
基于Python实现自然语言处理(主题层次的情感分类)【100010252】
主题层次的情感分类
1 任务及数据集介绍
该项目作业的具体任务是来自于 BDCI2018-汽车行业用户观点主题及情感识别的题目。数据是网络中公开的用户对汽车相关内容的评价文本。此任务是对每条文本内容(即用户评论)进行分析,确定该条评论中讨论的主题以及每个主题的情感信息,以此获知用户对所讨论主题的偏好。
其中主题一共分为 10 类:动力、价格、内饰、配置、安全性、外观、操控、油耗、空间、舒适性。情感分为 3 类:中立、正向、负向,分别用数字 0、1、-1 表示。
训练集数据一共有 10654 条评论,已由人工进行标注,为 CSV 格式的文件,以逗号分隔,首行为表头,字段说明如表 1 所示。其中 content_id 与 content 一一对应,但同一条 content 中可能包含多个主题,此时会出现多条记录来标注不同的主题及情感,因此在整个训练集中 content_id 存在重复值。
测试数据也为 CSV 格式的文件,首行为表头,字段有 content_id 和 content,与训练集对应字段相同。
但由于 BDCI 官网上此比赛已结束,线上提交接口已关闭,我们无法在测试数据对模型进行评估。因此,此次项目作业完全是在训练数据上进行的。我们将训练数据按照 8:1:1 的比例划分成训练集(8523 条数据)、验证集(1066 条数据)、测试集(1065 条数据)。
表1: 训练集字段说明
| 字段名称 | 类型 | 描述 | 说明 |
|---|---|---|---|
| content_id | Int | 数据 ID | |
| content | String | 文本内容 | |
| subject | String | 主题 | 分析出的主题 |
| sentiment_value | Int | 情感分析 | 分析出的该主题的情感 |
该任务采用 F1 值评估指标,按照“主题 + 情感词”精确匹配的方式,用 Tp 表示判断正确的数量,Fp 表示判断错误或多判的数量,Fn 表示漏判的数量。则准确率 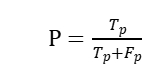 ,召回率 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7jAectmF-1674957094326)(https://www.writebug.com/myres/static/uploads/2021/12/16/ac9936f7619115582c16f85e961a4bbb.writebug)],
,召回率 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7jAectmF-1674957094326)(https://www.writebug.com/myres/static/uploads/2021/12/16/ac9936f7619115582c16f85e961a4bbb.writebug)],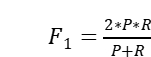 。
。
2 相关工作
上述任务是一个主题级别(Aspect-level)的文本情感分类任务,它是情感分类的一个分支,其目标是识别出句子中某个特定主题的情感极性。相比文档级别的情感分类任务,主题级别的情感分类是更细粒度的分类任务,它可以克服文档级别情感分类的局限性。尤其是当一篇文本中同时涉及多个主题时,正负的情感极性通常是混杂在一起的,如果忽略主题信息,我们很难确定目标文本的情感极性。比如“great food but the service was dreadful”,在这条用户对餐厅的评论中同时涉及到了“食物”和“服务”两个主题,而且用户在这两个主题上的评价的情感极性是相反的,如果我们在文本层次进行情感分类,很难说这条文本是正向的,还是负向的,甚至是中性的。
