
基于C++实现自然语言理【100010540】
自然语言理解工程报告
一、研究背景
1.1 涉及领域:
自然语言理解研究集认知科学、计算机科学、语言学、数学与逻辑学、心理学等多种学科于一身。
1.2 研究范畴:
不仅涉及对人脑语言认知机理、语言习得与生成能力的探索,而且,包括对语言知识的表达方式及其与现实世界之间的关系,语言自身的结构、现象、运用规律和演变过程。大量存在的不确定性和未知语言现象以及不同语言之间的语义关系等各方面问题的研究。
1.3 研究方法:
理性主义方法:
-
人的很大一部分语言知识是与生俱来的,由遗传决定。
-
在自然语言处理系统中,首先由词法分析器按照人编写的词法规则对输入句子的单词进行词法分析,然后,语法分析器根据人设计的语法规则对输入句子进行语法结构分析,最后再根据一套变换规则将语法结构映射到语义符号。
经验主义思想:
-
假定孩子的大脑一开始具有处理联想、模式识别和通用化处理的能力,这些能力能够使孩子充分利用感官输入来掌握具体的字眼语言结构。
-
这种方法是建立于统计方法基础之上。
1.4 存在的问题:
-
自然语言中大量存在的歧义现象,无论在词法层次、句法层次,还是在语义层次和语用层次,无论哪类语言单位,其歧义性始终都是困扰实现应用目标的一个根本问题。
-
对于一个特定系统来说,总是有可能遇到未知词汇、未知结构等各种意想不到的情况,而且每一种语言又都随着社会的发展而动态变化着,新的词汇、新的词义、新的词汇用法,甚至新的句子结构都在不断出现,尤其在口语对话和计算机网络对话、微博、博客等中,稀奇古怪的词语和话语结构更是司空见惯。
-
数学模型不够奏效,有些算法复杂度过高,鲁棒性太差等理论问题。
-
数据资源匮乏,覆盖率低,知识表示困难等知识资源方面的问题。
-
实现技术和系统集成方法不够先进等方面的问题。
1.5 现有解决方案:
理性主义的问题求解方法:
- 基于规则的分析方法,建立符号处理系统。
- 知识库 + 推理系统 → NLP 系统。
- 理论基础:Chomsky 的文法理论
经验主义的问题求解方法:
- 基于大规模真实语料(语言数据)的计算方法
- 语料库 + 统计模型 → NLP 系统
- 理论基础:统计学、信息论、机器学习
1.6 研究现状:
-
已开发完成一批颇具影响的语言资料库,部分技术已达到或基本达到实用化程度。例如:北京大学语料库和综合型语言知识库、HowNet、LDC 语言资源等,以及汉字输入、编辑、排版、文字识别、电子词典、语音合成和机器翻译、搜索引擎(Google,百度)等。
-
许多新的研究方向不断出现。例如:网络内容管理、网络信息监控和有害信息过滤、语音自动文摘、语音检索等
-
许多理论问题尚未得到根本性的解决。例如:语义理解问题、句法分析问题、指代歧义消解问题、汉语自动分词中的未登录词识别问题等,尚未建立起一套完整、系统的理论框架体系。
二、模型方法
2.1 词频统计:
基本理论:
利用计算机统计宋词中汉字出现的频率,并通过对大量语料的学习,利用宋词自身的特性,在经过大量语料学习后,使用在宋词当中出现频率较高的词语或者单字排列组合来生成宋词。
算法基本思想:
- 按顺序获取宋词语料中中文汉字信息。
- 按顺序依次截取一个中文字符,并统计相同的中文字符出现的频率,按顺序保存到文件中,直到语料被截取完毕。
- 按顺序依次截取两个中文字符,并统计相同的中文字符出现的频率,按顺序保存到文件中,直到语料被截取完毕。
- 按顺序依次截取三个中文字符,并统计相同的中文字符出现的频率,按顺序保存到文件中,直到语料被截取完毕。
- 获取在宋词中,不同词牌所对应的宋词生成规律。
- 从之前所获得的的一个、两个、三个中文字符中,分别抽取一定数量的出现频率较高的中文字符。
- 按照 E 中所获得的规律,生成相应词牌所对应的宋词。
算法评价:
由于此算法需要频繁查找已有的中文字符,所以使用哈希表作为存储结构,这样将每次查询的时间复杂度控制在 O(1),那么整个算法的复杂度在 O(n)的时间内即可完成。当然,使用哈希表的缺点便是,占用很大的内存资源。
2.2 汉语自动分词:
基本理论:
