
基于Python(Django)+MongoDB实现的(Web)新闻采集和订阅系统【100010319】
本科生毕业论文(设计)
基于网络爬虫的新闻采集和订阅系统的设计与实现
[摘 要] 随着互联网的迅速发展,互联网大大提升了信息的产生和传播速度,网络上每天都会产生大量的内容,如何高效地从这些杂乱无章的内容中发现并采集所需的信息显得越来越重 要。网络中的新闻内容也一样,新闻分布在不同的网站上,而且存在重复的内容,我们往往只 关心其中的一部分新闻,网络中的新闻页面往往还充斥着大量许多与新闻不相关的信息,影响 了我们的阅读效率和阅读体验,如何更加方便及时并高效地获取我们所关心的新闻内容,本系 统能够帮我们做到这一点。本系统利用网络爬虫我们可以做到对网络上的新闻网站进行定时定 向的分析和采集,然后把采集到的数据进行去重,分类等操作后存入数据库,最后提供个性化 的新闻订阅服务。考虑了如何应对网站的反爬虫策略,避免被网站封锁爬虫。在具体实现上会 使用 Python 配合 scrapy 等框架来编写爬虫,采用特定的内容抽取算法来提取目标数据,最后使用 Django 加上 weui 来提供新闻订阅后台和新闻内容展示页,使用微信向用户推送信息。用户可以通过本系统订阅指定关键字,当爬虫系统爬取到了含有指定关键字的内容时会把新闻推 送给用户。
[关键词] 网络爬虫;新闻;个性化;订阅;Python
1. 引言
1.2 项目的背景和意义
如今我们所处的时代是一个信息时代,信息处处影响着人们的生活,无论是个人还是企业,都希望能够获取自己所关心的内容。人们获取信息的方式渐渐从传统的纸质阅读转移到了信息传播速度更快互联网的在线阅读上,而许多媒体和互联网企业都推出了各自的新闻门户来提供新闻内容阅读和检索等功能,但是这些新闻信息仍需要我们主动去访问这些网站才能获取到,而且我们还要在这些新闻中筛选出自己所关心的内容进行阅读,这样浪费了我们许多阅读之外的时间。网络中的新闻分布在不同的网站上,我们往往只关心其中的一部分新闻,网络中的新闻页面往往还充斥着大量许多与新闻不相关的信息,影响了我们的阅读效率和阅读体验,如何更加方便及时并高效地获取我们所关心的新闻内容,这是一个急需解决的问题,本系统就是为了解决这样的痛点而产生的。
1.3 研究开发现状分析
个性化新闻服务现状
如今国内外存在众多提供个性化新闻服务的互联网公司,如著名的 ZAKER 和今日头条,这些公司的产品都能够根据你的兴趣爱好来展示和推荐你喜欢的内容,这种创新性已经颠覆了传统的新闻资讯平台的市场格局,大众纷纷表现出对这些个性化新闻平台的追捧。据最新的《中国互联网络发展状况统计报告》显示, 截至 2016 年 12 月,中国网民规模达 7.31 亿,移动互联网用户规模达到 6.95 亿,其中新闻资讯领域行业用户规模达到 6.14 亿,年增长率为 8.8%,在移动端渗透率达到 82.2%。[1]新闻资讯信息的用户需求也更加细分,用户对内容的需求也更加精细,除了方便阅读、时效性高、趣味性强外,个性化推荐方式也 越来越受到用户的关注。在猎豹全球智库发布的安卓 2016 年 1 月新闻类 APP 排行榜
中,作为个性化新闻平台的今日头条、一点资讯皆排在移动资讯 APP 的前三位。而前三中采用传统编辑推荐方式的只有腾讯新闻,可见如今个性化新闻平台已经成为绝对的主流。
网络爬虫研究现状
网页抓取工具是一种根据特定规则来自动获取互联网信息的脚本或程序。[2] 网页或搜索引擎等网站通过爬虫软件来更新自己的网站内容或者是更新对其他网站的索引。一般来说,网络爬虫会保留被抓取的页面,然后用户可以通过搜索引擎后来生成的索引进行搜索。因为爬虫访问网页的方式与人类相似,而且一般比人类访问的速度要快,会消耗访问的网站的系统资源。因此爬虫在需要大量访问页面时,要考虑到规划和负载等情况,否则容易被网站禁封。 网站站长可以使用 robots.txt 文件来告诉爬虫访问的规则。robots.txt 文件是一个具有指定格式的文件,网站站长可以通过此文件来要求爬虫机器人不能访问某些目录或者只能访问某些目录。互联网上的页面极多,而且数量一直在增长,即使是像谷歌这样的爬虫系统也无法做出完整的索引,因此在某些地方会根据需求来做一些主题化的爬虫,这样的爬虫爬到的结果往往能够更加精确。
项目的范围和预期结果
本文描述了基于网络爬虫的新闻订阅系统的设计与实现的过程,主要工作如下:
- 编写一个网络爬虫,使其能够对网络中指定站点的新闻进行自动收集并存入数据库;
- 数据的去重和网络爬虫的反爬虫策略应对;
- 提供一个新闻展示页面,把爬取到的新闻展示给用户;
- 提供新闻订阅页面,用户可以在页面输入指定订阅的关键词;
- 编写微信推送服务,把用户订阅的新闻通过微信推送给用户;
1.4 论文结构简介
本论文的结构安排如下:
- 第一章,引言。主要介绍了论文选题项目的背景、意义和目的;以及对相关领域中已有的研究成果和国内外研究现状的简要评述;介绍本系统涉及的范围和预期结果等。
- 第二章,技术与原理。主要介绍本系统中所用到的主要技术和理论。
- 第三章,系统需求分析。使用用例析取和用例规约等系统分析方法对本系统进行了需求分析。
- 第四章,新闻采集与订阅系统的设计。介绍了系统的架构与原理,讲述本系统的各大模块的设计以及数据库的设计详情。
- 第五章,新闻采集与订阅系统的实现。介绍本系统具体的实现过程以及实现的效果。