在主题级别的情感分类任务上,目前已有的工作大致可以分为两类。一类是基于手工提取的特征和机器学习算法的级联方法,例如 Nasukawa 等人[1]的工作中,首先对句子进行依存句法分析,然后使用预定义的规则确定每个主题的情感极性。Jiang 等人[2]提出,基于句子的语法结构构造一些主题依赖的特征,将这些特征和其他文本内容特征一起作为 SVM 分类器的输入,从而提高主题依赖的情感分类的准确度。另一类工作是采用端到端的神经网络模型,使用神经网络模型可以自动进行表征学习,不需要花费大量时间进行手工工程或者编写规则。在这类模型中,大多数是基于 LSTM 的网络架构,因为 LSTM 可以很好地处理像文本这样的序列数据,而且可以捕捉到长期依赖。例如 Tang 等人[3]提出了 TD-LSTM 的方法,该方法的基本思路是通过两个 LSTM 网络分别来建模主题的左、右上下文,然后使用这两个 LSTM 网络的输出的串接进行情感预测。除此之外,近年来的工作中也大量使用注意力机制,它和 LSTM 结合,在很多任务上可以提高网络性能。例如 Wang 等人[4]提出了 AE-LSTM 模型和 ATAE-LSTM 模型。AE-LSTM 模型是先将文本通过 LSTM 网络层,得到每个词对应的隐单元输出,然后结合主题向量表示计算一组注意力值来加权句子的不同部分,从而得到最终的向量表达,进行情感分类。相比 AE-LSTM 模型,ATAE-LSTM 模型更强调主题向量表达的影响,它把主题向量表达和每个词的向量表达串接在一起进行建模,得到文本的表示。Ma 等人[5]提出了 IAN 模型,该模型使用两个 LSTM 网络分别对句子和主题进行建模,然后对句子的隐状态进行池化操作,使用池化的结果和主题的隐状态计算一组注意力值,对主题的隐状态进行加权得到主题的最终向量表示,同时对主题的隐状态进行池化操作,使用池化结果和句子的隐状态计算另一组注意力值,对句子的隐状态进行加权得到句子的最终向量表示,最后将两个向量表示串接起来进行情感分类。
3 模型
针对 BDCI-2018 的汽车行业用户观点主题及情感识别任务,我们在调研的基础上对一些模型进行改进,从而使其能够适应该任务的特点和需求。最终实现的 3 个模型的具体思路如下。
3.1 基于 AOA 的改进模型 1
第一个模型架构如图 1 所示,是对 AOA(Attention Over Attention)模型[6]的改进,一共分为四个部分:词嵌入模块、双向 LSTM 模块、注意力模块和最终的分类预测模块。
词嵌入模块:对于一个给定的句子,经过分词之后可以将其表示为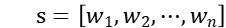 。对于所有主题,我们可以将其表示成
。对于所有主题,我们可以将其表示成 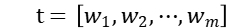 (此任务有 10 个主题词,则 m=10)。我们首先使用预训练好的词向量将每个词
(此任务有 10 个主题词,则 m=10)。我们首先使用预训练好的词向量将每个词 映射到一个低维的实值向量
映射到一个低维的实值向量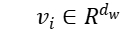 。则句子和主题分别通过一个词嵌入层之后我们可以得到两个词向量集合
。则句子和主题分别通过一个词嵌入层之后我们可以得到两个词向量集合 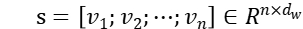 和
和 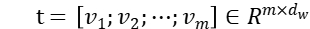 。
。
双向 LSTM 模块:我们将得到的词向量 s 和 t 分别通过一个双向 LSTM 层来学习句子和主题的隐含语义表达,结果为双向 LSTM 隐单元输出的串接,此时可以得到句子和主题的表达 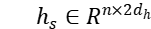 和
和  。
。
