
基于Java实现(图形界面)小型类 C 语言编译器【100010634】
小型类 C 语言编译器
一、设计目的及设计要求
设计一个完整的小的编译程序模型,在 Java 语言为工具的基础上,实现从 C 语言(部分核心语法)到汇编语言的编译,进一步加深理解和掌握所学知识,完成词法分析,语法分析,语义分析和中间代码生成,最终产生目标汇编代码。
二、开发环境描述
操作系统:Windows 10,Intel® Core™ i7-8750H CPU @ 2.20GHz
集成开发环境:eclipse-java-2019-06-R-win32-x86_64
三、设计内容、主要算法描述
对于本部分“设计内容、主要算法描述”,我将分为词法分析、语法分析、中间代码生成、目标代码生成四个主要部分进行介绍(也就是对程序的四个主要功能实现的 Java 类介绍),其中涉及到的其他小类就顺带在大类中介绍。
3.1 词法分析 LexAnalyse
词法分析的定义是根据词法规则识别出源程序中的各个记号(token),每个记号代表一类单词(lexeme)。源程序中常见的记号可以归为几大类:关键字、标识符、字面量和特殊符号。词法分析器的输入是源程序,输出是识别的记号流。词法分析器的任务是把源文件的字符流转换成记号流。本质上它查看连续的字符然后把它们识别为“单词”。
在我设计的编译器中,词法分析的结果将被存于 wordList 的 ArrayList 中,同时将被存于 tiny Compiler 包下的 output 文件夹下的 wordList.txt 文件中。要对词法分析介绍,就得先介绍其中用到的小类 Word 类和 Error 类。
Word 类
单词 Word 类包括四个成员变量:整型变量单词序号 id,字符串变量单词的值 value,字符串变量单词类型 type,整型变量单词所在行 line,布尔型变量单词合法标志 flag(但是构造函数时无需构造,默认为 true),如下表所示:
表 1 Word 类成员变量
| 数据类型 | 数据名字 | 数据含义 |
|---|---|---|
| int | id | 单词序号 |
| String | value | 单词值 |
| String | type | 单词类型 |
| int | line | 单词所在行 |
| boolean | flag | 单词合法标志 |
声明中的类型有以下多种:KEY(关键词)、OPERATOR(运算符),INT_CONST(整形常量)、CHAR_CONST(字符常量)、BOOL_CONST(布尔常量)、IDENTIFYER(标志符)、BOUNDARYSIGN(界符)、END(结束符)、UNIDEF(未知类型);
其中 KEY 类型包括以下符号:void、main、int、char、if、else、while、for、printf、scanf;其中 OPERATOR 类型包括以下符号:+、-、++、–、*、/、>、<、>=、<=、==、!=、=、&&、||、!、.、?、|、&;其中 BOUNDARYSIGN 类型包括以下符号:(、)、{、}、;、,;
除构造函数外,单词类 Word 还提供了 5 种成员函数如下表所示:(其中最后两种函数是 isOperator 函数的后续分流函数)
表 2 Word 类成员函数
| 级别 | 函数名字 | 函数功能 |
|---|---|---|
| 1 | boolean isKey(String word) | 判断单词 word 是否是关键词 |
| 1 | boolean isOperator(String word) | 判断单词 word 是否是运算符 |
| 1 | boolean isBoundarySign(String word) | 判断单词 word 是否是边界符 |
| 2 | boolean isArOP(String word) | 判断 word 是否是算数运算符 |
| 2 | boolean isBoolOP(String word) | 判断 word 是否是逻辑运算符 |
Error 类
错误 Error 类有四个成员变量:整型变量错误序号 id,字符串变量 info 错误信息 info,整型变量错误所在行 line,Word 类对象错误的单词 word。其构造函数就是通过其参数构造一个 Error 类对象,如下表所示:
表 3 Error 类成员变量
| 数据类型 | 数据名字 | 数据含义 |
|---|---|---|
| int | id | 错误序号 |
| String | info | 错误信息 |
| int | line | 错误所在行 |
| Word | word | 错误的单词对象 |
LexAnalyse 类
介绍完单词类Word和错误类Error,下面就可以介绍LexAnalyse类了,其由ArrayList单词表wordList(用于顺序存储词法分析得到的每个单词),ArrayList错误信息表errorList,整型变量单词个数wordCount,整型变量errorCount错误个数,布尔类型变量多行注释标志noteFlag,布尔类型变量词法分词错误标志lexErrorFlag,如下表所示:
表 4 LexAnalyse 类成员变量
| 数据类型或结构 | 名称 | 含义与作用 |
|---|---|---|
| ArrayList | wordlist | 单词表,存储词法分析出的单词 |
| ArrayList | errorList | 错误信息表,存储词法分析出的错误信息 |
| int | wordcount | 单词个数,统计 |
| int | errorCount | 错误个数,统计 |
| boolean | noteFlag | 多行注释标志,检测到多行注释时置为 1,排除掉后置为 0 |
| boolean | lexErrorFlag | 词法分析出错标志 |
除构造函数外,本函数还提供以下成员函数,如下表所示:
表 5 LexAnalyse 类成员函数
| 函数名字 | 函数作用 |
|---|---|
| boolean isDigit(char ch) | 判断单个字符 ch 是否为数字 |
| boolean isInteger(String word) | 判断单词对象 word 的值是否为数字 |
| boolean isLetter(char ch) | 判断单个字符 ch 是否为字母 |
| boolean isID(String word) | 判断单词对象 word 的值是否是标识符 |
| boolean isFail() | 判断词法分析是否出错 |
| void analyse(String str, int line) | 对 line 行的字符串 str 进行词法分析 |
| ArrayList lexAnalyse(String str) | 对字符串 str,调用 analyse()函数来进行词法分析,结果存到 wordList |
| ArrayList lexAnalyse1(String filePath) | 对 filePath 路径内的文件,调用 analyse()函数来进行词法分析,结果存到 wordList |
| String outputWordList() | 把 wordList 中的词法分析结果写到路径下的/output/文件下,并返回这个文件的路径 |
其中最核心的函数是 void analyse(String str, int line),也就是对 line 行的字符串 str 进行词法分析的具体函数。限于不能大量引用代码进行分析,我将用图片形式进行介绍,如下图 1 所示:
图 1 状态转换图
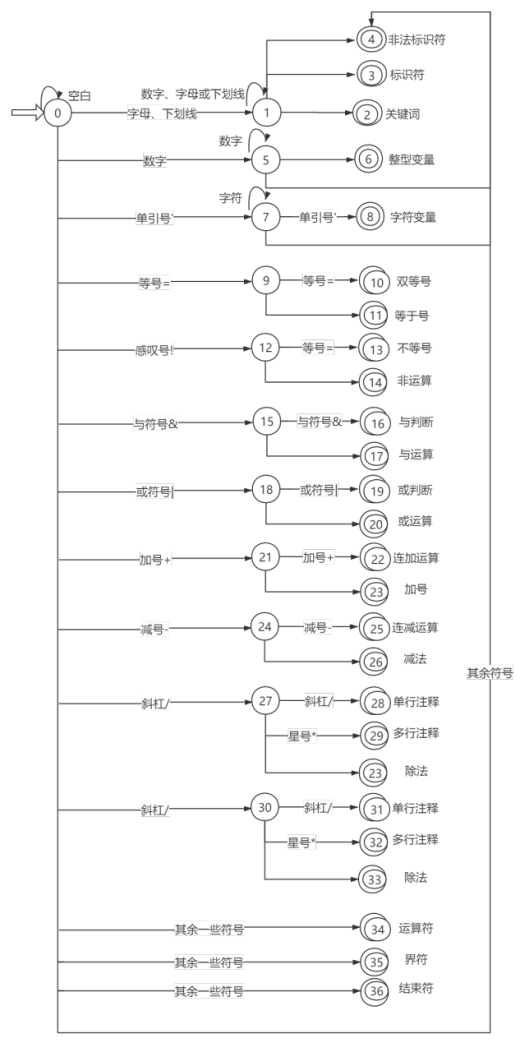
简单介绍一下上面的状态转换图的思路:
1)首先读取第一个字符,根据第一个字符的判断结果,进行后续操作:
2)如果第一个字符是字母或者下划线,继续判断后面的字符直到出现边界符、运算符、空字符、回车换行符、回车符、制表符才停下,停下后判断读取的 word,是关键字、标识符、或是非法标识符;
3)如果第一个字符是数字,继续判断后面的字符直到出现边界符、运算符、空字符、回车换行符、回车符、制表符才停下,停下后判断读取的 word,是整型常量或是非法标识符;
4)如果第一个字符是单引号’,继续判断后面的字符直到长度超出本行,或是另外一个单引号’,或是某位字符不是 0-255 的 ASCII 码才停下,停下后判断读取的 word,是字符常量或是非法标识符;
5)如果第一个字符是等号=,继续判断紧接着的下一个字符是不是一个=,由此判断运算符=还是运算符==;
6)如果第一个字符是等感叹号!,继续判断紧接着的下一个字符是不是一个=,由此判断运算符!还是运算符!=;
7)如果第一个字符是与符号&,继续判断紧接着的下一个字符是不是一个&,由此判断运算符&还是运算符&&;
8)如果第一个字符是或符号 |,继续判断紧接着的下一个字符是不是一个 |,由此判断运算符 | 还是运算符 ||;
9)如果第一个字符是加号 +,继续判断紧接着的下一个字符是不是一个 +,由此判断运算符 + 还是运算符 ++;
10)如果第一个字符是减号-,继续判断紧接着的下一个字符是不是一个-,由此判断运算符-还是运算符–;
11)如果第一个字符是与符号/,继续判断紧接着的下一个字符是不是一个/,或是一个*,由此判断是单行注释//,还是多行注释/*,还是运算符/;
12)如果以上都不是,就通过 switch 语法判断是否是’ ‘、’\t’、‘\r’、‘\n’、‘[’、‘]’、‘(’、‘)’、‘{’、‘}’、‘,’、‘"’、‘.’、‘;’、‘*’、‘%’、 ‘>’、‘<’、‘?’、‘#’,并按照 Word 中的分类对其进行类型判断,并且存入 wordList
13)如果上述都不是,那么算做非法标识符。
3.2 语法分析 Parser
语法分析器根据语法规则识别出记号流中的结构(短语、句子),并构造一棵能够正确反映该结构的语法树。
在我设计的编译器中,语法分析是最困难的一步,结构最复杂。语法分析涉及到的最主要的预备知识和结构如下:
C 语言的 LL1 语法
为了适当降低难度,我选择的是 LL1 文法,具体文法(没有实现对 C 语言的所有语法,只是子集)如下:
1.1、文法开始:
2.S->voidmain(){A}
3.
4.2、声明:
5.X->YZ;
6.Y->int|char|bool
7.Z->UZ’
8.Z’->,Z|$
9.U->idU’
10.U’->=L|$
11.
12.3、赋值:
13.R->id=L;
14.
15.4、算术运算:
16.L->TL’
17.L’->+L|-L|$
18.T->FT’
19.T’->*T|/T|$
20.F->(L)
21.F->id|num
22.O->++|--|$
23.Q->idO|$
24.
25.5、布尔运算
26.E->HE’
27.E’->&&E|$
28.H->GH’
29.H’->||H
30.H’->$
31.G->FDF
32.D-><|>|==|!=
33.G->(E)
34.G->!E
35.
36.5、控制语句
37.B->if(E){A}else{A}
38.B->while(E){A}
39.B->for(YZ;G;Q){A}
40.
41.6、功能函数
42.B->printf(P);
43.B->scanf(id);
44.P->id|ch|num
45.
46.7、复合语句
47.A->CA
48.C->X|B|R
49.A->$
四元式类 FourElement
四元式 FourElement 类有五个成员变量:整型变量四元式序号 id,字符串变量操作符 op,字符串变量第一个操作数 arg1,字符串变量第二个操作数 arg2,字符串变量结果 result。其构造函数就是通过其参数构造一个 FourElement 类对象,如下表所示:
表 6 FourElement 类成员变量
| 数据类型 | 数据名字 | 数据含义 |
|---|---|---|
| int | id | 四元式序号 |
| String | op | 四元式操作符 |
| String | arg1 | 第一个操作数 |
| String | arg2 | 第二个操作数 |
| String | result | 结果 |
要进行语法分析,就需要从语法分析器得到的结果 wordList 中不断取出第一个数,与分析栈 analyseStack 之间进行配合分析,必要时将一些数据填入语义栈 semanticStack 和四元式列表 fourElemList。在语法分析这一步,最重要的就是上述四个“数据结构”。大致示意图如下:
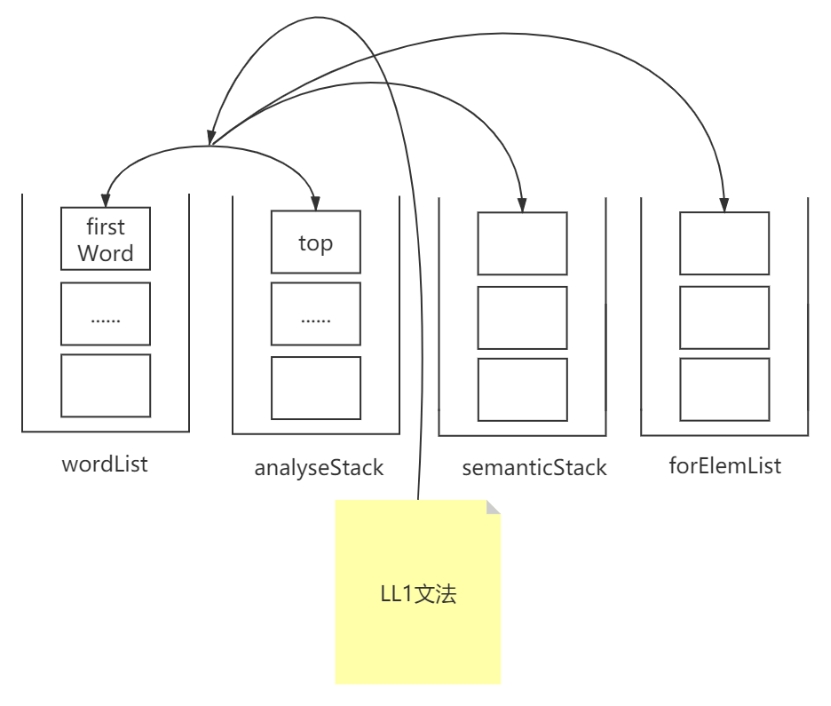
图 2 语法分析示意图
LL(1)文法:从文法的开始符,向下推导,推出句子。对文法 G 的句子进行确定的自顶向下语法分析的充分必要条件是,G 的任意两个具有相同左部的产生式 A—>α|β 满足下列条件:
(1)如果 α、β 均不能推导出 ε,则 FIRST(α) ∩ FIRST(β) = 。
(2)α 和 β 至多有一个能推导出 ε。
(3)如果 β *═> ε,则 FIRST(α) ∩ FOLLOW(A) = 。
将满足上述条件的文法称为 LL(1)文法。
实例分析
由于语法分析比较复杂,为了更好的介绍语法分析,我将对实例中的一段 C 语言代码经过词法分析和语法分析的过程进行介绍,如下:
1.voidmain()
2.{
3.intsum=0;
4.for(inti=1;i<11;i++){
5.sum=sum+i;
6.}
7.}
#
这是我输入的要进行词法分析和语法分析的 C 语言代码段(限制代码段不能超过 10 行,所以不取太多)。
首先是词法分析,根据我们之前介绍的词法分析,编译器中的词法分析器,将会对每一行进行分析,提取出所有的单词 word 存入 wordList,最终结果是 44 个单词(含结束符#),也就是说单词表 wordList 结果如下:
1.单词序号单词的值单词类型单词所在行单词是否合法
2.1void 关键字1true
3.2main关键字1true
4.3(界符1true
5.4)界符1true
6.5{界符2true
7.6int关键字3true
8.7sum标志符3true
9.8=运算符3true
10.90整形常量3true
11.10;界符3true
12.11for关键字4true
13.12(界符4true
14.13int关键字4true
15.14i标志符4true
16.15=运算符4true
17.161整形常量4true
18.17;界符4true
19.18i标志符4true
20.19<运算符4true
21.2011整形常量4true
22.21;界符4true
23.22i标志符4true
24.23++运算符4true
25.24)界符4true
26.25{界符4true
27.26sum标志符5true
28.27=运算符5true
29.28sum标志符5true
30.29+运算符5true
31.30i标志符5true
32.31;界符5true
33.32}界符6true
34.33}界符7true
35.34#结束符8true
36.词法分析通过:
语法分析:
首先需要在语法分析栈中放入文法开始符和结束符 S#,在语义栈中放入#。然后开始语法分析:
步骤 1)
S 被读取,根据程序,在下一步中,voidmain(){A}#将被存入语法分析栈;
步骤 2)
当前语法分析栈:voidmain(){A}#
wordList 中:voidmain(){intsum=0;for(inti=1;i<11;i++){sum=sum+i;}}#
语义栈:#
步骤 3)
可以看出此时 term.equals(firstWord.value),所以可以将语法分析栈和 wordList 的栈顶元素相抵消,并且接下来几个都可以抵消,直到如下状态:
当前语法分析栈:A}#
wordList 中:intsum=0;for(inti=1;i<11;i++){sum=sum+i;}}#
语义栈:#
此时根据文法,应该使用 A->C,结果如下一步骤
步骤 4)
当前语法分析栈:CA}#
wordList:intsum=0;for(inti=1;i<11;i++){sum=sum+i;}}#
语义栈:#
此后都是按照文法,判断,进入不同的路径即可,直到第一个赋值语句;
步骤 5)
由于前面的已经列出的文法的判断帮助,文法将声明语句帮助我们识别赋值:
1.X->YZ;
2.Y->int|char|bool
3.Z->UZ’
4.Z’->,Z|$
5.U->idU’
6.U’->=L|$
重点在于报告中要求“基于一遍扫描的语法制导翻译方法。算术表达式、 赋值语句、布尔表达式、控制语句等语法单位的翻译模式。”
所以对于之前已经提到的文法,我们需要构造 LL1 属性翻译文法,即在原有 LL1 文法基础上加上动作符号,并给非终结符和终结符加上一定属性,给动作符号加上语义子程序,具体改动如下:
2.1、构造LL1属性翻译文法
3.构造LL1属性翻译文法即在原有LL1文法基础上加上动作符号,并给非终结符和终结符加上一定属性,给动作符号加上语义子程序。
4.对原有LL1文法改进的地方如下:
5.1、赋值:
6.产生式语义子程序
7.R->@ASS_Rid=L@EQ;@ASS{R.VAL=id并压入语义栈}
8.@EQ{RES=R.VAL,OP=’=’,ARG1=L.VAL,
9.newfourElement(OP,ARG1,/,RES)}
10.U->@ASS_UidU’{U.VAL=id并压入语义栈}
11.U’->=L|$@EQ_U’{RES=U.VAL,OP=’=’,ARG1=L.VAL,newfourElement(OP,ARG1,/,RES)}
12.
