
《高性能科学与工程计算》——第3章 数据访存优化3.1 平衡分析与lightspeed评估
本节书摘来自华章计算机《高性能科学与工程计算》一书中的第3章,第3.1节,作者:(德)Georg Hager Gerhard Wellein 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
第3章 数据访存优化在高性能计算中,访存是最重要的性能限制因素。如前所述,微处理器的理论峰值性能和访存带宽存在固有的“不平衡性”。因为很多科学和工程应用程序由需要大量数据传输的基于循环的代码构成,所以相对较低的内存(甚至是硬盘)访存带宽,就会导致片上资源的低效利用和程序性能的降低。
图3-1综合显示了现代并行计算机系统的数据通路构成,以及在不同层次上的带宽和延迟范围。执行计算任务的功能部件位于该层次结构的顶部。在这些不同层次的数据通路中,访存带宽最大有3~4个数量级的差异,访存延迟最高也有8个数量级的差异。为了获得计算操作数,数据传输需要到达的数据通路层次越深,对性能的影响就越小。因此,任何优化首先要考虑减少在性能低的数据通路上的数据传输。当这不能实现时,至少要让数据传输尽可能高效。
3.1 平衡分析与lightspeed评估
3.1.1 基于带宽的性能建模
许多程序员都会竭尽全力提高程序性能。为了确定这些努力是否有效或者确定目标程序是否已经得到了充分优化,程序员会使用简单的经验法则来评估这些基于循环且带宽访存受限的代码的理论性能。这里引入一个核心概念:平衡(balance)。例如,一个处理器芯片的“机器平衡”Bm等于可能的访存带宽(GWord/s,千兆字/秒)与峰值性能(GFlop/s,千兆浮点运算次数/秒)的比值:

尽管“访存带宽”通常对真正访存受限的代码有用,但这个术语可被cache带宽或者网络带宽代替。假定访存延迟被预取和软件流水这类技术隐藏,例如,一个时钟频率为3.0 GHz的双核芯片,每核每个时钟周期最多可执行4个浮点数计算,访存带宽为10.6GB/s,则这个处理器的机器平衡值为0.055W/F。在本书进行写作的时候,Bm值一般位于0.03W/F(标准的基于cache的微处理器)~0.5W/F(高端行向量处理器)之间。由于不断增长的DRAM差距和不断增加的处理器核数,未来标准架构的机器平衡值可能会降低。表3-1显示了不同数据传输路径的平衡值。
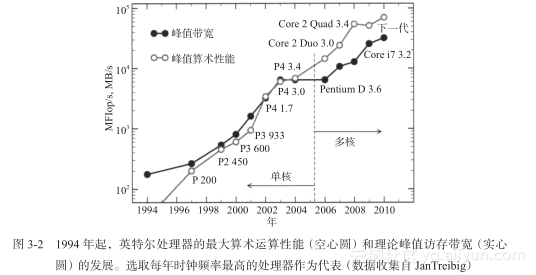
图3-2收集了1994~2010年间,英特尔处理器的峰值性能和访存带宽信息(选取每年时钟性能最高的桌面处理器作为代表)。尽管2005年之前峰值性能的增长速度要快于访存带宽,但第一款双核芯片(Pentium D)的推出才真正大幅增大了DRAM差距。虽然Core i7为访存带宽赢回了一些颜面,但长期的发展趋势显然不会受到这个例外的影响。
为了量化运行在具有特定平衡值机器上的代码需求,我们进一步定义了循环的代码平衡值:

“数据传输量”表示通过数据通路(性能限制因素)传输的所有数据量(单位为字),这个术语在一定程度上依赖于硬件(见3.3节实例)。代码平衡值的倒数称为计算密度(computational intensity)。现在我们可以计算出代码平衡值为Bc的代码在机器平衡值为Bm的设备上所能达到的峰值性能的最大期望:
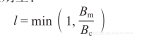
我们将这个小数称为循环的“lightspeed”。则所能达到的峰值性能(GFlop/s)为:
