
基于Python实现的人脸识别系统【100010666】
一:问题描述
选题五:

二:实现思路
一开始拿到这个题目是有点懵的,因为我们组里都是信安,并没有学习过机器学习类似的课程,但是这道题目是一定要用到机器学习。再加上这道题老师并没有给出参考代码,所以可以说是完全是“从头开始”。不过功夫不负有心人并且老师给了我们最后一个选题充裕的时间,所以我们才可以将其做出来。
2.1 切换点
而根据问题的描述:根据声音或者视频,给出镜头的切换点,按照时间段给出时间起点和终点。
我们所理解的切换点为两种:镜头切换点和音频切换点。
2.1.2 镜头切换点
对于镜头切换点:对于这个视频来说,可以很明显的看到这个视频的拍摄并不是一个机位拍摄的,而是多机位进行拍摄。每个机位对着一个嘉宾或者主持人。如下图所示:

所以我们想到如果说我们可以找到这个视频的镜头切换点或者说剪辑点,对于一个视频而言后期剪辑会将不同机位拍摄的视频剪辑在一起,而这个剪辑点是很好找的,所以只要找到这视频的剪辑点就相当于找到了这个视频的镜头切换点,就可以将一段视频分段,分成一段只有一个主持人的样子,并且将每一段所对应的时间记录下来生成一个列表,这样就可以达到选题给出的要求。
至于如何找这个剪辑点在之后的第三段:分帧中会提到,这里就不赘述了。
2.1.2 音频切换点。
对比寻找视频切换点,音频切换点就显得不是友好了。
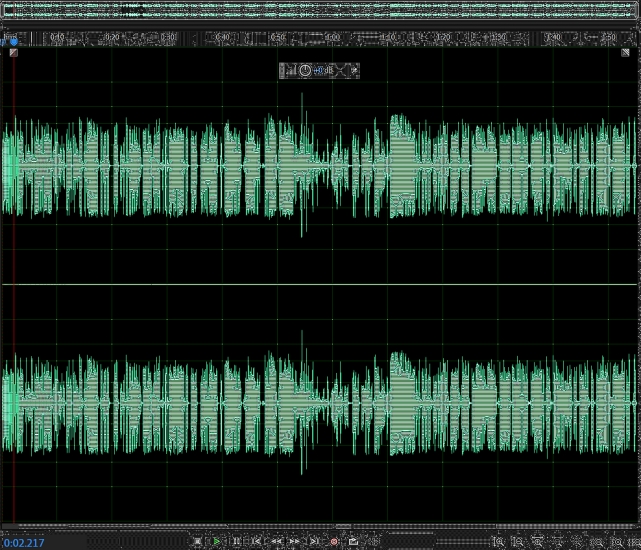
这是我们用来测试的波形图
对于这段音频,当一个人停止说话时就是波谷,然后后面一个人又接话这样就可以判断音频的切换点。
虽然说理论上这样是没有错的,但是实际实现上是有很多纰漏的:当一个人说完了一句话,其实就有停顿,这个时候如果说时音频切换点的话那么一段视频中就有很多很多个切换点,如上图,其实里面实际的音频切换点没有几个,但是可以观察到波谷有二十来个左右,所以这种方法一开始就被我们摒弃了,但是不无参考价值。
对于这个切换点我们给出了两种方案:
1:设定相应的步长,分块进行声纹识别,得出说话人队列。
2:说话人日志(Speaker Diarization):基于深度学习的说话人日志,通过深度学习的方法,从训练数据中学习语音和说话人的特征,从而实现说话人“谁在什么时候说话”的目标。
2.2 嘉宾识别 = 人脸识别 & 声纹识别
2.2.1 人脸识别
对于人脸识别这方面,现在技术上已经做的很发达了。比如说图书馆和宿舍用的人脸识别系统:可以说秒识别了。而且识别准确率特别高。
我们在这里先假设我们的人脸识别准确率可以达到90%以上,实际上我们也达到了90%以上。但是在这里我们假设人脸识别是成功的,是可移植的。如果说分帧做好了的话,对于人脸识别的话我们就可以在一段视频中取多帧图片,对其进行人脸识别,然后取匹配结果中的最匹配的那一项作为结果,成为那个片段的标签用来标记这个片段中是哪个嘉宾。这样我们就可以将嘉宾识别出来。具体的人脸识别是怎么样实现的之后会有详细的介绍。
2.2.2 声纹识别
对于声纹识别这方面,通过对市面上的调研,声纹识别的应用场景并没有人脸识别广泛。所以对于声纹识别这方面的实现来说,并不是一件简单的事情。所以对于声纹识别这个部分,我们也像人脸识别一样假设,我们实现的声纹识别准确率可以达到90%以上,(实际上可能最高只有80%)。通过上面介绍的两种找音频切换点的方案:这样也可以像人脸识别一样得到一项列表,也可以将嘉宾实现出来。具体的声纹识别是怎么样实现的在之后会有所涉及。
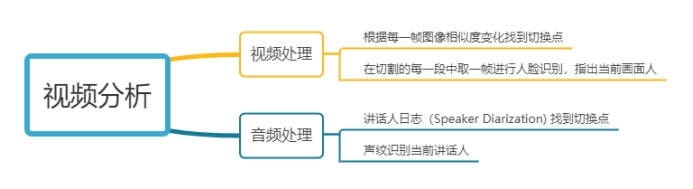
所以我们的这个实现思路可以用下面的一张图来表示:
三:实验环境
操作系统:Windows 10 pro
编译环境: Python 3.7.4 + Pychram 2019.3 + Jupyter Notebook
视频播放器:potplayer Mini
四:分帧
这一部分是由我的队友严诚逸来进行实现的。所以这一部分详细内容见他的实验报告即可,这里是简单的介绍。
对于视频的处理而言,区分每个分镜之间最重要的就是做好每一帧之间的相似度对比,当相似度跳动的超过了某个我们设置的阈值,我们就可以认为镜头切换了。而如何做每一帧的相似度对比呢。
我们找到了三种解决上述问题的方法:
4.1 直方图计算法
从机器的角度上来说,如果说要识别两种相似的图像,应该先识别图像的特征,然后进行对比。
而如果说没有建立一个模型来提取特征值,计算机很难识别两张相似图片。但是计算机却可以很容易就识别图像的图像值。
所以我们选择使用直方图的计算法。
在颜色检索中,颜色直方图是最通用的颜色特征形式,它运用了统计学的方法,体现了三个颜色通道分布密度的联合分布概率。它具有特征提取和相似度计算方便,并且随图像尺度,旋转等变化不敏感的特点,它能简单描述一幅图像颜色的全局分布,即不同色彩在整幅图像中所占的比例
下列图片来源自:https://blog.csdn.net/feimengjuan/article/details/51279629