注意力模块:对于上一步得到的  和
和 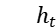 ,我们首先计算一个相互作用矩阵
,我们首先计算一个相互作用矩阵 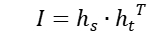 ,矩阵中的每个元素
,矩阵中的每个元素 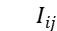 表示句子中的某个词
表示句子中的某个词 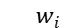 和某个主题
和某个主题 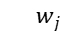 之间的关系。然后我们对矩阵
之间的关系。然后我们对矩阵  的每列进行 softmax 操作,得到 aspect-to-sentence 的注意力值
的每列进行 softmax 操作,得到 aspect-to-sentence 的注意力值 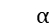 ,其中
,其中 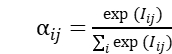 。直观来讲,
。直观来讲,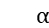 每一列的意义是,对于某个主题而言,句子中的哪些词比较重要。最终根据注意力值
每一列的意义是,对于某个主题而言,句子中的哪些词比较重要。最终根据注意力值 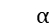 和句子的隐含语义表达
和句子的隐含语义表达 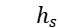 来计算各主题感知的句子向量表达,即
来计算各主题感知的句子向量表达,即 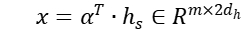 。
。
分类模块:我们将上一步得到的句子表达向量 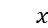 展平,然后输入到两层的全连接网络,得到 40 维的分类结果。对于 10 个主题中的每一个主题,对应有 4 维输出结果,分别表示句子中不含该主题的概率、该句子在该主题的情感极性为中性的概率、该句子在该主题的情感极性为正向的概率、该句子在该主题的情感极性为负向的概率。对每个主题的四维输出结果进行 softmax,以此判断该句子是否不含该主题或者该句子在该主题上的情感极性。
展平,然后输入到两层的全连接网络,得到 40 维的分类结果。对于 10 个主题中的每一个主题,对应有 4 维输出结果,分别表示句子中不含该主题的概率、该句子在该主题的情感极性为中性的概率、该句子在该主题的情感极性为正向的概率、该句子在该主题的情感极性为负向的概率。对每个主题的四维输出结果进行 softmax,以此判断该句子是否不含该主题或者该句子在该主题上的情感极性。

图1:AOA模型整体架构
3.2 基于 IAN 的改进模型 2
第二个模型架构如图 2 所示,是对 IAN(Interactive Attention Networks)模型的改进,一共分为四个部分:词嵌入模块、双向 LSTM 模块、交互注意力模块和最终的分类预测模块。
词嵌入模块:与上一个模型相同,句子和主题分别通过一个词嵌入层之后我们可以得到两个词向量集合 和
和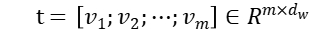 。
。
双向 LSTM 模块:将得到的词向量 s 和 t 分别通过一个双向 LSTM 层来学习句子和主题的隐含语义表达,结果为双向 LSTM 隐单元输出的串接,此时得到隐状态  和
和  。
。
交互注意力模块:对于上一步得到的 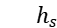 和
和 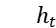 ,我们首先进行平均池化,得到