13.2、算术运算:
14.产生式语义子程序
15.L->TL’@ADD_SUB{If(OP!=null)RES=NEWTEMP;L.VAL=RES,并压入语义栈;NewfourElement(OP,T.VAL;,L’VAL,RES),
16.}
17.L’->+L@ADD{OP=+,ARG2=L.VAL}
18.L’->-L@SUB{OP=-,ARG2=L.VAL}
19.L’->$
20.T->FT’@DIV_MUL{if(OP!=null)RES=NEWTEMP;T.VAL=RES;
21.newFourElement(OP,F.VAL,ARG2,RES)
22.elseARG1=F.VAL;}
23.T’->/T@DIV{OP=/,ARG2=T.VAL}
24.T’->*T@MUL{OP=*,ARG2=T.VAL}
25.T’->$
26.F->(L)@VOL{F.VAL->L.VAL}
27.F->@ASS_Fnum|id{F.VAL=num|id}
28.Q->idO|$
29.O->@SINGLE_OP++|--{OP=++|--}
30.
31.3、布尔运算
32.产生式语义子程序
33.G->FDF@COMPARE{OP=D.VAL;ARG1=F(1).VAL;ARG2=F(2).VAL,RES=NEWTEMP;
34.NewfourElement(OP,F.VAL,ARG2,RES);G.VAL=RES并压入语义栈}
35.D->@COMPARE_OP<|>|==|!={D.VAL=<|>|==|!=,并压入语栈}
36.
37.4、控制语句
38.产生式语义子程序
39.B->if(G)@IF_FJ{A}@IF_BACKPATCH_FJ@IF_RJelse{A}@IF_BACKPATCH_RJ
40.@IF_FJ{OP=”FJ”;ARG1=G.VAL;RES=if_fj,NewfourElement(OP,ARG1,/,RES),将其插入到四元式列表中第i个}
41.@IF_BACKPATCH_FJ{回填前面假出口跳转四元式的跳转序号,BACKPATCH(i,if_fj)}
42.B->while(G)@WHILE_FJ{A}@WHILE_RJ@WHILE_BACKPATCH_FJ{参照ifelse}
43.B->for(YZ;G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJ{参照ifelse}
44.@SINGLE{ARG1=id;RES=NEWTEMP;NewfourElement(OP,ARG1,/,RES)}
45.
46.说明:
47.(1)、R.VAL表示符号R的值,VAL是R的一个属性,其它类似。
48.(2)、NEWTEMP()函数:每调用一次生成一个临时变量,依次为T1,T2,…Tn。
49.(3)、BACKPATCH(inti,intres):回填函数,用res回填第i个四元式的跳转地址。
50.(4)、newfourElement(StringOP,StringARG1,StringARG2,StringRES):生成一个四元式
(OP,ARG1,ARG2,RES)
于是在遇到赋值、算数运算、布尔运算、控制语句,到达可以被属性翻译文法处理时,就遵照改进后的 LL1 属性翻译文法进行,也就是它的优先级更高,步骤如下:
步骤 6)
直到各栈等状态如下:
当前语法分析栈:UZ’;BRA}#
wordList:sum=0;for(inti=1;i<11;i++){sum=sum+i;}}#
语义栈:#
于是根据优先级更高的属性翻译文法,翻译后如下步骤:
步骤 7)
当前语法分析栈:@ASS_UidU’Z’;BRA}#
wordList:sum=0;for(inti=1;i<11;i++){sum=sum+i;}}#
语义栈:#
这个@ASS_U 的作用是将要赋值的对象拷入语义栈,然后删除语法分析栈中的@ASS_U,对 wordList 无影响,运行后各栈状态如下一步骤:
步骤 8)
当前语法分析栈:idU’Z’;BRA}#
wordList:sum=0;for(inti=1;i<11;i++){sum=sum+i;}}
#语义栈:sum#
可以看到 sum 拷入语义栈
步骤 9)
上一步之后,语法分析栈中剩余的是 id,它的作用是与 wordList 中的标识符相抵消,于是处理后如下一步:
步骤 10)
当前语法分析栈:U’Z’;BRA}#
余留符号串:=0;for(inti=1;i<11;i++){sum=sum+i;}}#
语义栈:sum#
此时 U’将由属性翻译文法变为下一步骤所示;
步骤 11)
当前语法分析栈:=L@EQ_U’Z’;BRA}#
余留符号串:=0;for(inti=1;i<11;i++){sum=sum+i;}}#
语义栈:sum#
很明显,等号将抵消,但是为保险起见,将语法分析栈中 L 的翻译文法,判断这个等号之前是否存在加减乘除号,如下:
步骤 12)
当前语法分析栈:TL’@ADD_SUB@EQ_U’Z’;BRA}#
余留符号串:0;for(inti=1;i<11;i++){sum=sum+i;}}#
语义栈:sum#
这里是用于判断有无加减号的,然后下一步:
步骤 13)
当前语法分析栈:FT’@DIV_MULL’@ADD_SUB@EQ_U’Z’;BRA}#
wordList:0;for(inti=1;i<11;i++){sum=sum+i;}}#
语义栈:sum#
这里添加上了判断是否有乘除号。
为了存储要赋值给标识符的值,F 将转化为 F->@ASS_Fnum,如下:
步骤 14)
然后上一步中 wordList 中的 0 将被存入语义栈,num 与 wordList 中的数字 0 抵消,然后到下一步:
步骤 15)
语法分析栈:T’@DIV_MULL’@ADD_SUB@EQ_U’Z’;BRA}#
wordList:;for(inti=1;i<11;i++){sum=sum+i;}}#
语义栈:0sum#
此时的状态中,T’将被用于判断是否有乘除,若无,T’和@DIV_MULL 都将失效,然后进入下一步骤:
步骤 16)
语法分析栈:L’@ADD_SUB@EQ_U’Z’;BRA}#
余留符号串:;for(inti=1;i<11;i++){sum=sum+i;}}#
语义栈:0sum#
这一步中,L’将被用于判断是否有加减,若无,L’和@ADD_SUB 都将失效,然后进入下一步骤:
步骤 17)
语法分析栈:@EQ_U’Z’;BRA}#
余留符号串:;for(inti=1;i<11;i++){sum=sum+i;}}#
语义栈:0sum#
此时就可以确保无误(由于是赋值语句不是判断等语句,所以只需要判断等号前面有无加减乘除即可),下一步将将这个赋值语句生成为四元式。
步骤 18)
当前语法分析栈:@EQ_U’Z’;BRA}#
wordList:;for(inti=1;i<11;i++){sum=sum+i;}}#
语义栈:0sum#
在此状态时,将生成四元式,其中操作符是等号,第一操作数是语义栈中的当前栈顶数 0,并出栈,结果是语义栈中的当前栈顶数 sum。四元式生成完毕后,将被存入四元式集合中。此后,将一直简单判断直到 wordList 栈顶为 for
步骤 19)
此时,由于 wordList 栈顶是 for,
根据文法 B->for(YZ;G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJ
将进入如下状态:
语法分析栈:for(YZ;G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#
余留符号串:for(inti=1;i<11;i++){sum=sum+i;}}#
语义栈:#
这个针对 for 的属性翻译文法是有讲究的,可以看出
for(YZ;G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}
YZ 是之前用过的赋值语句,没什么好分析的,我们直接开始分析后面,状态如下:
步骤 20)
步骤当前语法分析栈:G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#
wordList:i<11;i++){sum=sum+i;}}#
语义栈:#
根据文法,唯一一种路径只能:G->FDF@COMPARE
然后进行下一步:
步骤 21)
分析栈:FDF@COMPARE@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#
wordList:i<11;i++){sum=sum+i;}}#
语义栈:#
根据文法,由于此时 wordList 的栈顶是 i(标识符),所以下一步:
步骤 22)
栈:@ASS_FidDF@COMPARE@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#wordList:i<11;i++){sum=sum+i;}}# 、
语义栈:#
于是和之前一样,ASS_F 用于将标识符 i 加入到语义栈,id 用于和 wordList 中的 i 相抵消,然后就是 D,D 是一个双目运算符的文法符号,用于判断==,!=,>,<。所以检测到 wordList 中是 <,将通过文法:D->@COMPARE_OP<;
步骤 23)
语法分析栈:@COMPARE_OP<F@COMPARE@FOR_FJ;Q){A@SINGLE}@FOR_RJ
@FOR_BACKPATCH_FJRA}#
余留符号串:<11;i++){sum=sum+i;}}#
语义栈:i#
此时的@COMPARE_OP 将用于把 < 入到语义栈,然后 < 相抵消,之后的 F 将用于读取数字 num1 到生成四元式,如下一步:
步骤 24)
语法分析栈:@COMPARE@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}# wordList:;i++){sum=sum+i;}}#
语义栈:11<i#
到这一步时,语法分析栈中的@COMPARE 将用于生成一个四元式,其中操作数 2 是语义栈栈顶的 11 并将其出栈,操作符是语义栈栈顶的 < 并将其出栈,操作数 1 是语义栈栈顶的 i,然后四元式的结果 result 是通过 newTemp()函数新建的一个字符串“T”+tempCount(初始为 0++);然后将这个四元式存入 fourElemList,然后在语义栈中存入 result。如下一步:
步骤 25)
当前语法分析栈:@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#
余留符号串:;i++){sum=sum+i;}}#
语义栈:T1#
此时,语法分析栈栈顶是@FOR_FJ,其作用是将上一步存入语义栈的 T1 拿出生成一个四元式:(FJ,T1,/,9),然后将之后的两个;相抵消,还有重要的作用就是将这一步生成的四元式的序号存入 Stack for_fj 也就是跳转地址栈,进入下一步:
步骤 26)
当前语法分析栈:Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#
wordList:i++){sum=sum+i;}}#
语义栈:#
这个 Q 也是文法中单独设计的,因为我们知道在 C 语言中,for 语句的一般情况下语法是 for(赋值;判断;递增递减)(没有设计更复杂的),所以 Q 将用于识别这个递增递减部分,如下一步:
步骤 27)
当前语法分析栈:@ASS_QidO){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#
余留符号串:i++){sum=sum+i;}}#
语义栈:#
可以看出,@ASS_Q 用于读取 i 到语义栈,id 用于和 i 相抵消,O 用于识别递增递减符号,其中 O 生成的@SINGLE_OP 用于将 ++ 或是—存入 Stackfor_op,后面在 SINGLE 时,再将其取出这三个 top 识别完成后,状态如下一步(不需要存入四元式,因为 for 循环中的递增不是在这个时候进行,而是在循环完成一轮时进行):
步骤 28)
当前语法分析栈:{A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#
余留符号串:{sum=sum+i;}}#
语义栈:i#
A 就不必多说了,是用于读取 sum = sum + i,唯一需要注意的是这种赋值语句,不论是自身赋值 a = a + b,还是 a = b + c,都是只需要两个四元式就可以完成,之前在 i = 1 已经使用过了。那么@SINGLE 在前面的介绍中我们也知道是用于读取之前读到 for_op 中的递增或是递减符号,如下一步。
步骤 29)
当前语法分析栈:@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#
余留符号串:}}#
语义栈:i#
这一步就完成了 i++ 的四元式化,下一步就进入到 for 循环的收尾阶段。
步骤 30)
当前语法分析栈:@FOR_RJ@FOR_BACKPATCH_FJRA}#
余留符号串:}#
语义栈:#
这里的@FOR_RJ 和@FOR_BACKPATCH_FJRA 都是为了循环完成后的回溯准备的,思路如下:
}else if(top.name.equals("@FOR_RJ")){
OP="RJ";
RES=(for_fj.peek()-1)+"";
FourElement fourElem=new FourElement(++fourElemCount,OP,"/","/",RES);
for_rj.push(fourElemCount);
fourElemList.add(fourElem);
OP=null;
analyseStack.remove(0);
}else if(top.name.equals("@FOR_BACKPATCH_FJ")){
backpatch(for_fj.pop(), fourElemCount+1);
analyseStack.remove(0);
}
*可以看出,@FOR_RJ 是用于生成四元式**(RJ,/,/,3)**的,这个 3 就来自于之前跳转地址栈 for_fj 栈存入的 for 语句判断语句存入的四元式的序号 3,但是并不出栈找这个数字 3,因为后面的@FOR_BACKPATCH 还要用到。存入了当前四元式的序号到地址栈\Stack for_rj*中,目的是为了退出循环,也是后面的@FOR_BACKPATCH 还要用到。\
步骤 31)
当前语法分析栈:@FOR_BACKPATCH_FJRA}#
余留符号串:}#
语义栈:#
根据上面的 12 行代码可知,对参数调用了 backpatch 函数,这个函数定义如下:
private void backpatch( int i, int res )
{
FourElement temp = fourElemList.get( i - 1 );
temp. result = res + "";
fourElemList.set( i - 1, temp );
}
作用很明显,就是将 for 循环的最后一个四元式序号 +1(也就是退出 for 循环后的位置)作为参数,然后其传回到 for 循环的判断开始处,更新之前的判断四元式的 result,意即当那个判断为否时,就直接退出 for 循环,来到 for 循环的下一行(退出循环)。
以上就是本语法分析器的主要作用,本报告以一个 11 行的 C 语言代码(包含赋值语句、判断语句、递减)的词法分析、语法分析、中间代码生成(四元式)的例子来进行功能、设计思想上的介绍。
语法分析中已经生成的中间代码将用于在下一步中进行目标代码(汇编语言)的生成。
3.3 目标代码生成 huibian
中间代码生成器根据语义分析器的输出生成中间代码。中间代码可以有若干种形式,它们的共同特征是与具体机器无关。最常用的一种中间代码是三地址码,它的一种实现方式是四元式,在上一部分的语法分析中,我得到的中间代码结果,也就是四元式,如下:
1.生成的四元式如下
2.序号(OP,ARG1,ARG2,RESULT)
3.1(=,0,/,sum)
4.2(=,1,/,i)
5.3(<,i,11,T1)
6.4(FJ,T1,/,9)
7.5(+,sum,i,T2)
8.6(=,T2,/,sum)
9.7(++,i,/,i)
10.8(RJ,/,/,3)
目标代码生成是编译器的最后一个阶段。在生成目标代码时要考虑以下几个问题:计算机的系统结构、指令系统、寄存器的分配以及内存的组织等。编译器生成的目标程序代码可以有多种形式:汇编语言、可重定位二进制代码、内存形式。这一步其实难度不大,有了四元式,想要生成目标代码就是简单的循环判断即可。
在验收的时候。蒋老师对我的工作给出了很高的评价,同时也指出更好的编译器最后一步汇编代码生成,应该是使用单词表,而不是使用逻辑循环来翻译。
如对上述的四元式结果,我们继续实例分析:
实例分析
步骤 1)
按照换行符进行分行,从第三行开始处理,通过逗号,进行分词,首先读取第一个逗号前的符号,如果是=,那么就判断为赋值语句,配合四元式,产生目标汇编代码为:MOV sum,0
步骤 2)
仍旧是=,赋值语句,目标代码生成为:MOV i,1
步骤 3)
四元式首个符号为 <,比较语句,目标代码生成为:CMP i,11
步骤 4)
四元式首个符号为 F,下一个符号为 J,目标代码生成为:JZ 11
(我是按照大二时学习的 8086 汇编代码来设计的,这两行代码的意思也就是比较 i 和 11,如果 11 小于 i,Less(JL)就跳转到四元式中序号 9 的位置去)
步骤 5)
四元式首个符号为 +,运算符,目标代码生成为:MOV AX,i、MOV T2,sum、ADD T2,AX
步骤 6)
四元式首个符号为=,赋值语句,目标代码生成为:MOV sum,T2
步骤 7)
四元式首个符号为 ++,递增语句,目标代码生成为:INC i
步骤 8)
四元式首个符号为 RJ,for 的回溯,目标代码生成为:JMP 3
最后目标代码结果如下:
1.生成的目标代码如下
2.序号(OP,ARG1,ARG2)
3.1MOVsum,0
4.2MOVi,1
5.3CMPi,11
6.4JL11
7.5MOVAX,i
8.6MOVT2,sum
9.7ADDT2,AX
10.8MOVsum,T2
11.9INCi
12.10JMP3
3.4 演示界面设计
演示代码的设计,由两个类组成:
主界面 MainFrame
主界面上设置三个 Panel,布局都是 BorderLayout。
然后在布局 North 加入组件 createUpPane,其中放入一些界面显示文字的控件,最主要的是浏览和确认按钮,其浏览按钮的动作函数是打开文件夹选择文件,确认按钮的动作函数是打开文件内容并且读取,然后显示在 textArea 上。
在布局 Center 加入组件 createCenterPane,其中放入一些界面显示文字的控件,最主要的是一个显示 textArea 控件,用于显示从文件中读取的源代码文件。
在布局 COUTH 加入组件 createBottomPane,其中放入四个按钮控件,分别唤醒四个子界面 InfoFeame,分别显示词法分析,语法分析,中间代码生成,目标代码生成。
子界面 InfoFrame
显示一个有 title 的子界面,将每一步(词法分析、语法分析、中间代码生成、目标代码生成)的存入路径下的结果拿出,显示到子界面的 TextArea 中。
四、设计的输入和输出形式
输入内容是一个 C 语言源代码文件 a.c,如下所示:

图 3 源代码在文件夹中的形式
内容如下,其形式是一个完整的 C 语言源代码加上一个结束符#
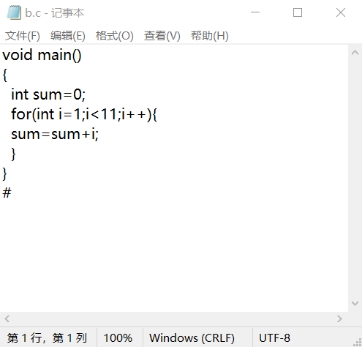
图 4 被编译的 C 语言源代码
输出内容是在路径/output/下的三个文件 wordList.txt,用于存储词法分析结果;LL1.txt,用于存储语法分析结果;FourElement.txt,用于存储四元式分析结果(中间代码)。
词法分析结果 wordList.txt 如下,其形式是五列数据,其内容分别是:单词序号、单词的值、单词类型、单词所在行、单词是否合法。
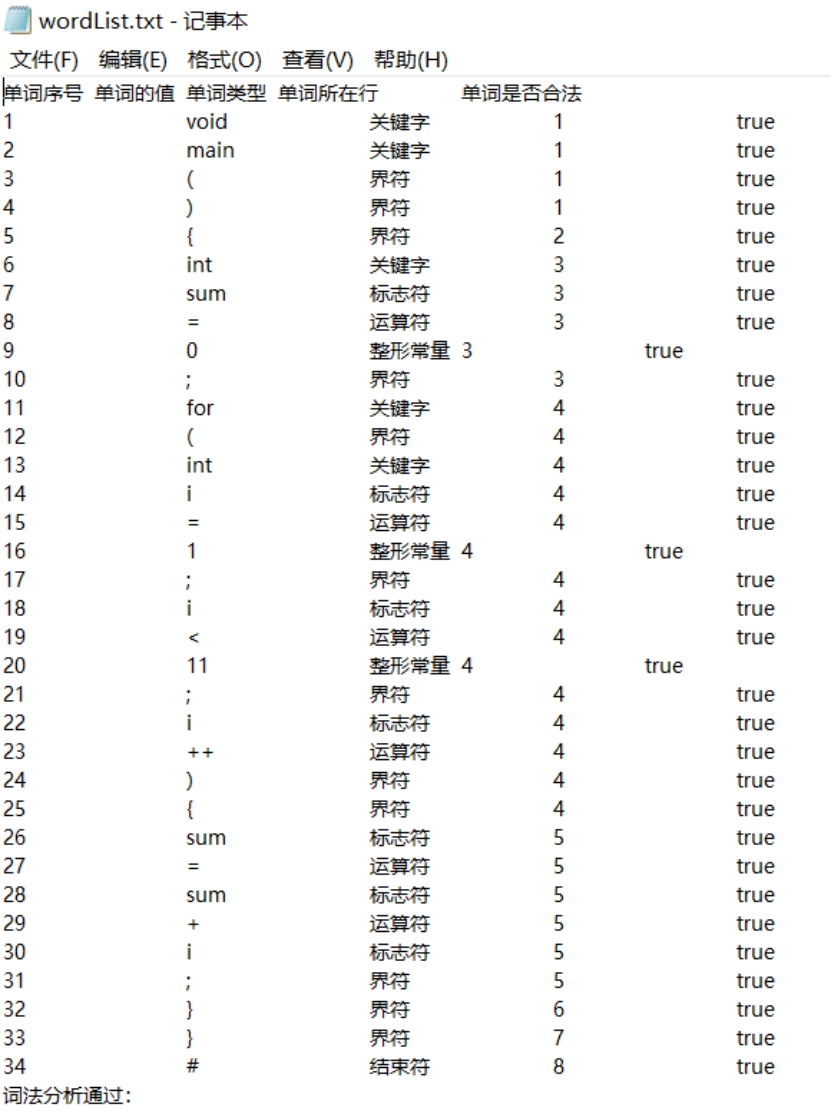
图 5 词法分析结果文件
语法分析结果 LL1.txt 如下,其形式是:步骤及序号、当前语法分析栈的内容(对应文法)、余留符号串(也就是 wordList 中的单词集合)、语义栈(用于生成
四元式)。

图 6 语法分析结果文件