可以看到两张片除了天空中的云或者说下面的牛羊其他景色都是差不多的。然而在计算机的眼中:
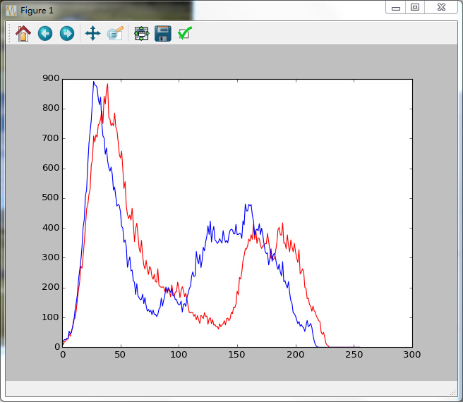
所以根据这个特性我们可以将两张图片区分开来。但是缺点也很显著:也就是如果说两张图片都有一个相同的主色调,那么这样的话也有可能将两张图片判断为相同的。
所以我们在最终结果处理的时候并没有采取这种算法。
4.2 图像指纹:hash
图像指纹就像是人的指纹一样,每一张图片本质上还是0101组合的01串,所以利用hash算法计算汉明距离,从而可以通过距离上的近远来判断相似与否。【5】
python︱imagehash 中有四种图像哈希方式,分别是
感知hash:PHash(Perceptual Hash)
平均hash:AHash(Average Hash)
差值hash:DHash(Difference Hash)
小波hash:WHash(Wavelet Hash)
DHash:梯度散列。
计算每个像素的差值,并与平均差异的差异进行比较。

Ahash:平均散列。
对于每个像素,如果该像素是大于或等于平均值,则输出1,否则为0。

PHash:核心:离散余弦变换(DCT)