如果l ≈ 1,则代码性能的限制因素将在CPU或其他地方,访存带宽不再是代码性能的限制因素。值得注意的是这个简单的性能模型是基于以下几点重要假设: 循环代码应以最佳方式使用所有的算术单元(乘法和加法)。如没有,则必须引入一个校正因子来反映有效峰值性能和绝对峰值性能的比值(例如,如果代码只使用了加法单元,则有效峰值性能为绝对峰值性能的一半)。当使用的内核数量少于芯片上的内核总数时,也要有类似的考虑。 虽然循环代码基于双精度浮点数运算。然而我们可以非常容易地得到更加适合其他代码的相似术语(例如,32位字每整数算术运算指令)。 数据传输和运算完美重叠。 最慢的数据通路决定了循环代码的性能。所有更快的数据通路都被认为是无限快的。 计算系统面向吞吐量,即忽略延迟对性能的影响。 完全有可能实现对内存带宽的利用达到饱和,从而使机器平衡值的计算达到最大值。近年来的多核架构设计中如果只使用其中一部分核,则对内存接口的使用是低效的。这使得性能预测更加困难,因为这需要一个单独的“有效”机器平衡值,这个值不仅是简单地使用核数与总核数的比值。3.1.2节和习题3.1对这点会有更加详细的讨论。
虽然平衡模型经常很有用,足够评估循环代码的性能,并能对性能优化提供指导(特别是同可视化结合起来,比如roofline模型[M42])。我们必须强调的是确实存在更加先进的性能模型策略,参见文献[L76, M43, M41]。
我们以1.3节介绍的标准向量基准代码为例:
该内核每个迭代循环执行两次浮点数运算、三次数据读取指令(读取数据B(i)、C(i)和D(i))和一次数据存储指令(存储A(i))。代码平衡值为Bc = (3+1)/2 = 2。如果该代码运行在机器平衡值Bm = 0.1的CPU上,那么我们可以预期lightspeed比为0.05,即峰值的5%。
基于cache的标准微处理器,其最外层cache通常会具有回写策略。如1.3节所述,如果延迟写或者行0未被使用时,当一次写操作未命中时,为保证cache –存储器的一致性,需要一次cache行的写分配。在这样的条件下,计算代码平衡值时,数组A的存储操作必须计算两次,这样我们计算出最终的lightspeed为lwa = 0.04。
3.1.2 STREAM 基准测试
McCalpin STREAM是用来评估处理器或者系统内存接口性能的基准测试,包含四个简单的合成内核循环代码。表3-2列出了它们的操作以及各自的代码平衡值。有效内存带宽(GB/s)通常作为其性能提供报告。注意不要将STREAM TRIAD内核与上一节讨论的三元组向量操作混淆,它包含一个额外的数据读取操作。
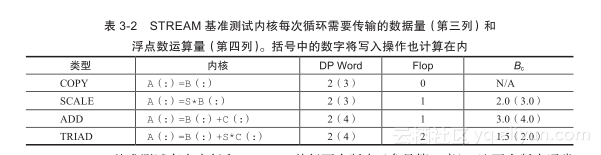
STREAM基准测试存在串行和OpenMP并行两个版本(参见第6章)。这两个版本通常都运行在足够大的数据集上,以确保内核性能都是访存受限的。因此,内存带宽测试仅依赖于数据读取和存储操作的次数,COPY和SCALE(ADD和TRIAD同样适用)内核代码的性能结果往往类似。需要搞清楚的是,STREAM并不是仅通过表3-2列出的循环内核定义的,还包含Fortran源代码(也有可用的C语言版本)。这一点非常重要,因为经过优化的编译器会识别出STREAM源代码,从而使用手工优化的机器代码代替内核代码。因此,STREAM的性能结果可以真实地反映出硬件的实际性能。在STREAM网站上可以找到许多针对过去和现在的计算机系统的基准测试代码[W119]。
遗憾的是,STREAM同三元组向量代码一样,达不到平衡分析所预测的性能水平,特别是在商业(基于PC的)硬件上。其中的原因是多方面的,这里不进行详细讨论,主要原因如下:
然而,STREAM结果所标记的最大内存带宽依然是正确的。没有具有类似特征(读写操作的数量)的实际应用代码可以表现得更好。这样,在lightspeed计算中应该引用STREAM所测得的带宽bS,而不是硬件的理论值。式(3-4)可修正为:
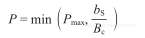
如果一个实际应用程序能够达到基于STREAM预测带宽的较大比值(如80%),往往意味着该程序没有继续改进内存接口利用率的余地。当然,这并不意味着没有进一步优化的空间(如下面章节的讨论)。