词是自然语言中能够独立运用的最小单位,,是自然语言处理的基本单位。自动词法分析就是利用计算机对自然语言的形态 (morphology) 进行分析,判断词的结构和类别等。词性或称词类(Part-of-Speech, POS)是词汇最重要的特性,是连接词汇到句法的桥梁。
算法基本思想:
正向最大匹配算法 (Forward MM, FMM) 描述:
假设句子:S = c1c2…cn ,某一词:w = c1c2…cm,m 为词典中最长词的字数。
-
令 i=0,当前指针 pi 指向输入字串的初始位置,执行下面的操作。
-
计算当前指针 pi 到字串末端的字数(即未被切分字串的长度)n,如果 n=1,转 第四步,结束算法。否则,令 m=词典中最长单词的字数,如果 n<m, 令 m=n;
-
从当前 pi 起取 m 个汉字作为词 wi,判断:
-
a.如果 wi 确实是词典中的词,则在 wi 后添加一个切分标志,转©;
-
b.如果 wi 不是词典中的词且 wi 的长度大于 1,将wi 从右端去掉一个字,转(a)步;否则(wi 的长度等于 1),则在 wi 后添加一个切分标志(单字),执行 ©步;
-
c.根据 wi 的长度修改指针 pi 的位置,如果 pi 指向
-
字串末端,转(4),否则,i=i+1,返回第二步;
-
-
输出切分结果,结束分词程序。
算法评价:
优点:
- 程序简单易行,开发周期短;
- 仅需要很少的语言资源(词表),不需要任何词法、句法、语义资源;
缺点:
-
歧义消解的能力差;
-
切分正确率不高,一般在 95%左右。
三、系统设计
(注:源码参见附录)
3.1 词频统计:
数据结构:
pair<string, int> :string:
中文字符 int:
相对应的中文字符出现频率
struct myNode {
string Chant; // 词牌名
string Rules; // 格式
};
算法实现:
对用于生成词频的文件 Ci.txt,进行预处理。
- 将所有 Ci.txt 中的中文汉字信息按顺序放入变量 Text 中。
- 实现函数:void InitText(string _infile);
获取一个中文字的词频,并输出到文件。
-
文本中文字体编码格式采用 GB2312,一个汉字需要两个字节来表示,所以遍历 Text,每次截取两个字节,并用哈希表来保存每次截取的一个中文字,记录出现的频率。遍历结束,将哈希表中保存的数据转移到 vector 中,进行排序,调用输出函数,按词频由大到小输出到文件中。
-
实现函数:void getOneWord(string out1);
获取两个中文字的词频,并输出到文件。
-
遍历 Text,每次截取四个字节(原因同上),并用哈希表来保存每次截取的两个中文字,记录出现的频率。遍历结束,将哈希表中保存的数据转移到 vector 中,进行排序,调用输出函数,按词频由大到小输出到文件中。
-
实现函数:void getTwoWord(string out2);
遍历 Text,每次截取六个字节(原因同上),并用哈希表来保存每次截取的三个中文字,记录出现的频率。遍历结束,将哈希表中保存的数据转移到 vector 中,进行排序,调用输出函数,按词频由大到小输出到文件中。
- 实现函数:void getThreeWord(string out3);
输出函数。
-
从 vector 中将保存的数据输出。
-
实现函数:
void myOutput(const vector<Pair_StrInt> &StrInt_Vec, string out);
生成词前的预处理。
- 分别抽取词频为前 100 的一个、两个、三个中文字。并对所选定的词牌进行定义。
定义规则:
为自动生成一首词,先根据不同词牌名,定义不同的格式。
在此:
1 代表 此处应填入一个中文字
2 代表 此处应填入两个中文字
3 代表 此处应填入三个中文字
0 代表 回车换行
- 代表 空格
其他字符 代表 该词牌中相应位置应该填入的符号
- 实现函数:void makePoetry(string out1, string out2, string out3);