- 第六章,系统部署。介绍本系统的部署环境与部署方法。
- 第七章,总结与展望。对本系统所做的工作进行总结,提出了需要讨论的问题和一些本系统中可以改进的地方。
2. 技术与原理
2.1 技术选型
Python 语言介绍
Python 是一种面向对象、解释型的计算机程序编程语言。它包含了一个功能强大并且完备的标准库,能够轻松完成很多常见的任务。它的语法比较简单,与其它大多数程序设计语言使用大括号把函数体包起来不一样,它通过缩进来定义语句块。[4]使用 Python 能够高效灵活地实现开发的任务,内置库以及大量的第三方库能够在许多地方避免重复造轮子的现象,有时使用 C++ 语言来实现的一个功能可能需要几十行,Python 只需要几行就足够了。与传统的脚本语言相比,Python 拥有更佳的可读性和可维护性。这门语言的强大吸引到了许多开发者,拥有比较热门的 Python 社区,许多开发者在维护着这种 Python 编写的库,影响力也在日益增强。在网络爬虫领域,Python 这门语言的使用也比较广泛,留下了大量的前人的学习研究的资料。基于以上优点,我选择了使用 Python 来开发本系统的网络爬虫部分和展示部分的服务端。
Scrapy 框架介绍
Scrapy 是一个纯 Python 基于 Twisted 实现的爬虫框架,用户只需要定制开发几个模块就可以方便地实现一个爬虫,用来抓取网页内容、图片、视频等。它最初是为了网站页面抓取所设计的,也可以应用在获取网络应用 API 所返回的各类数据或者是编写通用的网络爬虫。Scrapy 用途比较广泛,可以应用于数据挖掘、自动化测试和数据监控等场景。Scrapy 提供了一些网络爬虫中比较通用的中间件和模块等,也可以方便地编写自己所需的中间件来对爬取结果进行处理,只要在配置里面引用这些中间件就可以了。使用 Scrpay 来编写爬虫可以降低很多需要重复编写的爬虫处理代码所带来的成本。
Django 框架介绍
Django 是最早由 Python 实现的最着名的 Web 框架之一,最初是由美国芝加哥的 Python 用户组来开发的,拥有新闻行业背景的 Adrian Holovaty 是 Django 框架的主要开发人员之一。 在 Adrian 的领导下,Django 团队致力于为 Web 开发人员提供一个高效和完美的 Python 开发框架,并授权开发人员根据 BSD 开源协议许可证免费访问。 [5] Django 是一个高效的 Web 框架,可以帮助我们减少重复的代码,并把更多重点放在 Web 应用程序上的关键之处。在架构上,Django 跟 Scrapy 类似,也提供了中间件等,配置的方式也是类似的,使用类似的技术架构可以减少学习成本。本系统中我选用 Django 作为新闻订阅的服务端来提供 API。
MongoDB 数据库介绍
MongoDB 是一个由 C++ 语言编写的高性能,无模型的开源文档型数据库, 是当前 NoSQL 数据库产品中最具有代表性的一种。MongoDB 是使用文档来作为对象存储的,一条记录对应一个文档,集合类似传统的关系型数据库中的表, 集合中存放的是那些具有同一特征或者属性的文档。在一个集合中,不同文档拥有的属性可以是不同的,这就是与传统的关系型的数据库的重点了,传统的关系型数据库要求表里的数据所拥有的属性格式都是一致的,MongoDB 这种灵活性更利于文档映射到一个对象或一个实体上。对于需要经常改动数据格式或者数据格式不定的一些需求来讲,这种数据格式更为合适。MongoDB 在读写性能方面也远超传统的关系型数据库的代表之一的 MySQL。在本系统中我使用 MongoDB 来存储爬取到的数据以及用户数据等。像 MongoDB 这样的非关系型数据库更合适储存爬虫数据,因为爬虫数据量可能比较大,数据之间关系型也不强。MongoDB 的性能也比传统的关系型数据库代表 MySQL 之类要强。
AJAX 介绍
AJAX(异步的 JavaScript + XML)本身并不是一种技术, 它是由 Jesse James Garrett 在 2005 年提出的一个术语, 描述了一种需要结合使用大量已经存在的技术的方式, 包括 HTML, JavaScript, CSS, DOM, JSON, XML 等, 还有最重要 JavaScript 中的的 XMLHttpRequest 对象。当这些技术以 AJAX 模型的方式聚合时,Web 应用程序可以更迅速地,无需加载整个页面就能更新全部或者部分的用户界面。这使 Web 应用能够更快地响应用户行为,带来更友好的用户体验。尽管在 AJAX 中 X 代表 XML, 但现在 JSON 使用的更多,因为 JSON 具有许多 XML 不具备的优势,比如它更轻量并且是 JavaScript 的一部分,各个程序语言都能够轻松解析 JSON 格式的数据。在 AJAX 模型中,JSON 和 XML 的作用都是承载信息。[6]本系统会在新闻订阅和展示部分的前端使用 AJAX 来跟服务端进行交互,以达到前后端分离的目的。
2.2 相关原理介绍
网络爬虫介绍
网络爬虫(英语:Web crawler),也叫网络蜘蛛(spider),是一种自动提取网页的程序,它为搜索引擎从万维网上下载网页。传统的爬虫的启动从一个或多个初始网页开始的,从这些初始网页上获得接下来要爬取的 URL,在抓取网页内容的过程中,不断从当前页面的内容上抽取新的需要继续爬取 URL 放入队列,直到满足系统的一定停止条件。[7]网络爬虫的抓取策略大致可以分为以下三类:广度优先搜索策略、深度优先搜索策略、最佳优先搜索策略等。本系统的爬虫部分使用的爬虫策略是广度优先搜索策略,因为本系统的网络爬虫具有针对性,所以爬取的层数不会很多。
