
《树莓派开发实战(第2版)》——2.2 创建模型和运行推理:重回Hello World
本节书摘来异步社区《概率编程实战》一书中的第2章,第2.2节,作者:【美】Avi Pfeffer(艾维·费弗),更多章节内容可以访问云栖社区“异步社区”公众号查看。
2.2 创建模型和运行推理:重回Hello World您已经概要了解了Figaro概念,接下来看看它们是如何融合在一起的。您将回顾第1章的Hello World示例,特别注意图2-2中的所有概念是如何出现在这个例子中的。您将关注如何从原子和复合元素中构建模型,观测证据,提出查询,运行推理算法,得到答案。
本章的代码可以两种方式运行。一种是使用Scala控制台,逐行输入语句并获得即时响应。为此,进入本书项目根目录PracticalProbProg/examples并输入sbt console,将会看到Scala提示符。然后输入每行代码,查看响应。
第二种方式是通常的方法:编写一个包含main方法的程序,该方法包含想要执行的代码。在本章中,我不提供将代码转换为可运行程序的模板,只提供与Figaro相关的代码。我将确保指出您需要导入的内容及将其导入的位置。
2.2.1 构建第一个模型首先,您将构建最简单的Figaro模型。这个模型包含一个原子元素。构建模型之前,必须导入必要的Figaro结构:
import com.cra.figaro.language._``` 上述语句导入com.cra.figaro.language包中的所有类,该包包含最基本的Figaro结构。这些类中有一个称为Flip。可以用Flip构建一个简单模型:
val sunnyToday = Flip(0.2)`
图2-3解释了这一行代码。搞清楚哪一部分是Scala,哪一部分是Figaro,是很重要的。在这行代码中,创建了一个名为sunnyToday的变量,并赋值Flip(0.2)。Scala值Flip(0.2)是一个Figaro元素,表示true值概率为0.2、false值概率为0.8的一个随机过程。元素是表示随机产生一个值的过程的数据结构。随机过程可能产生任意数量的结果。每个可能结果被称为过程的一个值。因此,Flip(0.2)是可能取值为布尔值true及false的元素。总结起来就是,您有了一个包含Scala值的Scala变量。该Scala值是Figaro元素,它包含表示过程不同结果的任意个可能取值。
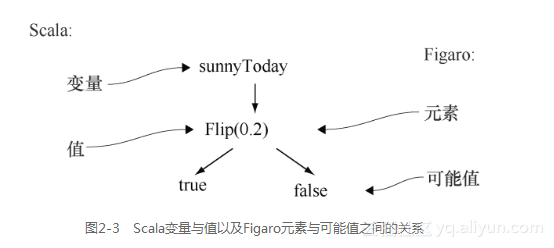
在Scala中,类型可以由另外一种描述其内容的类型参数化。您可能从Java泛型中已经熟悉了这个概念,例如,在Java中可以得到一个整数或者字符串的列表。所有Figaro元素都是Element类的实例。Element类由元素可能取值的类型参数化。这种类型称作元素的值类型。因为Flip(0.2)可以取布尔值,Flip(0.2)的值类型为Boolean。这一事实的标记方法是:Flip(0.2)是Element[Boolean]的一个实例。
关键定义
元素——代表一个随机过程的Figaro数据结构。
值——随机过程的一个可能结果。
值类型——代表元素可能取值的Scala类型。
关于这个简单模型有许多值得说明的地方。幸运的是,您已经学到的知识适用于所有Figaro模型。Figaro模型通过取得和组合简单的Figaro元素(构件)创建更复杂的元素和相关元素集合而创建。您刚刚学到的元素、值和值类型的定义是Figaro中最为重要的定义。
在继续构建更复杂的模型之前,我们先来看看如何用这个简单模型进行推理。
2.2.2 运行推理和回答查询您已经构建了一个简单模型。我们运行推理,查询sunnyToday为true的概率。首先,需要导入将要使用的推理算法:
import com.cra.figaro.algorithm.factored.VariableElimination``` 上述语句导入所谓的“变量消除”(variable elimination)算法,这是一种精确的推理算法,也就是说,它可以准确地计算您的模型和证据隐含的概率。概率推理很复杂,所以精确的算法有时候需要花费很长时间,或者耗尽内存。Figaro提供近似算法,这种算法通常提供与准确答案大致相同的答案。本章使用简单的模型,所以变量消除算法在大部分情况下可行。 现在,Figaro提供一个简单命令以指定查询、运行算法并获得答案。可以编写如下的代码:
println(VariableElimination.probability(sunnyToday, true))`
上述命令打印输出0.2。您的模型只包含元素Flip(0.2),结果为true的概率为0.2。变量消除算法正确计算出sunnyToday为true的概率是0.2。
详细说来,您刚刚看到的命令完成好几件工作:首先创建变量消除算法的一个实例,告诉实例查询目标是sunnyToday。然后运行算法并返回sunnyToday值为true的概率。这条命令还负责执行完毕的清理,释放算法所用的任何资源。
2.2.3 构建模型和生成观测值现在,我们开始构建一个更有趣的模型。您需要一个Figaro结构——If,因此要导入它。还需要一个名为Select的结构,但是这已经随着com.cra.figaro.language导入:
import com.cra.figaro.library.compound.If``` 我们使用If和Select构建更复杂的元素:
val greetingToday = If(sunnyToday,
Select(0.6 - "Hello, world!", 0.4 - "Howdy, universe!"), Select(0.2 - "Hello, world!", 0.8 - "Oh no, not again"))```
对此的思维方式是元素代表一个随机过程。在本例中,名为greetingToday的元素代表着这样的过程:首先检查sunnyToday的值,如果为true,选择“Hello,world!”的概率为0.6,“Howdy, universe!”的概率为0.4。如果sunnyToday的值为false,选择“Hello, world!”的概率为0.2,“Oh no, not again”的概率为0.8。greetingToday是一个复合元素,因为它由3个元素构建而成。由于greetingToday的可能取值为字符串,所以它是Element[String]。
现在,假定您已经看到今天的问候语是“Hello, world!”,您可以使用一个观测值说明这一证据:
greetingToday.observe("Hello, world!")```
接下来,您可以根据问候语是“Hello, world!”算出今天是晴天的概率:
println(VariableElimination.probability(sunnyToday, true))`
这条命令打印输出0.4285714285714285。注意,结果明显高于前一个答案(0.2)。这是因为问候语是“Hello, world!”时,今天是晴天的可能性高于其他情况,所以证据支持今天是晴天。这一推理是贝叶斯法则的简单实例,第9章将介绍这一法则。
您打算扩展该模型,用不同证据运行更多查询,所以应该移除变量greetingToday的观测值。用如下命令可以完成:
greetingToday.unobserve()``` 现在,如果发出如下查询:
println(VariableElimination.probability(sunnyToday, true))`
您将得到和指定证据之前一样的答案0.2。
在本节的最后,我们进一步细化模型:
val sunnyTomorrow = If(sunnyToday, Flip(0.8), Flip(0.05)) val greetingTomorrow = If(sunnyTomorrow, Select(0.6 - "Hello, world!", 0.4 - "Howdy, universe!"), Select(0.2 - "Hello, world!", 0.8 - "Oh no, not again"))``` 您可以计算在有无关于今天问候语的证据情况下,明天的问候语为“Hello, world!”的概率:
println(VariableElimination.probability(greetingTomorrow, "Hello, world!"))
// prints 0.27999999999999997
greetingToday.observe("Hello, world!")
println(VariableElimination.probability(greetingTomorrow, "Hello, world!"))
