
Python被动收入教程之从非结构化文档中提取信息的结构化方法
2023-09-11 14:18:32 时间
在结构化数据集(例如表格数据、发票等)领域已经进行了很多探索和征服,我们已经预先定义了要遵循的步骤以获得良好的结果,而在从保险文件、合同、医疗报告等非结构化文件中提取信息时等,没有这样的指南。
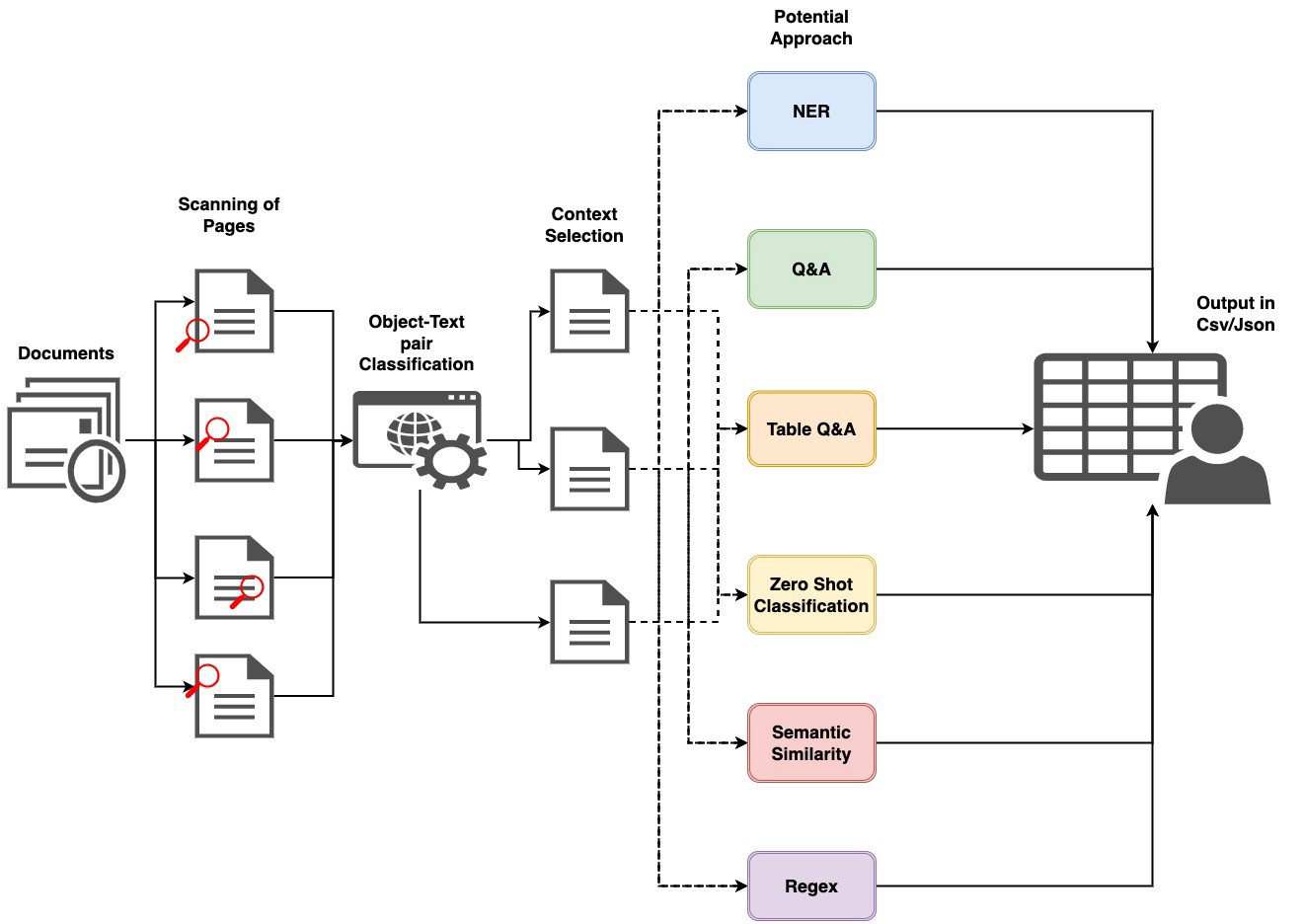
在本文中,我将介绍一些从非结构化文档中获得所需结果的一般步骤,并提供示例代码以开始使用。我还将为想要进一步探索该主题的人们提供一些参考资料。
总之,该方法可分为 4 个主要步骤。首先,文档页面将被拆分为单独的图像。其次,每张图像将通过黑盒视觉模型发送,该模型将从文档中识别出不同的对象,例如表格、标题、段落、图形/图表、徽标、签名、二维码等。第三,一旦检测到这些对象,它们将根据用例进行过滤。例如,人们可能希望从文档中的特定部分提取信息,或者只想识别特定类型的徽标。最后,一旦识别出相关部分,它将通过另一个黑盒模型(文本相关算法)根据用例和业务需求提取信息,最后可以将结果保存为 CSV、JSON 或其他要求的格式。
内容:
商业机会
方法论
— 将文档拆分为页面
— 对象检测
— 对象分类
— 基于文本的信息提取方法
结论
商业机会
如果您清楚业务需求并且只想检查方法,请跳过此部分
在深入研究方法部分之前,让我们了解为什么需要这些方法以及它们可以给企业带来什么影响。
相关文章
- Python中python-nmap模块的使用
- Python脚本写端口扫描器(socket,python-nmap)
- Python中sys模块的使用
- python执行脚本加参数_命令行运行Python脚本时传入参数的三种方式详解以及argparse子命令subparsers()方法
- 测试面试 | Python 算法与数据结构面试题系列二(附答案)
- 【华为OD机试真题 python】最长的顺子【2022 Q4 | 200分】
- 【零基础学python】:清华官方出品的《看漫画学Python》全彩PDF,495页资源分享
- 每天一个python小知识——如何在Python 3中转换数据类型
- 将自己OpenCV-Python-PyCharm开发环境的Python-3.6.8更换为python-3.9.10的详细过程记录
- gyp ERR! stack Error: Can‘t find Python executable “python“, you can set the PYTHON env variable.
- Python入门(一)-打开世界之Hello World
- Python编程-基础知识-python项目包和文件的管理以及如何引用相对路径的包和模块
- 推荐Python、Django中文文档地址
- 《Python Cookbook(第2版)中文版》——1.15 扩展和压缩制表符
- python学习之基于Python的人脸识别技术学习
- 如何在 Python 中从文档字符串创建文档?
- Python教程之使用 Python 识别加密的 PDF 文档和解密受 PDF
- Python 实现被动收入教程之我如何使用 python 制作我的第一个高级telegram机器人
- 小学生python游戏编程6----碰边变颜色的小球
- Python使用APScheduler实现定时任务
- 【人生苦短,我用Python】Python免费精品课连载(1)——Python入门
- 2.1 The Python Interpreter(python解释器)
- 【python百度智能云】:Python — 三种获取__VIEWSTATE、__VIEWSTATEGENERATOR、__EVENTVALIDATION方法。
- python量化交易框架