关键词提取技术
通过分析文本,利用关键词抽取技术可以抽取出文本的关键词,关键词能够简单地反映出文本的主要内容,使人们更加直观方便地了解到文本内容的主题。关键词提取的技术有许多种,最常用的应该是基于统计的方法的 TF-IDF 算法。TF-IDF(term frequency-inverse document frequency)是一种常用的用于数据挖掘与信息检索的加权技术。[8]词语的重要性是在 TF-IDF 算法中主要是由它在文中出现频率决定的。
Jieba 是一个基于 Python 的中文分词库,支持三种分词模式:精确模式、全模式和搜索引擎模式,它能够基于 Trie 树结构来实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图,采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合。在本系统中,将考虑使用 Jieba 分词基于 TF-IDF 算法的关键词抽取来抽取出爬取到的新闻内容的关键词。
智能推送技术
当我们使用如今的一些应用程序时,会经常收到来自这些应用的推送,过多的、不适当的推送会打扰到用户,互联网技术在最近几十年里已经得到了很大的发展,但是推送通知技术仍旧停留多年以前。为了实现智能化推送,我们需要搜集和分析能够帮助我们实现智能化推送通知的用户数据,这些数据的来源可以是用户的设置或者用户在应用中产生的数据等。在智能推送通知中,与时间相关的, 个性化的,有帮助的,有联系性的是智能推送通知中四个基本的特征。
在推送的时间上,我们可以做到时间智能化,时间智能化指的是推送的时间要恰当,推送发生在不恰当的时间比无用的垃圾推送消息造成的不良效果更验证。在不恰当的时候推送的通知不但打扰到用户,还很容易会被用户忽略。智能推送应该能够做到自动解决推送时间不恰当的问题。具体的实现可以通过一个对推送信息的重要性评估的引擎来决定消息推送的时间。
在个性化上,我们可以把推送机器人设计成人类的形态,比起传统的系统消息,拟人化的方式能够让人更加容易接受,如苹果的 Siri 和微软的 Cortana。当我们将来自机器智能的推送通知语言根据用户自己的特点进行调整后,用户在查看时看到的是更像交流式的风格,会感到更有亲切感,更加个人化。
在推送的内容上也要慎重选择,根据不同用户来推送不同的内容。因为对于用户来说,只有用户关心的内容才是对用户有帮助的。拿新闻订阅应用来讲,就是用户只会对某些主题内容的新闻感兴趣,应用要做的就是把新闻的主题进行分析,打上不同的标签。然后找到用户兴趣中含有这些标签用户进行推送。如果不经处理对全部用户进行统一的推送,用户需要花费大量时间在这上面去过滤出自己感兴趣的内容。
在推送内容的数量上也有讲究,如果一个服务高频次地的使用通知推送,用户可能会感觉到被冒犯然后会关掉它,后面的推送就都收不到了。因此,将推送的内容进行分组就很重要了。系统可以把一些相似的通知进行分组合并,可以减少对用户的打扰,在消息很多的时候这种优势就很明显了。在信息较少的时候可以选择把这些推送通知进行展开,因为此时用户可能会比较关心这些少见的内容,也是一个不错的选择。
3. 系统需求分析
3.1 新闻订阅系统用例析取
基于网络爬虫的新闻采集与订阅系统要实现新闻数据抓取,数据过滤,数据筛选,数据展示,新闻订阅,推送等服务和功能,本系统用例图如图 3.1 所示:

图 3.1 系统用例图
本系统主要用于以下几类人员:
-
数据管理员,完成数据的抓取,过滤与筛选,新闻的推送,以及本系统管理与维护等。
-
用户,在网页上进行新闻订阅,通过微信接收订阅新闻的推送,点击进入对应新闻展示页面等
3.2 新闻订阅系统用例规约
新闻订阅
-
简要说明
本用例允许用户增加或者删除自己订阅新闻的关键字,以及对已经订阅的关键字进行确认等操作。
-
参与者
用户。
-
事件流
基本事件流
用例开始于用户进入新闻订阅页面进行操作。
-
订阅新闻关键字的状态共有两种,分别为“已订阅”、“未订阅”。顾客可以在相应的状态下进行操作,选择增加关键字或者删除关键字。
-
如果关键字状态为“未订阅”,用户可以增加该关键字到自己的订阅列表中, 本用例结束。
-
如果关键字状态为“已订阅”,用户可以选择删除该关键字,本用例结束。
-
特殊要求无。
-
前置条件
本用例开始前用户必须是微信已登录状态。
-
后置条件
如果用例成功,用户的订阅列表将被更新。
-
活动图
-

新闻推送
-
简要说明
本用例允许数据管理员根据新闻的关键字向已经订阅该关键字的用户进行推送等操作。
-
参与者
数据管理员。
-
事件流
-
基本事件流
用例开始于爬虫系统采集到新闻时。
-
系统将新闻内容根据算法与用户订阅的新闻关键字作对比,对比结果分别为“匹配”、“不匹配”。
-
如果匹配状态为“匹配”,系统将调用微信推送接口向用户推送该新闻,本用例结束。
-
如果匹配状态为“不匹配”,用户将不会收到该新闻的推送,本用例结束。
-
特殊要求无。
-
前置条件
本用例开始前采集到的新闻必须有效。
-
后置条件
如果用例成功,用户将收到一条新闻推送。
