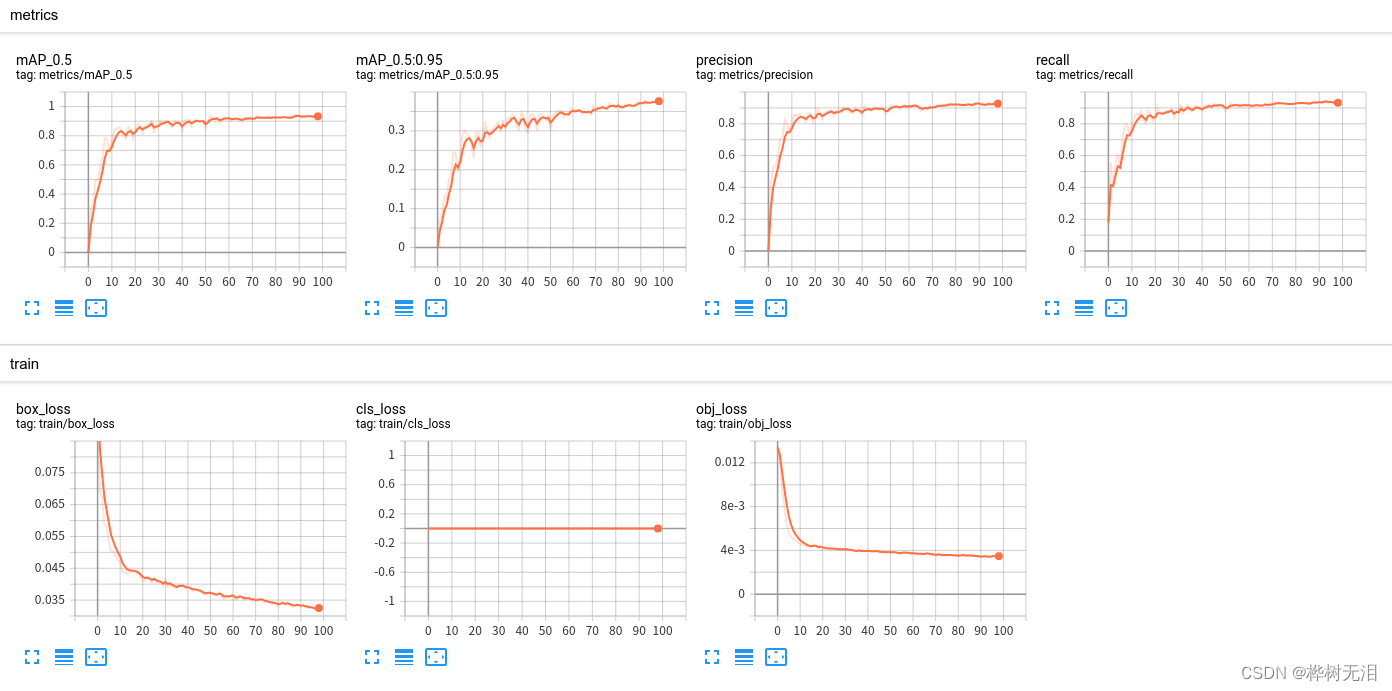
可以看到效果不错,map0.5达到了0.94,loss接近于0
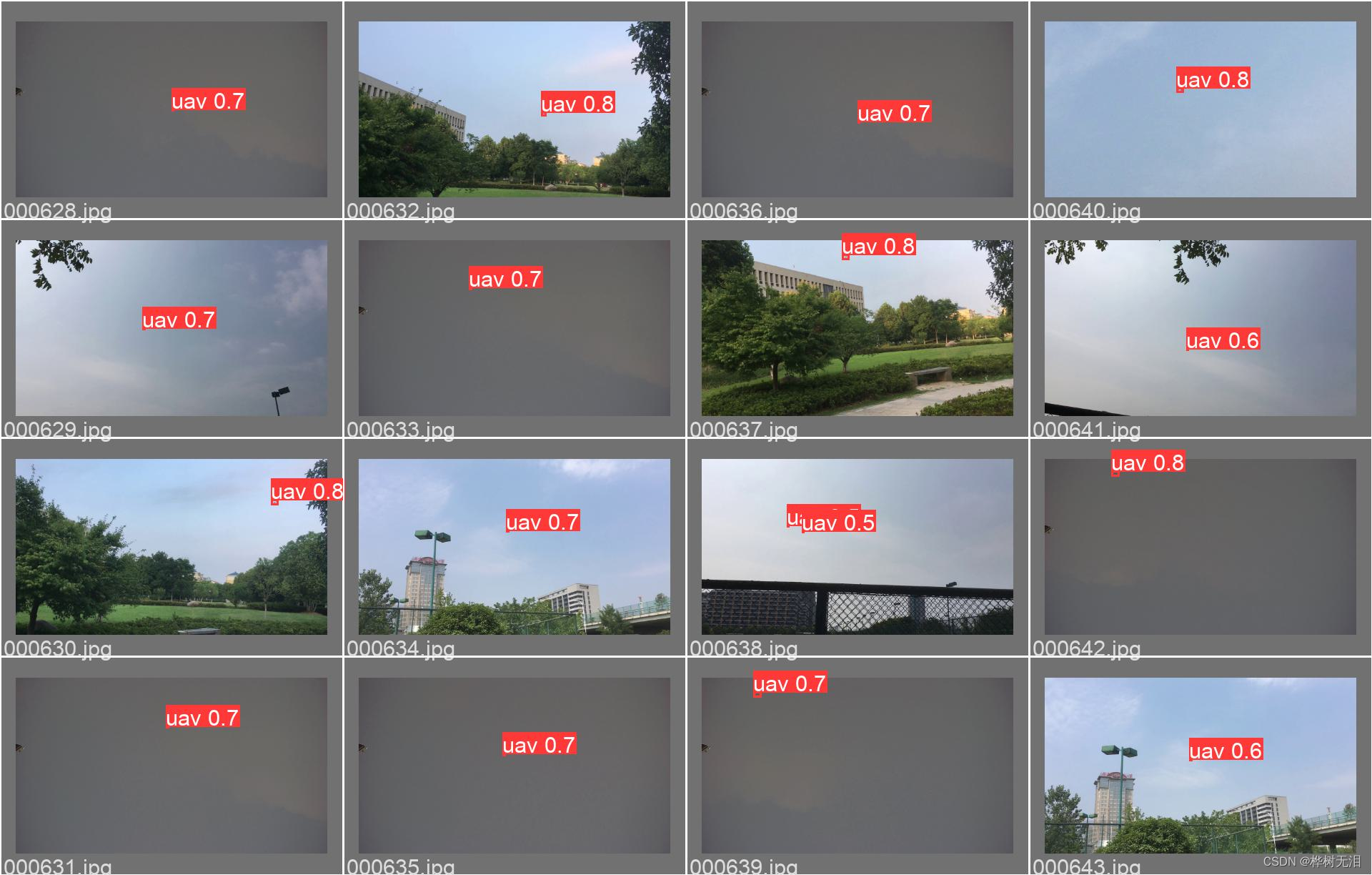
将训练好的权重保存为yolov5suav.pt,随后进行测试
测试
python detect.py --source ./data/images/ --weights weights/yolov5suav.pt --conf 0.4
detect: weights=['weights/yolov5suav.pt

PS : yolov5 txt文件train val划分
1、json转txt
import json
import os
def convert(img_size, box):
# dw = 1. / (img_size[0])
# dh = 1. / (img_size[1])
# x = (box[0] + box[2]) / 2.0 - 1
# y = (box[1] + box[3]) / 2.0 - 1
# w = box[2] - box[0]
# h = box[3] - box[1]
# x = x * dw
# w = w * dw
# y = y * dh
# h = h * dh
x1 = box[0]
y1 = box[1]
x2 = box[2]
y2 = box[3]
return (x1, y1, x2, y2)
def decode_json(json_floder_path, json_name):
txt_name = save_path+json_name[0:-5] + '.txt' #生成txt文件你想存放的路径
txt_file = open(txt_name, 'w')
json_path = os.path.join(json_floder_path, json_name)
data = json.load(open(json_path, 'r', encoding='utf-8'))
img_w = data['imageWidth']
img_h = data['imageHeight']
for i in data['shapes']:
if (i['shape_type'] == 'rectangle' and i['label'] == 'cone tank'): #分类的标签
x1 = float((i['points'][0][0]))/img_w
y1 = float((i['points'][0][1]))/img_h
x2 = float((i['points'][1][0]))/img_w
y2 = float((i['points'][1][1]))/img_h
bb = (x1, y1, x2, y2)
bbox = convert((img_w, img_h), bb)