自动生成并输出的词。
- 按照规则,以生成随机数在数组中定位中文字的方式自动生成并输出词。
- 实现函数:void Poetry(string _strTmp);
算法评估:
- 理论上,由于采用哈希表作为存储结构,故算法时间复杂度为 O(n)。
实际执行程序所需的时间为:

- 通过 VS2013 性能评测,得到:


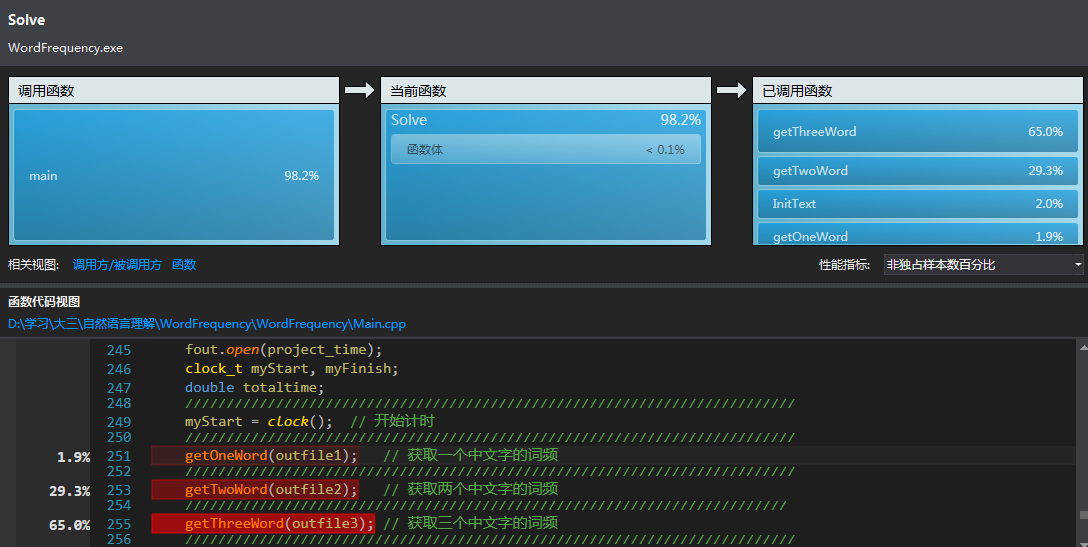
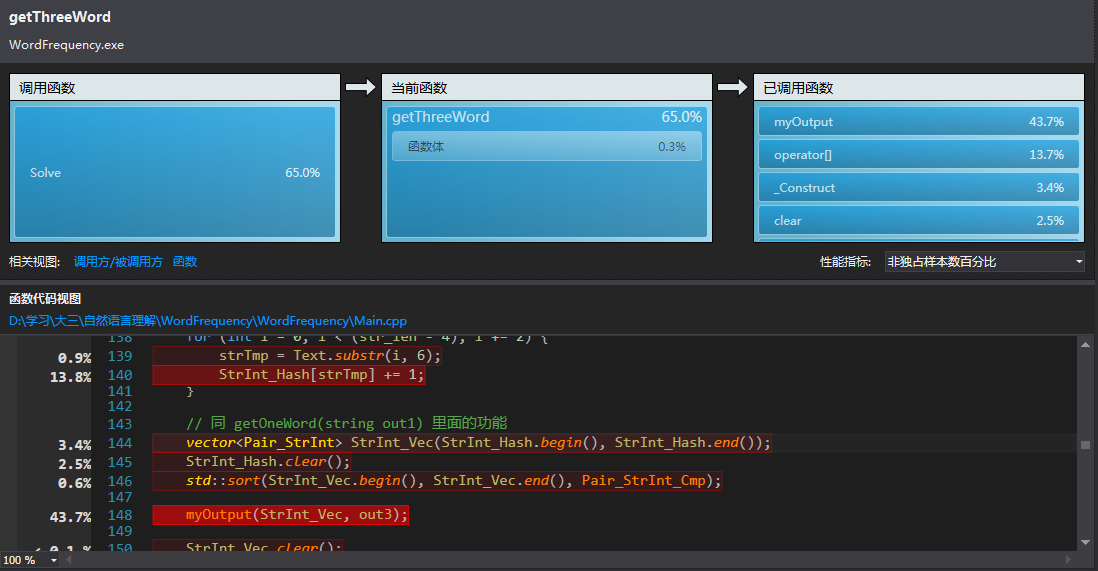
通过分析发现:
整体消耗资源最多的地方是在输出到文件,以及哈希表查询数据。
3.2 汉语自动分词:
数据结构:
unordered_map<string, int> StrInt_Hash : 哈希表存储词典(便于查询)
算法实现:
-
对词典进行预处理,截取出所有中文汉字。
循环读入字符串(遇到空格刚好读出一个字符串),直到文件结束。在此过程中,记录下词典中最长词的字节数。
实现函数: void IniText(string _ini_file);
-
正向最大匹配算法。
对汉语自动分词的正向匹配算法的实现(模型方法中有详细叙述),并将生成好的分词结果写入到文件中。
实现函数:void Solve(string _infile, string _outfile);
算法评估:
-
理论上,时间复杂度最差为:
*Maxlen) (Maxlen 代表词典中最长词的字节数)
实际执行程序所需的时间为(测试的数据量比较小):

- 通过 VS2013 性能评测,得到:

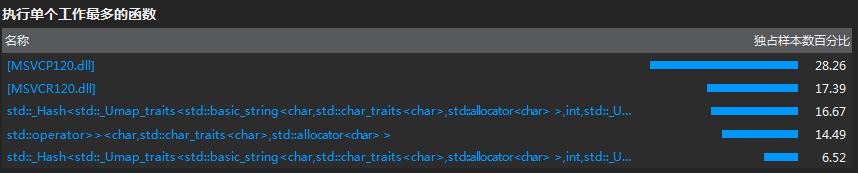
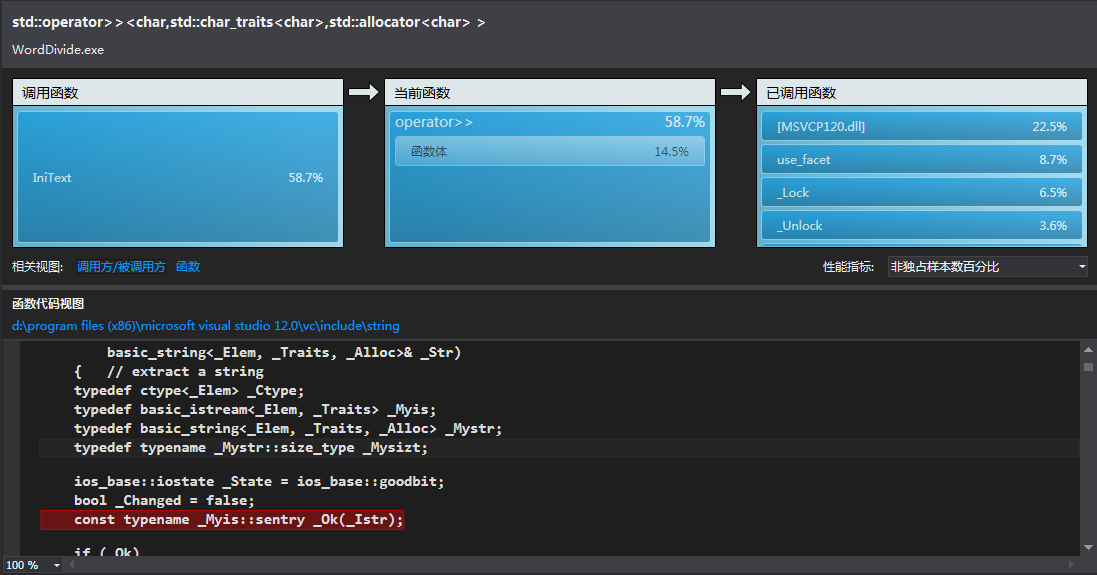
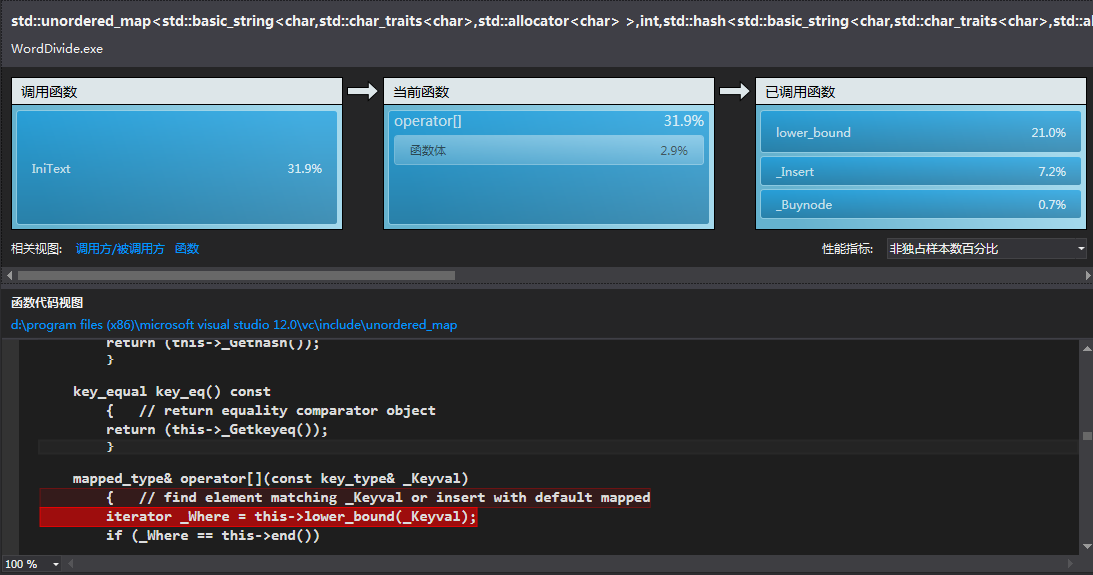
通过分析发现:
整体消耗资源最多的地方是在生成哈希表的时候。
四、系统演示与分析
4.1 词频统计:
1.输入文件:Ci.txt
输出:
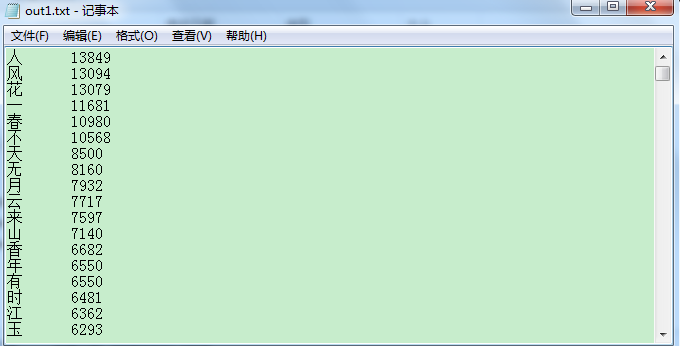
- 统计一个中文字的词频的文件
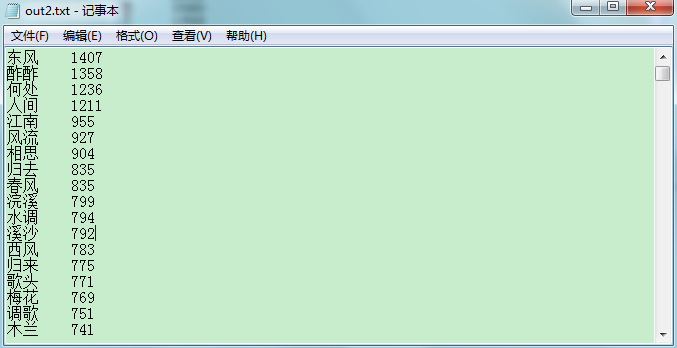
- 统计两个中文字的词频的文件
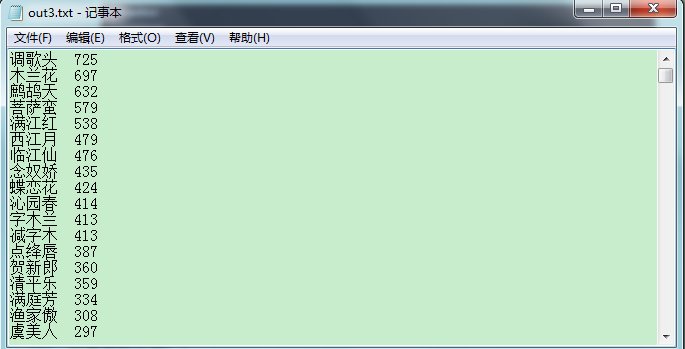
- 统计三个中文字的词频的文件
- 自动生成词:

2.出现的问题:
编码格式的问题:
- 由于 GB2312 所编码的汉字数目有限,所以对于 GB2312 没有编码的汉字,程序会无法识别,显示“?”。
3.改进方案:
-
在词中有许多词牌,鉴于时间关系,只举了一个例子,但由于生成词的规则已定,所以其他词牌按规则设计即可。
-
对文件的输入、输出进行优化,这样程序的运行时间会提高的更多。
4.2 汉语自动分词:
输入文件:

输出文件:

出现的问题:
- 编程时,出现失误,使输出文件出现异常。原因是,输出文件的缓冲区没有清空。
改进方案:
- 正向最大匹配算法算法本身存在一些弱点:歧义消解的能力差,切分正确率不高,一般在 95% 左右。所以,可以改进算法,采用诸如:最短路径法、基于语言模型的分词方法、基于 HMM 的分词方法、由字构词 (基于字标注)的分词方法等,并进行时间复杂度、性能、切分准确率进行对比分析。
五、感想、意见和建议
通过自然语言理解这门课程,使我对自然语言理解有了一定的了解,自然语言理解研究的是在人与人交际中以及人与计算机交际中的语言问题,是一门交叉学科,它涉及了语言学、计算机科学、数学、自动化技术等不同学科。自然语言理解所做的一些研究在当今社会乃至将来会有广阔的应用前景。
在课程中,老师所讲的自然语言理解所需的数学知识、语料库、语言模型、汉语自动分词、机器翻译等知识,帮助我们拓宽了知识面,学习了很多有趣的技术和想法,同时也为我们以后进一步去学习自然语言理解的知识奠定了基础。
在实验中,通过编写词频统计、汉语自动分词的程序,使我了解到了许多新的知识,并且解决了所遇到的新的问题,训练了编程能力。例如:学习了正向匹配算法;对中文字符的处理方法;对性能分析工具的使用。