-
活动图
-
-

图 3.3 新闻推送活动图
4. 新闻采集与订阅系统的设计
4.1 系统架构及原理
本新闻采集与订阅系统分别由爬虫部分与新闻订阅和展示部分构成,在新闻订阅与展示部分采用基于 C/S 的架构,代码的组织方式为 MVC 三层结构,其中的三个层次分别为视图层(View )、控制器层(Controller)和模型层(Model)。代码整体采取前后端分离的方式,前端负责视图层,后端负责模型层和控制器层,客户端使用微信和网页实现, 前后端通讯使用 AJAX 交换 JSON 的方式。系统的总体框架图如图 4.1 所示:

图 4.1 系统总体架构图
爬虫部分使用了 Python 编写 Scrapy 框架,它的基本架构如图 4.2 所示,其中 Scrapy 引擎的作用是控制数据的流向,是整个爬虫框架的核心。网络蜘蛛(spiders) 定义了如何爬取某个(或某些)网站,包括了爬取的动作以及如何从网页的内容中提取结构化数据。蜘蛛中间件(spider middleware)是在 Scrapy 引擎和网络蜘蛛间的一个钩子,它可以处理蜘蛛的输入与输出。调度器(scheduler)能够从 Scrapy 引擎接受请求并放入队列,在引擎请求调度器时返回对应的请求。下载器(downloader)负责下载网页,把爬取到的内容返回给 Scrapy 引擎和网络蜘蛛。下载器中间件(downloader middleware)是在 Scrapy 引擎和下载器间的一个钩子,它可以处理传入的请求跟传出的响应。Item Pipeline 负责处理网络蜘蛛传过来的 Item,可以在此做数据格式化,数据清理等操作。
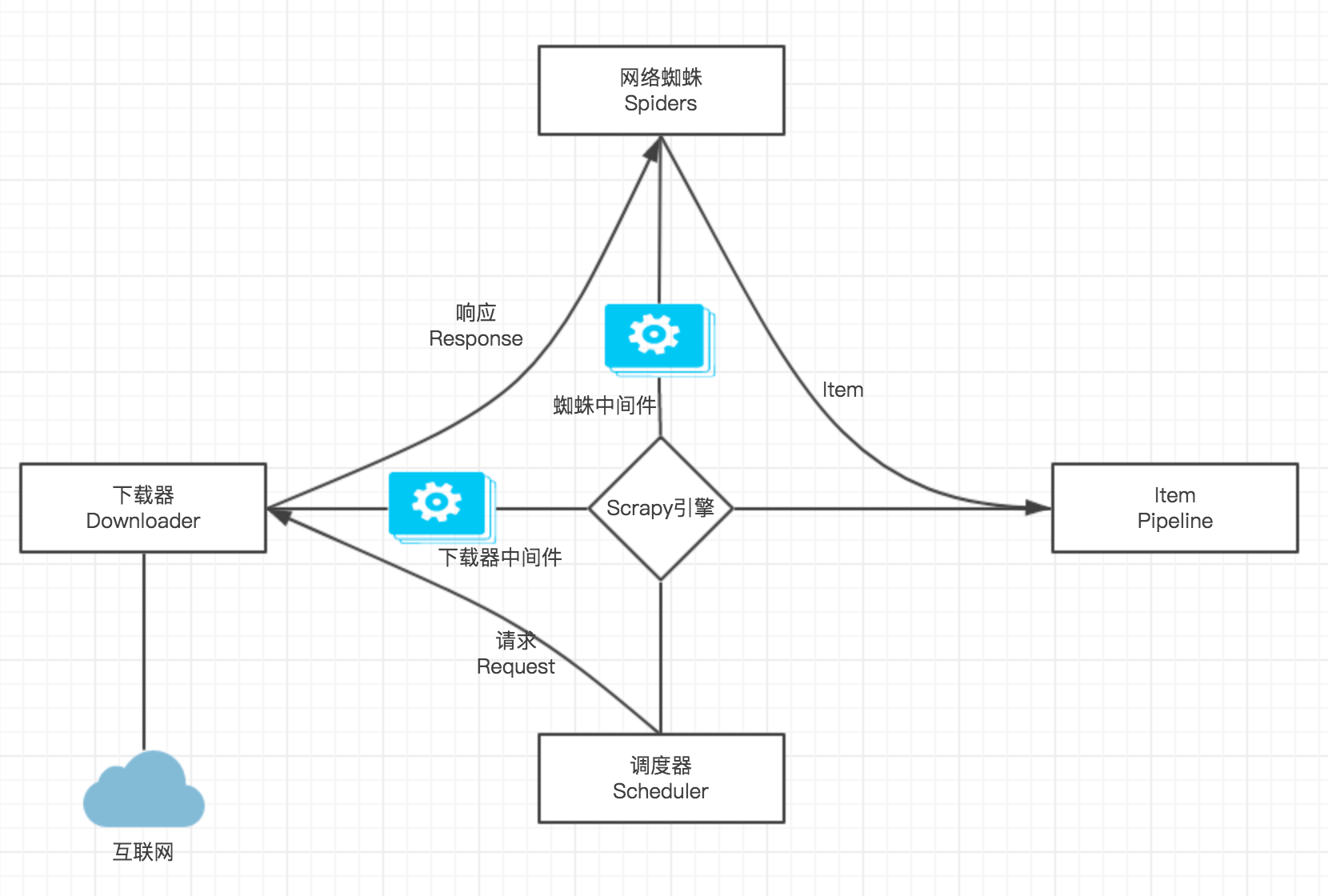
图 4.2 Scrapy 架构图
爬虫的整体上数据流向的开始是由 Scrapy 引擎让网络蜘蛛以一个初始的 URL 来初始化一个请求,并设置回调函数,然后网络蜘蛛把该请求向调度器申请任务,把申请到的任务交给下载器,这里会经过一次下载器中间件,然后下载器把下载完后产生的响应再经过一次下载器中间件,然后传递给引擎,引擎接收到该响应后通过蜘蛛中间件传给网络蜘蛛处理,网络蜘蛛处理该响应,产生一个 item 或者是新的请求给引擎,引擎会把传过来的 item 放入 Item Pipeline,把传过来的新的请求传给调度器,Item Pipeline 获取接收到的 item 对该 item 进行逐层处理,接着这个流程就重复直到爬取完成。
4.2 系统模块设计
爬虫采集模块设计
使用 Scrapy 框架来编写爬虫首先要编写核心的蜘蛛(spiders)的代码,Spider 类定义了如何爬取某个(或某些)网站,包括了爬取的动作以及如何从网页的内容中提取结构化数据。本系统主要针对网易新闻和腾讯新闻的科技频道进行主题式的爬虫,所以设计了两个网络蜘蛛,名字分别为 NeteaseSpider 和 QQSpider,如果后续需要更多需要爬虫的站点,只要增加对应站点的网络蜘蛛就可以了,其余处理部分都是通用的。在这里选择主题式的爬虫的原因主要是一个通用爬虫对于新闻这样的每个站点的文章有固定格式的爬取解析的代价比较大,还不如手工去对需要爬取的站点进行分析,根据每个站点的特点来编写解析的代码。这样的主题式的爬虫能够提高爬虫的精确度,同时也提高了爬虫的效率,这样我们的爬虫就能够及时爬取到最新的新闻内容了。每个站点对应一个特定的网络蜘蛛还有一个好处就是如果后续需要完成分布式爬虫等需求时会很方便,因为这样的方式代码之间的耦合度较小,同时非常简洁。
网络蜘蛛首先从一个 start_url 开始爬取,这里我选取了网易新闻和腾讯新闻的科技频道的首页,蜘蛛爬取这个起始 URL 上的页面后,对里面的内容进行解析。因为每篇新闻的 URL 都具有一定的格式,凡是该页面上有符合这种格式的 URL,蜘蛛都会对这些 URL 进行回调,继续爬取这些 URL 的页面,这些页面上就会包含所要获取的新闻的内容了。对于同一个新闻站点来说,一般页面上的内容的结构也是一样的,所以按照一定的规则来对这些页面上的内容进行解析,获得新闻内容原始数据,对这些数据进行格式化的处理,封装成一个 item,传回给 Scrapy 引擎处理。
因为新闻具有一定时效性,一般来说我们只会关注那些新产生的新闻内容, 所以本爬虫不需要考虑需要爬取过往产生的新闻的情况。本系统的爬虫部分只聚焦于每个站点的首页的新闻,因为新闻是滚动刷新的,所以我们需要定时对首页进行爬取,获取新的新闻内容。本系统设计了一个类似守护程序,来控制爬虫的启动与停止,在爬虫结束后等待一段时间再重新开始爬取。
爬虫去重模块设计
在爬虫过程中会遇到重复内容的情况,所以我们需要设计一个爬虫用到的去重的模块。考虑到每个 URL 对应的新闻内容是不变的,我们只要针对 URL 来进行去重即可,而不需要等到把内容取回来之后再判断内容是否已经爬取过,那样会消耗大量额外的资源,也对目标网站造成了额外的压力,显得不友好。我们选择去重的时机是 Scrapy 的调度器把请求分配给下载器之前,也就是说在下载器中间件中处理,在本系统中定义了一个下载器中间件 RedisMiddleware,这个中间件的作用是在 Redis 的一个散列中判断是否存在该 URL,如果不存在,把该请求传给下一个中间件处理。如果该 URL 存在于散列中,则忽视掉该请求,不进行后续操作。在本系统中定义了一个 Item 管道 RedisPipeline,在爬取数据完成后,数据库处理完后 Item 会传到该管道,该管道的作用是把这个新闻所属 URL 存入 Redis 的散列中,标记该 URL 已经爬取。