四元式分析结果 FourElement.txt 如下,其形式是:四元式序号、四元式操作符、四元式操作数 1、四元式操作数 2、四元式结果。

五、程序运行的结果
为了充分展示设计到的 C 语言语法,此处我们选择一个相对较为复杂,包含赋值,循环,判断,递增,四则运算等的的源代码作为输入,也就是 a.c,作为我的程序运行测试的样例。运行程序,初始界面如下:
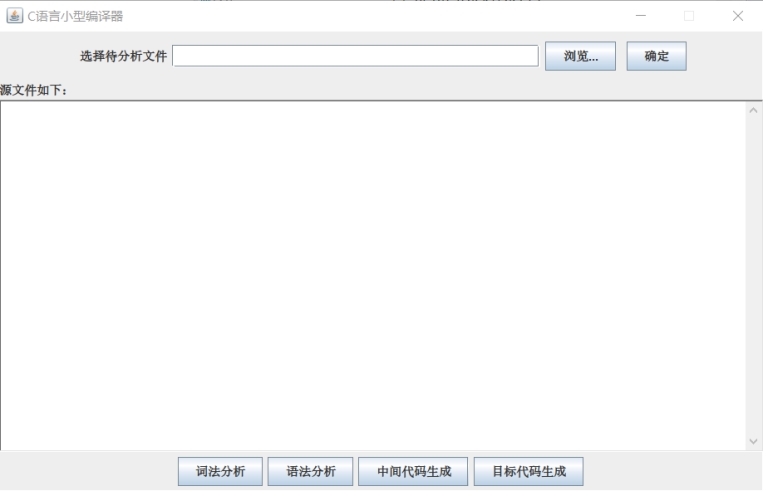
图 8 程序运行初始界面
点击“浏览…”按钮,可以选择要编译的 C 语言文件,界面如下:
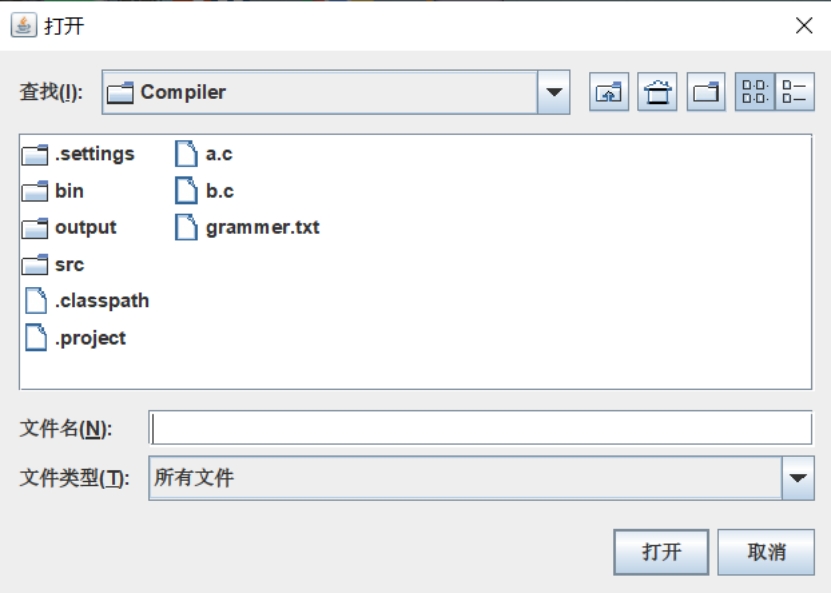
图 9 打开文件夹选择.c 文件功能界面
选择好之后源代码文件 b.c 之后,该文件路径将显示在 text 中。
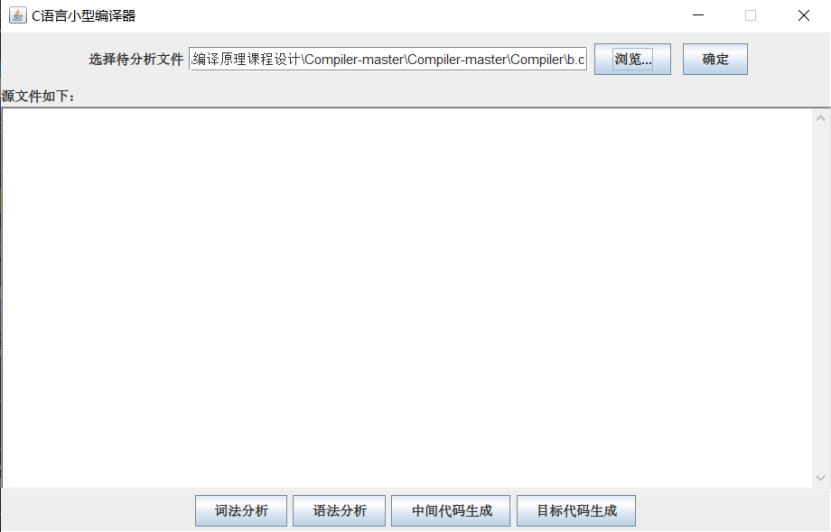
图 10 选择好.c 文件后界面
然后点击按钮“确定”,就可以将文件显示在下面的 textArea 中,如下所示:
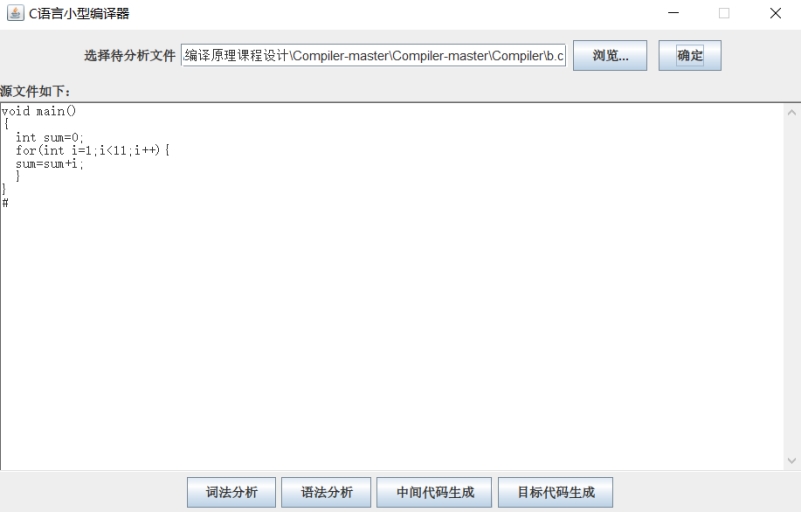
图 11 源程序展示界面
然后点击“词法分析”按钮,就会弹出子界面,里面是词法分析的结果:
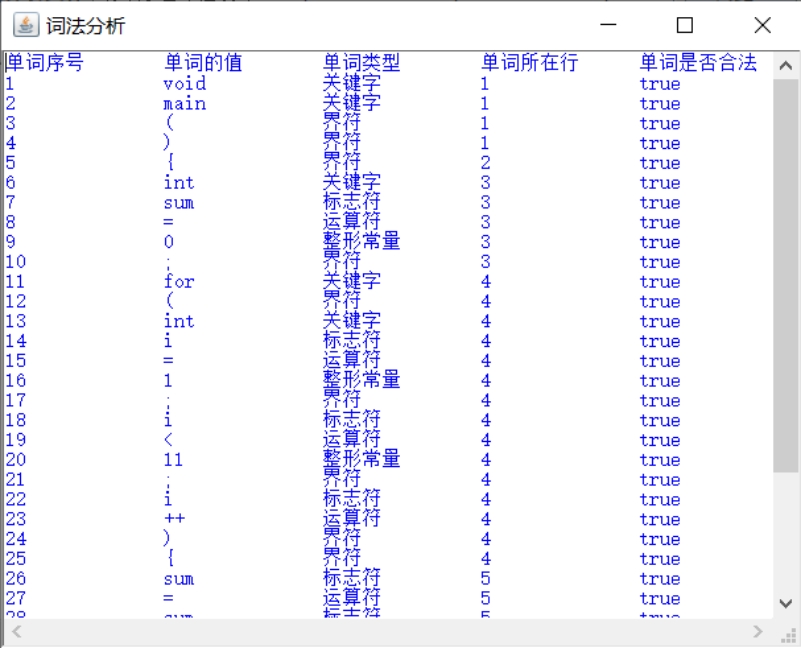
图 12 词法分析结果界面
然后点击“语法分析”按钮,就会弹出子界面,里面是语法分析的结果:
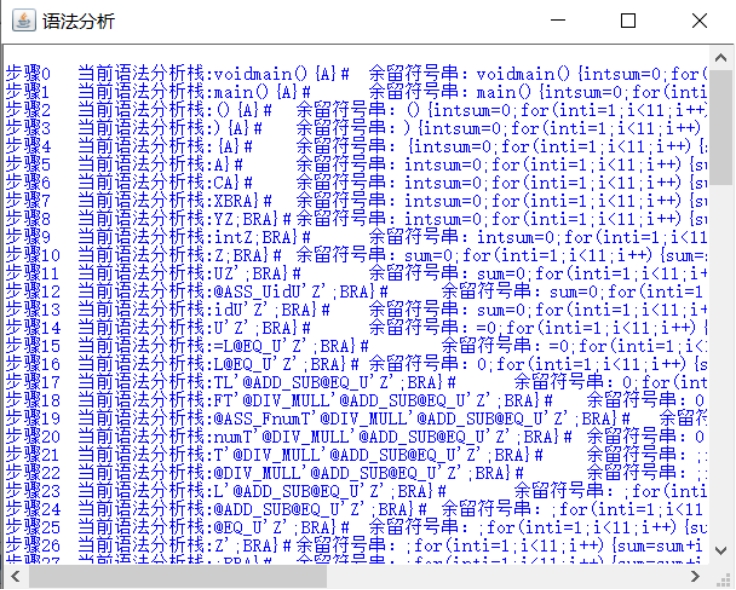
图 13 语法分析结果界面
然后点击“中间代码生成”按钮,就会弹出子界面,里面是四元式分析结果:
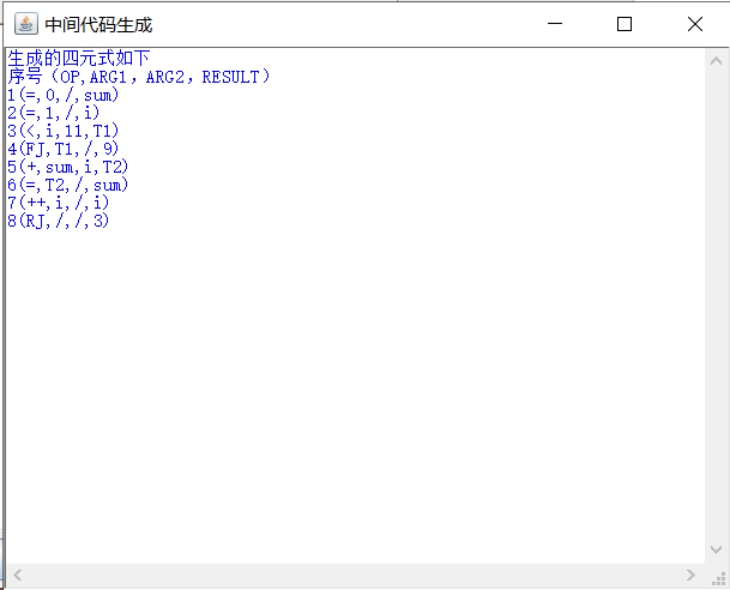
图 14 中间代码四元式分析结果界面
然后点击目标代码生成,就会弹出子界面,里面是目标代码(汇编语言):
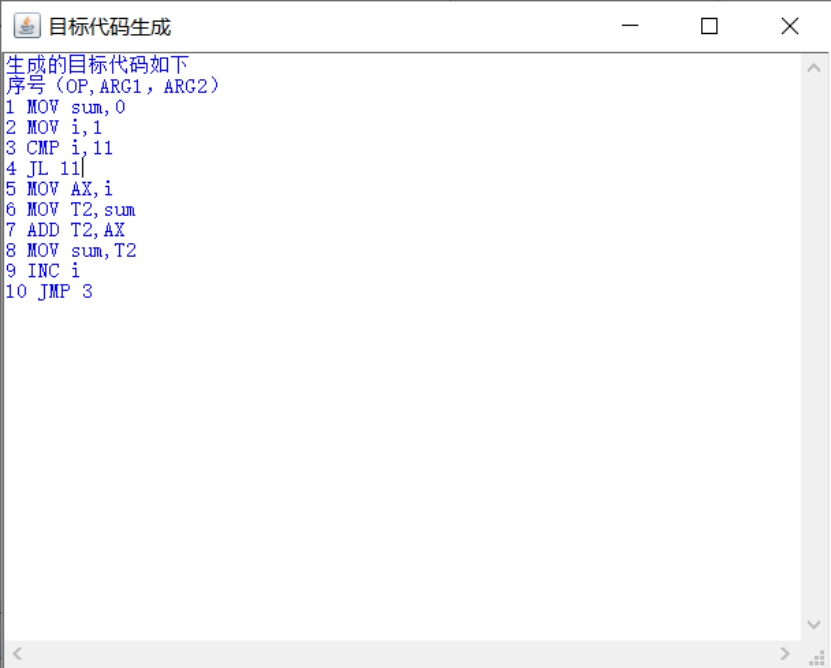
图 15 目标代码生成
界面
至此,所有界面都已展示完毕,下面安装课设要求,拷贝结果的打印输出:
源文件 a.c:
1.voidmain()
2.{
3.intsum=0;
4.for(inti=1;i<11;i++){
5.sum=sum+i;
6.}
7.}
8.#
词法分析结果:
1.单词序号单词的值单词类型单词所在行单词是否合法
2.1void关键字1true
3.2main关键字1true
4.3(界符1true
5.4)界符1true
6.5{界符2true
7.6int关键字3true
8.7sum标志符3true
9.8=运算符3true
10.90整形常量3true
11.10;界符3true
12.11for关键字4true
13.12(界符4true
14.13int关键字4true
15.14i标志符4true
16.15=运算符4true
17.161整形常量4true
18.17;界符4true
19.18i标志符4true
20.19<运算符4true
21.2011整形常量4true
22.21;界符4true
23.22i标志符4true
24.23++运算符4true
25.24)界符4true
26.25{界符4true
27.26sum标志符5true
28.27=运算符5true
29.28sum标志符5true
30.29+运算符5true
31.30i标志符5true
32.31;界符5true
33.32}界符6true
34.33}界符7true
35.34#结束符8true
36.词法分析通过:
语法分析结果:
1.步骤0当前语法分析栈:voidmain(){A}#余留符号串:voidmain(){intsum=0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
2.步骤1当前语法分析栈:main(){A}#余留符号串:main(){intsum=0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
3.步骤2当前语法分析栈:(){A}#余留符号串:(){intsum=0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
4.步骤3当前语法分析栈:){A}#余留符号串:){intsum=0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
5.步骤4当前语法分析栈:{A}#余留符号串:{intsum=0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
6.步骤5当前语法分析栈:A}#余留符号串:intsum=0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
7.步骤6当前语法分析栈:CA}#余留符号串:intsum=0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
8.步骤7当前语法分析栈:XBRA}#余留符号串:intsum=0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
9.步骤8当前语法分析栈:YZ;BRA}#余留符号串:intsum=0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
10.步骤9当前语法分析栈:intZ;BRA}#余留符号串:intsum=0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
11.步骤10当前语法分析栈:Z;BRA}#余留符号串:sum=0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
12.步骤11当前语法分析栈:UZ';BRA}#余留符号串:sum=0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
13.步骤12当前语法分析栈:@ASS_UidU'Z';BRA}#余留符号串:sum=0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
14.步骤13当前语法分析栈:idU'Z';BRA}#余留符号串:sum=0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:sum#
15.步骤14当前语法分析栈:U'Z';BRA}#余留符号串:=0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:sum#
16.步骤15当前语法分析栈:=L@EQ_U'Z';BRA}#余留符号串:=0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:sum#
17.步骤16当前语法分析栈:L@EQ_U'Z';BRA}#余留符号串:0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:sum#
18.步骤17当前语法分析栈:TL'@ADD_SUB@EQ_U'Z';BRA}#余留符号串:0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:sum#
19.步骤18当前语法分析栈:FT'@DIV_MULL'@ADD_SUB@EQ_U'Z';BRA}#余留符号串:0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:sum#
20.步骤19当前语法分析栈:@ASS_FnumT'@DIV_MULL'@ADD_SUB@EQ_U'Z';BRA}#余留符号串:0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:sum#
21.步骤20当前语法分析栈:numT'@DIV_MULL'@ADD_SUB@EQ_U'Z';BRA}#余留符号串:0;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:0sum#
22.步骤21当前语法分析栈:T'@DIV_MULL'@ADD_SUB@EQ_U'Z';BRA}#余留符号串:;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:0sum#
23.步骤22当前语法分析栈:@DIV_MULL'@ADD_SUB@EQ_U'Z';BRA}#余留符号串:;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:0sum#
24.步骤23当前语法分析栈:L'@ADD_SUB@EQ_U'Z';BRA}#余留符号串:;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:0sum#
25.步骤24当前语法分析栈:@ADD_SUB@EQ_U'Z';BRA}#余留符号串:;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:0sum#
26.步骤25当前语法分析栈:@EQ_U'Z';BRA}#余留符号串:;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:0sum#
27.步骤26当前语法分析栈:Z';BRA}#余留符号串:;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
28.步骤27当前语法分析栈:;BRA}#余留符号串:;for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
29.步骤28当前语法分析栈:BRA}#余留符号串:for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
30.步骤29当前语法分析栈:for(YZ;G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:for(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
31.步骤30当前语法分析栈:(YZ;G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:(inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
32.步骤31当前语法分析栈:YZ;G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
33.步骤32当前语法分析栈:intZ;G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:inti=1;i<11;i++){sum=sum+i;}}#语义栈:#
34.步骤33当前语法分析栈:Z;G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:i=1;i<11;i++){sum=sum+i;}}#语义栈:#
35.步骤34当前语法分析栈:UZ';G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:i=1;i<11;i++){sum=sum+i;}}#语义栈:#
36.步骤35当前语法分析栈:@ASS_UidU'Z';G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:i=1;i<11;i++){sum=sum+i;}}#语义栈:#
37.步骤36当前语法分析栈:idU'Z';G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:i=1;i<11;i++){sum=sum+i;}}#语义栈:i#
38.步骤37当前语法分析栈:U'Z';G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:=1;i<11;i++){sum=sum+i;}}#语义栈:i#
39.步骤38当前语法分析栈:=L@EQ_U'Z';G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:=1;i<11;i++){sum=sum+i;}}#语义栈:i#
40.步骤39当前语法分析栈:L@EQ_U'Z';G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:1;i<11;i++){sum=sum+i;}}#语义栈:i#
41.步骤40当前语法分析栈:TL'@ADD_SUB@EQ_U'Z';G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:1;i<11;i++){sum=sum+i;}}#语义栈:i#
42.步骤41当前语法分析栈:FT'@DIV_MULL'@ADD_SUB@EQ_U'Z';G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:1;i<11;i++){sum=sum+i;}}#语义栈:i#
43.步骤42当前语法分析栈:@ASS_FnumT'@DIV_MULL'@ADD_SUB@EQ_U'Z';G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:1;i<11;i++){sum=sum+i;}}#语义栈:i#
44.步骤43当前语法分析栈:numT'@DIV_MULL'@ADD_SUB@EQ_U'Z';G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:1;i<11;i++){sum=sum+i;}}#语义栈:1i#
45.步骤44当前语法分析栈:T'@DIV_MULL'@ADD_SUB@EQ_U'Z';G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;i<11;i++){sum=sum+i;}}#语义栈:1i#
46.步骤45当前语法分析栈:@DIV_MULL'@ADD_SUB@EQ_U'Z';G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;i<11;i++){sum=sum+i;}}#语义栈:1i#
47.步骤46当前语法分析栈:L'@ADD_SUB@EQ_U'Z';G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;i<11;i++){sum=sum+i;}}#语义栈:1i#
48.步骤47当前语法分析栈:@ADD_SUB@EQ_U'Z';G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;i<11;i++){sum=sum+i;}}#语义栈:1i#
49.步骤48当前语法分析栈:@EQ_U'Z';G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;i<11;i++){sum=sum+i;}}#语义栈:1i#
50.步骤49当前语法分析栈:Z';G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;i<11;i++){sum=sum+i;}}#语义栈:#
51.步骤50当前语法分析栈:;G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;i<11;i++){sum=sum+i;}}#语义栈:#
52.步骤51当前语法分析栈:G@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:i<11;i++){sum=sum+i;}}#语义栈:#
53.步骤52当前语法分析栈:FDF@COMPARE@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:i<11;i++){sum=sum+i;}}#语义栈:#
54.步骤53当前语法分析栈:@ASS_FidDF@COMPARE@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:i<11;i++){sum=sum+i;}}#语义栈:#
55.步骤54当前语法分析栈:idDF@COMPARE@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:i<11;i++){sum=sum+i;}}#语义栈:i#
56.步骤55当前语法分析栈:DF@COMPARE@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:<11;i++){sum=sum+i;}}#语义栈:i#
57.步骤56当前语法分析栈:@COMPARE_OP<F@COMPARE@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:<11;i++){sum=sum+i;}}#语义栈:i#
58.步骤57当前语法分析栈:<F@COMPARE@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:<11;i++){sum=sum+i;}}#语义栈:<i#
59.步骤58当前语法分析栈:F@COMPARE@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:11;i++){sum=sum+i;}}#语义栈:<i#
60.步骤59当前语法分析栈:@ASS_Fnum@COMPARE@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:11;i++){sum=sum+i;}}#语义栈:<i#
61.步骤60当前语法分析栈:num@COMPARE@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:11;i++){sum=sum+i;}}#语义栈:11<i#
62.步骤61当前语法分析栈:@COMPARE@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;i++){sum=sum+i;}}#语义栈:11<i#
63.步骤62当前语法分析栈:@FOR_FJ;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;i++){sum=sum+i;}}#语义栈:T1#
64.步骤63当前语法分析栈:;Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;i++){sum=sum+i;}}#语义栈:#
65.步骤64当前语法分析栈:Q){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:i++){sum=sum+i;}}#语义栈:#
66.步骤65当前语法分析栈:@ASS_QidO){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:i++){sum=sum+i;}}#语义栈:#
67.步骤66当前语法分析栈:idO){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:i++){sum=sum+i;}}#语义栈:i#
68.步骤67当前语法分析栈:O){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:++){sum=sum+i;}}#语义栈:i#
69.步骤68当前语法分析栈:@SINGLE_OP++){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:++){sum=sum+i;}}#语义栈:i#
70.步骤69当前语法分析栈:++){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:++){sum=sum+i;}}#语义栈:i#