当然,感觉自然语言理解这门课程的课时偏少,如果增加一些,那么对于我们增加对理论知识的理解更有帮助。
附录:
操作系统:Windows 7
编程语言:C++
开发工具:Visual Studio 2013
源码:
词频统计:
#include <iostream>
#include <fstream>
#include <algorithm>
#include <functional>
#include <string>
#include <vector>
#include <map>
#include <unordered_map>
#include <sstream>
#include <ctime>
using namespace std;
typedef long clock_t; // 测试程序运行时间
typedef pair<string, int> Pair_StrInt; // string: 中文字符 int: 相对应的中文字符出现频率
typedef vector<Pair_StrInt>::iterator Vec_Pair_StrInt_Itr; // 用于给词频排序
#define ERROR0 cerr << "Open error !!!" << endl; exit(1); // 警告:文件打开错误
#define ERROR1 cerr << "无法识别 !!!" << endl; exit(1); //
#define Lim 100 // 用于生成古诗词的中文字符来源:词频为前100的中文字符
string infile = "Ci.txt"; // 用于生成词频的文本
string outfile1 = "out1.txt"; // 统计一个中文字的词频的文件
string outfile2 = "out2.txt"; // 统计两个中文字的词频的文件
string outfile3 = "out3.txt"; // 统计三个中文字的词频的文件
string project_time = "project_time.txt"; // 存储整个程序所运行的时间的文件
string One_strArr[100]; // 用于生成古诗词,所用到的一个中文字符
string Two_strArr[100]; // 用于生成古诗词,所用到的两个中文字符
string Three_strArr[100]; // 用于生成古诗词,所用到的三个中文字符
ifstream fin;
ofstream fout;
string Text;
struct myNode {
string Chant; // 词牌名
string Rules; // 格式
};
// 比较函数
bool Pair_StrInt_Cmp(const Pair_StrInt& p0, const Pair_StrInt& p1) { return (p0.second > p1.second); }
// 定义哈希类型的存储结构,每次查找的时间复杂度控制在 O(1)。
unordered_map<string, int> StrInt_Hash;
// 对用于生成词频的文件Ci.txt,进行预处理:将所有Ci.txt中的中文汉字信息按顺序放入 变量Text 中。
void InitText(string _infile) {
fin.open(_infile);
if (!fin) { ERROR0; }
//
// 将整个文件读入 string : 流迭代器
std::ostringstream tmp;
tmp << fin.rdbuf();
string Text_tmp = tmp.str();
//
unsigned char Judge;
string strTmp;
int len = Text_tmp.size();
for (int i = 0; i < len; ) {
Judge = Text_tmp[i];
// 采用GB2312编码,所有中文字符的编码范围:[0xB0, 0xF7]