防反爬虫模块设计
防反爬虫是在大多数爬虫中需要考虑的情况,因为爬虫对网站服务器造成的压力比正常人要多,如果爬取频率足够高的话,会使网站访问变慢,甚至无法访问,所以网站可能会有一系列的反爬虫措施。首先我们的爬虫需要遵守网站的爬虫协议,然后把爬取速率控制好,例如间隔一秒才爬取一个页面。其次,我们需要伪装成一个浏览器,有些网站会通过 HTTP 请求头中的 User-Agent 中的信息来判断用户,我们不但需要在爬虫请求中的 HTTP 设置 User-Agent 请求头,还需要对该请求头进行更换,因此在本系统中定义了一个下载器中间件 RotateUserAgentMiddleware,这个中间件的作用是在请求前在请求的 HTTP 请求头中设置一个轮换的随机的模拟用户浏览器的 User-Agent 请求头,这些 User-Agent 与真实浏览器的 User-Agent 一致,数据来源是 Python 中一个叫 fake-useragent 的库。后续如果对方服务器针对 IP 进行禁封了的话可以采用代理服务器的方式来应对,在做了以上措施的情况下本系统目前没有出现过被禁封的情况,因此该方法没有在本系统中实现。
爬虫存储模块设计
爬虫的数据存储是一个爬虫系统中很重要的一部分,因为爬虫的目的就是获得数据,在这里我们需要考虑数据的存储方式与储存时机。在本系统中储存部分使用了 ORM(对象关系映射)的方式来实现,ORM 的好处在于把数据访问的细节隐藏起来,在 ORM 上的操作出错的可能性会比手写数据库操作的可能性低。在 ORM 中,我们只需要关注数据的结构,这样一来,我们只需要编写数据储存对象的参数定义等属性跟方法就可以了,初始化、查询、更新等操作都可以由 ORM 来实现。在本系统中,爬虫部分与订阅和展示部分都共用一个数据库,爬虫部分需要对数据库进行写操作,展示部分需要对数据库进行读操作。在蜘蛛解析完数据后,蜘蛛会把封装好的 Item 通过 Scrapy 引擎传给 Item 管道,系统定义了一个 MongoDBPipeline,这个管道的作用是维持一个 MongoDB 的数据库链接,接收到传入的 Item 后先校验完数据的完整性,然后把合法的数据插入数据库对应的集合中,否则丢弃该 Item。
消息推送模块设计
消息推送部分本系统使用微信来实现,需要用户关注指定公众号。本系统需要推送消息给用户时,先选择一个本系统预定义的模板,在模板中填入消息标题, 内容和链接等数据后,通过微信提供的接口来进行推送。这里需要注意的是我们需要给推送的消息接口提供一个本系统所用的公众号的 AccessToken,这个 AccessToken 是向微信证明本系统的凭证,它有一定的有效期,需要定时刷新。
消息订阅与展示模块设计
消息订阅与展示模块是本系统中与用户交互的模块,这个模块负责用户订阅新闻的功能与向用户展示所需新闻内容的模块。在本系统蜘蛛解析完数据后,蜘蛛会把封装好的 Item 传给 MongoDBPipeline 储存后,会继续往下传递,传递到一个 PushPipeline 中,这个管道的作用是判断爬取到的数据是否包含用户所订阅的关键词,如果包含的话则调用消息推送模块把新闻消息推送给用户。在消息推送后,用户会在微信端本系统的公众号中接收到一条包含新闻消息简要内容的消息,点击该消息可以跳转到新闻展示页面。本系统提供了一个消息订阅页面,用户可以在该页面上管理自己的新闻关键词。
4.3 数据库设计
本系统存放数据用到的数据库分别是 Redis 和 MongoDB,在本系统的数据库设计中,数据库的集合主要包括爬取到的新闻信息集合和用户订阅新闻关键词集合,系统的配置信息都写在配置文件中,就不需要使用数据库来存放了。这里选择 MongoDB 的原因是考虑到当爬虫的数据量和并发数很大时,关系型数据库的容量与读写能力会是瓶颈,另一方面,爬虫需要保存的内容之间一般不会存在关系。另外本系统会使用 Redis 中的散列类型来存放已经爬取过的 URL 和不合法的 URL,因为判断 URL 是否合法或者是否已经爬取过是一个高频的操作,使用 Redis 这样的高性能的内存键值对类型的数据库可以减少主数据库的压力,同时提高爬虫的性能。
表 4.1 新闻信息集合
| 属性名 | 含义 | 类型 | 说明 |
|---|---|---|---|
| title | 新闻标题 | string | |
| content | 正文内容 | string | 纯文本 |
| source | 来源 | string | 新闻出处 |
| published | 发布时间 | timestamp | 精确到秒 |
| url | 原文链接 | string | 用于跳转 |
表 4.2 用户订阅新闻关键词集合
| 属性名 | 含义 | 类型 | 说明 |
|---|---|---|---|
| open_id | 用户微信 openid | string | 唯一标识 |
| keywords | 订阅的关键词列表 | array | 字符串类型的数组 |
| tags | 订阅的标签列表 | array | 字符串类型的数组 |
5. 新闻采集与订阅系统的实现