txt_file.write( '0' + " " + " ".join([str(a) for a in bbox]) + '\n')
if (i['shape_type'] == 'rectangle' and i['label'] == 'water horse bucket'): #分类的标签
x1 = float((i['points'][0][0]))/img_w
y1 = float((i['points'][0][1]))/img_h
x2 = float((i['points'][1][0]))/img_w
y2 = float((i['points'][1][1]))/img_h
bb = (x1, y1, x2, y2)
bbox = convert((img_w, img_h), bb)
txt_file.write( '1' + " " + " ".join([str(a) for a in bbox]) + '\n')
if __name__ == "__main__":
json_floder_path = './labels/' #json文件的路径
save_path = './labelstxt/'
json_names = os.listdir(json_floder_path)
for json_name in json_names:
decode_json(json_floder_path, json_name)2、数据集划分
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='images', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='./ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.7
train_percent = 1
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/val.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/test.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
3、生成数据集txt列表文件
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'test', 'val']
abs_path = os.getcwd()
print(abs_path)
wd = getcwd()
for image_set in sets:
image_ids = open('./ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('./%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.jpg\n' % (image_id))
#convert_annotation(image_id)
list_file.close()
val.txt test.txt train.txt images labels 在同一目录下
4、改yaml文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC by University of Oxford
# Example usage: python train.py --data VOC.yaml
# parent
# ├── yolov5
# └── datasets
# └── VOC ← downloads here
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
train: data/train.txt
val: data/val.txt
test: data/test.txt
# Classes
nc: 7 # number of classes
names: ['pedestrian','cyclist','car','bus','truck','traffic_light','traffic_sign'] # class names相关文章
- 计算机等级考试二级C语言程序设计专项训练题——程序修改题(二)
- 基于预训练模型的语义匹配
- 情感分析预训练模型SKEP教程
- PaddleHub2.0——使用动态图版预训练模型ERNIE实现文新闻本分类
- 回顾BART模型 其实是BART的策略,训练标准的transformer模型
- [DeeplearningAI笔记]第三章2.4-2.6不匹配的训练和开发/测试数据
- 利用EM算法进行小波域隐马尔科夫模型的参数训练
- 机器学习笔记之深度信念网络(三)贪心逐层预训练算法
- tensorflow学习笔记四:mnist实例--用简单的神经网络来训练和测试
- PyTorch多卡分布式训练DistributedDataParallel 使用方法
- 本地构建自己的chatgpt已成为可能,国外团队从GPT3.5提取大规模数据完成本地机器人训练,并开源项目源码和模型支持普通在笔记上运行chatgpt
- 如何手动对一万篇科学论文进行 GPT-2 微调训练(教程含源码)
- 【转载】 在PyTorch训练一个epoch时,模型不能接着训练,Dataloader卡死——在pytorch中尽量不要使用opencv而是使用PIL
- 【2016多校训练4】Multi-University Training Contest 4
- Pytorch实现动物识别(含动物数据集和训练代码)
- Tensorflow入门与实战学习笔记(十一)-预训练网络
- 试题 算法训练 最小距离
- 算法训练 数字三角形
- 蓝桥杯训练1
- Caffe下CRNN训练自己的数据
- 算法训练 最大的算式(DP)
- 算法训练 Balloons in a Box (枚举,模拟)