,我们首先进行平均池化,得到 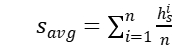 和
和 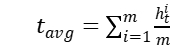 。 然后由
。 然后由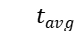 和句子的隐状态
和句子的隐状态 计算一组注意力分值,其中每个分值
计算一组注意力分值,其中每个分值 ,由注意力值对句子的各部分进行加权,得到句子的最终向量表达
,由注意力值对句子的各部分进行加权,得到句子的最终向量表达 。同时由
。同时由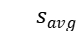 和主题的隐状态
和主题的隐状态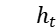 计算另一组注意力分值,其中每个分值
计算另一组注意力分值,其中每个分值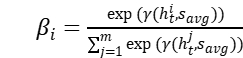 ,由该组注意力值对各主题进行加权,得到主题的最终向量表达
,由该组注意力值对各主题进行加权,得到主题的最终向量表达 。两组注意力分值的计算公式中,
。两组注意力分值的计算公式中,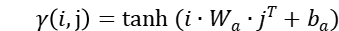 。
。
**分类模块:**我们将上一步得到的主题和句子的最终向量表达 和
和 串接起来,然后输入到两层的全连接网络,得到 40 维的分类结果。对于 10 个主题中的每一个,有 4 维输出结果,分别表示句子中不含该主题的概率、该句子在该主题的情感极性为中性的概率、该句子在该主题的情感极性为正向的概率、该句子在该主题的情感极性为负向的概率。这一步与上一个模型相同,对每个主题的四维输出结果进行 softmax,以此判断该句子是否不含该主题或者该句子在该主题上的情感极性。
串接起来,然后输入到两层的全连接网络,得到 40 维的分类结果。对于 10 个主题中的每一个,有 4 维输出结果,分别表示句子中不含该主题的概率、该句子在该主题的情感极性为中性的概率、该句子在该主题的情感极性为正向的概率、该句子在该主题的情感极性为负向的概率。这一步与上一个模型相同,对每个主题的四维输出结果进行 softmax,以此判断该句子是否不含该主题或者该句子在该主题上的情感极性。
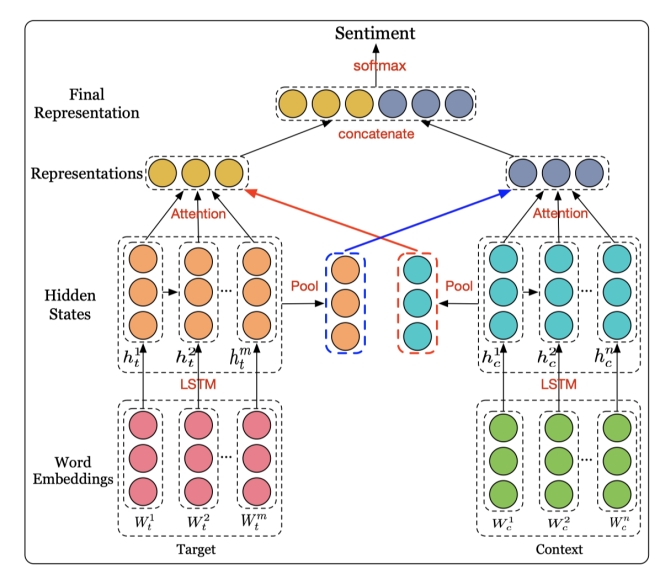
图 2:IAN 模型整体架构
3.3 基于 AEN 的改进模型 3
第三个模型架构如图 3 所示,是利用 AEN(Attention Encoder Networks)模型[7]对 AOA(Attention Over Attention)模型的更深层次改进,一共分为五个部分:词嵌入模块、双向 LSTM 模块、注意力模块、多输入池化模块和最终的分类预测模块。
词嵌入模块、双向 LSTM 模块、注意力模块:这三个模块与第一个模型 AOA 相同,总共得到三个输出向量,句子的隐层状态 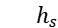 和主题的隐层状态
和主题的隐层状态 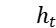 以及句子和主题交互得到的主题交互状态
以及句子和主题交互得到的主题交互状态 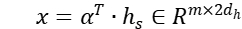 ,这三个向量都是下一个模块的输入。
,这三个向量都是下一个模块的输入。
多输入池化模块:将上一步得到的三个输出分别进行一维最大池化,得到三个池化结果向量,对应为 、
、 以及
以及 ,然后将三个池化向量串接,得到最终分类模块的输入向量 x
,然后将三个池化向量串接,得到最终分类模块的输入向量 x  。
。