5.1 系统框架实现
本新闻采集与订阅系统的爬虫部分框架是利用 Scrapy 自带的命令行工具来初始化,初始化后已经创建好了 Scrapy 引擎所需的几个重要的文件,如中间件, 数据管道,配置文件等,这样做的好处是能够快速搭建起框架,并且能够达到官方定义的最佳实践。接下来我们可以在这个目录下定义自己的一些模块文件,再在这些文件中实现自己的处理函数就可以了,最终实现的爬虫部分的目录结构如图 5.1 所示,其中 items.py 是用于定义数据储存模型的文件,middlewares.py 是用于定义中间件的文件,pipelines.py 是用于定义数据管道的文件,settings.py 是本系统爬虫部分的配置内容,spiders 文件夹中存放了不同爬虫的网络蜘蛛代码, utils.py 则是一些通用的函数存放的地方,wechat_config.py 和 wechat_push.py 分别是微信推送部分的配置和推送代码。
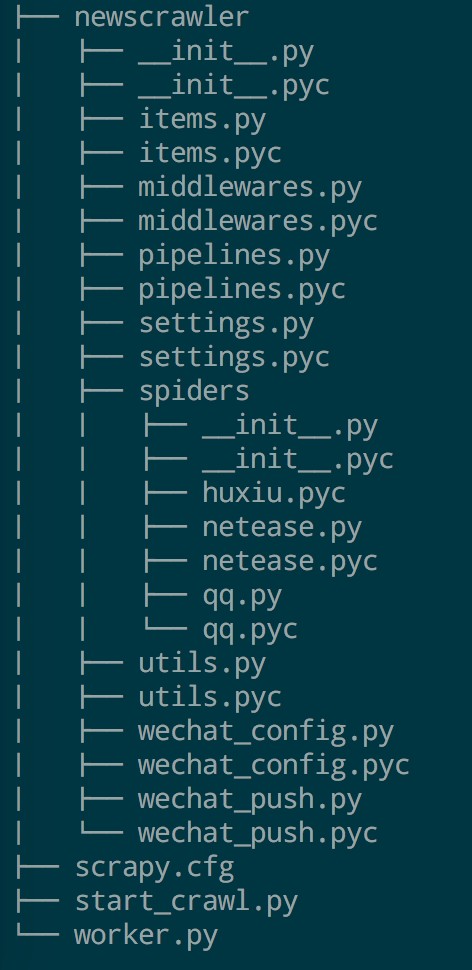
图 5.1 爬虫部分目录结构
新闻订阅和展示部分的 API 服务器端则使用 Django 自带的命令行工具来初始化,使用 django-admin startproject 命令来新建一个项目,然后使用 django-admin startapp 命令来新建一个 app,这样 API 服务器的基本框架就完成了,然后往创建的目录中添加其余代码,最终实现的新闻订阅与展示部分的目录结构如图 5.2 所示,其中 frontend 文件夹存放的是本系统的前端静态文件,分别是新闻订阅页面和新闻展示页面,init_db.py 文件是一个用于初始化数据库用的脚本,lib 文件夹中存放的是本系统中一些能够被公用的函数文件。manage.py 是由 Django 生成的用于管理任务的命令行工具脚本, news_web 存放的是本项目的代码, run_server.sh 是一个用于启动服务器的脚本文件,web_server 中存放的是本系统新闻订阅与展示部分的服务端代码的主要文件,主要包括了用于配置路由 urls.py,存放新闻和订阅信息数据模型 models.py 和提供 API 的 views.py。
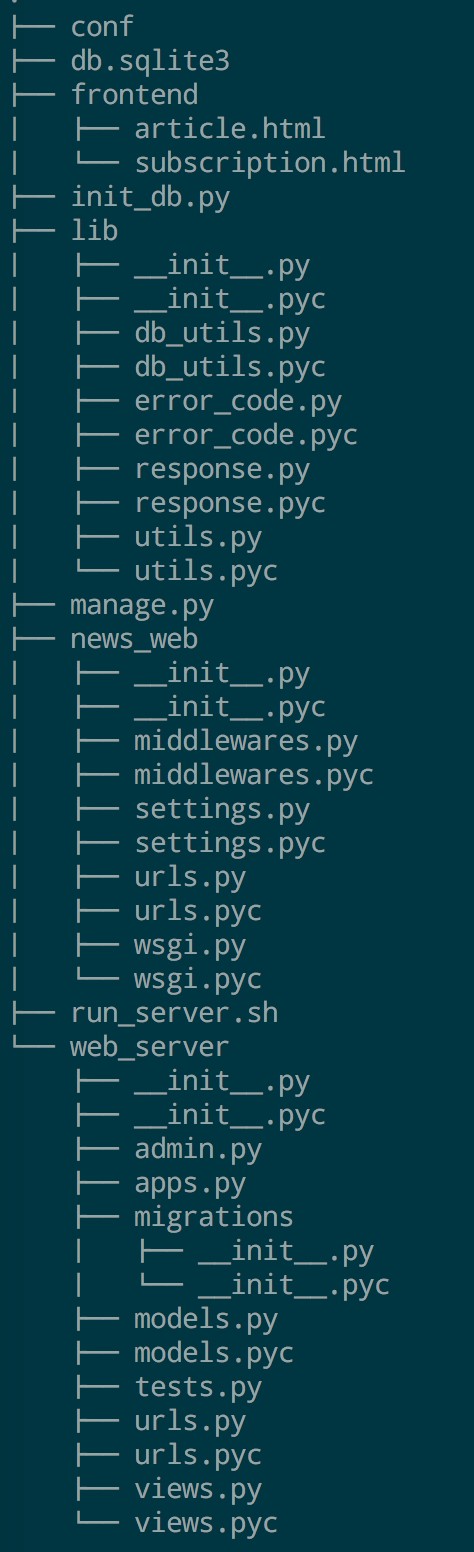
图 5.2 新闻订阅与展示部分的目录结构
5.2 爬虫采集模块实现
爬虫采集模块的核心的网络蜘蛛,下面以爬取网易科技频道新闻的蜘蛛为例讲解本系统爬虫采集模块的实现过程。图 5.3 为该蜘蛛的解析网页请求响应的代码,首选我通过分析网易科技频道新闻中的网页源码,分析得到网页中所需的新闻内容的数据所在的位置特征信息,例如通过分析发现标题位置是处于 HTML 标签下的 head 标签里的 title 标签里的文本。24-27 行中的代码的作用是通过 xpath 使用之前分析出来的格式来从抓取到的数据中提取出新闻相关的信息,包括新闻标题、新闻消息来源、新闻内容、新闻发布时间。29-32 行的代码作用是把时间解析为时间戳,这样做的目的是为了方便把时间转换成不同的表现格式,时间表现会更为准确。34-40 行的代码作用则是把数据封装成一个本系统中的新闻 Item, 然后传给 Item 管道来处理。另外一个用于爬取腾讯新闻科技频道蜘蛛的分析方法和代码写法是类似的,在这就不详细介绍了。
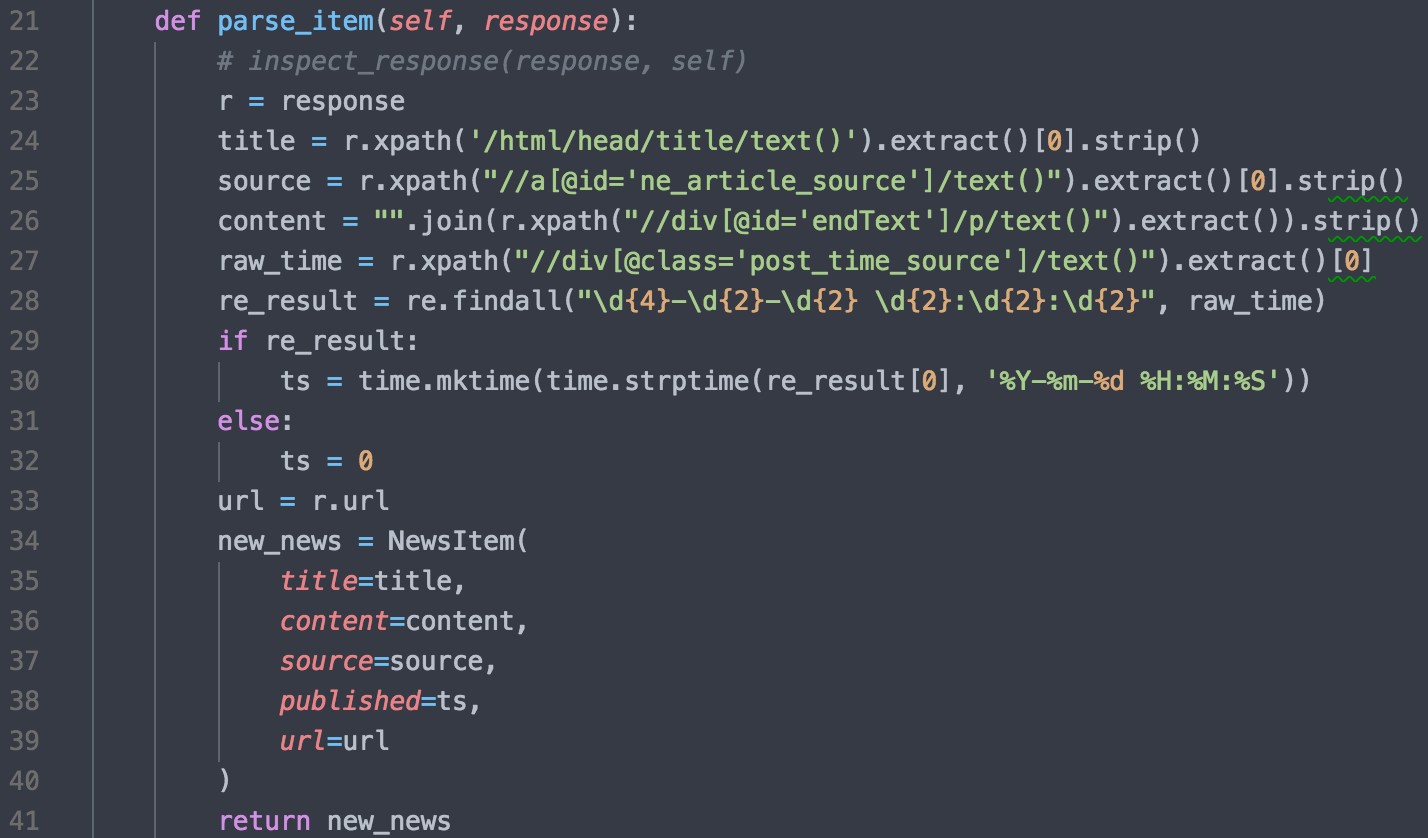
图 5.3 蜘蛛解析网页请求响应的代码
为了实现定时爬虫的功能,在本系统中实现了一个名为 worker.py 的守护进程脚本和一个 start_crawl.py 的用于调用爬虫的脚本,运行 worker.py 脚本后会每三十秒调用启动一次 start_crawl.py,start_crawl.py 每次启动会调用爬虫主程序, 程序核心代码如下:
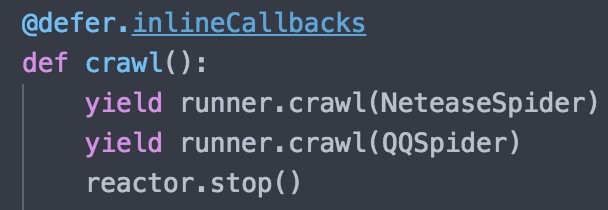
图 5.4 守护进程核心代码
5.3 防反爬虫模块实现
为了防止反爬虫对本系统爬虫部分的影响,对于每次请求,本系统都会伪装成一个真实的用户,防止被爬取的网站通过 User-Agent 等信息来判断或者禁封掉本系统的爬虫,导致后续爬虫无法正常进行。本系统在发送请求之前会在请求的头部加上 User-Agent 的请求头信息,这个请求头的信息会在本系统配置中的 User-Agent 列表中随机选取一个,图 5.5 为部分 User-Agent 信息。除此之外,还可以利用代理服务器来代理请求,防止被爬取的网站通过 IP 信息来禁封本系统爬虫。

图 5.5 部分 User-Agent 列表
5.4 爬虫存储模块实现
爬虫储存模块的数据设计与格式等在上一章已经说明,在这介绍在数据库中的具体实现。爬虫爬取到的新闻数据会存放于 MongoDB 中,使用 ORM 来映射数据对象模型到数据库,使用的 ORM 框架是 MongoEngine,下面通过讲解一个新闻内容的数据模型的定义来说明这种定义方式,在图 5.6 中的第 9 行,我们定义了一个父类为 MongoEngine 的 Document 类的类,这样定义就使这个类拥有了关系对象映射的能力,再在这个类中定义一个 to_json 的方法,作用是把本类的实例转化为一个 Dict 类型的数据,方便 API 调用时将对象转换成 JSON 格式的数据返回给前端。图 5.7 展示了部分爬取到的新闻数据的内容。
