
基于C++实现 bp 神经网络的手写数字识别【100010276】
基于 bp 神经网络的手写数字识别
1 设计目的与要求
通过神经网络的方法,用于识别 mnist 手写数据,并分析各种超参数对识别效果的影响,自己手写替换所有库函数,尝试通过更换激活函数,进行数据增强来提高识别效果,尝试使用卷积神经网络进行识别。
2 设计原理
2.1:bp 神经网络的原理与构建:
BP(BackPropagation)神经网络构建 1. 理论模型
1)神经元 M-P 模型
按照生物神经元,我们建立 M-P 模型。为了使得建模更加简单,以便于进行形式化表达,我们忽略时间整合作用、不应期等复杂因素,并把神经元的突触时延和强度当成常数。下图就是一个 M-P 模型的示意图。

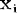 结合 M-P 模型示意图来看,对于某一个神经元 j,它可能接受同时接受了许多个输入信号,用表示。由于生物神经元具有不同的突触性质和突触强度,所以对神经元的影响
结合 M-P 模型示意图来看,对于某一个神经元 j,它可能接受同时接受了许多个输入信号,用表示。由于生物神经元具有不同的突触性质和突触强度,所以对神经元的影响
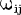
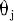 不同,我们用权值来表示,其正负模拟了生物神经元中突出的兴奋和抑制,其大小则代表了突出的不同连接强度。表示为一个阈值(threshold),或称为偏置(bias)。由于累加性,我们对全部输入信号进行累加整合,相当于生物神经元中的膜电位,其值就为:
不同,我们用权值来表示,其正负模拟了生物神经元中突出的兴奋和抑制,其大小则代表了突出的不同连接强度。表示为一个阈值(threshold),或称为偏置(bias)。由于累加性,我们对全部输入信号进行累加整合,相当于生物神经元中的膜电位,其值就为:
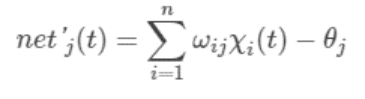
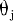 神经元激活与否取决于某一阈值电平,即只有当其输入总和超过阈值时,神经元才被激活而发放脉冲,否则神经元不会发生输出信号。整个过程可以用下面这个函数来表示:
神经元激活与否取决于某一阈值电平,即只有当其输入总和超过阈值时,神经元才被激活而发放脉冲,否则神经元不会发生输出信号。整个过程可以用下面这个函数来表示:
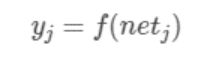
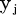
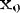 表示神经元 j 的输出,函数 f 称为激活函数(ActivationFunction)或转移函数(TransferFunction),net’j(t)称为净激活(netactivation)。若将阈值看成是神经元 j 的一个输入的权重
表示神经元 j 的输出,函数 f 称为激活函数(ActivationFunction)或转移函数(TransferFunction),net’j(t)称为净激活(netactivation)。若将阈值看成是神经元 j 的一个输入的权重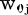 ,则上面的式子可以简化为:
,则上面的式子可以简化为:

若用 X 表示输入向量,用 W 表示权重向量,即:

则神经元的输出可以表示为向量相乘的形式:

若神经元的净激活为正,称该神经元处于激活状态或兴奋状态,若净激活为负,则称神经元处于抑制状态。
由此我们可以得到总结出 M-P 模型的 6 个特点:
<1> 每个神经元都是一个多输入单输出的信息处理单元;
<2> 神经元输入分兴奋性输入和抑制性输入两种类型;
<3> 神经元具有空间整合特性和阈值特性;
<4> 神经元输入与输出间有固定的时滞,主要取决于突触延搁;
<5> 忽略时间整合作用和不应期;
<6> 神经元本身是非时变的,即其突触时延和突触强度均为常数。这种“阈值加权和”的神经元模型称为 M-P 模型(McCulloch-PittsModel),也称为神经网络的一个处理单元(PE,ProcessingElement)。
2)BP 神经网络
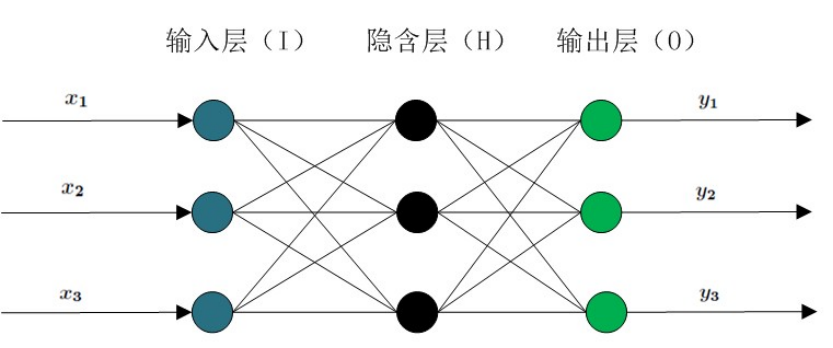
BP(BackPropagation)神经网络分为两个过程:工作信号正向传递子过程与误差信号反向传递子过程。BP(BackPropagation)神经网络的学习过程由信号的正向传播与误差的反向传播两个过程组成。正向传播时,输入样本从输入层传入,经隐含层逐层处理后,传向输出层。若输出层的实际输出与期望输出不符,则转向误差的反向传播阶段。误差的反向传播是将输出误差以某种形式通过隐含层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。在 BP 神经网络中,单个样本有 m 个输入,有 n 个输出,在输入层和输出层之间通常还有若干个隐含层。一个三层的 BP 网络就可以完成任意的 m 维到 n 维的映射。即这三层分别是输入层(I),隐含层(H),输出层(O),如下图所示。
 正向传递子过程:现在设节点
正向传递子过程:现在设节点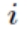 和节点
和节点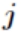 之间的权值为
之间的权值为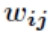 ,节点
,节点 的阀值为 ,每个节点的输出值为
的阀值为 ,每个节点的输出值为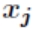 ,而每个节点的输出值是根据上层所有节点的输出值、当前节点与上一层所有节点的权值和当前节点的阀值还有激活函数来实现的。具体计算方法如下:
,而每个节点的输出值是根据上层所有节点的输出值、当前节点与上一层所有节点的权值和当前节点的阀值还有激活函数来实现的。具体计算方法如下:

其中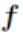 为激活函数,一般选取 S 型函数或者线性函数。正向传递的过程比较简单,按照上述公式计算即可。在 BP 神经网络中,输入层节点没有阀值。
为激活函数,一般选取 S 型函数或者线性函数。正向传递的过程比较简单,按照上述公式计算即可。在 BP 神经网络中,输入层节点没有阀值。
反向传递子过程:在 BP 神经网络中,误差信号反向传递子过程比较复杂,它是基于 Widrow-Hoff 学习规则的。假设输出层的所有结果为[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BrshTWYO-1675646378394)(https://www.writebug.com/myres/static/uploads/2021/11/24/ca28ecf34e93d687da69ae76921d2245.writebug)],误差函数如下
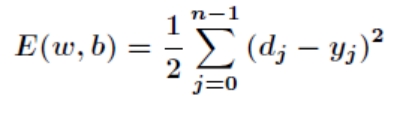
而 BP 神经网络的主要目的是反复修正权值和阀值,使得误差函数值达到最小。Widrow-Hoff 学习规则是通过沿着相对误差平方和的最速下降方向,连续调整网络的权值和阀值,根据梯度下降法,权值矢量的修正正比于当前位置上 E(w,b)的梯度,对于第 j 个输出节点有
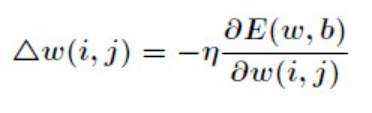
对激活函数求导,得到
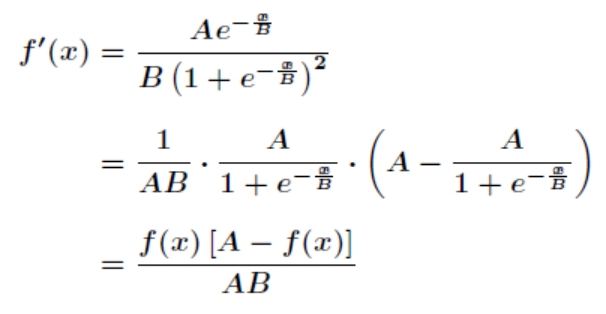
 那么接下来针对有
那么接下来针对有
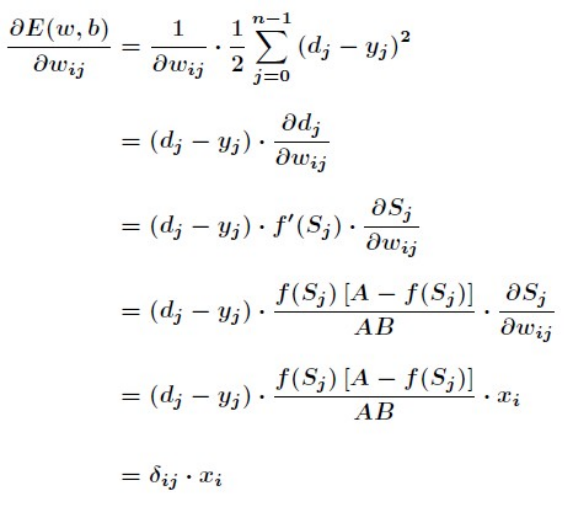
其中有
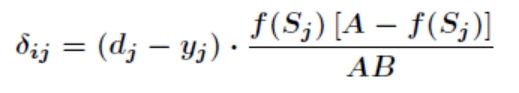
同样对于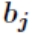 有
有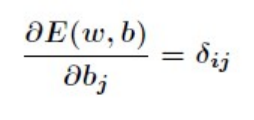
这就是著名的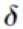 学习规则,通过改变神经元之间的连接权值来减少系统实际输出和期望输出的误差,这个规则又叫做 Widrow-Hoff 学习规则或者纠错学习规则。上面是对隐含层和输出层之间的权值和输出层的阀值计算调整量,而针对输入层和隐含层的阀值调整量的计算更为复杂。假设
学习规则,通过改变神经元之间的连接权值来减少系统实际输出和期望输出的误差,这个规则又叫做 Widrow-Hoff 学习规则或者纠错学习规则。上面是对隐含层和输出层之间的权值和输出层的阀值计算调整量,而针对输入层和隐含层的阀值调整量的计算更为复杂。假设 是输入层第 k 个节点和隐含层第 i 个节点之间的权值,那么有
是输入层第 k 个节点和隐含层第 i 个节点之间的权值,那么有