WHash:核心:离散小波变换(DWT),和感知哈希步骤相同,只是将步骤 DCT 换为 DWT

然后通过比较两张相邻的帧的汉明距离,设置一个阈值即可,就可以达到判断两张图片是否相似的目的。
4.3 SSIM法
SSIM的全称为structural similarity index,即为结构相似性,是一种衡量两幅图像相似度的指标。该指标首先由德州大学奥斯丁分校的图像和视频工程实验室(Laboratory for Image and Video Engineering)提出。
它是一种全参考的图像质量评价指标,分别从亮度、对比度、结构三个方面度量图像相似性。
SSIM取值范围[0, 1],值越大,表示图像失真越小。在实际应用中,可以利用滑动窗将图像分块,令分块总数为N,考虑到窗口形状对分块的影响,采用高斯加权计算每一窗口的均值、方差以及协方差,然后计算对应块的结构相似度SSIM,最后将平均值作为两图像的结构相似性度量,即平均结构相似性SSIM。
在python中,compare_ssim()是scikit-image库自带的一种计算方法。
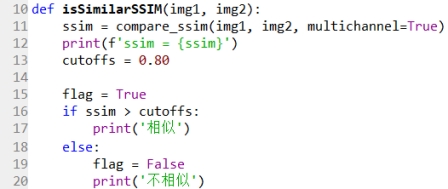
4.4 实验输出及结果
在本次实验中,我们使用了4.2中的AHash进行图像相似度的比较。
具体代码如下:
from pyaudio import PyAudio, paInt16
import numpy as np
from datetime import datetime
import wave
class recoder:
NUM_SAMPLES = 2000 #pyaudio内置缓冲大小
SAMPLING_RATE = 8000 #取样频率
LEVEL = 500 #声音保存的阈值
COUNT_NUM = 20 #NUM_SAMPLES个取样之内出现COUNT_NUM个大于LEVEL的取样则记录声音
SAVE_LENGTH = 8 #声音记录的最小长度:SAVE_LENGTH * NUM_SAMPLES 个取样
TIME_COUNT = 60 #录音时间,单位s
Voice_String = []
def savewav(self,filename):
wf = wave.open(filename, 'wb')
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(self.SAMPLING_RATE)
wf.writeframes(np.array(self.Voice_String).tostring())
# wf.writeframes(self.Voice_String.decode())
wf.close()
def recoder(self):
pa = PyAudio()
stream = pa.open(format=paInt16, channels=1, rate=self.SAMPLING_RATE, input=True,
frames_per_buffer=self.NUM_SAMPLES)
save_count = 0
save_buffer = []
time_count = self.TIME_COUNT
while True:
time_count -= 1
# print time_count
# 读入NUM_SAMPLES个取样
string_audio_data = stream.read(self.NUM_SAMPLES)
# 将读入的数据转换为数组
audio_data = np.fromstring(string_audio_data, dtype=np.short)
# 计算大于LEVEL的取样的个数
large_sample_count = np.sum( audio_data > self.LEVEL )
print(np.max(audio_data))
# 如果个数大于COUNT_NUM,则至少保存SAVE_LENGTH个块
if large_sample_count > self.COUNT_NUM:
save_count = self.SAVE_LENGTH
else:
save_count -= 1
if save_count < 0:
save_count = 0
if save_count > 0 :
# 将要保存的数据存放到save_buffer中
#print save_count > 0 and time_count >0
save_buffer.append( string_audio_data )
else:
#print save_buffer
# 将save_buffer中的数据写入WAV文件,WAV文件的文件名是保存的时刻
#print "debug"
if len(save_buffer) > 0 :
self.Voice_String = save_buffer
save_buffer = []
print("Recode a piece of voice successfully!")
return True
if time_count==0:
if len(save_buffer)>0:
self.Voice_String = save_buffer
save_buffer = []
print("Recode a piece of voice successfully!")
return True
else:
return False
if __name__ == "__main__":
r = recoder()
r.recoder()
r.savewav("test.wav")
输入的就是我们需要进行分段的视频,而输出就是一段列表,标明了每个镜头的时间段,开始时间以及结束时间,如下图所示。
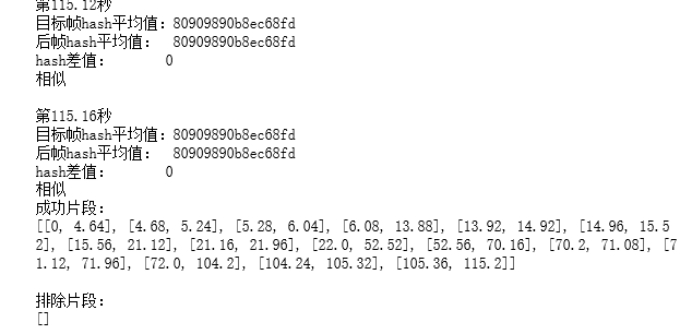
从而就可以进行下一步的人脸识别过程了。
五:人脸识别
5.1 数据集的构建
对于人脸识别来说,数据集是必不可少的一项。
如果说对视频的一帧进行人脸识别的话,我们势必需要对应人脸识别的数据集,所以我采取了一个很笨但是很有效的办法:自己动手制作数据集。
通过反复观看视频,我们发现了一个特点:在视频中的大部分镜头都是一个人的上半身,或者说头像,并且大部分都没有其他干扰,比如说低头:被遮挡,侧脸等等干扰。所以我们可以构建一个良好的数据集,这是前提。
所以我们花了一个小时,手工捕捉并截图各个嘉宾的表情,做成了四类人脸数据集。分别是这四位嘉宾的人脸。如下图:
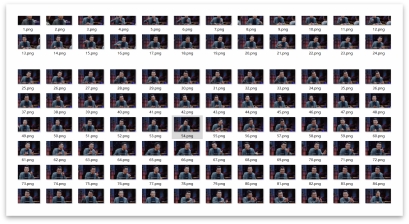
窦文涛(主持人):211张