if (Judge >= 0xB0 && Judge <= 0xF7) {
strTmp = Text_tmp.substr(i, 2);
i += 2;
Text += strTmp;
}
else { ++i; }
}
fin.close();
fin.clear();
}
// 输出到文件
void myOutput(const vector<Pair_StrInt> &StrInt_Vec, string out) {
fout.open(out);
if (!fout) { ERROR0; }
vector<Pair_StrInt>::const_iterator pair_itr;
for (pair_itr = StrInt_Vec.begin(); pair_itr != StrInt_Vec.end(); ++pair_itr) {
fout << pair_itr->first << "\t" << pair_itr->second << endl;
}
fout.close();
fout.clear();
}
// 获取一个中文字的词频
void getOneWord(string out1) {
string strTmp;
int str_len = Text.size();
// 两个字符拼成一个中文字符,要获取一个中文字,所以 +2 递增。
for (int i = 0; i < str_len; i += 2) {
strTmp = Text.substr(i, 2);
StrInt_Hash[strTmp] += 1;
}
// 将哈希表里的数据放入 vector 中
vector<Pair_StrInt> StrInt_Vec(StrInt_Hash.begin(), StrInt_Hash.end());
StrInt_Hash.clear();
// 按词频排序
std::sort(StrInt_Vec.begin(), StrInt_Vec.end(), Pair_StrInt_Cmp);
// 输出到文件中
myOutput(StrInt_Vec, out1);
StrInt_Vec.clear();
}
// 获取两个中文字的词频
void getTwoWord(string out2) {
string strTmp;
int str_len = Text.size();
// 两个字符拼成一个中文字符,要获取两个中文字,所以 +4 递增。
for (int i = 0; i < (str_len - 2); i += 2) {
strTmp = Text.substr(i, 4);
StrInt_Hash[strTmp] += 1;
}
// 同 getOneWord(string out1) 里面的功能
vector<Pair_StrInt> StrInt_Vec(StrInt_Hash.begin(), StrInt_Hash.end());
StrInt_Hash.clear();
std::sort(StrInt_Vec.begin(), StrInt_Vec.end(), Pair_StrInt_Cmp);
myOutput(StrInt_Vec, out2);
StrInt_Vec.clear();
}
// 获取三个中文字的词频
void getThreeWord(string out3) {
string strTmp;
int str_len = Text.size();
// 两个字符拼成一个中文字符,要获取两个中文字,所以 +6 递增。
for (int i = 0; i < (str_len - 4); i += 2) {
strTmp = Text.substr(i, 6);
StrInt_Hash[strTmp] += 1;
}
// 同 getOneWord(string out1) 里面的功能
vector<Pair_StrInt> StrInt_Vec(StrInt_Hash.begin(), StrInt_Hash.end());