// prints 0.3485714285714286`
可以看到,在观察到今天的问候语是“Hello, world!”时,明天的问候语是“Hello, world!”的概率增大,为什么?因为今天的问候语是“Hello, world!”,今天就更有可能是晴天,明天是晴天的可能性也就更大,最终使明天的问候语更可能是“Hello, world!”。正如在第1章中所看到的,这是推断过去更好预测未来的一个例子,Figaro负责所有的计算。
现在,您已经看到了创建模型、指定证据和查询、运行推理得到答案的所有步骤,接下来我们更仔细地观察Hello World模型,理解如何从构件(原子元素)和连接器(复合元素)构建它。
图2-4是模型的图形描述。该图首先重现了模型定义,每个Scala变量在一个单独的方框中。在下半部分中,每个节点表示模型中的对应元素,同样在单独的方框中显示。有些元素本身就是Scala变量值。例如,Scala变量sunnyToday的值是Flip(0.2)元素。如果元素是Scala变量值,图上显示变量名称和元素。该模型还包含了一些不是特定Scala变量值,但仍出现在模型中的元素。例如,因为sunnyTomorrow的定义是If(sunnyToday, Flip(0.8), Flip(0.05)),Flip(0.8) 和Flip(0.05)也是模型的一部分,所以它们显示为图中的节点。
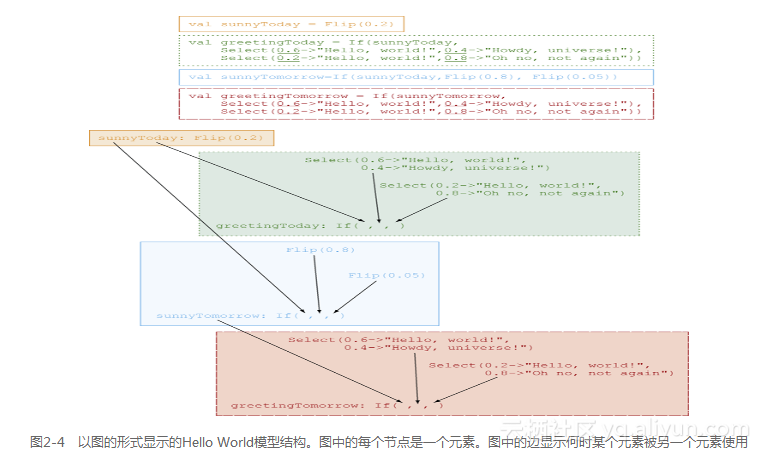
该图包含了元素之间的边。例如,从Flip(0.8)到取sunnyTomorrow值的If元素之间有一条边,表明If元素使用Flip(0.8)元素。一般来说,如果第二个元素的定义中使用了第一个元素,则两者之间存在一条边。因为只有复合元素是由其他元素构建而成的,所以只有复合元素可能成为边的终点。
2.2.5 理解重复的元素:何时相同,何时不同需要注意的一点是,Select(0.6 - "Hello, world!", 0.4 - "Howdy, universe!")在图中出现了两次,Select(0.2 - "Hello, world!", 0.8 - "Oh no, not again")也是如此。这是因为代码中定义出现了两次,一次用于greetingToday,另一次用于greetingTomorrow。尽管定义相同,但是这是两个不同的元素。它们在Figaro模型定义的随机过程的同一次执行中可能取不同的值。例如,该元素的第一个实例可能取值“Hello, world!”,而第二个实例可能取值“Howdy, universe!”。这是有意义的,因为第一个元素实例用于定义greetingToday,第二个则用于定义greetingTomorrow。今天和明天的问候语很可能不一样。
这和常规编程类似,想象一下您有一个Greeting类和如下代码:
class Greeting {
var string = "Hello, world!"
val greetingToday = new Greeting
val greetingTomorrow = new Greeting
greetingTomorrow.string = "Howdy, universe!"```
尽管定义完全相同,greetingToday 和 greetingTomorrow是Greeting类的两个不同实例。因此,greetingTomorrow.string和greetingToday.string可能取不同值,后者仍然等于“Hello, world!”。同样,Figaro构造函数(如Select)创建对应元素类的新实例。所以greetingToday和greetingTomorrow是Select元素的两个不同实例,因此在一次运行中可能取不同的值。
另一方面,注意Scala变量sunnyToday也出现了两次,一次在greetingToday的定义中,另一次在sunnyTomorrow中。但是本身是sunnyToday值的元素在图中仅出现一次。为什么?因为sunnyToday是一个Scala变量,而不是Figaro元素定义。当Scala变量在一段代码中出现超过一次时,它是相同的变量,所以使用相同的值。在我们的模型中,这是有意义的;它表示同一天的天气,用于greetingToday和sunnyTomorrow的定义中,所以在模型的任何随机执行中都取相同的值。
常规代码中也会发生相同的事情。如果编写如下代码:
val greetingToday = new Greeting
val anotherGreetingToday = greetingToday
anotherGreetingToday.string = "Howdy, universe!"`
anotherGreetingToday和greetingToday是相同的Scala变量,所以运行上述代码之后,greetingToday的值也是“Howdy, universe!”,同样,如果同一个Scala变量代表程序中出现多次的一个元素,它在每次运行中也取相同的值。
理解这一点对于了解Figaro模型的构建方式是必不可少的,所以我建议反复阅读本节以确保理解。此时,您应该已经概要了解所有的Figaro主要概念以及它们的组合方式。在下面几节中,您将更详细地研究其中一些概念,下一节首先介绍原子元素。
事实胜于雄辩,苹果MacOs能不能玩儿机器/深度(ml/dl)学习(Python3.10/Tensorflow2) 坊间有传MacOs系统不适合机器(ml)学习和深度(dl)学习,这是板上钉钉的刻板印象,就好像有人说女生不适合编程一样的离谱。现而今,无论是[Pytorch框架的MPS模式](https://v3u.cn/a_id_272),还是最新的Tensorflow2框架,都已经可以在M1/M2芯片的Mac系统中毫无桎梏地使用GPU显卡设备,本次我们来分享如何在苹果MacOS系统上安装和配置Tensorflow2框架(CPU/GPU)。
ARM放大招发布Trillium项目:包含神经网络软件库和两种AI处理器 90% 的 AI 设备都是用 Arm 的架构设计的,现在 Arm 在人工智能领域厚积薄发,发布了 Trillium 项目,包括一款为移动设备而设计的机器学习处理器、一款目标检测处理器和一个神经网络软件库。
(4运行例子)自己动手,编写神经网络程序,解决Mnist问题,并网络化部署 1、联通ColaB 2、运行最基础mnist例子,并且打印图表结果 # https://pypi.python.org/pypi/pydot#!apt-get -qq install -y graphviz && pip install -q pydot#import pydotfrom _...