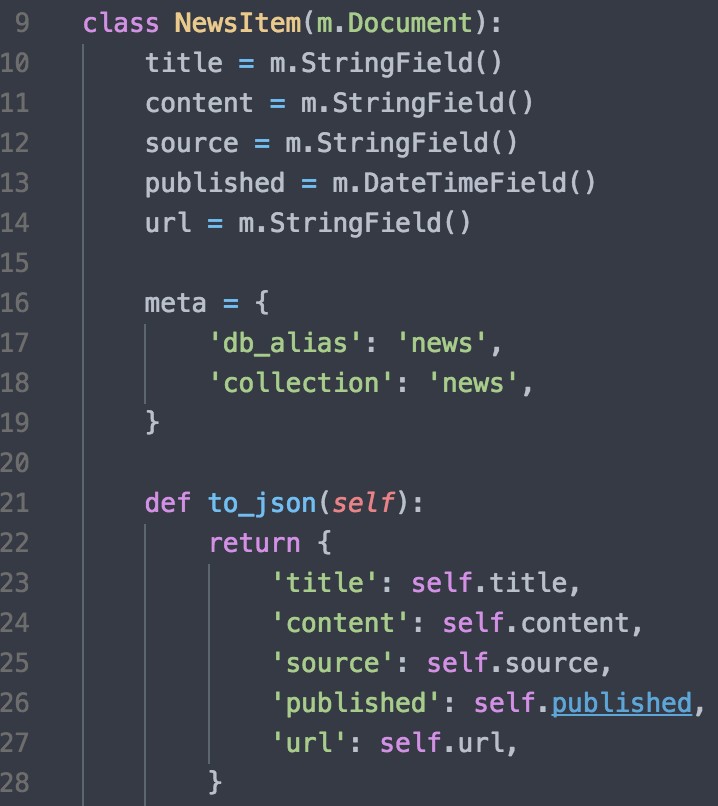
图 5.6 新闻数据库 ORM 模型
图 5.7 部分爬取到的新闻数据的内容
5.5 消息推送模块实现
消息推送模块使用了微信公众号的推送,在本系统中使用微信的接口测试号来代替公众号,微信的接口测试号是一种用于测试的,可以使用微信号扫一扫登录的账号,而且这种账号能够直接体验和测试公众平台所有高级接口。在申请完后登录系统,获得该系统的 appID 和 appsecret,这两个字符串是使用该账号的凭据。需要注意的是,用户需要关注本账号后才能够收到本账号推送的消息。

图 5.8 测试号管理
接下来我们在网页下方新增一个消息模板,填入推送新闻消息的模板内容, 填写完成后记录对应的模板 ID。

图 5.9 测试模板消息
获得以上信息后把信息写入消息推送模块的配置文件中,供消息推送模块调用。下面讲解消息推送模块核心部分的实现,核心部分如图 5.10 所示,是一个名为 send_msg 的函数,这个函数接收四个参数,分别为新闻标题、新闻内容、新闻的 ID 和订阅者的 openid。订阅者的 openid 是用户微信的唯一标识,在测试号的页面可以查看已关注该账号的用户微信的 openid。该函数的 29-42 行的作用是把数据封装成微信推送接口所需的格式,然后在 45 行使用 requests 模块来 POST 一个请求到微信推送接口,微信推送接口收到请求后会在公众号中把该消息推送给用户。该函数使用了一个自定义的装饰器 update_token 来装饰,之前存放的 appID 和 appsecret 可以用来生成推送用的 access token,而这个 access token 有固定的存活期限的,这个装饰器的作用就是定时去获取这个 access token 并存放,直到过期之后再重新获取。
爬虫模块爬取到含有用户订阅的关键词的新闻时会向该用户推送这则新闻, 图 5.11 是用户在微信公众号上收到的该新闻的推送消息示例。

图 5.10 推送消息函数

图 5.11 用户收到的推送消息
5.6 消息订阅与展示模块实现
消息订阅与展示模块主要由前端静态文件部分和后端 API 部分组成。在开发方式上本系统选择了使用前后端分离的方式,前端通过 AJAX 的方式来跟后端提供的 API 进行交互,后端 API 服务器收到请求后返回对应的 JSON 格式的数据给前端,前端根据数据来渲染出最终展示给用户的页面,这种前后端分离的方式有效地降低了代码之间的耦合度。在前端实现方面,使用了 jQuery 来对 DOM 元素进行操作以及进行异步请求等,另外使用了 WeUI 的样式库,WeUI 是一套提供了同微信原生一致的视觉体验的基础样式库,由微信官方设计团队为微信内网页和微信小程序量身设计,令用户的使用感知更加统一。
接下来以用户端的角度来展示消息订阅与展示模块的实现。
用户想要收到新闻推送,需要先关注本系统的公众号,然后打开新闻订阅页面:

图 5.12 新闻订阅界面
这时可以输入要订阅的关键词,这里填 IT,点击添加订阅关键词,系统提示添加关键词 IT 成功,刷新已订阅关键词列表:
图 5.13 新闻订阅界面-添加关键词
点击已订阅关键词列表中的项会弹出对话框询问是否删除该关键词:
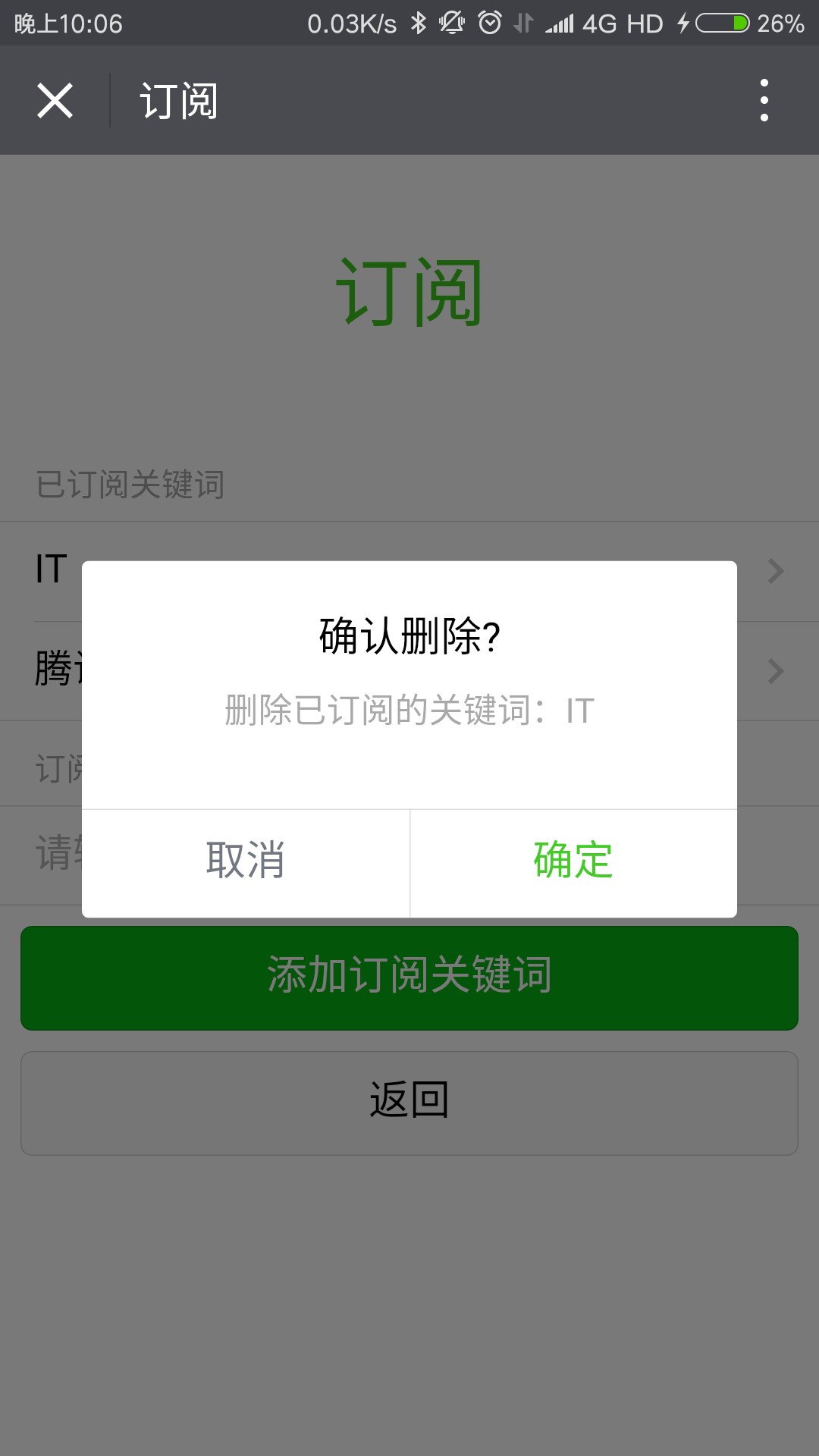
图 5.14 新闻订阅界面-提示删除关键词
点击确定,提示操作成功,同时刷新已订阅关键词列表:
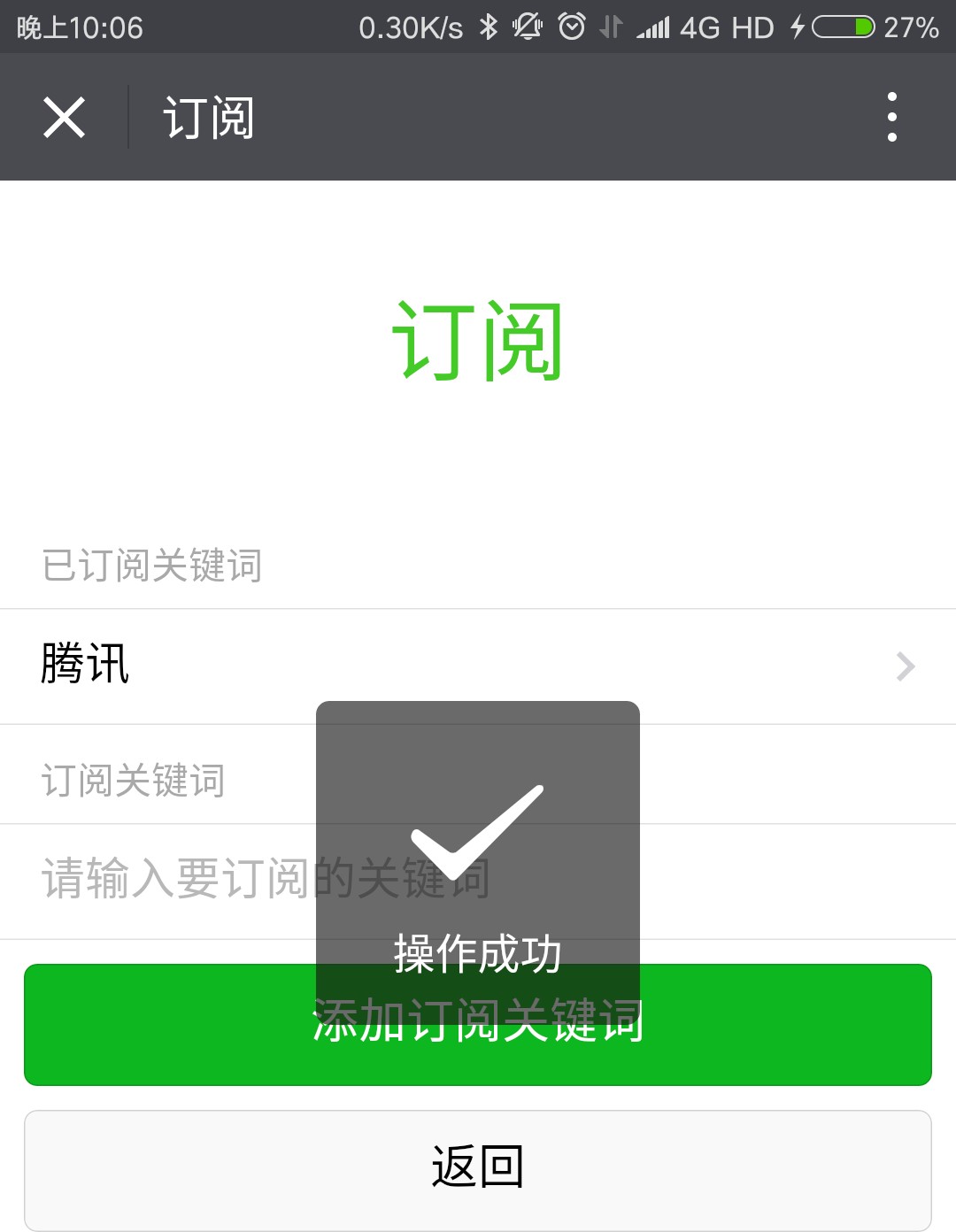
图 5.14 新闻订阅界面-删除关键词成功
在订阅关键词后,系统爬虫爬取到相关内容时会把内容通过微信推送给用户,用户点击后可以看到新闻内容,在此页面可以点击查看原文按钮打开原新闻页面,还有可以点击订阅更多前往订阅新闻关键词的页面:


图 5.15 新闻内容界面 1 图 5.16 新闻内容界面 2

点击查看原文,会跳转到新闻的原页面:
图 5.17 新闻原页面
第六章 系统部署
6. 部署机器概述
为了运行本新闻采集与订阅系统,至少需要一台拥有公网 IP 的 Linux 服务器, 这是为了用户在外网能够访问到。至于配置方面则不需要太高,在测试时我选用了一台腾讯云上的服务器,这台服务器的配置如下:
表 6.1 服务器配置
| 项目 | 内容 |
|---|---|
| 操作系统 | Ubuntu Server 14.04.1 LTS 64 位 |
| CPU | 1 核 |
| 内存 | 1GB |
| 系统盘 | 20GB |
| 公网带宽 | 1Mbps |
6.2 配置环境
- 安装 Nginx 作为反向代理服务器,并编辑 Nginx 相关配置文件,这样做是为了把不同的请求分发到后端不同的地方,例如请求前端文件就返回静态文件, 请求 API 就把请求转发给 API 服务器,Ningx 的配置文件部分内容如图 6.1 所示。这样就实现前后端分离而又不受到跨域请求限制的影响了。编辑完 Nginx 配置文件后,重启 Nginx 服务器。
- 安装 PIP,PIP 是 Python 用于管理第三方库的一个软件,这里用于安装本系统所需的第三方库。