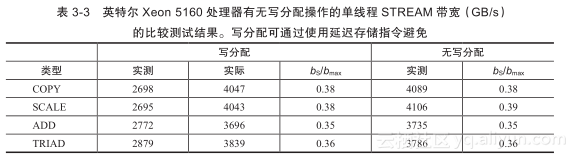
我们选择一个使用英特尔Xeon 5160 处理器(参见图4-4)的系统作为测试平台。该处理器的每核理论内存带宽为bmax = 10.66 GB/s,峰值性能为Pmax = 12 GFlop/s(3.0GHz,每个时钟周期可执行4次浮点数运算),则单核机器平衡值为Bm = 0.111 W/F(如果两个核都运行访存受限代码,则该值需除以2。但是目前我们假定每个系统通路只运行一个线程)。
表3-3显示了STREAM在这个平台上,有无写分配的比较测试结果。由于基准测试代码并没有考虑这个细节,所以当存在写分配操作时,测试带宽和实际内存传输不同。如
表3-3所示,实测性能和理论峰值性能的差距非常明显,在这个平台上几乎不可能超过峰值带宽的40%。ADD与TRIAD(两次读取操作而不是一次)内核的效率特别低。如果这个结果被用来做循环代码的平衡分析,COPY和SCALE应该运行在加载/存储(写入)平衡的情况下。3.3节将会讨论一个具体实例。
大咖说*计算讲谈社|如何提出关键问题? “定义问题”往往比“回答问题”本身更重要。那什么问题是关键问题?如何提出关键问题?【计算讲谈社】第三讲上线,阿里巴巴研究员吴翰清(道哥)携学员针对该主题展开分享和讨论。
【ASPLOS 2022】机器学习访存密集计算编译优化框架AStitch,大幅提升任务执行效率 近日,关于机器学习访存密集计算编译优化框架的论文《AStitch: Enabling A New Multi-Dimensional Optimization Space for Memory-Intensive ML Training and Inference on Modern SIMT Architectures》被系统领域顶会ASPLOS 2022接收。
如何从系统层面优化深度学习计算? 在图像、语音识别、自然语言处理、强化学习等许多技术领域中,深度学习已经被证明是非常有效的,并且在某些问题上已经达到甚至超越了人类的水平。然而,深度学习对于计算能力有着很大的依赖,除了改变模型和算法,是否可以从系统的层面来优化深度学习计算,进而改善计算资源的使用效率?本文中,来自微软亚洲研究院异构计算组资深研究员伍鸣与大家分享他对深度学习计算优化的一些看法。
相关文章
- 云计算与大数据催生黑暗面 用户的错?
- 计算一/二元一次方程的类(用于动画控制)
- 漫谈边缘计算(二):各怀心事的玩家
- 第二百六十四节,Tornado框架-基于正则的动态路由映射分页数据获取计算
- 使用函数计算自定义运行时快速部署一个 SpringBoot 项目 | 文末有礼
- 我们怎样确保从大数据计算中获得价值
- 以云计算与大数据为代表的信息技术是电力行业未来发展核心
- 大数据和云计算究竟有什么关系?
- PCL计算点云粗糙度
- PCL 计算点云各字段数据的均值
- 【华为云技术分享】华为云多元计算+AI 打造企业级智能数据湖
- C++计算数据的MD5值
- 【Linux 内核】CFS 调度器 ③ ( 计算进程 “ 虚拟运行时间 “ )
- 【互动问答分享】第15期决胜云计算大数据时代Spark亚太研究院公益大讲堂
- 量子计算的基本原理——本质上是在操作薛定谔的猫(同时去运算和操作死+不死两种状态)
- 在AVFrame中计算音视频数据大小
- MySQL常用日期的计算
- SQL每日一练——第14天:创建计算字段、使用函数处理数据
- 比Hive还快10倍的大数据计算引擎
- OpenCV-Python实战(4) —— OpenCV 五角星各点在坐标系上面的坐标计算(以重心为原点)
- 云计算如何支持数字化转型
- 2022年河南省高等职业教育技能大赛云计算赛项竞赛赛卷(样卷)