梁文道(媒体人):202张

马家辉(作家):209张

周轶君(记者):201张
数据集中四位嘉宾的人脸图片,总计823张图片。按照9:1的比例进行划分,90%用于训练,10%用于测试。
自定义的数据集,首先要生成图像列表,把自定的图像分为测试集和训练集,并带有标签。将里面的每个小类别都迭代,生成固定格式的列表.比如我们把人脸类别的根目录传进去…/images/face。最后会在指定目录下面生成三个文件,readme.json、trainer.list和test.list.
5.2 训练集和测试集的构建
之前提到,构建了四类人脸的数据集。
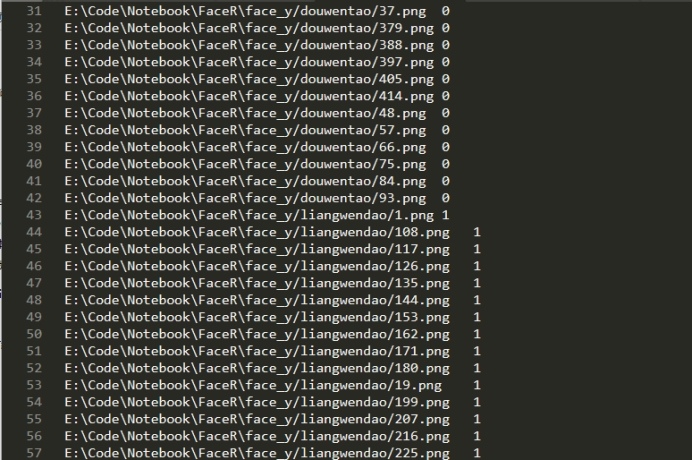
所以将这些构建的数据集的10%作为测试集,90%作为训练集。并将各自保存为list。如下图所示:

其中的内容为:数据集的路径和给图片贴上的标签。
并且将其汇总的数据保存为一个json文件:

Json文件中记录了图片的总数,图片的路径,图片的类数,以及对应每个类的标签,名字,测试集的数目,训练集的数目。
5.3 数据的处理
现在我们已经做好了数据集,但是这时我们并没有将数据传输给我们需要训练的模型,所以这个时候我们还需要对数据进行处理。
train_reader和test_reader分别用于获取训练集和测试集 paddle.reader.shuffle()表示每次缓存BUF_SIZE个数据项,并进行打乱 paddle.batch()表示每BATCH_SIZE组成一个batch
自定义数据集需要先定义自己的reader,把图像数据处理一些,并输出图片的数组和标签。
定义一个对训练集的图像进行处理修剪和数组变换,返回img数组和标签。
而sample是一个python元组,里面保存着图片的地址和标签。
而paddle接口提供了数据已经经过了归一化,居中等处理。如下图:就是处理好的数据。

5.4 人脸识别的历程
5.4.1 早期 模板匹配技术
早期:模板匹配技术,即用一个人脸模板与被检测图像中各个位置进行匹配。
成就:Rowley等人利用神经网络训练出对人脸-非人脸的多层感知器;也利用两个神经网络解决多角度人脸问题,第一个神经网络估计人脸角度并旋转,第二个则进行判断人脸-非人脸。但采用密集滑动窗口进行采样并且分类器的设计相对复杂,导致速度太慢。(在Neural network-based face detection)1998年
5.4.2 中期 voila-jonesVJ框架
中期:voila-jonesVJ框架(加入级联AdaBoost分类器(boost算法的改进):基于PAC学习理论建立的集成学习算法,其根本思想为通过多个简单的弱分类器,构建出准确率高的强分类器。)
成就:Viola和Jones用简单的Haar-like特征和级联AdaBoost分类器构造出一个检测器(VJ框架),速度和精度有所提高。《Rapid Object Dection using a Boosted Cascade of Simple Features》和《Robust Real-Time Face Detection》2001年
5.4.3 现在 深度学习
深度学习时代: CNN算法:采用卷积网络作为每一级的分类器。
用CNN卷积神经网络识别图片,一般需要的步骤有:
1、卷积层初步提取特征
2、池化层提取主要特征
3、全连接层将各部分特征汇总
4、产生分类器,进行预测识别 【1】
5.5 配置神经网络
5.5.1 CNN
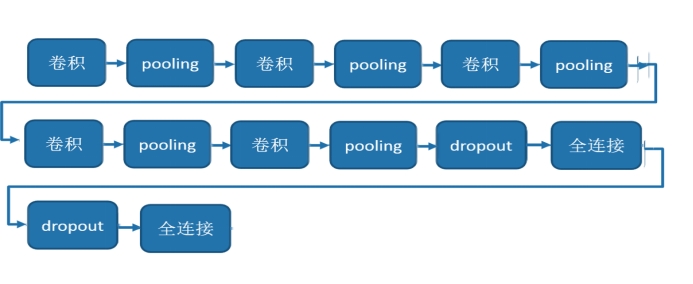
对于本次实验而言,使用了三个卷积池化层进行卷积,在每一次的池化后都进行一次dropout处理,最后进行两次全连接处理即可。如下图所示:

1.输入的图片类型:(-1,3,100,100)这里的-1为默认。就是经过了人脸居中归一化得到的100x100x3的图片的float32的数据,以及输入一个type_size这里的type_size就是我们要分类的种类数。

2.对卷积层数据进行池化处理,池化层为2x2,池化层步长为2,池化层实际上就是简化卷积的操作,将2x2简化为神经网络的一个神经元(使用激发函数relu传递特征值),这样每次移动两步就可以将一个2N2N的卷积层池化为NN。这样就可以大大简化操作,从而可以很快的提取主要特征。

3.在这里面引入了paddle库中的dropout方法: Dropout主要作用是减少过拟合,随机让某些权重不更新
Dropout是一种正则化技术,通过在训练过程中阻止神经元节点间的联合适应性来减少过拟合。
根据给定的丢弃概率dropout_prob = 0.5 随机将一些神经元输出设置为0,其他的仍保持不变。

4.输出层是以softmax为激活函数的全连接输出层,输出层的大小为图像类别type_size在这里即为4,生成分类器。
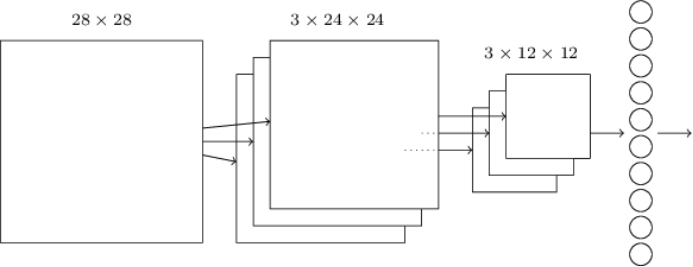
对于本次使用到的CNN就是在卷积,池化,全连接的基础上加上了一个dropout的操作,这个操作用来消除神经网络的过拟化。
5.5.3 VGG
与CNN所不同的地方是VGG比CNN多了一个全连接层,并且VGG的第一个全连接层的参数比CNN多了很多,所以训练起来VGG会比CNN花费更多的资源和时间。
1.首先定义了一组卷积网络,即conv_block。卷积核大小为3x3,池化窗口大小为2x2,窗口滑动大小为2,groups决定每组VGG模块是几次连续的卷积操作,dropouts指定Dropout操作的概率。所使用的img_conv_group是在paddle.networks中预定义的模块,由若干组 Conv->BN->ReLu->Dropout 和 一组 Pooling 组成。

2.五组卷积操作,即 5个conv_block。 第一、二组采用两次连续的卷积操作。第三、四、五组采用三次连续的卷积操作。每组最后一个卷积后面Dropout概率为0,即不使用Dropout操作。

3.最后接两层512维的全连接。

4.通过上面VGG网络提取高层特征,然后经过全连接层映射到类别维度大小的向量,再通过Softmax归一化得到每个类别的概率,也可称作分类器。
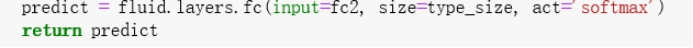
5.5.3 定义损失函数和准确率
本实验使用的是交叉熵损失函数,这个函数在分类任务上比较常用。
定义了一个损失函数后,还有对它求平均值,因为定义的是一个Batch的损失值,同时我们还可以定义一个准确率函数,这个可以在我们训练的时候输出分类的准确率。
5.6 训练网络和保存模型
5.6.1创建Executor
通过查询Paddle的接口,知道首先需要定义运算场所fluid.CPUPlace()和fluid.CUDAPlace(0)分别表示运算场所为CPU和GPU Executor接收传入的program,通过run()方法运行program【2】
而训练分为三步:第一步配置好训练的环境,第二部用训练集进行训练,并用验证集对训练进行评估,不断优化,第三步保存好训练的模型。
5.6.2展示模型训练曲线
5.6.3训练并保存模型
Executor接收传入的program,并根据feed map(输入映射表)和fetch_list(结果获取表) 向program中添加feed operators(数据输入算子)和fetch operators(结果获取算子)。
feed map为该program提供输入数据。fetch_list提供program训练结束后用户预期的变量。
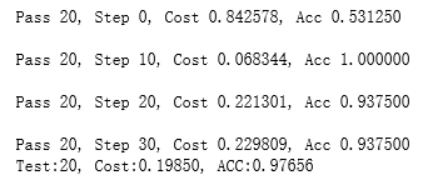
这次训练5个Pass。每一个Pass训练结束之后,再使用验证集进行验证,并求出相应的损失值Cost和准确率acc。
5.7 模型评估
5.7.1CNN
由于CNN是神经网络中最基础的卷积神经网络所以相较于VGG而言训练速度是很快的。训练20轮只要10分钟就可以。而40轮需要30分钟
而由于上面提供的损失函数coss以及准确率ACC:
在第20轮的时候:
在第40轮的时候:

可以看到20轮的时候CNN就已经有了较为理想的正确率。而40轮的时候结果太理想了,这种就是因为数据集过少。
而根据5.6.2中的展示训练曲线:
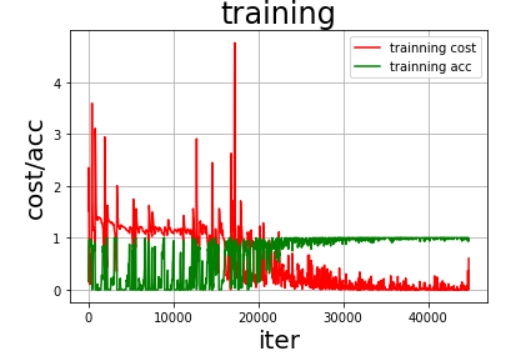
这是一共40轮的训练的cost和acc可以看到在中间的时候就已经趋于1了,于是我们将训练轮数定为20轮。
5.7.2VGG
在之前有提到因为VGG比CNN多了一个参数很多的全连接层所以VGG训练速度直线下降,对于一个20轮的训练需要4个多小时才可以将其完成。而对于40轮的需要8个多小时。
在第15轮的时候:

在第19轮的时候

训练了15轮的时候其实可以看到已经达到了预期的效果,但是自从第15轮之后ACC开始下降。
由于数据集的不够导致了这样的结果,所以这次我们选择第15轮训练出来的结果。
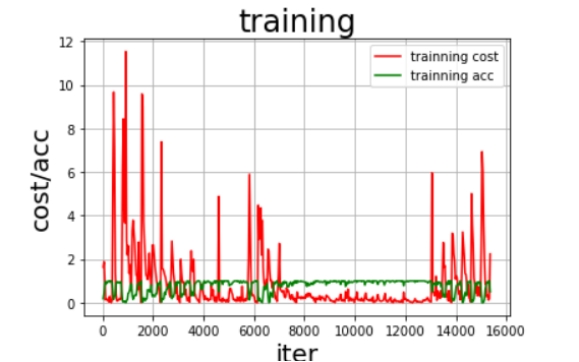
5.8 对视频进行识别并且进行可视化输出
5.8.1 对视频进行识别
我们在这里先假设我们的人脸识别准确率可以达到90%以上,实际上我们也达到了90%以上。但是在这里我们假设人脸识别是成功的,是可移植的。如果说分帧做好了的话,对于人脸识别的话我们就可以在一段视频中取多帧图片,对其进行人脸识别,然后取匹配结果中的最匹配的那一项作为结果,成为那个片段的标签用来标记这个片段中是哪个嘉宾。
在这里我们得到了一个列表,这个列表表明了视频中各个分好的片段中的嘉宾是谁。
下面是一个2分钟视频生成的各个镜头的片段:
[[0, 4.64], [4.68, 5.24], [5.28, 6.04], [6.08, 13.88], [13.92, 14.92], [14.96, 15.52], [15.56, 21.12], [21.16, 21.96], [22.0, 52.52], [52.56, 70.16], [70.2, 71.08], [71.12, 71.96], [72.0, 104.2], [104.24, 105.32], [105.36, 115.2]]
以及对应片段所对应的嘉宾是谁:
[‘窦文涛’, ‘梁文道’, ‘马家辉’, ‘窦文涛’, ‘周轶君’, ‘马家辉’, ‘窦文涛’, ‘马家辉’, ‘窦文涛’, ‘周轶君’, ‘梁文道’, ‘马家辉’, ‘窦文涛’, ‘周轶君’, ‘窦文涛’]
在这里我们对视频进行了手动的检查,发现百分百正确。从而从视频的角度上解决了课题。

部分的识别结果
5.8.2 将结果可视化输出
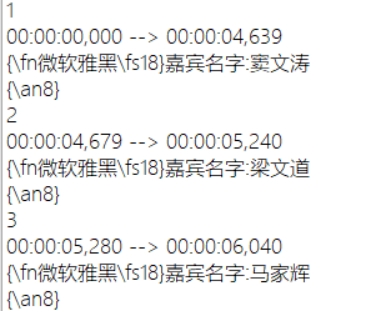
将上述的列表转化成SRT字幕的形式,输出在视频上,这样的生成的数据更加形象,并且方便观察。
将之前生成的视频时间段的List写成SRT字幕的格式,写入”文件名.srt”以及对应的嘉宾名字
字幕有两种:图形字幕与文字字幕相比于图形字幕,文字字幕更易于实现。本次使用的就是SRT(SubRip Text)
最后会生成如下的文件:
5.9 实验结果及分析