- 使用 PIP 安装本系统所依赖的第三方库,包括 pymongo, scrapy, redis, fake-useragent, django, mongoengine, jieba, lxml, gevent, gunicorn 等。

图 6.1 Nginx 配置
6.3 系统运行
由于本新闻采集与订阅系统是由爬虫部分与展示部分组成,所以需要分别运行爬虫的守护进程和后端 API 服务器,静态页面是由 Nginx 指定的一个目录来提供的,不需要后台服务器。
使用 python worker.py 命令来运行爬虫的守护进程,得到以下输出:
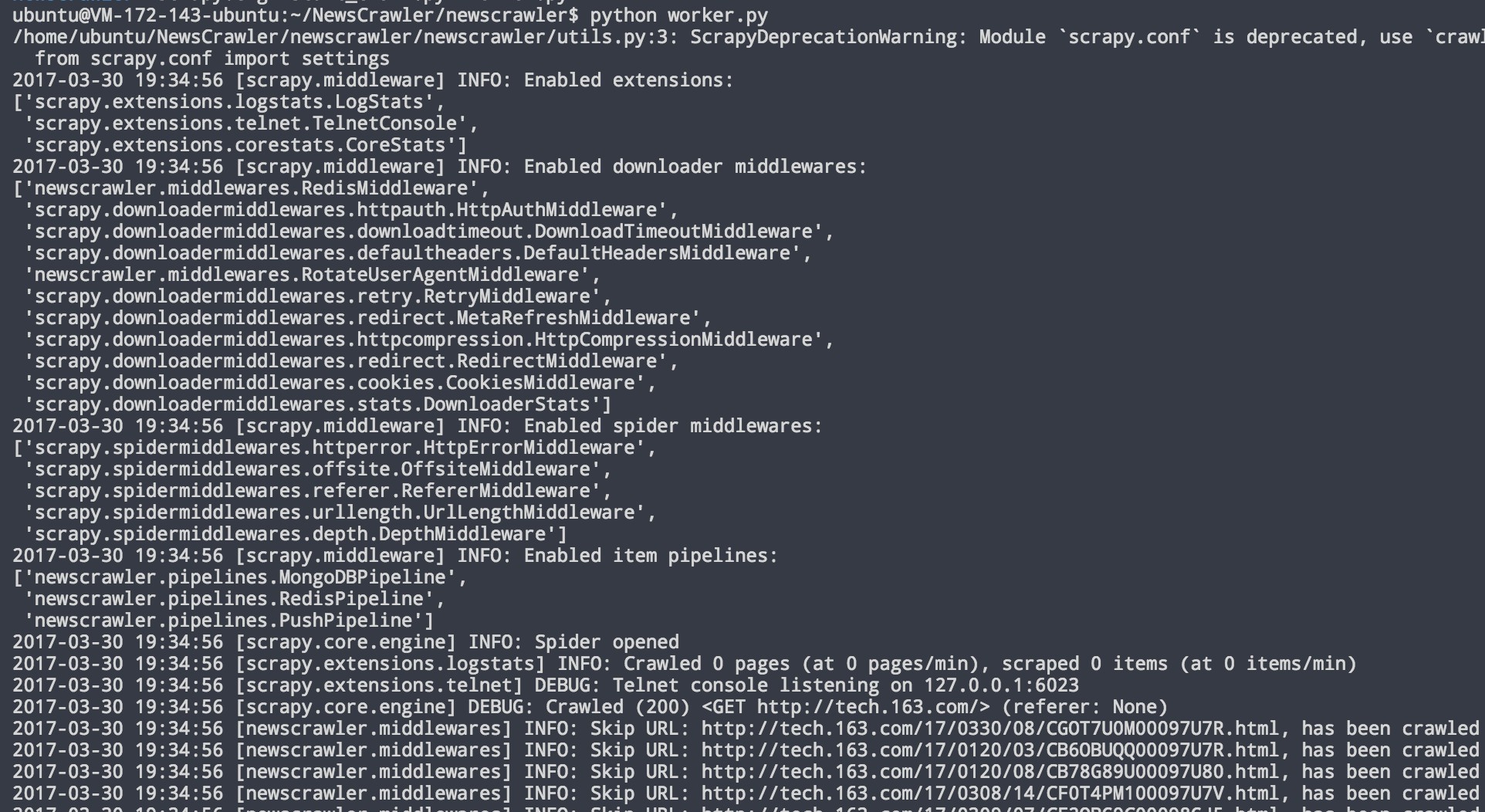
图 6.2 爬虫守护进程运行
使用 sh run_server.sh 命令来运行后端 API 服务器,这个脚本的实际作用是使用 gevent 作为 gunicorn 的 worker 来运行了四个后端 API 服务器进程,成功运行会得到以下输出:
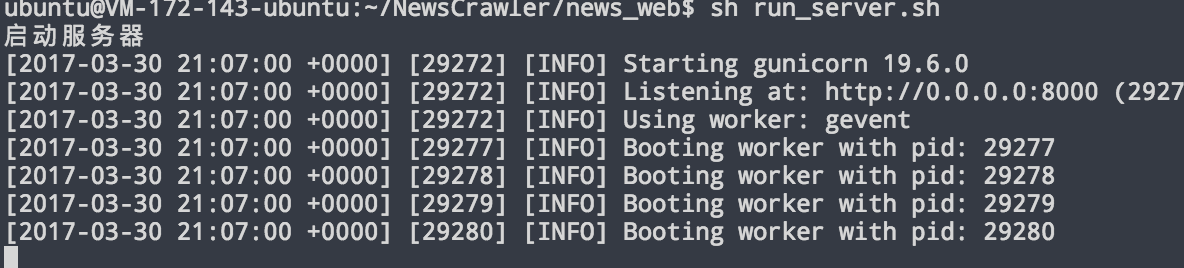
图 6.3 后端 API 服务器启动
7. 总结与展望
7.1 总结
本系统是一个基于网络爬虫实现的新闻采集与订阅系统,实现了对网络上新闻内容的自动化采集、用户新闻关键词订阅、新闻内容展示以及新闻推送等功能。为实现本系统的功能,查阅了大量学习资料,在实现方面使用了一些比较前沿的技术以及较多的第三方库,从中能够学习到很多新知识和新技能。在本文中较为完整地从系统的需求分析、不同模块的设计与实现几个方面来展示了一个完整的爬虫系统以及对应的新闻订阅 API 服务器等的实现过程,最后在云服务器上部署本系统并测试,达到了预期的效果。
7.2 展望
本新闻采集与订阅系统在设计上考虑了许多来降低代码之间的耦合度,同时提高代码的健壮性与性能,使本系统能够达到容易扩展以及高可用的需求,即便后续需要爬取另外一个新的新闻网站上的新闻,只需要编写对应网站的解析部分就可以了,大部分代码已经被模块化,能够被重用。对比了已有的类似的成熟大型新闻服务系统,发现还有以下能够改进的地方:
- 本系统只对新闻的基本文字信息等进行了采集与展示,后续可以考虑实现对新闻中图片与视频等多媒体信息的采集。
- 本系统缺乏一个较为完善的用户模块,目前用户是在配置文件中配置的, 用户模块对于这类的订阅系统是比较重要的。
- 订阅机制不够智能,也没有智能推荐等功能,后期可以采用机器学习等人工智能方法来实现智能化推送与推荐功能。
除了以上几点,本系统仍然存在许多能够改进的地方,但由于本文作者水平有限以及时间限制,未能够将这些一一实现,还希望各位专家学者能够给予批评与建议。
♻️ 资源

大小: 7.04MB
➡️ 资源下载:https://download.csdn.net/download/s1t16/87359325
相关文章
- Python中转换角度为弧度的radians()方法
- python-django框架-电商项目-项目部署_20191127
- python-django-fastdfs+Nginx的安装和配置_20191122
- python基于django编写api+前端后端分离
- Python - Python2与Python3合理共存Windows平台
- coroutine in Python Tornado and NodeJs
- python django ansible自动化运维管理平台源码收藏
- Python Django列表渲染for的使用
- Python Django URL逆向解析(通过模板页面逆向访问)代码示例
- Python Django创建项目命令
- Python语言学习之打印输出那些事:python输出图表和各种吊炸天的字符串或图画、版权声明(如README.md)等之详细攻略
- Python语言编程学习:利用python输出当前python版本、MSC版本型号
- Python编程语言学习:python编程语言中重要函数讲解之map函数等简介、使用方法之详细攻略
- 已解决2.Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and wi
- 已解决2. Set PROTOCOL_BUPFERS_PYTHON_iMPLEMENTATION=python (but this will use pure-Python parsing and w
- 高清无码的MP4如何采集?python带你保存~
- Python实战 | 如何抓取tx短片弹幕并作词云图分析
- 通过python基于netconf协议获取网络中网元的配置数据,助力企业网络控制自动化轻松实现!
- 【Python成长之路】python 基础篇 -- 装饰器【华为云分享】
- Python Django框架学习03:Django 安装
- python编程:Django常用的模板语言标签
- Python+Django+SAE系列教程15-----输出非HTML内容(图片/PDF)
- 【Leetcode刷题Python】206.反转链表
- 〖Python语法进阶篇⑩〗- 正则表达式的字符匹配
- 学习C++:C++进阶(六)如何在C++代码中调用python类,实例化python中类的对象,如何将conda中的深度学习环境导入C++项目中
- Python常用内置函数(python 3.x)