StrInt_Hash.clear();
std::sort(StrInt_Vec.begin(), StrInt_Vec.end(), Pair_StrInt_Cmp);
myOutput(StrInt_Vec, out3);
StrInt_Vec.clear();
}
// 定义自动生成一首词的规则
/*
为自动生成一首词,先根据不同词牌名,定义不同的格式。
在此:
1 代表 此处应填入一个中文字符
2 代表 此处应填入两个中文字符
3 代表 此处应填入三个中文字符
0 代表 回车换行
- 代表 空格
其他字符 代表 该词牌中相应位置应该填入的符号
据以上规则:
1)makePoetry(string out1, string out2, string out3) 函数对所选定的词牌进行定义。
2)Poetry(string _strTmp) 函数自动生成并输出的词。
*/
// 自动生成词
void Poetry(string _strTmp) {
int len = _strTmp.size();
int myRandom;
srand((unsigned)(time(NULL)));
for (int i = 0; i < len; ++i) {
switch (_strTmp[i])
{
case '2': {
myRandom = rand() % Lim;
cout << Two_strArr[myRandom];
break;
}
case '1': {
myRandom = rand() % Lim;
cout << One_strArr[myRandom];
break;
}
case '3': {
myRandom = rand() % Lim;
cout << Three_strArr[myRandom];
break;
}
case '0': {
cout << '\n';
break;
}
case '-': {
cout << " ";
break;
}
default: {
cout << _strTmp.substr(i, 2);
++i;
break;
}
}
}
cout << endl;
}
// 生成词前的预处理
void makePoetry(string out1, string out2, string out3) {
ifstream fin1, fin2, fin3;
ofstream fout1, fout2, fout3;
fin1.open(out1);
if (!fin1) { ERROR0; }
fin2.open(out2);
if (!fin2) { ERROR0; }
fin3.open(out3);
if (!fin3) { ERROR0; }
string strTmp;
for (int i = 0; i < Lim; ++i) {
getline(fin1, strTmp);
One_strArr[i] = strTmp.substr(0, 2);
getline(fin2, strTmp);
Two_strArr[i] = strTmp.substr(0, 4);
getline(fin3, strTmp);
Three_strArr[i] = strTmp.substr(0, 6);
}
myNode node0;
node0.Chant = "念奴娇";
node0.Rules = "·220--22,12,222。22,21:222。22,22,23。22,222。0--222,23,22。22,3222。22,23,22。22,222。0";
string strTmp0 = "----" + node0.Chant + node0.Rules; // "----"表示为生成的词设置格式
Poetry(strTmp0);
//system("pause");
}
void Solve() {
InitText(infile);
ofstream fout;
fout.open(project_time);
clock_t myStart, myFinish;