71.步骤70当前语法分析栈:){A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:){sum=sum+i;}}#语义栈:i#
72.步骤71当前语法分析栈:{A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:{sum=sum+i;}}#语义栈:i#
73.步骤72当前语法分析栈:A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:sum=sum+i;}}#语义栈:i#
74.步骤73当前语法分析栈:CA@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:sum=sum+i;}}#语义栈:i#
75.步骤74当前语法分析栈:XBRA@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:sum=sum+i;}}#语义栈:i#
76.步骤75当前语法分析栈:BRA@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:sum=sum+i;}}#语义栈:i#
77.步骤76当前语法分析栈:RA@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:sum=sum+i;}}#语义栈:i#
78.步骤77当前语法分析栈:@ASS_Rid=L@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:sum=sum+i;}}#语义栈:i#
79.步骤78当前语法分析栈:id=L@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:sum=sum+i;}}#语义栈:sumi#
80.步骤79当前语法分析栈:=L@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:=sum+i;}}#语义栈:sumi#
81.步骤80当前语法分析栈:L@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:sum+i;}}#语义栈:sumi#
82.步骤81当前语法分析栈:TL'@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:sum+i;}}#语义栈:sumi#
83.步骤82当前语法分析栈:FT'@DIV_MULL'@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:sum+i;}}#语义栈:sumi#
84.步骤83当前语法分析栈:@ASS_FidT'@DIV_MULL'@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:sum+i;}}#语义栈:sumi#
85.步骤84当前语法分析栈:idT'@DIV_MULL'@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:sum+i;}}#语义栈:sumsumi#
86.步骤85当前语法分析栈:T'@DIV_MULL'@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:+i;}}#语义栈:sumsumi#
87.步骤86当前语法分析栈:@DIV_MULL'@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:+i;}}#语义栈:sumsumi#
88.步骤87当前语法分析栈:L'@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:+i;}}#语义栈:sumsumi#
89.步骤88当前语法分析栈:+L@ADD@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:+i;}}#语义栈:sumsumi#
90.步骤89当前语法分析栈:L@ADD@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:i;}}#语义栈:sumsumi#
91.步骤90当前语法分析栈:TL'@ADD_SUB@ADD@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:i;}}#语义栈:sumsumi#
92.步骤91当前语法分析栈:FT'@DIV_MULL'@ADD_SUB@ADD@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:i;}}#语义栈:sumsumi#
93.步骤92当前语法分析栈:@ASS_FidT'@DIV_MULL'@ADD_SUB@ADD@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:i;}}#语义栈:sumsumi#
94.步骤93当前语法分析栈:idT'@DIV_MULL'@ADD_SUB@ADD@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:i;}}#语义栈:isumsumi#
95.步骤94当前语法分析栈:T'@DIV_MULL'@ADD_SUB@ADD@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;}}#语义栈:isumsumi#
96.步骤95当前语法分析栈:@DIV_MULL'@ADD_SUB@ADD@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;}}#语义栈:isumsumi#
97.步骤96当前语法分析栈:L'@ADD_SUB@ADD@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;}}#语义栈:isumsumi#
98.步骤97当前语法分析栈:@ADD_SUB@ADD@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;}}#语义栈:isumsumi#
99.步骤98当前语法分析栈:@ADD@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;}}#语义栈:isumsumi#
100.步骤99当前语法分析栈:@ADD_SUB@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;}}#语义栈:isumsumi#
101.步骤100当前语法分析栈:@EQ;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;}}#语义栈:T2sumi#
102.步骤101当前语法分析栈:;A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:;}}#语义栈:i#
103.步骤102当前语法分析栈:A@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:}}#语义栈:i#
104.步骤103当前语法分析栈:@SINGLE}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:}}#语义栈:i#
105.步骤104当前语法分析栈:}@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:}}#语义栈:#
106.步骤105当前语法分析栈:@FOR_RJ@FOR_BACKPATCH_FJRA}#余留符号串:}#语义栈:#
107.步骤106当前语法分析栈:@FOR_BACKPATCH_FJRA}#余留符号串:}#语义栈:#
108.步骤107当前语法分析栈:RA}#余留符号串:}#语义栈:#
109.步骤108当前语法分析栈:A}#余留符号串:}#语义栈:#
110.步骤109当前语法分析栈:}#余留符号串:}#语义栈:#
111.步骤110当前语法分析栈:#余留符号串:#语义栈:#
112.步骤111
113.当前语法分析栈:余留符号串:语义栈:#
114.语法分析通过:
中间代码生成结果:
1.生成的四元式如下
2.序号(OP,ARG1,ARG2,RESULT)
3.1(=,0,/,sum)
4.2(=,1,/,i)
5.3(<,i,11,T1)
6.4(FJ,T1,/,9)
7.5(+,sum,i,T2)
8.6(=,T2,/,sum)
9.7(++,i,/,i)
10.8(RJ,/,/,3)
目标代码生成结果:
1.生成的目标代码如下
2.序号(OP,ARG1,ARG2)
3.1MOVsum,0
4.2MOVi,1
5.3CMPi,11
6.4JL11
7.5MOVAX,i
8.6MOVT2,sum
9.7ADDT2,AX
10.8MOVsum,T2
11.9INCi
12.10JMP3
源程序清单
Word.java
package compiler;
import java.util.ArrayList;
import compiler.LexAnalyse;
/**
* 单词类
*
* @author Administrator 1、单词序号 2、单词的值 3、单词类型 4、单词所在行 5、单词是否合法
*/
public class Word {
public final static String KEY = "关键字";
public final static String OPERATOR = "运算符";
public final static String INT_CONST = "整形常量";
public final static String CHAR_CONST = "字符常量";
public final static String BOOL_CONST = "布尔常量";
public final static String IDENTIFIER = "标志符";
public final static String BOUNDARYSIGN = "界符";
public final static String END = "结束符";
public final static String UNIDEF = "未知类型";
public static ArrayList<String> key = new ArrayList<String>();// 关键字集合
public static ArrayList<String> boundarySign = new ArrayList<String>();// 界符集合
public static ArrayList<String> operator = new ArrayList<String>();// 运算符集合
static {
Word.operator.add("+");
Word.operator.add("-");
Word.operator.add("++");
Word.operator.add("--");
Word.operator.add("*");
Word.operator.add("/");
Word.operator.add(">");
Word.operator.add("<");
Word.operator.add(">=");
Word.operator.add("<=");
Word.operator.add("==");
Word.operator.add("!=");
Word.operator.add("=");
Word.operator.add("&&");
Word.operator.add("||");
Word.operator.add("!");
Word.operator.add(".");
Word.operator.add("?");
Word.operator.add("|");
Word.operator.add("&");
Word.boundarySign.add("(");
Word.boundarySign.add(")");
Word.boundarySign.add("{");
Word.boundarySign.add("}");
Word.boundarySign.add(";");
Word.boundarySign.add(",");
Word.key.add("void");
Word.key.add("main");
Word.key.add("int");
Word.key.add("char");
Word.key.add("if");
Word.key.add("else");
Word.key.add("while");
Word.key.add("for");
Word.key.add("printf");
Word.key.add("scanf");
}
int id;// 单词序号
String value;// 单词的值
String type;// 单词类型
int line;// 单词所在行
boolean flag = true;//单词是否合法
public Word() {
}
public Word(int id, String value, String type, int line) {
this.id = id;
this.value = value;
this.type = type;
this.line = line;
}
public static boolean isKey(String word) {
return key.contains(word);
}
public static boolean isOperator(String word) {
return operator.contains(word);
}
public static boolean isBoundarySign(String word) {
return boundarySign.contains(word);
}
public static boolean isArOP(String word) {// 判断单词是否为算术运算符
if ((word.equals("+") || word.equals("-") || word.equals("*") || word
.equals("/")))
return true;
else
return false;
}
public static boolean isBoolOP(String word) {// 判断单词是否为布尔运算符
if ((word.equals(">") || word.equals("<") || word.equals("==")
|| word.equals("!=") || word.equals("!") || word.equals("&&") || word
.equals("||")))
return true;
else
return false;
}
}
Error.java
package compiler;
public class Error {
int id ;//错误序号;
String info;//错误信息;
int line ;//错误所在行
Word word;//错误的单词
public Error(){
}
public Error(int id,String info,int line,Word word){
this.id=id;
this.info=info;
this.line=line;
this.word=word;
}
}
LexAnalyse.java
package compiler;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.util.ArrayList;
/**
* 词法分析器
*
*
*/
public class LexAnalyse {
ArrayList<Word> wordList = new ArrayList<Word>();//单词表
ArrayList<Error> errorList = new ArrayList<Error>();//错误信息列表
int wordCount = 0;// 统计单词个数
int errorCount = 0;// 统计错误个数
boolean noteFlag = false;// 多行注释标志
boolean lexErrorFlag = false;// 词法分析出错标志
public LexAnalyse() {
}
public LexAnalyse(String str) {
lexAnalyse(str);
}
/*以下方法是
1)为了确定初始位 便于继续while
2)判断while得到的word属于Word类中的哪一种type
*/
/**
* 单个字符 判断是否为数字
*
* @param
* @return
*/
private static boolean isDigit(char ch) {
boolean flag = false;
if ('0' <= ch && ch <= '9')
flag = true;
return flag;
}
/**
* 字符串 判断是否为数字int
*
* @param string
* @return
*/
private static boolean isInteger(String word) {
int i;
boolean flag = false;
for (i = 0; i < word.length(); i++) {
if (Character.isDigit(word.charAt(i))) {
continue;
} else {
break;
}
}
if (i == word.length()) {
flag = true;
}
return flag;
}
/**
* 字符串 判断是否都是\char\
* @param
* @return
*/
private static boolean isChar(String word) {
boolean flag = false;
int i = 0;
char temp = word.charAt(i);
if (temp == '\'') {
for (i = 1; i < word.length(); i++) {
temp = word.charAt(i);
if (0 <= temp && temp <= 255)
continue;
else
break;
}
if (i + 1 == word.length() && word.charAt(i) == '\'')
flag = true;
} else
return flag;
return flag;
}
/**
* 字符 判断是否为字母
*
* @param ch
* @return
*/
private static boolean isLetter(char ch) {
boolean flag = false;
if (('a' <= ch && ch <= 'z') || ('A' <= ch && ch <= 'Z'))
flag = true;
return flag;
}
/**
* 字符串 判断是否为合法标识符ID
*
* @param
* @return
*/
private static boolean isID(String word) {
boolean flag = false;
int i = 0;
if (Word.isKey(word))
return flag;
char temp = word.charAt(i);
if (isLetter(temp) || temp == '_') {//字母或是_开头
for (i = 1; i < word.length(); i++) {
temp = word.charAt(i);
if (isLetter(temp) || temp == '_' || isDigit(temp))//只含有字母、_、数字
continue;
else
break;
}
if (i >= word.length())
flag = true;
} else
return flag;
return flag;
}
/**
* 判断词法分析是否出错了
*
*/