分类模块:最终的分类模块输入为上一步三个池化向量的串接展平结果,分类机制与前两个模型相同。对每个主题的四维输出结果进行 softmax,以此判断该句子是否不含该主题或者该句子在该主题上的情感极性。
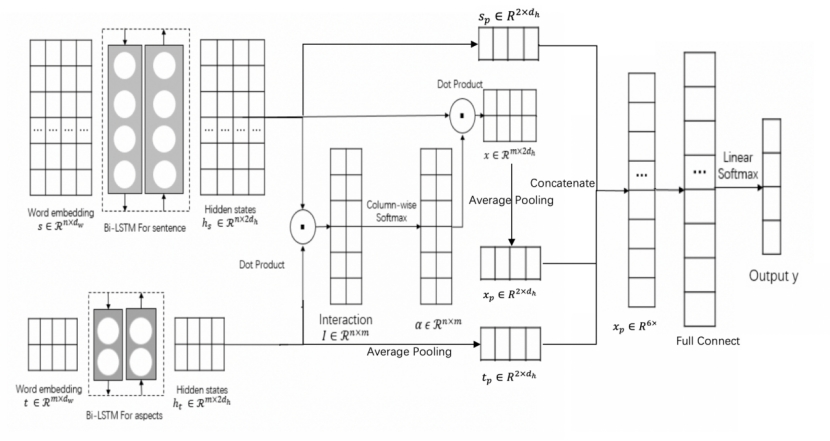
图3:AEN模型整体架构
4 实验过程与结果
4.1 实验过程
第一步:对任务数据进行分词,得到数据集的词典,及每个词的 embedding,结果文件 embeddings_.p 会输出到指定目录下。(因为本实验使用腾讯公开的预训练的汉语词嵌入,数据量比较大,为了减少模型训练时的计算资源需求,我们先处理得到本任务数据集的词典,并提取出这些单词的 embedding 另存到文件 embeddings_.p)
python get_embed.py \
--train_data_path=path/to/train_data \
--embed_data_path=path/to/pretrain/word_embedding \
--out_embed_dit=dir/to/save/output_file
第二步:模型训练及评估。如前所述,我们将训练集以 8:1:1 的比例划分成训练集、验证集和开发集进行实验,此处我们的超参数具体设置如下所示。
python aspect_senti.py \
--train_data_path=path/to/train_data \
--embed_data_path=path/to/embeddings_.p \
--out_dir=/dir/to/save/model \
--max_sentence_length=256 \
--lstm_hidden_size=100 \
--dense_hidden_size=512 \
--leakyRelu_alpha=0.01 \
--drop_rate=0.5 \
--reg_rate=0.001 \
--optimizer=adam \
--lr_factor=0.65 \
--batch_size=32 \
--epochs=30
为了方便运行,模型必须的参数都已经在代码中设置了默认值,均是在验证集上进行调参之后的最佳参数设置,而且项目目录已经按照需要进行调整,只需输入 python 加模型名称即可运行不同的模型,比如 python aen.py。
4.2 实验结果
三个模型训练时使用的损失函数均是各主题的交叉熵损失之和。训练过程中我们保存在验证集上 值最大的模型,然后在测试集上进行评估,同时每个模型还测试了不同的固定文本长度。三个模型在测试集上的评估结果如下表:
值最大的模型,然后在测试集上进行评估,同时每个模型还测试了不同的固定文本长度。三个模型在测试集上的评估结果如下表:
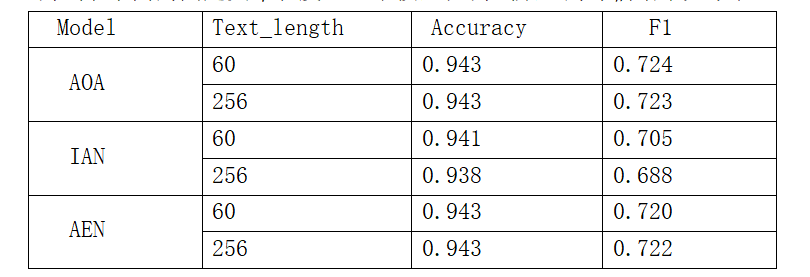
据 BDCI 官网上该任务的排行榜,官方测试集上最好的模型表现为 F1=0.708。由于我们无法再官方测试集上进行模型评估,因此我们的结果和排行榜结果无法进行的严格比较,但从结果来看,我们的模型还是表现不错的。
5 总结
通过此次项目实践,我们了解了文本情感分析的相关模型,尤其是主题级别的情感极性分析,改进了端到端的神经网络模型,如 AOA、IAN 和 AEN,使得模型能够适应主题层次情感分类任务的特点和需求。我们遇到的问题要比普通的文本分类任务更加复杂,在该问题中,一篇文本中通常会同时涉及多个主题,正负的情感极性通常是混杂在一起的,如果忽略主题信息,我们很难确定目标文本的情感极性。因此,在在主题级别的情感分类任务上,我们在调研的基础上对 AOA、IAN 和 AEN 模型进行了改进,从而使其能够适应该任务的特点和需求。
在 BDCI 官方数据集上,我们将训练集以 8:1:1 的比例划分成训练集、验证集和开发集进行实验,设置模型的固定文本长度分别为 60 和 256,三个模型的表现不错,其中 AOA 模型和 AEN 模型的 F1 值均超过了官网测试集上最好的模型表现。由于我们无法对官方发布的测试集进行线上评估,因此无法和赛题排行榜进行精确对比,但就排行榜情况来看,最好成绩也不高于 0.71,我们的方法所取得的结果是不错的。