double totaltime;
//
myStart = clock(); // 开始计时
//
getOneWord(outfile1); // 获取一个中文字的词频
//
getTwoWord(outfile2); // 获取两个中文字的词频
/
getThreeWord(outfile3); // 获取三个中文字的词频
//
myFinish = clock(); // 计时结束
totaltime = (double)(myFinish - myStart) / CLOCKS_PER_SEC; // 计算出程序总的运行时间
fout << "运行时间为: " << totaltime << " 秒。" << endl;
fout.close();
fout.clear();
makePoetry(outfile1, outfile2, outfile3); // 自动生成一首词
}
int main() {
Solve();
return 0;
}
汉语自动分词:
#include <iostream>
#include <cstdlib>
#include <cstdio>
#include <string>
#include <fstream>
#include <sstream>
#include <unordered_map>
#include <ctime>
using namespace std;
#define MAX(a,b) ((a)>(b)?(a):(b)) // 获取两个值中最大的
#define MIN(a,b) ((a)<(b)?(a):(b)) // 获取两个值中最小的
#define ERROR0 cerr << "Open error !!!" << endl; exit(1); // 文件打开出错提示
int MaxLen; // 词典中最长词的字节数
unordered_map<string, int> StrInt_Hash; // 哈希表存储词典(便于查询)
const string ini_file = "1998-01-2003版-带音.txt"; // 词典
const string infile = "in.txt"; // 需要分词的文件
const string outfile = "out.txt"; // 分词后的文件
string project_time = "project_time.txt"; // 存储整个程序所运行的时间的文件
// 对词典进行预处理,截取出所有中文汉字。
void IniText(string _ini_file) {
ifstream fin;
fin.open(_ini_file);
if (!fin) { ERROR0; }
string strTmp, str;
int pos;
MaxLen = 0;
// 循环读入字符串(遇到空格刚好读出一个字符串),直到文件结束。
// 在此过程中,记录下词典中最长词的字节数
while (fin >> strTmp) {
pos = strTmp.find("/");
str = strTmp.substr(0, pos);
if (str.size() > MaxLen) {
MaxLen = str.size();
}
StrInt_Hash[str] = 1;
}
fin.close();
fin.clear();
}
// 正向最大匹配算法
void Solve(string _infile, string _outfile) {
IniText(ini_file);
ifstream fin;
ofstream fout;
fin.open(_infile);
fout.open(_outfile);
if (!fin) { ERROR0; }
if (!fout) { ERROR0; }
//
ofstream fout_time;
fout_time.open(project_time);
if (!fout) { ERROR0; }
clock_t myStart, myFinish;