public boolean isFail() {
return lexErrorFlag;
}
public void analyse(String str, int line) {//str都是处理掉空白符号的 按行处理
int beginIndex;
int endIndex;
int index = 0;
int length = str.length();
Word word = null;
Error error;
// boolean flag=false;
char temp;
while (index < length) {//
temp = str.charAt(index);
if (!noteFlag) {//不是多行注释
if (isLetter(temp) || temp == '_') {//如果是字母或者_开头,就判断是不是标志符
beginIndex = index; //初始为 0
index++;
// temp=str.charAt(index);
while ((index < length)//while循环 直到出现&&中的各种情况
&& (!Word.isBoundarySign(str.substring(index,index + 1)))//看开头除外的后面的 从beginIndex开始取,到endIndex结束,从0开始数,其中不包括endIndex位置的字符
&& (!Word.isOperator(str.substring(index, index + 1)))
&& (str.charAt(index) != ' ')
&& (str.charAt(index) != '\t')
&& (str.charAt(index) != '\r')
&& (str.charAt(index) != '\n'))
{
index++;
}
endIndex = index;
word = new Word();
wordCount++;
word.id = wordCount;
word.line = line;//按行处理
word.value = str.substring(beginIndex, endIndex);//把刚刚while得到的词存入wordList
if (Word.isKey(word.value)) {
word.type = Word.KEY;
} else if (isID(word.value)) {
word.type = Word.IDENTIFIER;
} else {//如果上述都不是,那就是一个非法标识符
word.type = Word.UNIDEF;
word.flag = false;
errorCount++;
error = new Error(errorCount, "非法标识符", word.line, word);
errorList.add(error);
lexErrorFlag = true;
}
index--;//
} else if (isDigit(temp)) {//如果初始位是数字 判断是不是int常数
beginIndex = index;
index++;
while ((index < length)
&& (!Word.isBoundarySign(str.substring(index,index + 1)))
&& (!Word.isOperator(str.substring(index, index + 1)))
&& (str.charAt(index) != ' ')
&& (str.charAt(index) != '\t')
&& (str.charAt(index) != '\r')
&& (str.charAt(index) != '\n'))
{
index++;
}
endIndex = index;
word = new Word();
wordCount++;//lexAnalyse中的全局变量
word.id = wordCount;
word.line = line;
word.value = str.substring(beginIndex, endIndex);
if (isInteger(word.value)) {
word.type = Word.INT_CONST;
} else {
word.type = Word.UNIDEF;
word.flag = false;//应该是用来标识不是错误符
errorCount++;
error = new Error(errorCount, "非法标识符", word.line, word);
errorList.add(error);
lexErrorFlag = true;
}
index--;
} else if (String.valueOf(str.charAt(index)).equals("'")) {//当第一个是字符是'时 字符常量
//flag=true;
beginIndex = index;
index++;
temp = str.charAt(index);
while (index < length && (0 <= temp && temp <= 255)) {
if (String.valueOf(str.charAt(index)).equals("'"))//直到读到'
break;
index++;
// temp=str.charAt(index);
}
if (index < length) {
endIndex = index;
word = new Word();
wordCount++;
word.id = wordCount;
word.line = line;
word.value = str.substring(beginIndex, endIndex);
word.type = Word.CHAR_CONST;
// flag=true;
// word.flag=flag;
index--;
} else {
endIndex = index;
word = new Word();
wordCount++;
word.id = wordCount;
word.line = line;
word.value = str.substring(beginIndex, endIndex);
word.type = Word.UNIDEF;
word.flag = false;
errorCount++;
error = new Error(errorCount, "非法标识符", word.line, word);
errorList.add(error);
lexErrorFlag = true;
index--;
}
} else if (temp == '=') {//当第一个字符是 = 时 就往后再来一个 看是 = 还是 ==
beginIndex = index;
index++;
if (index < length && str.charAt(index) == '=') {
endIndex = index + 1;
word = new Word();
wordCount++;
word.id = wordCount;
word.line = line;
word.value = str.substring(beginIndex, endIndex);
word.type = Word.OPERATOR;
} else {
// endIndex=index;
word = new Word();
wordCount++;
word.id = wordCount;
word.line = line;
word.value = str.substring(index - 1, index);
word.type = Word.OPERATOR;
index--;
}
} else if (temp == '!') {//当第一个字符是 ! 就往后再来一个看是 ! 还是 !=
beginIndex = index;
index++;
if (index < length && str.charAt(index) == '=') {
endIndex = index + 1;
word = new Word();
wordCount++;
word.id = wordCount;
word.line = line;
word.value = str.substring(beginIndex, endIndex);
word.type = Word.OPERATOR;
index++;
} else {
// endIndex=index;
word = new Word();
wordCount++;
word.id = wordCount;
word.line = line;
word.value = str.substring(index - 1, index);
word.type = Word.OPERATOR;
index--;
}
} else if (temp == '&') {//当第一个字符是 & 就往后再来一个看是 & 还是 &&
beginIndex = index;
index++;
if (index < length && str.charAt(index) == '&') {
endIndex = index + 1;
word = new Word();
wordCount++;
word.id = wordCount;
word.line = line;
word.value = str.substring(beginIndex, endIndex);
word.type = Word.OPERATOR;
} else {
// endIndex=index;
word = new Word();
wordCount++;
word.id = wordCount;
word.line = line;
word.value = str.substring(index - 1, index);
word.type = Word.OPERATOR;
index--;
}
} else if (temp == '|') {//当第一个字符是 | 就往后再来一个看是 | 还是 ||
beginIndex = index;
index++;
if (index < length && str.charAt(index) == '|') {
endIndex = index + 1;
word = new Word();
wordCount++;
word.id = wordCount;
word.line = line;
word.value = str.substring(beginIndex, endIndex);
word.type = Word.OPERATOR;
} else {
// endIndex=index;
word = new Word();
wordCount++;
word.id = wordCount;
word.line = line;
word.value = str.substring(index - 1, index);
word.type = Word.OPERATOR;
index--;
}
} else if (temp == '+') {//当第一个字符是 + 就往后再来一个看是 + 还是 ++
beginIndex = index;
index++;
if (index < length && str.charAt(index) == '+') {
endIndex = index + 1;
word = new Word();
wordCount++;
word.id = wordCount;
word.line = line;
word.value = str.substring(beginIndex, endIndex);
word.type = Word.OPERATOR;
} else {
// endIndex=index;
word = new Word();
wordCount++;
word.id = wordCount;
word.line = line;
word.value = str.substring(index - 1, index);
word.type = Word.OPERATOR;
index--;
}
} else if (temp == '-') {//当第一个字符是 - 就往后再来一个看是 - 还是 --
beginIndex = index;
index++;
if (index < length && str.charAt(index) == '-') {
endIndex = index + 1;
word = new Word();
wordCount++;
word.id = wordCount;
word.line = line;
word.value = str.substring(beginIndex, endIndex);
word.type = Word.OPERATOR;
} else {
// endIndex=index;
word = new Word();
wordCount++;
word.id = wordCount;
word.line = line;
word.value = str.substring(index - 1, index);
word.type = Word.OPERATOR;
index--;
}
} else if (temp == '/') {//当第一个字符是 / 就往后再来一个看是 / 还是 /* 还是//
index++;
if (index < length && str.charAt(index) == '/')
break;//单行注释就不加了 直接跳出这一行 因为 单行注释只能在这一行的最后出现 反正也不需要编译
/*
* { index++; while(str.charAt(index)!='\n'){ index++; } }
*/
else if (index < length && str.charAt(index) == '*') {//如果是多行注释
noteFlag = true;
} else {//只是单纯的除法
word = new Word();
wordCount++;
word.id = wordCount;
word.line = line;
word.value = str.substring(index - 1, index);
word.type = Word.OPERATOR;
}
index--;
} else {// 不是标识符、数字常量、字符串常量
switch (temp) {
case ' ':
case '\t':
case '\r':
case '\n':
word = null;
break;// 过滤空白字符
case '[':
case ']':
case '(':
case ')':
case '{':
case '}':
case ',':
case '"':
case '.':
case ';':
// case '+':
// case '-':
case '*':
// case '/':
case '%':
case '>':
case '<':
case '?':
case '#':
word = new Word();
word.id = ++wordCount;
word.line = line;
word.value = String.valueOf(temp);
if (Word.isOperator(word.value))
word.type = Word.OPERATOR;
else if (Word.isBoundarySign(word.value))
word.type = Word.BOUNDARYSIGN;
else
word.type = Word.END;
break;
default://没考虑到的非法标识符
word = new Word();
wordCount++;
word.id = wordCount;
word.line = line;
word.value = String.valueOf(temp);
word.type = Word.UNIDEF;
word.flag = false;
errorCount++;
error = new Error(errorCount, "非法标识符", word.line, word);
errorList.add(error);
lexErrorFlag = true;
}
}
} else {//如果前面发现了/* 也就是多行注释 那么通过indexOf找到多行注释的结尾 把注释跳过
int i = str.indexOf("*/");
if (i != -1) {
noteFlag = false;
index = i + 2;
continue;
} else
break;
}
if (word == null) {
index++;
continue;
}
wordList.add(word);
index++;
}
}
public ArrayList<Word> lexAnalyse(String str) {
String buffer[];
buffer = str.split("\n");
int line = 1;
for (int i = 0; i < buffer.length; i++) {
analyse(buffer[i].trim(), line);
line++;
}
if (!wordList.get(wordList.size() - 1).type.equals(Word.END)) {
Word word = new Word(++wordCount, "#", Word.END, line++);
wordList.add(word);
}
return wordList;
}
public ArrayList<Word> lexAnalyse1(String filePath) throws IOException {
FileInputStream fis = new FileInputStream(filePath);
BufferedInputStream bis = new BufferedInputStream(fis);
InputStreamReader isr = new InputStreamReader(bis, "utf-8");
BufferedReader inbr = new BufferedReader(isr);
String str = "";
int line = 1;
while ((str = inbr.readLine()) != null) {
// System.out.println(str);
analyse(str.trim(), line);
line++;
}
inbr.close();
if (!wordList.get(wordList.size() - 1).type.equals(Word.END)) {
Word word = new Word(++wordCount, "#", Word.END, line++);
wordList.add(word);
}
return wordList;
}
public String outputWordList() throws IOException {//处理之后,返回一个文件名 供InfoFrame使用
File file = new File("./output/");
if (!file.exists()) {
file.mkdirs();
file.createNewFile();// 如果这个文件不存在就创建它
}
String path = file.getAbsolutePath();
FileOutputStream fos = new FileOutputStream(path + "/wordList.txt");
BufferedOutputStream bos = new BufferedOutputStream(fos);
OutputStreamWriter osw1 = new OutputStreamWriter(bos, "utf-8");
PrintWriter pw1 = new PrintWriter(osw1);
pw1.println("单词序号\t单词的值\t单词类型\t单词所在行\t单词是否合法");//mainframe显示的只是compiler里面的,难道mainframe与backup无关?