其中有
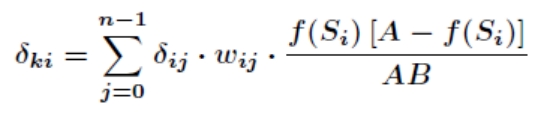
根据梯度下降法,那么对于隐含层和输出层之间的权值和阀值调整如下
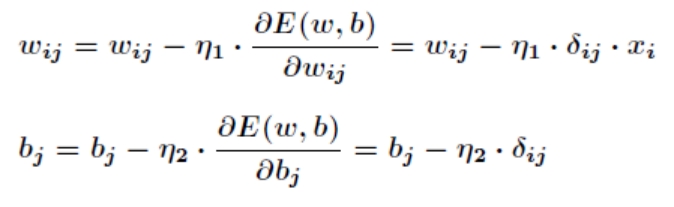
而对于输入层和隐含层之间的权值和阀值调整同样有
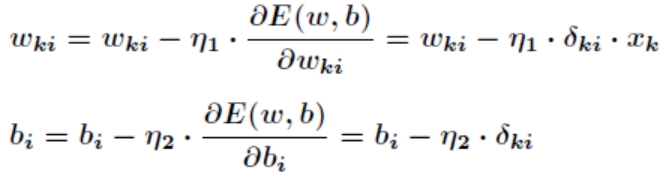
如上所述,在实际过程中,BP 神经网络的训练流程可大致分为 5 步:初始化网络的突触权值和阈值矩阵;训练样本的呈现;前向传播计算;误差反向传播计算并更新权值;迭代,用新的样本进行前向传播与反向传播,直至满足停止准则。
2.2 卷积神经网络的原理
卷积神经网络原理:

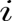
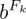
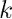 首先使用过滤器,将 28×28 的输入层的数据处理并建立卷积层,用
首先使用过滤器,将 28×28 的输入层的数据处理并建立卷积层,用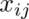 表示所读入的图像的行
表示所读入的图像的行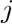 列位置的像素数据,用
列位置的像素数据,用 表示过滤器的第行第
表示过滤器的第行第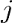 列的权重,用 表示过滤器
列的权重,用 表示过滤器
 的偏置,本程序中过滤器层数为 30,过滤器边长为 25,则卷积层中第
的偏置,本程序中过滤器层数为 30,过滤器边长为 25,则卷积层中第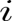 行第
行第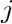 列的数值为:
列的数值为:
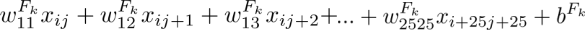
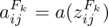 设激活函数为 a(z),则神经单元的输出即卷积层第
设激活函数为 a(z),则神经单元的输出即卷积层第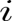 行第
行第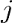 列的值为 。
列的值为 。
然后将卷积层每 2×2 个神经单元压缩为一个神经单元,形成池化层,这里使用最大化
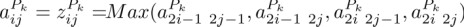 池,从 4 个神经单元的输出中选出最大值作为代表,即:池化层的边长为(28-25+1)/2=2。
池,从 4 个神经单元的输出中选出最大值作为代表,即:池化层的边长为(28-25+1)/2=2。
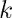

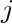 输出层有 10 个神经单元,分别代表十个数。令
输出层有 10 个神经单元,分别代表十个数。令 表示从池化层第个子层第行第
表示从池化层第个子层第行第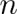

 列的神经单元指向输出层的第个神经单元的权重,
列的神经单元指向输出层的第个神经单元的权重,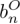 为输出层第个单元的神经偏置,则输出层第
为输出层第个单元的神经偏置,则输出层第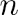 个神经单元的加权输入为:
个神经单元的加权输入为:
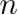
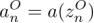
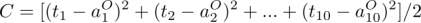
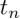 输出层第个神经单元的输出值为
输出层第个神经单元的输出值为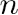 ,代价函数:其中为输出层第个神经单元的输出期望值,为 1 或 0。
,代价函数:其中为输出层第个神经单元的输出期望值,为 1 或 0。
卷积神经网络误差反向传播法:梯度下降法基本式为:
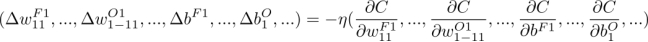
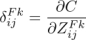
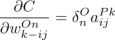 本程序中学习率取的 0.08。定义神经单元误差 ,
本程序中学习率取的 0.08。定义神经单元误差 ,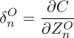 ,根据函数求导链规则有输出神经单元的梯度分量:
,根据函数求导链规则有输出神经单元的梯度分量:
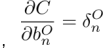
 卷积层神经单元的梯度分量:
卷积层神经单元的梯度分量:
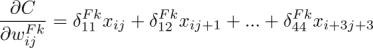

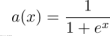 因此,计算神经单元误差即可得到代价函数的梯度。计算输出层单元神经误差:其中 时有
因此,计算神经单元误差即可得到代价函数的梯度。计算输出层单元神经误差:其中 时有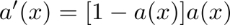 ;卷积层神经单元误差递推式:
;卷积层神经单元误差递推式:
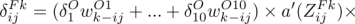 (当
(当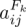 在区块中最大时为 1,否则为 0)
在区块中最大时为 1,否则为 0)
根据已有数据进行训练并进行测试,不断调整参数,最后对测试集进行测试,准确率可达到 96.5%。
3 设计内容
3.1bp 神经网络的实现
1)BP 神经网络基本参数

其中输入层节点数为 784,由于手写数字识别的结果只能为 0-9 这十种,故输出层节点数为 10。而对于隐含层节点数,有如下经验公式确定:
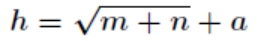
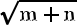

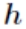
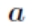
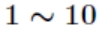 其中 为隐含层节点数目,
其中 为隐含层节点数目,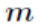 为输入层节点数目,
为输入层节点数目,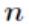 为输出层节点数目, 为之间的调节常数。在本次项目中 ,故取隐含层节点数为 30。
为输出层节点数目, 为之间的调节常数。在本次项目中 ,故取隐含层节点数为 30。
2)为权重矩阵和偏置向量随机赋初值