double totaltime;
myStart = clock(); // 开始计时
//
//
// 将整个文件读入 string : 流迭代器
std::ostringstream tmp;
tmp << fin.rdbuf();
string Text_tmp = tmp.str();
//
int myEnd = Text_tmp.size();
int myBegin = 0;
while (myBegin < myEnd) {
string str;
int num;
for (num = MIN(MaxLen, (Text_tmp.size() - myBegin)); num > 0; num -= 1) {
str = Text_tmp.substr(myBegin, num);
if (StrInt_Hash.find(str) != StrInt_Hash.end()) {
fout << str;
myBegin += num;
break;
}
}
if (0 == num) {
fout << Text_tmp.substr(myBegin, 1);
myBegin += 1;
}
fout << "/";
}
//
myFinish = clock(); // 计时结束
totaltime = (double)(myFinish - myStart) / CLOCKS_PER_SEC; // 计算出程序总的运行时间
fout_time << "运行时间为: " << totaltime << " 秒。" << endl;
fout_time.close();
fout_time.clear();
//
fout.close();
fout.clear();
fin.close();
fin.clear();
}
int main() {
Solve(infile, outfile);
return 0;
}
♻️ 资源
大小: 23.0MB
➡️ 资源下载:https://download.csdn.net/download/s1t16/87400373
相关文章
- 《数字图像处理与机器视觉——Visual C++与Matlab实现(第2版)》——第 1 章 MATLAB数字图像处理编程基础2.1 MATLAB R2011a简介
- 《C++面向对象高效编程(第2版)》——2.14 类的实现者
- 基于C++实现存储器的分配与回收算法【100010768】
- 基于C++实现(控制台)校园卡管理系统【100010752】
- 基于 C++ 语言实现 A算法的求解八数码问题的程序【100010703】
- 基于QT(C++)+Oracle实现的(界面)教务管理系统【100010664】
- 基于C++(Cocos2d)实现的射击类游戏【100010652】
- 基于C++ 哈夫曼编码 实现(控制台)文件加密系统【100010605】
- 基于 C++ 实现日志文件压缩【100010585】
- 基于 C++和 MySQL 实现(控制台)汽销售管理系统【100010538】
- 基于C++实现集合的关系性质计算器【100010522】
- 基于C++实现(控制台)学生档案管理系统【100010515】
- 基于C++实现(控制台)银行业务系统【100010510】
- 基于C++实现(控制台)学籍管理系统【100010507】
- 基于C++实现(控制台)校友录管理系统【100010421】
- 基于C++面向对象实现(控制台)宠物小精灵对战系统【100010120】
- 基于QT(C++)实现绘图程序【100010115】
- 基于C+++FLTK实现(WinForm)超市收银系统【100010032】
- 基于C++实现(控制台)单位职工管理系统(数据结构)【100010017】
- 基于C++实现(控制台)人事管理系统【100010009】
- 基于QT(C++) 实现哈夫曼压缩(多线程)【100010471】
- C++从零实现简单深度神经网络(基于OpenCV)
- 大话设计模式C++实现-第17章-适配器模式