Word word;
for (int i = 0; i < wordList.size(); i++) {//数据取自wordList
word = wordList.get(i);
if(isInteger(word.value)) {//调整一下位置 使之对齐
pw1.println(word.id + "\t\t" + word.value + "\t\t" + word.type + "\t" + word.line + "\t\t" + word.flag);
}
else {
pw1.println(word.id + "\t\t" + word.value + "\t\t" + word.type + "\t" + "\t" + word.line + "\t\t" + word.flag);
}
}
if (lexErrorFlag) {
Error error;
pw1.println("错误信息如下:");
pw1.println("错误序号\t错误信息\t错误所在行 \t错误单词");
for (int i = 0; i < errorList.size(); i++) {
error = errorList.get(i);
pw1.println(error.id + "\t" + error.info + "\t\t" + error.line
+ "\t" + error.word.value);
}
} else {
pw1.println("词法分析通过:");
}
pw1.close();
return path + "/wordList.txt";
}
public static void main(String[] args) throws IOException {
LexAnalyse lex = new LexAnalyse();
lex.lexAnalyse1("b.c");
lex.outputWordList();
}
}
AnalyseNode.java
package compiler;
import java.util.ArrayList;
/**
* 分析栈节点类
* String type;//节点类型
String name;//节点名
Object value;//节点值
*/
public class AnalyseNode {
public final static String NONTERMINAL="非终结符";
public final static String TERMINAL="终结符";
public final static String ACTIONSIGN="动作符";
public final static String END="结束符";
static ArrayList<String>nonterminal=new ArrayList<String>();//非终结符集合
static ArrayList<String>actionSign=new ArrayList<String>();//动作符集合
static{
//N:S,B,A,C,,X,R,Z,Z’,U,U’,E,E’,H,H’,G,M,D,L,L’,T,T’,F,O,P,Q
nonterminal.add("S");
nonterminal.add("A");
nonterminal.add("B");
nonterminal.add("C");
nonterminal.add("D");
nonterminal.add("E");
nonterminal.add("F");
nonterminal.add("G");
nonterminal.add("H");
nonterminal.add("L");
nonterminal.add("M");
nonterminal.add("O");
nonterminal.add("P");
nonterminal.add("Q");
nonterminal.add("X");
nonterminal.add("Y");
nonterminal.add("Z");
nonterminal.add("R");
nonterminal.add("U");
nonterminal.add("Z'");
nonterminal.add("U'");
nonterminal.add("E'");
nonterminal.add("H'");
nonterminal.add("L'");
nonterminal.add("T");
nonterminal.add("T'");
actionSign.add("@ADD_SUB");
actionSign.add("@ADD");
actionSign.add("@SUB");
actionSign.add("@DIV_MUL");
actionSign.add("@DIV");
actionSign.add("@MUL");
actionSign.add("@SINGLE");
actionSign.add("@SINGTLE_OP");
actionSign.add("@ASS_R");
actionSign.add("@ASS_Q");
actionSign.add("@ASS_F");
actionSign.add("@ASS_U");
actionSign.add("@TRAN_LF");
actionSign.add("@EQ");
actionSign.add("@EQ_U'");
actionSign.add("@COMPARE");
actionSign.add("@COMPARE_OP");
actionSign.add("@IF_FJ");
actionSign.add("@IF_BACKPATCH_FJ");
actionSign.add("@IF_RJ");
actionSign.add("@IF_BACKPATCH_RJ");
actionSign.add("@WHILE_FJ");
actionSign.add("@WHILE_BACKPATCH_FJ");
actionSign.add("@IF_RJ");
actionSign.add("@FOR_FJ");
actionSign.add("@FOR_RJ");
actionSign.add("@FOR_BACKPATCH_FJ");
}
String type;//节点类型
String name;//节点名
String value;//节点值
public static boolean isNonterm(AnalyseNode node){
return nonterminal.contains(node.name);
}
public static boolean isTerm(AnalyseNode node){
return Word.isKey(node.name)||Word.isOperator(node.name)||Word.isBoundarySign(node.name)
||node.name.equals("id")||node.name.equals("num")||node.name.equals("ch");
}
public static boolean isActionSign(AnalyseNode node){
return actionSign.contains(node.name);
}
public AnalyseNode(){
}
public AnalyseNode(String type,String name,String value){
this.type=type;
this.name=name;
this.value=value;
}
}
FourElement.java
package compiler;
public class FourElement {
int id;//四元式序号,为编程方便
String op;//操作符
String arg1;//第一个操作数
String arg2;//第二个操作数
Object result;//结果
public FourElement(){
}
public FourElement(int id,String op,String arg1,String arg2,String result){
this.id=id;
this.op=op;
this.arg1=arg1;
this.arg2=arg2;
this.result=result;
}
}
Parser.java
package compiler;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.util.ArrayList;
import java.util.Stack;
/**
* 语法分析器
* @author xxz
*
*/
public class Parser {
/**
* @param args
*/
private LexAnalyse lexAnalyse ;//词法分析器
ArrayList<Word>wordList=new ArrayList<Word>();//单词表
Stack<AnalyseNode>analyseStack=new Stack<AnalyseNode>();//分析栈
Stack<String>semanticStack=new Stack<String>();//语义栈
ArrayList<FourElement>fourElemList=new ArrayList<FourElement>();//四元式列表
ArrayList<Error>errorList=new ArrayList<Error>();//错误信息列表
StringBuffer bf;//分析栈缓冲流
int errorCount=0;//统计错误个数
boolean graErrorFlag=false;//语法分析出错标志
int tempCount=0;//用于生成临时变量
int fourElemCount=0;//统计四元式个数
AnalyseNode S,B,A,C,X,Y,R,Z,Z1,U,U1,E,E1,H,H1,G,M,D,L,L1,T,T1,F,O,P,Q;
AnalyseNode ADD_SUB,DIV_MUL,ADD,SUB,DIV,MUL,ASS_F,ASS_R,ASS_Q,ASS_U,TRAN_LF;
AnalyseNode SINGLE,SINGLE_OP,EQ,EQ_U1,COMPARE,COMPARE_OP,IF_FJ,IF_RJ,IF_BACKPATCH_FJ,IF_BACKPATCH_RJ;
AnalyseNode WHILE_FJ,WHILE_RJ,WHILE_BACKPATCH_FJ,FOR_FJ,FOR_RJ,FOR_BACKPATCH_FJ;
AnalyseNode top;//当前栈顶元素
Word firstWord;//待分析单词
String OP=null;
String ARG1,ARG2,RES;
Error error;
//int if_fj,if_rj,while_fj,while_rj,for_fj,for_rj;
Stack<Integer>if_fj,if_rj,while_fj,while_rj,for_fj,for_rj;//if while for 跳转地址栈
Stack<String>for_op=new Stack<String>();
public Parser(){
}
public Parser(LexAnalyse lexAnalyse){
this.lexAnalyse=lexAnalyse;
this.wordList=lexAnalyse.wordList;
init();
}
private String newTemp(){
tempCount++;
return "T"+tempCount;
}
public void init(){
S=new AnalyseNode(AnalyseNode.NONTERMINAL, "S", null);
A=new AnalyseNode(AnalyseNode.NONTERMINAL, "A", null);
B=new AnalyseNode(AnalyseNode.NONTERMINAL, "B", null);
C=new AnalyseNode(AnalyseNode.NONTERMINAL, "C", null);
X=new AnalyseNode(AnalyseNode.NONTERMINAL, "X", null);
Y=new AnalyseNode(AnalyseNode.NONTERMINAL, "Y", null);
Z=new AnalyseNode(AnalyseNode.NONTERMINAL, "Z", null);
Z1=new AnalyseNode(AnalyseNode.NONTERMINAL, "Z'", null);
U=new AnalyseNode(AnalyseNode.NONTERMINAL, "U", null);
U1=new AnalyseNode(AnalyseNode.NONTERMINAL, "U'", null);
E=new AnalyseNode(AnalyseNode.NONTERMINAL, "E", null);
E1=new AnalyseNode(AnalyseNode.NONTERMINAL, "E'", null);
H=new AnalyseNode(AnalyseNode.NONTERMINAL, "H", null);
H1=new AnalyseNode(AnalyseNode.NONTERMINAL, "H'", null);
G=new AnalyseNode(AnalyseNode.NONTERMINAL, "G", null);
F=new AnalyseNode(AnalyseNode.NONTERMINAL, "F", null);
D=new AnalyseNode(AnalyseNode.NONTERMINAL, "D", null);
L=new AnalyseNode(AnalyseNode.NONTERMINAL, "L", null);
L1=new AnalyseNode(AnalyseNode.NONTERMINAL, "L'", null);
T=new AnalyseNode(AnalyseNode.NONTERMINAL, "T", null);
T1=new AnalyseNode(AnalyseNode.NONTERMINAL, "T'", null);
O=new AnalyseNode(AnalyseNode.NONTERMINAL, "O", null);
P=new AnalyseNode(AnalyseNode.NONTERMINAL, "P", null);
Q=new AnalyseNode(AnalyseNode.NONTERMINAL, "Q", null);
R=new AnalyseNode(AnalyseNode.NONTERMINAL, "R", null);
ADD_SUB=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@ADD_SUB", null);
ADD=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@ADD", null);
SUB=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@SUB", null);
DIV_MUL=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@DIV_MUL", null);
DIV=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@DIV", null);
MUL=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@MUL", null);
ASS_F=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@ASS_F", null);
ASS_R=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@ASS_R", null);
ASS_Q=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@ASS_Q", null);
ASS_U=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@ASS_U", null);
TRAN_LF=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@TRAN_LF", null);
SINGLE=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@SINGLE", null);
SINGLE_OP=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@SINGLE_OP", null);
EQ=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@EQ", null);
EQ_U1=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@EQ_U'", null);
COMPARE=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@COMPARE", null);
COMPARE_OP=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@COMPARE_OP", null);
IF_FJ=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@IF_FJ", null);
IF_RJ=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@IF_RJ", null);
IF_BACKPATCH_FJ=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@IF_BACKPATCH_FJ", null);
IF_BACKPATCH_RJ=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@IF_BACKPATCH_RJ", null);
WHILE_FJ=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@WHILE_FJ", null);
WHILE_RJ=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@WHILE_RJ", null);
WHILE_BACKPATCH_FJ=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@WHILE_BACKPATCH_FJ", null);
FOR_FJ=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@FOR_FJ", null);
FOR_RJ=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@FOR_RJ", null);
FOR_BACKPATCH_FJ=new AnalyseNode(AnalyseNode.ACTIONSIGN, "@FOR_BACKPATCH_FJ", null);
if_fj=new Stack<Integer>();
if_rj=new Stack<Integer>();
while_fj=new Stack<Integer>();
while_rj=new Stack<Integer>();
for_fj=new Stack<Integer>();
for_rj=new Stack<Integer>();
}
public void grammerAnalyse(){//LL1分析方法进行语法分析
if(lexAnalyse.isFail())javax.swing.JOptionPane.showMessageDialog(null, "词法分析未通过,不能进行语法分析");
bf=new StringBuffer();
int gcount=0;
error=null;
analyseStack.add(0,S);
analyseStack.add(1,new AnalyseNode(AnalyseNode.END, "#", null));
semanticStack.add("#");
while(!analyseStack.empty() && !wordList.isEmpty()){
//System.out.println(fourElemCount);
bf.append('\n');
bf.append("步骤"+gcount+"\t");
if(gcount++>10000){//一万步就算了
graErrorFlag=true;
break;
}
/*
* 此方法接受整数数据类型的强制参数索引。
* 它指定要从堆栈中获取的元素的位置或索引。
* Java.util.Stack.get()方法用于从堆栈中获取或检索特定索引处的元素。
*/
top=analyseStack.get(0);//当前分析栈栈底元素(不是栈顶吧
firstWord=wordList.get(0);//待分析单词
if(firstWord.value.equals("#") && top.name.equals("#")){//正常结束
bf.append("\n");
analyseStack.remove(0);
wordList.remove(0);
}
else if(top.name.equals("#")){//如果top == # 而first != # 则出错
analyseStack.remove(0);
graErrorFlag=true;
break;
}
//以AnalyseStack中的top结点为触媒
//!firstWord.value.equals("#") && !top.name.equals("#")
else if(AnalyseNode.isTerm(top)){//语法分析栈top为终结符时的处理
termOP(top.name);
}else if(AnalyseNode.isNonterm(top)){//语法分析栈top为非终结符时的处理
nonTermOP(top.name);
}else if(top.type.equals(AnalyseNode.ACTIONSIGN)){//语法分析栈top是动作符号时的处理
actionSignOP();//top.name
}
bf.append("当前语法分析栈:");
for(int i=0;i<analyseStack.size();i++){
bf.append(analyseStack.get(i).name);
//System.out.println(analyseStack.get(i).name);
}
bf.append("\t").append("余留符号串:");
for(int j=0;j<wordList.size();j++){
bf.append(wordList.get(j).value);
}
bf.append("\t").append("语义栈:");
for(int k=semanticStack.size()-1;k>=0;k--){
bf.append(semanticStack.get(k));
}
}
}
private void termOP(String term){
if(firstWord.type.equals(Word.INT_CONST)
||firstWord.type.equals(Word.CHAR_CONST)
||term.equals(firstWord.value)//相等也行
||(term.equals("id")&&firstWord.type.equals(Word.IDENTIFIER)))
{
analyseStack.remove(0);
wordList.remove(0);
}
else{
errorCount++;
analyseStack.remove(0);
wordList.remove(0);
error=new Error(errorCount,"语法错误",firstWord.line,firstWord);
errorList.add(error);
graErrorFlag=true;
}
}
private void nonTermOP(String nonTerm){
if(nonTerm.equals("Z'"))nonTerm="1";
if(nonTerm.equals("U'"))nonTerm="2";
if(nonTerm.equals("E'"))nonTerm="3";
if(nonTerm.equals("H'"))nonTerm="4";
if(nonTerm.equals("L'"))nonTerm="5";
if(nonTerm.equals("T'"))nonTerm="6";
switch(nonTerm.charAt(0)){//栈顶为非终结符处理
//N:S,B,A,C,,X,R,Z,Z’,U,U’,E,E’,H,H’,G,M,D,L,L’,T,T’,F,O,P,Q
case 'S':
if(firstWord.value.equals("void")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "void", null));
analyseStack.add(1,new AnalyseNode(AnalyseNode.TERMINAL, "main", null));
analyseStack.add(2,new AnalyseNode(AnalyseNode.TERMINAL, "(", null));
analyseStack.add(3,new AnalyseNode(AnalyseNode.TERMINAL, ")", null));
analyseStack.add(4,new AnalyseNode(AnalyseNode.TERMINAL, "{", null));
analyseStack.add(5,A);
analyseStack.add(6,new AnalyseNode(AnalyseNode.TERMINAL, "}", null));
}else{//第一步就出错了
errorCount++;
analyseStack.remove(0);
wordList.remove(0);
error=new Error(errorCount,"主函数没有返回值",firstWord.line,firstWord);
errorList.add(error);
graErrorFlag=true;
}
break;
case 'A':
if(firstWord.value.equals("int")||firstWord.value.equals("char")//A->CA
||firstWord.value.equals("bool")){
analyseStack.remove(0);
analyseStack.add(0,C);
analyseStack.add(1,A);
}else if(firstWord.value.equals("printf")){
analyseStack.remove(0);
analyseStack.add(0,C);
analyseStack.add(1,A);
}
else if(firstWord.value.equals("scanf")){
analyseStack.remove(0);
analyseStack.add(0,C);
analyseStack.add(1,A);
}
else if(firstWord.value.equals("if")){
analyseStack.remove(0);
analyseStack.add(0,C);
analyseStack.add(1,A);
}
else if(firstWord.value.equals("while")){
analyseStack.remove(0);
analyseStack.add(0,C);
analyseStack.add(1,A);
}
else if(firstWord.value.equals("for")){
analyseStack.remove(0);
analyseStack.add(0,C);
analyseStack.add(1,A);
}
else if(firstWord.type.equals(Word.IDENTIFIER)){
analyseStack.remove(0);
analyseStack.add(0,C);
analyseStack.add(1,A);
}else{//A->$
analyseStack.remove(0);
}
break;
case 'B':
if(firstWord.value.equals("printf")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "printf", null));
analyseStack.add(1,new AnalyseNode(AnalyseNode.TERMINAL, "(", null));
analyseStack.add(2,P);
analyseStack.add(3,new AnalyseNode(AnalyseNode.TERMINAL, ")", null));
analyseStack.add(4,A);
analyseStack.add(5,new AnalyseNode(AnalyseNode.TERMINAL, ";", null));
}
else if(firstWord.value.equals("scanf")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "scanf", null));
analyseStack.add(1,new AnalyseNode(AnalyseNode.TERMINAL, "(", null));
analyseStack.add(2,new AnalyseNode(AnalyseNode.TERMINAL, "id", null));
analyseStack.add(3,new AnalyseNode(AnalyseNode.TERMINAL, ")", null));
analyseStack.add(4,A);
analyseStack.add(5,new AnalyseNode(AnalyseNode.TERMINAL, ";", null));
}
else if(firstWord.value.equals("if")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "if", null));
analyseStack.add(1,new AnalyseNode(AnalyseNode.TERMINAL, "(", null));
analyseStack.add(2,G);
analyseStack.add(3,new AnalyseNode(AnalyseNode.TERMINAL, ")", null));
analyseStack.add(4,IF_FJ);
analyseStack.add(5,new AnalyseNode(AnalyseNode.TERMINAL, "{", null));
analyseStack.add(6,A);
analyseStack.add(7,new AnalyseNode(AnalyseNode.TERMINAL, "}", null));
analyseStack.add(8,IF_BACKPATCH_FJ);
analyseStack.add(9,IF_RJ);
analyseStack.add(10,new AnalyseNode(AnalyseNode.TERMINAL, "else", null));
analyseStack.add(11,new AnalyseNode(AnalyseNode.TERMINAL, "{", null));
analyseStack.add(12,A);
analyseStack.add(13,new AnalyseNode(AnalyseNode.TERMINAL, "}", null));
analyseStack.add(14,IF_BACKPATCH_RJ);
}
else if(firstWord.value.equals("while")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "while", null));
analyseStack.add(1,new AnalyseNode(AnalyseNode.TERMINAL, "(", null));
analyseStack.add(2,G);
analyseStack.add(3,new AnalyseNode(AnalyseNode.TERMINAL, ")", null));
analyseStack.add(4,WHILE_FJ);
analyseStack.add(5,new AnalyseNode(AnalyseNode.TERMINAL, "{", null));
analyseStack.add(6,A);
analyseStack.add(7,new AnalyseNode(AnalyseNode.TERMINAL, "}", null));
analyseStack.add(8,WHILE_RJ);
analyseStack.add(9,WHILE_BACKPATCH_FJ);
}
else if(firstWord.value.equals("for")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "for", null));
analyseStack.add(1,new AnalyseNode(AnalyseNode.TERMINAL, "(", null));
analyseStack.add(2,Y);
analyseStack.add(3,Z);
analyseStack.add(4,new AnalyseNode(AnalyseNode.TERMINAL, ";", null));
analyseStack.add(5,G);
analyseStack.add(6,FOR_FJ);
analyseStack.add(7,new AnalyseNode(AnalyseNode.TERMINAL, ";", null));
analyseStack.add(8,Q);
analyseStack.add(9,new AnalyseNode(AnalyseNode.TERMINAL, ")", null));
analyseStack.add(10,new AnalyseNode(AnalyseNode.TERMINAL, "{", null));
analyseStack.add(11,A);
analyseStack.add(12,SINGLE);
analyseStack.add(13,new AnalyseNode(AnalyseNode.TERMINAL, "}", null));
analyseStack.add(14,FOR_RJ);