利用 RAND_MAX 函数进行随机初始化,目的是使对称失效。否则的话,所有对称结点的权重都一致,也就无法区分并学习了
3)激活函数的定义

提供 sigmoid,Leaky_Relu,Relu 三种激活函数可供选择。
4)正向传播——由输入图像得到隐含层输出、由隐含层输出得到网络最终输出

5)损失函数

6)训练 BP 神经网络



3.2 可视化程序
搭建卷积神经网络以及卷积网络参数的调整,并将调整的参数用文件储存起来。
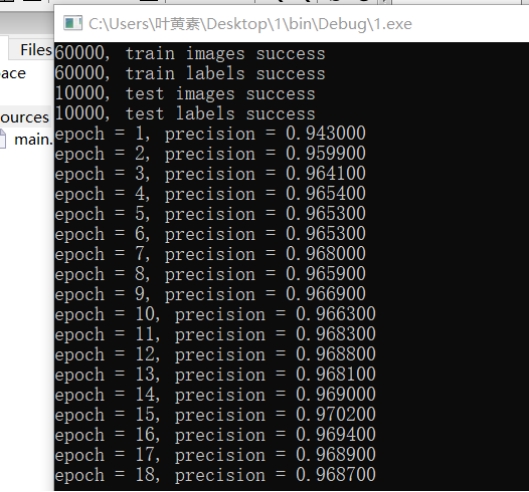
上图为开始卷积层设 50 时的训练过程,训练后发现利用训练好的参数,识别过程花的时间太长,因此进行了简化,将卷积层降到了 30,训练后的准确率同样也与层数为 50 时差不了多少。可以看到准确率并不是一味的增加,而是先增后减,尝试了在一轮轮学习过程中一旦准确率降低就将学习率减半,但结果准确率仍是不停跳变,也就作罢。最后在卷积网络层数为 30 时,训练过程中准确率最高的一次的参数保存下来。
使用 esayX 创建图形化界面,可以用鼠标在画板上写数字,原理是鼠标按键后,隔一段距离采集鼠标坐标,画好后在处理过程进行连线。鼠标移动速度越快,由于得到坐标需要花时间,则得到的两点距离越长,程序将将两点间连越细的线,这样手写的过程再处理后会得到更逼真自然的效果,最后进行马赛克处理,得到 28×28 个亮度数据。

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P8RWiNvJ-1675646378422)(https://www.writebug.com/myres/static/uploads/2021/11/24/6e1ecebff6548ce6f450580c7011f8d3.writebug)]

对于上图,两种识别方式都得到正确的结果,但可能由于训练集里手写数字的风格不同的影响,自己手写很多情况下反而会经常不准。
在测试过程中可以依次查看测试数据,如图

期间也能看到疑似数据中出现的问题,例如数字上的黑斑,笔画的缺失,只剩下边框等问题,如下图:


查看神经网络识别错误的图像能发现很多奇奇怪怪的图形,例如下面的数字的标签分别是 7,7,2,分别被识别成了 9,8,0。

4 结果分析
4.1 调整超参数
需要调整的超参数大致是学习率和学习轮数,经过控制变量之后,训练了三次寻找规律。1.学习率:0.08;学习轮数:10

可以看出随着学习轮数上升,预测置信度还在上升,所以增加学习轮数 2.学习率:0.08;学习轮数:15

可以看出学习轮数增加到 15 的时候,置信度已经到了 0.9614,达到了一个比较高的水平,且增加速度已经变慢,再增加学习轮数训练时间会比较长,加上可能会造成过拟合现象,遂认为 15 轮是一个理想的学习轮数。
3.学习率:0.2;学习轮数:15
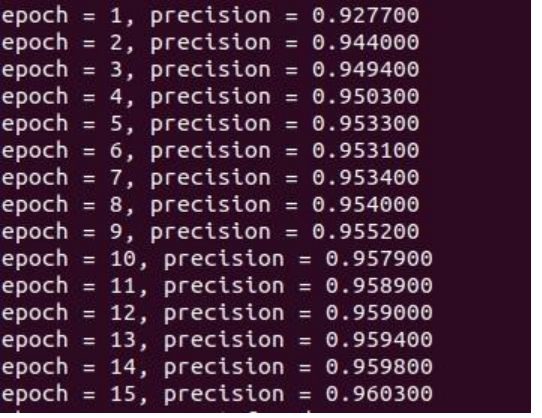
增加学习率,会使得收敛速度变快,但是模型精度会下降,得不偿失,由上述分析,最后选择学习率:0.08;学习轮数:15。
4.2 数据增强
因为 minst 数据集只有 6 万张图片作为训练集,所以我想进行数据增强,将训练集进行扩充,希望达到提高识别率的作用。代码中先将训练集由二进制文件数据存在数组里,然后通过随机数,以每种数据增强 30% 的几率进行,这里尝试了 6 种数据增强,顺时针 90 度,逆时针 90 度,旋转 180 度,左右翻转,上下翻转,平移,均是直接对数组进行操作,操作完成之后的数据存在一个新的数组里面,然后再将原训练集和增强后的数据集拼接起来形成一个新的训练集,对模型进行训练。