情感分析是自然语言处理中常见的场景,比如汽车行业用户观点主题及情感识别,对于指导产品更新迭代具有关键性作用。通过对用户评价进行情感分析,可以挖掘产品在各个维度的优劣,从而明确如何改进产品。比如对用户评价进行分析,可以得到汽车动力、价格、内饰、配置、安全性、外观、操控、油耗、空间、舒适性等多个维度的用户情感指数,从而从各个维度上改进现在汽车行业的制造和销售状况。
深度学习在 NLP 领域内应用相当广泛,在情感分类领域,我们同样可以采用深度学习方法。基于深度学习的情感分类,具有精度高,通用性强等优点。通过完成这次项目作业,我们对情感分类问题有了更深入的认识,对神经网络模型有了进一步的掌握,获益良多。
♻️ 资源
大小: 31.7MB
➡️ 资源下载:https://download.csdn.net/download/s1t16/87354341
相关文章
- 【Python】python 多线程两种实现方式
- Python中elasticsearch插入和更新数据的实现方法
- 点云Las格式分析及python实现
- Python:利用python代码编程实现将视频的avi格式转换为MP4格式
- Python编程语言学习:python的列表的特殊应用之一行命令实现if判断中的两类判断
- Python语言学习:Python语言学习之python包/库package的简介(模块的封装/模块路径搜索/模块导入方法/自定义导入模块实现华氏-摄氏温度转换案例应用)、使用方法、管理工具之详细攻略
- Python语言学习:python语言代码调试—异常处理之详细攻略
- Python:利用python编程实现三维图像绘制展示(六面体旋转、三维球柱状体、下雪场景等)
- Python编程语言学习:python的列表的特殊应用之一行命令实现if判断中的两类判断
- Python的IDE:基于Eclipse/MyEclipse软件的PyDev插件配置python的开发环境(不同python项目加载不同版本的python)—从而实现Python编程图文教程之详细攻略
- Python语言学习:基于python五种方法实现使用某函数名【func_01】的字符串格式('func_01')来调用该函数【func_01】执行功能
- Python语言学习:利用python语言实现调用内部命令(python调用Shell脚本)—命令提示符cmd的几种方法
- Python之API:基于python语言调用华为云API(华为网站)实现特定功能
- Python:利用python代码编程实现将视频的avi格式转换为MP4格式
- 神奇的量子世界——量子遗传算法(Python&Matlab实现)
- 超级炫酷的3D旋转动态图——Python代码实现
- Python设计模式中单例模式的实现及在Tornado中的应用
- 【华为机试真题 Python实现】括号匹配II
- 【华为机试真题 Python实现】水仙花数【2022 Q1 Q2 | 100分】
- 【华为机试 Python实现】VLAN资源池
- Python编程:Flask-BasicAuth实现Authentication登录认证
- Python-Tensorflow-优化器
- Python实现卡方检验和相关性分析
- 【异常】前端ERR! stack Error: Can‘t find Python executable “python“, you can set the PYTHON env variable.
- 日期和时间处理(Python实现)
- 神奇的量子世界——量子遗传算法(Python&Matlab实现)
- 【伏羲八卦图】(Python&Matlab实现)