analyseStack.add(15,FOR_BACKPATCH_FJ);
}
else{
analyseStack.remove(0);
}
break;
case 'C'://C->X|B|R
analyseStack.remove(0);
analyseStack.add(0,X);
analyseStack.add(1,B);
analyseStack.add(2,R);
break;
case 'X':
if(firstWord.value.equals("int")||firstWord.value.equals("char")||firstWord.value.equals("bool")){
analyseStack.remove(0);
analyseStack.add(0,Y);
analyseStack.add(1,Z);
analyseStack.add(2,new AnalyseNode(AnalyseNode.TERMINAL, ";", null));
}else{
analyseStack.remove(0);
}
break;
case 'Y':
if(firstWord.value.equals("int")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "int", null));
}
else if(firstWord.value.equals("char")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "char", null));
}
else if(firstWord.value.equals("bool")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "bool", null));
}
else{
errorCount++;
analyseStack.remove(0);
wordList.remove(0);
error=new Error(errorCount,"非法数据类型",firstWord.line,firstWord);
errorList.add(error);
graErrorFlag=true;
}
break;
case 'Z':
if(firstWord.type.equals(Word.IDENTIFIER)){
analyseStack.remove(0);
analyseStack.add(0,U);
analyseStack.add(1,Z1);//Z1即为一个analyseNode(z’)
}
else{
errorCount++;
analyseStack.remove(0);
wordList.remove(0);
error=new Error(errorCount,"非法标识符",firstWord.line,firstWord);
errorList.add(error);
graErrorFlag=true;
}
break;
case '1'://z'
if(firstWord.value.equals(",")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, ",", null));
analyseStack.add(1,Z);
}
else{
analyseStack.remove(0);
}
break;
case 'U':
if(firstWord.type.equals(Word.IDENTIFIER)){
analyseStack.remove(0);
analyseStack.add(0,ASS_U);//actionSignOP
analyseStack.add(1,new AnalyseNode(AnalyseNode.TERMINAL, "id", null));//助于下一步删除wordList中的顶值(已经拷贝到semanticStack中)
analyseStack.add(2,U1);
}
else{
errorCount++;
analyseStack.remove(0);
wordList.remove(0);
error=new Error(errorCount,"非法标识符",firstWord.line,firstWord);
errorList.add(error);
graErrorFlag=true;
}
break;
case '2'://U'
if(firstWord.value.equals("=")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "=", null));
analyseStack.add(1,L);
analyseStack.add(2,EQ_U1);
}
else{//有 = 但是没赋值 就走这条路
analyseStack.remove(0);
}
break;
case 'R':
if(firstWord.type.equals(Word.IDENTIFIER)){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.ACTIONSIGN, "@ASS_R", null));
analyseStack.add(1,new AnalyseNode(AnalyseNode.TERMINAL, "id", null));
analyseStack.add(2,new AnalyseNode(AnalyseNode.TERMINAL, "=", null));
analyseStack.add(3,L);
analyseStack.add(4,EQ);
analyseStack.add(5,new AnalyseNode(AnalyseNode.TERMINAL, ";", null));
}
else{
analyseStack.remove(0);
}
break;
case 'P':
if(firstWord.type.equals(Word.IDENTIFIER)){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "id", null));
}else if(firstWord.type.equals(Word.INT_CONST)){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "num", null));
}else if(firstWord.type.equals(Word.CHAR_CONST)){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "ch", null));
}
else{
errorCount++;
analyseStack.remove(0);
wordList.remove(0);
error=new Error(errorCount,"不能输出的数据类型",firstWord.line,firstWord);
errorList.add(error);
graErrorFlag=true;
}
break;
case 'E':
if(firstWord.type.equals(Word.IDENTIFIER)){
analyseStack.remove(0);
analyseStack.add(0,H);
analyseStack.add(1,E1);
}else if(firstWord.type.equals(Word.INT_CONST)){
analyseStack.remove(0);
analyseStack.add(0,H);
analyseStack.add(1,E1);
}else if(firstWord.value.equals("(")){
analyseStack.remove(0);
analyseStack.add(0,H);
analyseStack.add(1,E1);
}
else{
errorCount++;
analyseStack.remove(0);
wordList.remove(0);
error=new Error(errorCount,"不能进行算术运算的数据类型",firstWord.line,firstWord);
errorList.add(error);
graErrorFlag=true;
}
break;
case '3'://E'
if(firstWord.value.equals("&&")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "&&", null));
analyseStack.add(1,E);
}else {
analyseStack.remove(0);
}
break;
case 'H':
if(firstWord.type.equals(Word.IDENTIFIER)){
analyseStack.remove(0);
analyseStack.add(0,G);
analyseStack.add(1,H1);
}else if(firstWord.type.equals(Word.INT_CONST)){
analyseStack.remove(0);
analyseStack.add(0,G);
analyseStack.add(1,H1);
}else if(firstWord.value.equals("(")){
analyseStack.remove(0);
analyseStack.add(0,G);
analyseStack.add(1,H1);
}
else{
errorCount++;
analyseStack.remove(0);
wordList.remove(0);
error=new Error(errorCount,"不能进行算术运算的数据类型",firstWord.line,firstWord);
errorList.add(error);
graErrorFlag=true;
}
break;
case '4'://H'
if(firstWord.value.equals("||")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "||", null));
analyseStack.add(1,E);
}else {
analyseStack.remove(0);
}
break;
case 'D':
if(firstWord.value.equals("==")){
analyseStack.remove(0);
analyseStack.add(0,COMPARE_OP);
analyseStack.add(1,new AnalyseNode(AnalyseNode.TERMINAL, "==", null));
}else if(firstWord.value.equals("!=")){
analyseStack.remove(0);
analyseStack.add(0,COMPARE_OP);
analyseStack.add(1,new AnalyseNode(AnalyseNode.TERMINAL, "!=", null));
}else if(firstWord.value.equals(">")){
analyseStack.remove(0);
analyseStack.add(0,COMPARE_OP);
analyseStack.add(1,new AnalyseNode(AnalyseNode.TERMINAL, ">", null));
}else if(firstWord.value.equals("<")){
analyseStack.remove(0);
analyseStack.add(0,COMPARE_OP);
analyseStack.add(1,new AnalyseNode(AnalyseNode.TERMINAL, "<", null));
}
else{
errorCount++;
analyseStack.remove(0);
wordList.remove(0);
error=new Error(errorCount,"非法运算符",firstWord.line,firstWord);
errorList.add(error);
graErrorFlag=true;
}
break;
case 'G':
if(firstWord.type.equals(Word.IDENTIFIER)){
analyseStack.remove(0);
analyseStack.add(0,F);
analyseStack.add(1,D);
analyseStack.add(2,F);
analyseStack.add(3,COMPARE);
}else if(firstWord.type.equals(Word.INT_CONST)){
analyseStack.remove(0);
analyseStack.add(0,F);
analyseStack.add(1,D);
analyseStack.add(2,F);
analyseStack.add(3,COMPARE);
}
else if(firstWord.value.equals("(")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "(", null));
analyseStack.add(1,E);
analyseStack.add(2,new AnalyseNode(AnalyseNode.TERMINAL, ")", null));
}
else if(firstWord.value.equals("!")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "!", null));
analyseStack.add(1,E);
}
else{
errorCount++;
analyseStack.remove(0);
wordList.remove(0);
error=new Error(errorCount,"不能进行算术运算的数据类型或括号不匹配",firstWord.line,firstWord);
errorList.add(error);
graErrorFlag=true;
}
break;
case 'L':
if(firstWord.type.equals(Word.IDENTIFIER)){
analyseStack.remove(0);
analyseStack.add(0,T);
analyseStack.add(1,L1);
analyseStack.add(2,ADD_SUB);
}else if(firstWord.type.equals(Word.INT_CONST)){
analyseStack.remove(0);
analyseStack.add(0,T);
analyseStack.add(1,L1);
analyseStack.add(2,ADD_SUB);
}
else if(firstWord.value.equals("(")){
analyseStack.remove(0);
analyseStack.add(0,T);
analyseStack.add(1,L1);
analyseStack.add(2,ADD_SUB);
}
else{
errorCount++;
analyseStack.remove(0);
wordList.remove(0);
error=new Error(errorCount,"不能进行算术运算的数据类型或括号不匹配",firstWord.line,firstWord);
errorList.add(error);
graErrorFlag=true;
}
break;
case '5'://l'
if(firstWord.value.equals("+")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "+", null));
analyseStack.add(1,L);
analyseStack.add(2,ADD);
}
else if(firstWord.value.equals("-")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "-", null));
analyseStack.add(1,L);
analyseStack.add(2,SUB);
}else {
analyseStack.remove(0);
}
break;
case 'T':
if(firstWord.type.equals(Word.IDENTIFIER)){
analyseStack.remove(0);
analyseStack.add(0,F);
analyseStack.add(1,T1);
analyseStack.add(2,DIV_MUL);
}else if(firstWord.type.equals(Word.INT_CONST)){
analyseStack.remove(0);
analyseStack.add(0,F);
analyseStack.add(1,T1);
analyseStack.add(2,DIV_MUL);
}
else if(firstWord.value.equals("(")){
analyseStack.remove(0);
analyseStack.add(0,F);
analyseStack.add(1,T1);
analyseStack.add(2,DIV_MUL);
}
else{
errorCount++;
analyseStack.remove(0);
wordList.remove(0);
error=new Error(errorCount,"不能进行算术运算的数据类型",firstWord.line,firstWord);
errorList.add(error);
graErrorFlag=true;
}
break;
case '6'://T'
if(firstWord.value.equals("*")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "*", null));
analyseStack.add(1,T);
analyseStack.add(2,MUL);
}
else if(firstWord.value.equals("/")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "/", null));
analyseStack.add(1,T);
analyseStack.add(2,DIV);
}else {
analyseStack.remove(0);
}
break;
case 'F':
if(firstWord.type.equals(Word.IDENTIFIER)){
analyseStack.remove(0);
analyseStack.add(0,ASS_F);
analyseStack.add(1,new AnalyseNode(AnalyseNode.TERMINAL, "id", null));
}else if(firstWord.type.equals(Word.INT_CONST)){
analyseStack.remove(0);
analyseStack.add(0,ASS_F);
analyseStack.add(1,new AnalyseNode(AnalyseNode.TERMINAL, "num", null));
}else if(firstWord.value.equals("(")){
analyseStack.add(0,new AnalyseNode(AnalyseNode.TERMINAL, "(", null));
analyseStack.add(1,L);
analyseStack.add(2,new AnalyseNode(AnalyseNode.TERMINAL, ")", null));
analyseStack.add(3,TRAN_LF);
}
else{
//errorCount++;
analyseStack.remove(0);
// wordList.remove(0);
//error=new Error(errorCount,"不能进行算术运算的数据类型",firstWord.line,firstWord);
//errorList.add(error);
//graErrorFlag=true;
}
break;
case 'O':
if(firstWord.value.equals("++")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.ACTIONSIGN, "@SINGLE_OP", null));
analyseStack.add(1,new AnalyseNode(AnalyseNode.TERMINAL, "++", null));
}else if(firstWord.value.equals("--")){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.ACTIONSIGN, "@SINGLE_OP", null));
analyseStack.add(1,new AnalyseNode(AnalyseNode.TERMINAL, "--", null));
}else {
analyseStack.remove(0);
}
break;
case 'Q'://Q
if(firstWord.type.equals(Word.IDENTIFIER)){
analyseStack.remove(0);
analyseStack.add(0,new AnalyseNode(AnalyseNode.ACTIONSIGN, "@ASS_Q", null));
analyseStack.add(1,new AnalyseNode(AnalyseNode.TERMINAL, "id", null));
analyseStack.add(2,new AnalyseNode(AnalyseNode.TERMINAL, "O", null));
}else {
analyseStack.remove(0);
}
break;
}
}
private void actionSignOP(){
if(top.name.equals("@ADD_SUB")){
if(OP!=null&&(OP.equals("+")||OP.equals("-"))){
ARG2=semanticStack.pop();
ARG1=semanticStack.pop();
RES=newTemp();
//fourElemCount++;
FourElement fourElem=new FourElement(++fourElemCount,OP,ARG1,ARG2,RES);
fourElemList.add(fourElem);
L.value=RES;
semanticStack.push(L.value);
OP=null;
}
analyseStack.remove(0);
}else if(top.name.equals("@ADD")){
OP="+";
analyseStack.remove(0);
}else if(top.name.equals("@SUB")){
OP="-";
analyseStack.remove(0);
}else if(top.name.equals("@DIV_MUL")){//确保不是*= /=
if(OP!=null&&(OP.equals("*")||OP.equals("/"))){
ARG2=semanticStack.pop();
ARG1=semanticStack.pop();
RES=newTemp();
//fourElemCount++;
FourElement fourElem=new FourElement(++fourElemCount,OP,ARG1,ARG2,RES);
fourElemList.add(fourElem);
T.value=RES;
semanticStack.push(T.value);
OP=null;
}
analyseStack.remove(0);
}
else if(top.name.equals("@DIV")){
OP="/";
analyseStack.remove(0);
}
else if(top.name.equals("@MUL")){
OP="*";
analyseStack.remove(0);
}else if(top.name.equals("@TRAN_LF")){
F.value=L.value;
//semanticStack.push(F.value);
analyseStack.remove(0);
}else if(top.name.equals("@ASS_F")){
F.value=firstWord.value;
semanticStack.push(F.value);
analyseStack.remove(0);
}else if(top.name.equals("@ASS_R")){
R.value=firstWord.value;
semanticStack.push(R.value);
analyseStack.remove(0);
}else if(top.name.equals("@ASS_Q")){
Q.value=firstWord.value;
semanticStack.push(Q.value);
analyseStack.remove(0);
}
else if(top.name.equals("@ASS_U")){
U.value=firstWord.value;
semanticStack.push(U.value);
analyseStack.remove(0);
}else if(top.name.equals("@SINGLE")){
if(for_op.peek()!=null){
ARG1=semanticStack.pop();
RES=ARG1;
//fourElemCount++;
FourElement fourElem=new FourElement(++fourElemCount,for_op.pop(),ARG1,"/",RES);
fourElemList.add(fourElem);
}
analyseStack.remove(0);
}else if(top.name.equals("@SINGLE_OP")){
for_op.push(firstWord.value);
analyseStack.remove(0);
}else if(top.name.equals("@EQ")){
OP="=";
ARG1=semanticStack.pop();
RES=semanticStack.pop();;
//fourElemCount++;
FourElement fourElem=new FourElement(++fourElemCount,OP,ARG1,"/",RES);
fourElemList.add(fourElem);
OP=null;
analyseStack.remove(0);
}
else if(top.name.equals("@EQ_U'")){
OP="=";
ARG1=semanticStack.pop();
RES=semanticStack.pop();;
//fourElemCount++;
FourElement fourElem=new FourElement(++fourElemCount,OP,ARG1,"/",RES);// /代表 = 的另外一个操作数缺失 即为单目运算
fourElemList.add(fourElem);
OP=null;
analyseStack.remove(0);
}else if(top.name.equals("@COMPARE")){
ARG2=semanticStack.pop();
OP=semanticStack.pop();
ARG1=semanticStack.pop();
RES=newTemp();
//fourElemCount++;
FourElement fourElem=new FourElement(++fourElemCount,OP,ARG1,ARG2,RES);
fourElemList.add(fourElem);
G.value=RES;
semanticStack.push(G.value);
OP=null;
analyseStack.remove(0);
}else if(top.name.equals("@COMPARE_OP")){
D.value=firstWord.value;
semanticStack.push(D.value);
analyseStack.remove(0);
}else if(top.name.equals("@IF_FJ")){
OP="FJ";
ARG1=semanticStack.pop();
FourElement fourElem=new FourElement(++fourElemCount,OP,ARG1,"/",RES);
if_fj.push(fourElemCount);
fourElemList.add(fourElem);
OP=null;
analyseStack.remove(0);
}else if(top.name.equals("@IF_BACKPATCH_FJ")){
backpatch(if_fj.pop(), fourElemCount+2);
analyseStack.remove(0);
}else if(top.name.equals("@IF_RJ")){
OP="RJ";
FourElement fourElem=new FourElement(++fourElemCount,OP,"/","/","/");
if_rj.push(fourElemCount);
fourElemList.add(fourElem);
OP=null;
analyseStack.remove(0);
}else if(top.name.equals("@IF_BACKPATCH_RJ")){
backpatch(if_rj.pop(), fourElemCount+1);
analyseStack.remove(0);
}else if(top.name.equals("@WHILE_FJ")){
OP="FJ";
ARG1=semanticStack.pop();
FourElement fourElem=new FourElement(++fourElemCount,OP,ARG1,"/","/");
while_fj.push(fourElemCount);
fourElemList.add(fourElem);
OP=null;
analyseStack.remove(0);
}else if(top.name.equals("@WHILE_RJ")){
OP="RJ";
RES=(while_fj.peek()-1)+"";
FourElement fourElem=new FourElement(++fourElemCount,OP,"/","/",RES);
for_rj.push(fourElemCount);
fourElemList.add(fourElem);
OP=null;
analyseStack.remove(0);
}else if(top.name.equals("@WHILE_BACKPATCH_FJ")){
backpatch(while_fj.pop(), fourElemCount+1);
analyseStack.remove(0);
}else if(top.name.equals("@FOR_FJ")){
OP="FJ";
ARG1=semanticStack.pop();
FourElement fourElem=new FourElement(++fourElemCount,OP,ARG1,"/","/");
for_fj.push(fourElemCount);
fourElemList.add(fourElem);
OP=null;
analyseStack.remove(0);//除去Ti
}else if(top.name.equals("@FOR_RJ")){
OP="RJ";
RES=(for_fj.peek()-1)+"";
FourElement fourElem=new FourElement(++fourElemCount,OP,"/","/",RES);
for_rj.push(fourElemCount);
fourElemList.add(fourElem);
OP=null;
analyseStack.remove(0);
}else if(top.name.equals("@FOR_BACKPATCH_FJ")){
backpatch(for_fj.pop(), fourElemCount+1);
analyseStack.remove(0);
}
}
private void backpatch(int i,int res){
FourElement temp=fourElemList.get(i-1);
temp.result=res+"";
fourElemList.set(i-1, temp);
}
public String outputLL1() throws IOException{
//grammerAnalyse();
File file=new File("./output/");
if(!file.exists()){
file.mkdirs();
file.createNewFile();//如果这个文件不存在就创建它
}
String path=file.getAbsolutePath();
FileOutputStream fos=new FileOutputStream(path+"/LL1.txt");
BufferedOutputStream bos=new BufferedOutputStream(fos);
OutputStreamWriter osw1=new OutputStreamWriter(bos,"utf-8");
PrintWriter pw1=new PrintWriter(osw1);
pw1.println(bf.toString());
bf.delete(0, bf.length());
if(graErrorFlag){
Error error;
pw1.println("错误信息如下:");
pw1.println("错误序号\t错误信息\t错误所在行 \t错误单词");
for(int i=0;i<errorList.size();i++){
error=errorList.get(i);
pw1.println(error.id+"\t"+error.info+"\t\t"+error.line+"\t"+error.word.value);
}
}else {
pw1.println("语法分析通过:");
}
pw1.close();
return path+"/LL1.txt";
}
public String outputFourElem() throws IOException{
File file=new File("./output/");
if(!file.exists()){
file.mkdirs();
file.createNewFile();//如果这个文件不存在就创建它
}
String path=file.getAbsolutePath();
FileOutputStream fos=new FileOutputStream(path+"/FourElement.txt");