进行了三次训练:
1.学习率:0.08;学习轮数:15,翻转平移旋转
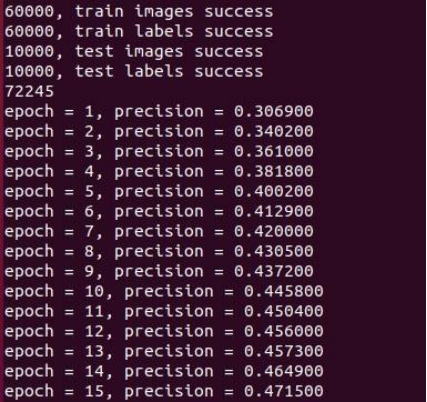
2.学习率:0.08;学习轮数:15,翻转平移

3.学习率:0.08;学习轮数:15,平移

对上述三次训练分析可见,旋转翻转两个操作对模型精度伤害极大,经过分析应该是 minst 数据集全由数字组成,旋转翻转可能会使得数据特征减弱。
平移也对模型精度有一点减弱,对 minst 数据集由二进制格式文件通过 python 转为 jpg 文件可以发现,图片像素是 28*28,而大部分数字都填满了整张图片,左右上下平移一个像素都有可能会使得数字移出图片,导致数据集出现错误,遂最后放弃了数据增强

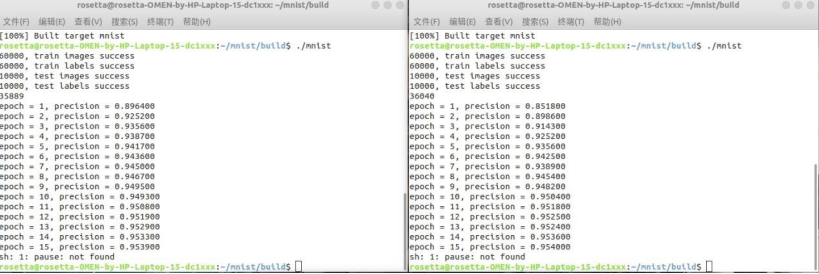
4.3 替换激活函数
之前用的激活函数均是 sigmoid,尝试了更换激活函数为 Relu 和 Leaky_Relu,左图为 Relu,右图为 Leaky_Relu
5 总结与体会
通过本次课设,我们初步了解到计算机语言中神经网络的魅力,这是用代码对人脑的识别系统的简单模拟,是人类创造的计算机世界与自然创造的人脑智慧相衔接的初步桥梁。课设任务中,我们成功完成了利用汇编语言实现对人脑识别数字的初步模拟,同时也面临问题,显然,人脑神经结构旁支交错,现阶段的模拟程度还远远不够。课设中,我们将任务分工,难点一步步攻克,最终的成功结果也让我们明白了团队合作、个人学习精神的重要性。
♻️ 资源
大小: 1.72MB
➡️ 资源下载:https://download.csdn.net/download/s1t16/87354549
相关文章
- C++随笔(2)
- 第八届蓝桥杯省赛C++A/B组,第八届蓝桥杯省赛JAVAA/B组—分巧克力(二分)
- C/C++基础讲解(六十六)之系统篇(设计立体窗口/读取CMOS信息)
- C语言/C++基础之是蛇你就贪起来
- Atitit.upnp SSDP 查找nas的原理与实现java php c#.net c++
- C++学习心得与c语言到c++衔接技巧
- 解答私信@被c++折磨头秃的花季美少女 //C++ 利用指针数组输入10个单词,编写函数对10个单词进行排序并输出,要求判断是否有相同的单词,如果有相同的单词在输出时该单词只输出一次。
- 解答私信@被c++折磨头秃的花季美少女 //C++ 编写一个进阶版的进制转换程序,运行功能如下:请选择要输入的数字的进制(2、8、10、16):请输入该数字:请选择要转换成的进制(2、8。。。
- OpenCV之识别自己的脸——C++源码放送
- C++11—lambda函数
- 【openvino】VS2019社区版c++开发报错error C4996: ‘wcstombs/mbstowcs‘: This function or variable may be unsafe
- 机器人C++库(7)Robotics Library 之场景模块 rl::sg