可以看到视频中体现的效果特别好,对于镜头的切换字幕也跟着切换。可以看到实验结果圆满成功。
具体的视频效果可以看我们发的源码文件中的video,由于需要外挂字幕所以需要一些专门的播放器导入字幕也可以观看效果。
这里使用的播放器为:potplayer。
下载链接:https://potplayer.en.softonic.com/
六:音频识别
这部分是由我的队友来进行实现的,具体的原理介绍,流程我这里不再赘述,可以参考他的报告,在这里我就简单描述一下大概原理过程。
声纹识别是对于一个人说话的,音色,频率,音高这三大要素进行建立模型从而可以达到对一个人声音的判断。但是在本次大作业中,我们要解决的问题远远不止这些。
在本次实验中,我们需要对一段音频,一段有很多人说话并且说笑的音频进行去识别出来哪个人什么时候说了什么话。这对于我们来说就很具有挑战性了。
所以在本次实验中我们采取了两种方式:
第一种分段式声纹识别,第二种说话人日志识别。
6.1 分段式声纹识别
基于tensorflow卷积神经网络算法实现的声纹识别训练得到的模型声纹识别准确率可以达到96.88%,但是实际上处理的时候却识别效果达不到预期。
无论是设置步长为2s,1s,0.5s识别出来的效果都特别差,由于声音之间的转折并不像视频上来的那么有冲击力(这个体现在如果说接电话的时候卡了,其实听者没什么,但是如果说看视频卡了的话,人的眼睛很快就可以感知出来),而基于人大脑的神经网络训练也是一样的道理。
原因:
结合视频发现,在每个人说话时,中间穿插着停顿、他人的插话和停顿…所以一个人的说话并不是我们设想的连续的一个步长的片段,换种说法,我们设置的步长限制了说话的连续性,这种简陋的分割注定了它不是一种成功的方案。
如果设置的步长过长(如:2s),嘉宾A说话的片段中间极有可能穿插着第二者B的插话,在进行声纹识别的时候,极大地影响了准确性,程序无法判断此时究竟是A或者是B,虽然会给出一个匹配相似度更高的结果,但是相似度过低,无法可信。如果设置的步长过短(如:0.5s),极大减少了突入插话的可能,但是伴随着更加严重的问题:准确率过低。
输入音频过短,经过处理输出的特征值信息很少,与语音库匹配相似度很低,结果仍是不可信的。设置步长为1s是比较好的一种结果,但是无法提升的68%准确率仍要舍弃分段式声纹识别方案。
6.2 说话人日志
由于一开始的时候我们对于这个课题的讨论就是对其进行声纹识别,但我们却没有做好分段的问题。
从而导致本来正确识别率很高的一个模型,我们却不能使用。之后在搜索引擎的帮助下,我们找到了一种方法:说话人日志。(Speaker diarization)
6.2.1 说话人日志原理
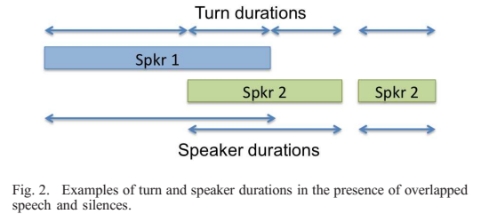
说话人日志可以理解为在一个连续的多人对话的语音片段中切分出不同的说话人片段,然后去判断每个语音片段属于哪个说话人,用来解决“谁在什么时候说话”的问题。可以简单理解为说话人分割(speaker segmentation)和声纹识别相结合的技术。而speaker segmentation就是确认when,即从当前speaker 切换到下一位出现的speaker,声纹识别在确认当前speaker的身份,speaker diarization就是完成把已切分的语音段分类到相同的说话人的任务。
为了解决“谁在什么时候说话”的问题,现有的说话人日志系统大多由多个相对独立的部分组成.如下:
(1)语音分割模块,将非语音部分去除,将输入的话语分割成小段;(2)提取emdedding特征向量模块。从小段中语音中提取能够判断说话人的特征向量,例如i-vector、d-vector等;
(3)聚类模块,确定说话人的数量,并将说话人的身份分配给每个段;
(4)重新分割模块,通过强制附加约束,进一步细化分类结果。
下图为Speaker的典型piprline:

Speaker Diarization的方法分为以下两种:
1)基于聚类的无监督方法:现代说话人分类系统通常基于k均值或谱聚类等聚类算法。由于这些聚类方法是无监督的,不能很好地利用数据中的监督说话人标签。此外,在线聚类算法在音频输入流的实时分类应用中通常质量较差。
如果单通道语音无overlapping,已知说话人个数,也知道每个人的说话起始与结束时间,那情况就好做多了;不过最好先有一个现成训练好的UBM/T或者DNN模型,以这些作为extractor,对这待识别的segments提取出高维矢量,再聚类,效果会好点。具体步骤可参考【4】
2)基于RNN的监督方法(UIS-RNN):该模型与常用的聚类算法的关键区别在于,该方法采用参数共享递归神经网络(RNN)对所有的说话人嵌入进行建模,并利用不同的RNN状态在时域内交错区分不同的说话人。
6.2.2 说话人日志结果分析
Uis-Rnn识别效果显著,能够输出连续的时间序列,识别结果连续(某种程度上损失了部分细节);最终准确率93.9%(选取样本有115s即115段,判断准确片段为108s即108段),准确率远超我们之前的分段式声纹识别方案;同时很多细节(人物的插话,语气词…)也能够识别出来。
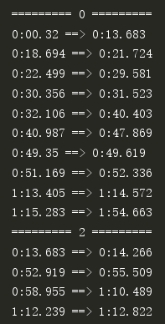

输出的讲话人序列以及对应时间段

讲话人的时间轴图
最终结果受每个窗口大小和重叠率的影响。当说话人的声音重叠太大的话,UIS-RNN会得出较少的说话人。窗口不能太短,他必须包含足够的信息。当然了,由于没有的出来说话人的序列,这个成功一半了,之后只要将其放入之前做好的声纹识别进行说话人识别即可。
6.3 数据可视化
用上面得出的结果将其放入在上述5.8.2中提到的制作SRT字幕模块当作输入即可。
结果:




可以看到结果是比较不错的。
七:代码查看方式
7.1 视频识别:
由于我们的人脸识别是在jupyter notebook中实现的。
所以我将其中的代码导出成了网页格式只要查看目录下的html文件即可,里面有我们实现的数据以及流程。
♻️ 资源
大小: 56.1MB
➡️ 资源下载:https://download.csdn.net/download/s1t16/87425292
相关文章
- 利用python求解物理学中的双弹簧质能系统详解
- Python - 在CentOS7.5系统中安装Python3
- Atitit web httphandler的实现 java python node.js c# net php 目录 1.1. Java 过滤器 servelet1 1.2. Python的
- Python编程:利用python编程实现对基于时间序列的数据(dataframe格式)按照指定时间范围进行单方向关联,不存在的日期补充为默认的NaN
- Python语言学习:在python中,如何获取变量的本身字符串名字而非其值/内容及其应用(在代码中如何查找同值的所有变量名)
- Python语言学习:利用python语言实现调用内部命令(python调用Shell脚本)—命令提示符cmd的几种方法
- Python之ffmpeg-python:ffmpeg-python库的简介、安装、使用方法之详细攻略
- Python之matplotlib:基于matplotlib库利用python语言实现一张画布显示多张图的多种方法
- Python语言学习之双下划线那些事:python和双下划线使用方法之详细攻略
- 〖Python语法进阶篇⑳〗- 综合实战 - 抽奖系统之user模块 - user的抽奖逻辑实现
- 【华为机试真题详解 Python实现】新员工座位安排系统【2023 Q1 | 100分】
- 【华为机试真题 Python实现】最优策略组合下的总的系统消耗资源数
- Ubuntu下完美切换Python版,即设置系统默认的python版本(亲测有效)
- Python编程:json序列化python对象
- python 将一个JSON 字典转换为一个Python 对象
- 写网络爬虫天然就是择Python而用 python 网络爬虫3
- python IDLE 背景修改 IDLE (Python GUI)
- python基础===pendulum '''Python datetimes made easy.'''
- python基础===八大排序算法的 Python 实现
- 【Python】Visual Studio Code 安装&&使用 hello python~~~~
- 【异常】前端ERR! stack Error: Can‘t find Python executable “python“, you can set the PYTHON env variable.
- 〖Python语法进阶篇⑯〗- 综合实战 - 抽奖系统之基础功能开发 - base奖品相关功能实现
- 〖Python语法进阶篇⑳〗- 综合实战 - 抽奖系统之user模块 - user的抽奖逻辑实现
- 〖Python自动化办公篇⑲〗 - python实现邮件自动化 - 邮件发送
- Python - Opencv应用实例之头发自动分割、计数、特征统计智能分析系统
- 【Python实战】 ---- python 实现 CSDN 的定时自动签到
- 【Python实战】 ---- python 自带的 venv 虚拟环境更新 pip 失败