BufferedOutputStream bos=new BufferedOutputStream(fos);
OutputStreamWriter osw1=new OutputStreamWriter(bos,"utf-8");
PrintWriter pw1=new PrintWriter(osw1);
pw1.println("生成的四元式如下");
pw1.println("序号(OP,ARG1,ARG2,RESULT)");
FourElement temp;
for(int i=0;i<fourElemList.size();i++){
temp=fourElemList.get(i);
pw1.println(temp.id+"("+temp.op+","+temp.arg1+","+temp.arg2+","+temp.result+")");
}
pw1.close();
return path+"/FourElement.txt";
}
public static void main(String[] args) {
// TODO Auto-generated method stub
}
}
huibian.java
package compiler;
import java.awt.BorderLayout;
import java.awt.Color;
import java.awt.Container;
import java.awt.Dimension;
import java.awt.Toolkit;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import javax.swing.JFrame;
import javax.swing.JPanel;
import javax.swing.JTextArea;
import java.awt.*;
public class huibian extends JFrame {
//private static final long serialVersionUID = 8766059377195109228L;
private static String title;
private static String fileName;
private static TextArea text;
private static boolean isInteger(String word) {
int i;
boolean flag = false;
for (i = 0; i < word.length(); i++) {
if (Character.isDigit(word.charAt(i))) {
continue;
} else {
break;
}
}
if (i == word.length()) {
flag = true;
}
return flag;
}
public huibian() {
init();
}
public huibian(String title,String fileName){//huibian inf = new huibian("目标代码生成", fourElementPath);
this.title=title;
this.fileName=fileName;
int count = 0;
init();
this.setTitle(title);
try {
String str[] =readFile(fileName).split("\n");
String str_1 = "生成的目标代码如下\n";
String str_2 = "序号(OP,ARG1,ARG2)\n";
text.append(str_1);
text.append(str_2);
for(int i = 2; i < str.length; i++)
{
String temp[] = str[i].split(",");
if(temp[0].charAt(temp[0].length() -1) == '='){//=
//if(temp[1].substring(0,temp[1].length()-1).equals("T"))
//{
//String temp1 = temp[0].substring(0,temp[0].length() - 2) + "\n";
//text.append(temp1);
//}
//else {
String temp1 = ++count + " MOV " + temp[3].substring(0,temp[3].length() - 1) + "," + temp[1] + "\n";
//System.out.println(temp1);
text.append(temp1);
//}
}
//++
else if(temp[0].charAt(temp[0].length() -1) == '+' && temp[0].charAt(temp[0].length() -2) == '+'){
String temp1 = ++count + " INC " + temp[1] + "\n";
//System.out.println(temp1);
text.append(temp1);
}
//+
else if(temp[0].charAt(temp[0].length() -1) == '+'){
//if(isInteger(temp[1])) {
String temp2 = ++count + " MOV " + "AX" + "," + temp[2] + "\n";
String temp3 = ++count + " MOV " + temp[3].substring(0,temp[3].length() - 1) + "," + temp[1] + "\n";
String temp1 = ++count + " ADD " + temp[3].substring(0,temp[3].length() - 1) + "," + "AX" + "\n";//temp[3].substring(0,temp[3].length() - 1)
text.append(temp2);
text.append(temp3);
text.append(temp1);
//}
//else {
//String temp1 = temp[0].substring(0,temp[0].length() - 2) + " ADD " + temp[3].substring(0,temp[3].length() - 1) + "," + temp[1] + "\n";//temp[3].substring(0,temp[3].length() - 1)
//System.out.println(temp1);
//text.append(temp1);
//}
}
//-
else if(temp[0].charAt(temp[0].length() -1) == '-'){
//String temp1 = ++count + " SUB " + temp[3].substring(0,temp[3].length() - 1) + "," + temp[1] + "\n";
String temp2 = ++count + " MOV " + "AX" + "," + temp[2] + "\n";
String temp3 = ++count + " MOV " + temp[3].substring(0,temp[3].length() - 1) + "," + temp[1] + "\n";
String temp1 = ++count + " SUB " + temp[3].substring(0,temp[3].length() - 1) + "," + "AX" + "\n";//temp[3].substring(0,temp[3].length() - 1)
text.append(temp2);
text.append(temp3);
text.append(temp1);
//System.out.println(temp1);
//text.append(temp1);
}
//*
else if(temp[0].charAt(temp[0].length() -1) == '*'){
//String temp1 = ++count + " MUL " + temp[3].substring(0,temp[3].length() - 1) + "," + temp[1] + "\n";
String temp2 = ++count + " MOV " + "AX" + "," + temp[2] + "\n";
String temp3 = ++count + " MOV " + temp[3].substring(0,temp[3].length() - 1) + "," + temp[1] + "\n";
String temp1 = ++count + " MUL " + temp[3].substring(0,temp[3].length() - 1) + "," + "AX" + "\n";//temp[3].substring(0,temp[3].length() - 1)
text.append(temp2);
text.append(temp3);
text.append(temp1);
//System.out.println(temp1);
//text.append(temp1);
}
///
else if(temp[0].charAt(temp[0].length() -1) == '/'){
//String temp1 = ++count + " DIV " + temp[3].substring(0,temp[3].length() - 1) + "," + temp[1] + "\n";
String temp2 = ++count + " MOV " + "AX" + "," + temp[2] + "\n";
String temp3 = ++count + " MOV " + temp[3].substring(0,temp[3].length() - 1) + "," + temp[1] + "\n";
String temp1 = ++count + " DIV " + temp[3].substring(0,temp[3].length() - 1) + "," + "AX" + "\n";//temp[3].substring(0,temp[3].length() - 1)
text.append(temp2);
text.append(temp3);
text.append(temp1);
//System.out.println(temp1);
//text.append(temp1);
}
//RJ
else if(temp[0].charAt(temp[0].length() -1) == 'J' && temp[0].charAt(temp[0].length() -2) == 'R'){
String temp1 = ++count + " JMP " + temp[3].substring(0,temp[3].length() - 1) + "\n";
//System.out.println(temp1);
text.append(temp1);
}
//FJ
else if(temp[0].charAt(temp[0].length() -1) == 'J' && temp[0].charAt(temp[0].length() -2) == 'F'){
//String temp1 = temp[0].substring(0,temp[0].length() - 3) + " JZ " + temp[3].substring(0,temp[3].length() - 1) + "\n";
//String temp1 = temp[0].substring(0,temp[0].length() - 3) + " JMP " + temp[3].substring(0,temp[3].length() - 1) + "\n";
String temp1 = ++count + " JL " + temp[3].substring(0,temp[3].length() - 1) + "\n";
//System.out.println(temp1);
text.append(temp1);
}
//>
else if(temp[0].charAt(temp[0].length() -1) == '>'){
String temp1 = ++count + " CMP " + temp[1] + "," + temp[2] + "\n";
//String temp2 = temp[0].substring(0,temp[0].length() - 2) + " JG " + temp[3].substring(0,temp[3].length() - 1) + "\n";
//System.out.println(temp1);
text.append(temp1);
//text.append(temp2);
}
//<
else if(temp[0].charAt(temp[0].length() -1) == '<'){
String temp1 = ++count + " CMP " + temp[1] + "," + temp[2] + "\n";
//String temp2 = temp[0].substring(0,temp[0].length() - 2) + " JL " + temp[3].substring(0,temp[3].length() - 1) + "\n";
//System.out.println(temp1);
text.append(temp1);
//text.append(temp2);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
private void init() {
Toolkit toolkit = Toolkit.getDefaultToolkit();
Dimension screen = toolkit.getScreenSize();
setSize(500, 400);
super.setLocation(screen.width / 2 - this.getWidth() / 2, screen.height
/ 2 - this.getHeight() / 2);
setContentPane(createContentPane());
}
private Container createContentPane() {
JPanel pane = new JPanel(new BorderLayout());
text = new TextArea();
//msg.setBackground(Color.green);
text.setForeground(Color.BLUE);
pane.add(BorderLayout.CENTER, text);
return pane;
}
private String readFile(String filename)
throws IOException{
StringBuilder sbr = new StringBuilder();
String str;
FileInputStream fis = new FileInputStream(filename);
BufferedInputStream bis = new BufferedInputStream(fis);
InputStreamReader isr = new InputStreamReader(bis, "UTF-8");
BufferedReader in=new BufferedReader(isr);
while((str=in.readLine())!=null){
sbr.append(str).append('\n');
}
in.close();
//text.setText(sbr.toString());
return sbr.toString();
}
public static String getTitl() {
return title;
}
public static void setTitl(String title) {
huibian.title = title;
}
public static String getFileName() {
return fileName;
}
public static void setFileName(String fileName) {
huibian.fileName = fileName;
}
public static TextArea getText() {
return text;
}
public static void setText(TextArea jText) {
huibian.text = jText;
}
public static void main(String[] args) {
// TODO Auto-generated method stub
huibian inf=new huibian("测试","test.txt");
inf.setVisible(true);
}
}
MainFrame.java
package gui;
import java.awt.*;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import javax.swing.*;
import compiler.*;
public class MainFrame extends JFrame {
TextArea sourseFile;//用来显示源文件的文本框
String soursePath;// 源文件路径
String LL1Path;
String wordListPath;
String fourElementPath;
LexAnalyse lexAnalyse;
Parser parser;
public MainFrame() {
this.init();
}
public void init() {
Toolkit toolkit = Toolkit.getDefaultToolkit();
Dimension screen = toolkit.getScreenSize();
setTitle("C语言小型编译器");
setSize(750, 480);
super.setResizable(false);
super.setLocation(screen.width / 2 - this.getWidth() / 2, screen.height / 2 - this.getHeight() / 2);
this.setContentPane(this.createContentPane());
}
private JPanel createContentPane() {
JPanel p = new JPanel(new BorderLayout());
p.add(BorderLayout.NORTH, createUpPane());
p.add(BorderLayout.CENTER, createcCenterPane());
p.add(BorderLayout.SOUTH, creatBottomPane());
// p.setBorder(new EmptyBorder(8,8,8,8));
return p;
}
private Component createUpPane() {
JPanel p = new JPanel(new FlowLayout());
final FilePanel fp = new FilePanel("选择待分析文件");
JButton button = new JButton("确定");
button.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
String text;
try {
soursePath = fp.getFileName();
text = readFile(soursePath);
sourseFile.setText(text);
} catch (IOException e1) {
e1.printStackTrace();
}
}
});
p.add(fp);
//p.add(fp1);
p.add(button);
return p;
}
private Component createcCenterPane() {
JPanel p = new JPanel(new BorderLayout());
JLabel label = new JLabel("源文件如下:");
sourseFile = new TextArea();
sourseFile.setText("");
p.add(BorderLayout.NORTH, label);
p.add(BorderLayout.CENTER, sourseFile);
return p;
}
private Component creatBottomPane() {
JPanel p = new JPanel(new FlowLayout());
JButton bt1 = new JButton("词法分析");
JButton bt2 = new JButton("语法分析");
JButton bt4 = new JButton("中间代码生成");
JButton bt5 = new JButton("目标代码生成");
bt1.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
try {
lexAnalyse=new LexAnalyse(sourseFile.getText());
wordListPath = lexAnalyse.outputWordList();
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
InfoFrame inf = new InfoFrame("词法分析", wordListPath);
inf.setVisible(true);
}
});
bt2.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
lexAnalyse=new LexAnalyse(sourseFile.getText());
parser=new Parser(lexAnalyse);
try {
parser.grammerAnalyse();
LL1Path= parser.outputLL1();
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
InfoFrame inf = new InfoFrame("语法分析", LL1Path);
inf.setVisible(true);
}
});
bt4.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
try {
lexAnalyse=new LexAnalyse(sourseFile.getText());
parser=new Parser(lexAnalyse);
parser.grammerAnalyse();
fourElementPath=parser.outputFourElem();
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
InfoFrame inf = new InfoFrame("中间代码生成", fourElementPath);
inf.setVisible(true);
}
});
bt5.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
try {
lexAnalyse=new LexAnalyse(sourseFile.getText());
parser=new Parser(lexAnalyse);
parser.grammerAnalyse();
fourElementPath=parser.outputFourElem();
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
huibian inf = new huibian("目标代码生成", fourElementPath);
inf.setVisible(true);
}
});
p.add(bt1);
p.add(bt2);
//p.add(bt3);
p.add(bt4);
p.add(bt5);
return p;
}
public static String readFile(String fileName) throws IOException {
StringBuilder sbr = new StringBuilder();
String str;
FileInputStream fis = new FileInputStream(fileName);
BufferedInputStream bis = new BufferedInputStream(fis);
InputStreamReader isr = new InputStreamReader(bis, "UTF-8");
BufferedReader in = new BufferedReader(isr);
while ((str = in.readLine()) != null) {
sbr.append(str).append('\n');
}
in.close();
return sbr.toString();
}
public static void main(String[] args) {
// TODO Auto-generated method stub
MainFrame mf = new MainFrame();
//TinyCompiler tinyCompiler = new TinyCompiler();
//mf.tinyCompiler = tinyCompiler;
mf.setVisible(true);
}
}
class FilePanel extends JPanel {
FilePanel(String str) {
JLabel label = new JLabel(str);
JTextField fileText = new JTextField(35);
JButton chooseButton = new JButton("浏览...");
this.add(label);
this.add(fileText);
this.add(chooseButton);
clickAction ca = new clickAction(this);
chooseButton.addActionListener(ca);
}
public String getFileName() {
JTextField jtf = (JTextField) this.getComponent(1);
return jtf.getText();
}
// 按钮响应函数
private class clickAction implements ActionListener {
private Component cmpt;
clickAction(Component c) {
cmpt = c;
}
public void actionPerformed(ActionEvent event) {
JFileChooser chooser = new JFileChooser();
chooser.setCurrentDirectory(new File("."));
int ret = chooser.showOpenDialog(cmpt);
if (ret == JFileChooser.APPROVE_OPTION) {
JPanel jp = (JPanel) cmpt;
JTextField jtf = (JTextField) jp.getComponent(1);//获取组件
jtf.setText(chooser.getSelectedFile().getPath());
}
}
}
}
InfoFrame.java
package gui;
import java.awt.BorderLayout;
import java.awt.Color;
import java.awt.Container;
import java.awt.Dimension;
import java.awt.Toolkit;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import javax.swing.JFrame;
import javax.swing.JPanel;
import javax.swing.JTextArea;
import java.awt.*;
public class InfoFrame extends JFrame {
private static final long serialVersionUID = 8766059377195109228L;
private static String title;
private static String fileName;
private static TextArea text;
public InfoFrame() {
init();
}
public InfoFrame(String title,String fileName){
this.title=title;
this.fileName=fileName;
init();
this.setTitle(title);
try {
readFile(fileName);
} catch (IOException e) {
e.printStackTrace();
}
}
private void init() {
Toolkit toolkit = Toolkit.getDefaultToolkit();
Dimension screen = toolkit.getScreenSize();
setSize(500, 400);
super.setLocation(screen.width / 2 - this.getWidth() / 2, screen.height / 2 - this.getHeight() / 2);
setContentPane(createContentPane());
}
private Container createContentPane() {
JPanel pane = new JPanel(new BorderLayout());
text = new TextArea();
//msg.setBackground(Color.blue);
text.setForeground(Color.BLUE);
pane.add(BorderLayout.CENTER, text);
return pane;
}
private String readFile(String filename)
throws IOException{
StringBuilder sbr = new StringBuilder();
String str;
FileInputStream fis = new FileInputStream(filename);
BufferedInputStream bis = new BufferedInputStream(fis);
InputStreamReader isr = new InputStreamReader(bis, "UTF-8");
BufferedReader in=new BufferedReader(isr);
while((str=in.readLine())!=null){
sbr.append(str).append('\n');
}
in.close();
text.setText(sbr.toString());
return sbr.toString();
}
public static String getTitl() {
return title;
}
public static void setTitl(String title) {
InfoFrame.title = title;
}
public static String getFileName() {
return fileName;
}
public static void setFileName(String fileName) {
InfoFrame.fileName = fileName;
}
public static TextArea getText() {
return text;
}
public static void setText(TextArea jText) {
InfoFrame.text = jText;
}
public static void main(String[] args) {
// TODO Auto-generated method stub
InfoFrame inf=new InfoFrame("测试","test.txt");
inf.setVisible(true);
}
}
♻️ 资源
大小: 2.32MB
➡️ 资源下载:https://download.csdn.net/download/s1t16/87415791
相关文章
- MySQL_(Java)【连接池】简单在JDBCUtils.java中创建连接池
- Java实现 LeetCode 717 1比特与2比特字符(暴力)
- Java实现 LeetCode 459 重复的子字符串
- Java实现 LeetCode 330 按要求补齐数组
- Java实现 LeetCode 224 基本计算器
- Java实现 蓝桥杯 猜算式
- Java实现 基础算法 百元买百鸡
- java实现第六届蓝桥杯垒骰子
- Java中TreeSet的详细用法
- Java 蓝桥杯 算法训练 字符串的展开 (JAVA语言实现)
- Java之字符串String,StringBuffer,StringBuilder
- 【JAVA】Java 异常中e的getMessage()和toString()方法的异同
- 【JAVA】毕向东Java基础视频教程-笔记
- Java超类-java.lang.object
- Atitit mybatis的扩展使用sql udf,js java等语言 目录 1.1. 默认,mybatis使用xml,sql等语言来书写业务流程1 2. 使用java扩展函数1 2.1.
- paip. 解决java程序不能自动退出
- paip.执行shell cmd 命令uapi java php python总结
- java 导出excel(简单案例)
- How to improve Java's I/O performance( 提升 java i/o 性能)
- 【java】Java中-> 是什么意思?
- java中TCP传输协议
- JAVA编程:java环境安装和helloworld
- Java程序猿从笨鸟到菜鸟之(九十二)深入java虚拟机(一)——java虚拟机底层结构具体解释
- 终极PK | Python和Java哪个语言更有前途?
- 尽管以C++为基础,但 Java 是一种更纯粹的面向对象程序设计语言
- 【java】Java 多态
- JAVA开发讲义(二)-Java程序设计之数据之谜二