如何让手机快速运行AI应用?这有份TVM优化教程 本文来自AI新媒体量子位(QbitAI) 在移动设备上部署深度神经网络的需求正在快速增加。 和桌面平台类似,GPU也能在移动平台加速推理速度、降低能耗。但问题是,大多数现有深度学习框架并不能很好的支持移动GPU。
实践操作:六步教你如何用开源框架Tensorflow对象检测API构建一个玩具检测器 TensorFlow对象检测API是一个建立在TensorFlow之上的开源框架,可以轻松构建,训练和部署对象检测模型。 到目前为止,API的性能给我留下了深刻的印象。在这篇文章中,我将API的对象设定为一个可以运动的玩具。
《计算机科学与工程导论:基于IoT和机器人的可视化编程实践方法第2版》一2.3.1 创建程序显示“Hello World” 本节书摘来华章计算机《计算机科学与工程导论:基于IoT和机器人的可视化编程实践方法第2版》一书中的第2章 ,第2.3.1节,陈以农 陈文智 韩德强 著 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
《Kinect应用开发实战:用最自然的方式与机器对话》一第3章 Kinect工作原理大揭秘 3.0 本节书摘来自华章出版社《Kinect应用开发实战:用最自然的方式与机器对话》一书中的第3章,第3.0节,作者 余涛,更多章节内容可以访问云栖社区“华章计算机”公众号查看
异步社区 异步社区(www.epubit.com)是人民邮电出版社旗下IT专业图书旗舰社区,也是国内领先的IT专业图书社区,致力于优质学习内容的出版和分享,实现了纸书电子书的同步上架,于2015年8月上线运营。公众号【异步图书】,每日赠送异步新书。
相关文章
- (高级篇 Netty多协议开发和应用)第十三章-文件传输
- 安卓开发——锁定软件——输入密码后重复弹出输入密码窗口的解决方法
- 从SeekFree的Gitee开源库建立通用MM32开发模板
- 《Unity虚拟现实开发实战》——第2章,第2.2节创建简单的透视图
- 《Unity虚拟现实开发实战》——第1章,第3.1节虚拟现实设备集成的软件
- 【QT】Qt 给已经开发好的程序快速封装成动态库
- Xamarin图表开发基础教程(11)OxyPlot框架支持的图表类型
- Andorid SQLite数据库开发基础教程(2)
- 《精通Linux设备驱动程序开发》——第1章 引言 1.1演进
- 《Clojure Web开发实战》——第2章,第2.4节Compojure和Ring之后
- 《Android传感器开发与智能设备案例实战》——第1章,第1.2节Android的巨大优势
- 《Java和Android开发学习指南(第2版)》——第1章,第1.1节下载和安装Java
- 《HTML5移动Web开发实战》—— 1.5 配置移动开发环境
- 《树莓派开发实战(第2版)》——1.2 封装树莓派
- 《Xcode实战开发》——1.3节更多素材
- 《Xcode实战开发》——2.2节创建项目
- 《树莓派开发实战(第2版)》——2.11 在Mac上共享树莓派的屏幕
- 《树莓派开发实战(第2版)》——第1部分 概率编程和Figaro简介
- 《Linux嵌入式实时应用开发实战(原书第3版)》——2.3 安装方案
- php扩展开发实战教程(1)
- iOS项目开发实战——学会使用TableView列表控件(四)plist读取与Section显示
- 【Unity】动作游戏开发实战详细分析-06-技能系统设计