
《Clojure数据分析秘笈》——1.8节从网页表中抓取数据
2023-09-11 14:18:20 时间
本节书摘来自华章社区《Clojure数据分析秘笈》一书中的第1章,第1.8节从网页表中抓取数据,作者(美)Eric Rochester,更多章节内容可以访问云栖社区“华章社区”公众号查看
1.8 从网页表中抓取数据
互联网上数据无处不在。遗憾的是,许多互联网上的数据不易获得。这些数据深埋于表、文章或者深层嵌套的标签中。网络抓取是一件让人讨厌的体力活,但是它通常又是唯一能将这些数据取出用于分析的手段。本方法描述如何加载网页并挖掘其内容以便取出数据。
使用Enlive库(https://github.com/cgrand/enlive/wiki)可以完成这项工作。这个库使用基于CSS选择器的领域专用语言(Domain-Sepecific Language,DSL)在网页中定位元素。这个库也可用于模板。在本例中,仅使用它从网页中取出数据。
1.8.1 准备工作
首先,需要将Enlive添加到项目的依赖中:
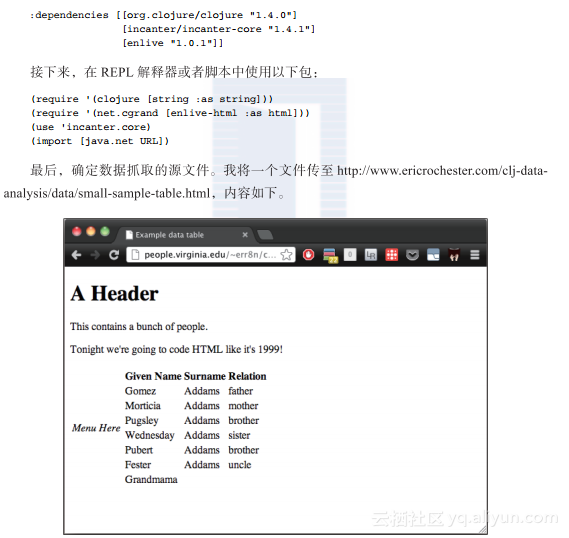
有意地去掉文件的其他内容,并使用表的布局。
1.8.2 具体实现

现在,选择所有表头单元,抽取其中的文本,将每个转换为关键词,然后将整个序列装入向量。得到了数据集的头部:

需要注意的是,在此展示的代码是多次试错后的结果。屏幕抓取的过程是这样的。通常我将下载并保存页面,从而不需要持续向Web服务器发送请求。然后启动REPL并在其中解析网页。可以通过浏览器的“查看源代码”功能查看网页和HTML,并且可以在REPL解释器中交互式地检查网页中的数据。由于比较方便,在工作过程中,我可以不断地在REPL解释器和文本编辑器中复制、粘贴代码。这种工作流程和环境使得屏幕抓取这样一个即使一切正常都需要精细操作的困难任务变得很轻松。
《Clojure数据分析秘笈》——导读 本节书摘来自华章社区《Clojure数据分析秘笈》一书中的目录,作者(美)Eric Rochester,更多章节内容可以访问云栖社区“华章社区”公众号查看
相关文章
- Redis缓存网页及数据行
- 定位网页元素
- 网页头部元素的详细定义
- 通过网页或者移动设备链接跳转qq(tim)添加好友(群)
- 使用Python爬取网页的相关内容(图片,文字,链接等等)
- 写论文,没数据?R语言抓取网页大数据
- 详解CSS网页布局中默认字体样式
- EasyNVR网页摄像机无插件H5、谷歌Chrome直播方案之使用ffmpeg保存快照数据方法与代码
- EasyNVR网页H5无插件播放摄像机视频功能二次开发之直播通道接口保活示例代码
- 通过摄像机视频设备或者流媒体服务器SDK获取到数据转换成RTMP流实现网页/手机微信播放
- 解决网页响应慢,waiting(TTFB)时间过长
- 网页引导:jQuery插件实现的页面功能介绍引导页效果
- 中文字体网页开发指南
- 内容分发网络 CDN 是如何提高网页加载时间的?
- Atitit 知识图谱 知识抽取 信息抽取的总结艾提拉总结 目录 1. 知识抽取1 2. 数据源主要来自两种渠道(2 2.1. 内部结构化数据vs 外部网页数据2 3. 2. 知识图谱的数据来
- 一段简单的JavaScript代码,实现在同一网页输出多个图标的功能
- 作为 Python 网页抓取自由职业者,每小时赚取 50-250 美元
- Python:Python语言的简介(语言特点/pyc介绍/Python版本语言兼容问题(python2 VS Python3))、安装、学习路线(数据分析/机器学习/网页爬等编程案例分析)之详细攻略
- 100天精通Python(爬虫篇)——第45天:lxml库与Xpath提取网页数据(基础+代码实战)
- 终于知道为啥网页不让我复制粘贴了!
- QT POST/GET 发送/获取网页数据
- Java抓取网页数据(原网页+Javascript返回数据)
- Java抓取网页数据(原网页+Javascript返回数据)
- 使用jsoup爬取网页数据,报错:org.jsoup.UnsupportedMimeTypeException:
- HTML5响应式网页设计——核心技能考核示例(用于2022年11月H5考核)
- python库Django链接mysql数据库做网站(二)--从网页向数据库中插入数据
- 浏览器常见问题1:浏览器打开网页提示:已限制此网页运行脚本和activex