
TensorFlow高阶 API: keras教程-使用tf.keras搭建mnist手写数字识别网络
TensorFlow高阶 API:keras教程-使用tf.keras搭建mnist手写数字识别网络
目录
TensorFlow高阶 API:keras教程-使用tf.keras搭建mnist手写数字识别网络
11、例子1:使用tf.keras搭建mnist手写数字识别网络
1、Keras
Keras 是一个用于构建和训练深度学习模型的高阶 API。它可用于快速设计原型、高级研究和生产,具有以下三个主要优势:
- 方便用户使用
Keras 具有针对常见用例做出优化的简单而一致的界面。它可针对用户错误提供切实可行的清晰反馈。- 模块化和可组合
将可配置的构造块连接在一起就可以构建 Keras 模型,并且几乎不受限制。- 易于扩展
可以编写自定义构造块以表达新的研究创意,并且可以创建新层、损失函数并开发先进的模型。
官方教程:https://www.tensorflow.org/guide/keras
Keras中文教程:https://keras-cn.readthedocs.io/en/latest/ (五分推荐)
2、导入 tf.keras
tf.keras 是 TensorFlow 对 Keras API 规范的实现。这是一个用于构建和训练模型的高阶 API,包含对 TensorFlow 特定功能(例如 Eager Execution、tf.data 管道和 Estimator)的顶级支持。 tf.keras 使 TensorFlow 更易于使用,并且不会牺牲灵活性和性能。
首先,导入 tf.keras 以设置 TensorFlow 程序:
import tensorflow as tf
from tensorflow import kerastf.keras 可以运行任何与 Keras 兼容的代码,但请注意:
- 最新版 TensorFlow 中的
tf.keras版本可能与 PyPI 中的最新keras版本不同。请查看tf.keras.version。- 保存模型的权重时,
tf.keras默认采用检查点格式。请传递save_format='h5'以使用 HDF5。
3、构建简单的模型
3.1、序列模型
在 Keras 中,您可以通过组合层来构建模型。模型(通常)是由层构成的图。最常见的模型类型是层的堆叠:tf.keras.Sequential 模型。
要构建一个简单的全连接网络(即多层感知器),请运行以下代码:
model = keras.Sequential()
# Adds a densely-connected layer with 64 units to the model:
model.add(keras.layers.Dense(64, activation='relu'))
# Add another:
model.add(keras.layers.Dense(64, activation='relu'))
# Add a softmax layer with 10 output units:
model.add(keras.layers.Dense(10, activation='softmax'))图文例子:



3.2、配置层
我们可以使用很多 tf.keras.layers,它们具有一些相同的构造函数参数:
activation:设置层的激活函数。此参数由内置函数的名称指定,或指定为可调用对象。默认情况下,系统不会应用任何激活函数。kernel_initializer和bias_initializer:创建层权重(核和偏差)的初始化方案。此参数是一个名称或可调用对象,默认为"Glorot uniform"初始化器。kernel_regularizer和bias_regularizer:应用层权重(核和偏差)的正则化方案,例如 L1 或 L2 正则化。默认情况下,系统不会应用正则化函数。
以下代码使用构造函数参数实例化 tf.keras.layers.Dense 层:
# Create a sigmoid layer:
layers.Dense(64, activation='sigmoid')
# Or:
layers.Dense(64, activation=tf.sigmoid)
# A linear layer with L1 regularization of factor 0.01 applied to the kernel matrix:
layers.Dense(64, kernel_regularizer=keras.regularizers.l1(0.01))
# A linear layer with L2 regularization of factor 0.01 applied to the bias vector:
layers.Dense(64, bias_regularizer=keras.regularizers.l2(0.01))
# A linear layer with a kernel initialized to a random orthogonal matrix:
layers.Dense(64, kernel_initializer='orthogonal')
# A linear layer with a bias vector initialized to 2.0s:
layers.Dense(64, bias_initializer=keras.initializers.constant(2.0))4、训练和评估
4.1、设置训练流程
构建好模型后,通过调用 compile 方法配置该模型的学习流程:
model.compile(optimizer=tf.train.AdamOptimizer(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])tf.keras.Model.compile 采用三个重要参数:
optimizer:此对象会指定训练过程。从tf.train模块向其传递优化器实例,例如AdamOptimizer、RMSPropOptimizer或GradientDescentOptimizer。loss:要在优化期间最小化的函数。常见选择包括均方误差 (mse)、categorical_crossentropy和binary_crossentropy。损失函数由名称或通过从tf.keras.losses模块传递可调用对象来指定。metrics:用于监控训练。它们是tf.keras.metrics模块中的字符串名称或可调用对象。
以下代码展示了配置模型以进行训练的几个示例:
# Configure a model for mean-squared error regression.
model.compile(optimizer=tf.train.AdamOptimizer(0.01),
loss='mse', # mean squared error
metrics=['mae']) # mean absolute error
# Configure a model for categorical classification.
model.compile(optimizer=tf.train.RMSPropOptimizer(0.01),
loss=keras.losses.categorical_crossentropy,
metrics=[keras.metrics.categorical_accuracy])4.2、输入 NumPy 数据
对于小型数据集,请使用内存中的 NumPy 数组训练和评估模型。使用 fit 方法使模型与训练数据“拟合”:
import numpy as np
data = np.random.random((1000, 32))
labels = np.random.random((1000, 10))
model.fit(data, labels, epochs=10, batch_size=32)tf.keras.Model.fit 采用三个重要参数:
epochs:以周期为单位进行训练。一个周期是对整个输入数据的一次迭代(以较小的批次完成迭代)。batch_size:当传递 NumPy 数据时,模型将数据分成较小的批次,并在训练期间迭代这些批次。此整数指定每个批次的大小。请注意,如果样本总数不能被批次大小整除,则最后一个批次可能更小。validation_data:在对模型进行原型设计时,您需要轻松监控该模型在某些验证数据上达到的效果。传递此参数(输入和标签元组)可以让该模型在每个周期结束时以推理模式显示所传递数据的损失和指标。
下面是使用 validation_data 的示例:
import numpy as np
data = np.random.random((1000, 32))
labels = np.random.random((1000, 10))
val_data = np.random.random((100, 32))
val_labels = np.random.random((100, 10))
model.fit(data, labels, epochs=10, batch_size=32,
validation_data=(val_data, val_labels))4.3、输入 tf.data 数据集
使用 Datasets API 可扩展为大型数据集或多设备训练。将 tf.data.Dataset 实例传递到 fit 方法:
# Instantiates a toy dataset instance:
dataset = tf.data.Dataset.from_tensor_slices((data, labels))
dataset = dataset.batch(32)
dataset = dataset.repeat()
# Don't forget to specify `steps_per_epoch` when calling `fit` on a dataset.
model.fit(dataset, epochs=10, steps_per_epoch=30)在上方代码中,fit 方法使用了 steps_per_epoch 参数(该参数表示模型在进入下一个周期之前运行的训练步数)。由于 Dataset 会生成批次数据,因此该代码段不需要 batch_size。
数据集也可用于验证:
dataset = tf.data.Dataset.from_tensor_slices((data, labels))
dataset = dataset.batch(32).repeat()
val_dataset = tf.data.Dataset.from_tensor_slices((val_data, val_labels))
val_dataset = val_dataset.batch(32).repeat()
model.fit(dataset, epochs=10, steps_per_epoch=30,
validation_data=val_dataset,
validation_steps=3)4.4、评估和预测
tf.keras.Model.evaluate 和 tf.keras.Model.predict 方法可以使用 NumPy 数据和 tf.data.Dataset。
要评估所提供数据的推理模式损失和指标,请运行以下代码:
model.evaluate(x, y, batch_size=32)
model.evaluate(dataset, steps=30)要在所提供数据(采用 NumPy 数组形式)的推理中预测最后一层的输出,请运行以下代码:
model.predict(x, batch_size=32)
model.predict(dataset, steps=30)5、构建高级模型
5.1、函数式 API
tf.keras.Sequential 模型是层的简单堆叠,无法表示任意模型。使用 Keras 函数式 API 可以构建复杂的模型拓扑,例如:
- 多输入模型,
- 多输出模型,
- 具有共享层的模型(同一层被调用多次),
- 具有非序列数据流的模型(例如,剩余连接)。
使用函数式 API 构建的模型具有以下特征:
- 层实例可调用并返回张量。
- 输入张量和输出张量用于定义
tf.keras.Model实例。- 此模型的训练方式和
Sequential模型一样。
以下示例使用函数式 API 构建一个简单的全连接网络:
inputs = keras.Input(shape=(32,)) # Returns a placeholder tensor
# A layer instance is callable on a tensor, and returns a tensor.
x = keras.layers.Dense(64, activation='relu')(inputs)
x = keras.layers.Dense(64, activation='relu')(x)
predictions = keras.layers.Dense(10, activation='softmax')(x)
# Instantiate the model given inputs and outputs.
model = keras.Model(inputs=inputs, outputs=predictions)
# The compile step specifies the training configuration.
model.compile(optimizer=tf.train.RMSPropOptimizer(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
# Trains for 5 epochs
model.fit(data, labels, batch_size=32, epochs=5)5.2、模型子类化
通过对 tf.keras.Model 进行子类化并定义您自己的前向传播来构建完全可自定义的模型。在 __init__ 方法中创建层并将它们设置为类实例的属性。在 call 方法中定义前向传播。
在启用 Eager Execution 时,模型子类化特别有用,因为可以命令式地编写前向传播。
要点:针对作业使用正确的 API。虽然模型子类化较为灵活,但代价是复杂性更高且用户出错率更高。如果可能,请首选函数式 API。
以下示例展示了使用自定义前向传播进行子类化的 tf.keras.Model:
class MyModel(keras.Model):
def __init__(self, num_classes=10):
super(MyModel, self).__init__(name='my_model')
self.num_classes = num_classes
# Define your layers here.
self.dense_1 = keras.layers.Dense(32, activation='relu')
self.dense_2 = keras.layers.Dense(num_classes, activation='sigmoid')
def call(self, inputs):
# Define your forward pass here,
# using layers you previously defined (in `__init__`).
x = self.dense_1(inputs)
return self.dense_2(x)
def compute_output_shape(self, input_shape):
# You need to override this function if you want to use the subclassed model
# as part of a functional-style model.
# Otherwise, this method is optional.
shape = tf.TensorShape(input_shape).as_list()
shape[-1] = self.num_classes
return tf.TensorShape(shape)
# Instantiates the subclassed model.
model = MyModel(num_classes=10)
# The compile step specifies the training configuration.
model.compile(optimizer=tf.train.RMSPropOptimizer(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
# Trains for 5 epochs.
model.fit(data, labels, batch_size=32, epochs=5)5.3、自定义层
通过对 tf.keras.layers.Layer 进行子类化并实现以下方法来创建自定义层:
build:创建层的权重。使用add_weight方法添加权重。call:定义前向传播。compute_output_shape:指定在给定输入形状的情况下如何计算层的输出形状。- 或者,可以通过实现
get_config方法和from_config类方法序列化层。
下面是一个使用核矩阵实现输入 matmul 的自定义层示例:
class MyLayer(keras.layers.Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyLayer, self).__init__(**kwargs)
def build(self, input_shape):
shape = tf.TensorShape((input_shape[1], self.output_dim))
# Create a trainable weight variable for this layer.
self.kernel = self.add_weight(name='kernel',
shape=shape,
initializer='uniform',
trainable=True)
# Be sure to call this at the end
super(MyLayer, self).build(input_shape)
def call(self, inputs):
return tf.matmul(inputs, self.kernel)
def compute_output_shape(self, input_shape):
shape = tf.TensorShape(input_shape).as_list()
shape[-1] = self.output_dim
return tf.TensorShape(shape)
def get_config(self):
base_config = super(MyLayer, self).get_config()
base_config['output_dim'] = self.output_dim
@classmethod
def from_config(cls, config):
return cls(**config)
# Create a model using the custom layer
model = keras.Sequential([MyLayer(10),
keras.layers.Activation('softmax')])
# The compile step specifies the training configuration
model.compile(optimizer=tf.train.RMSPropOptimizer(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
# Trains for 5 epochs.
model.fit(data, targets, batch_size=32, epochs=5)6、回调
回调是传递给模型的对象,用于在训练期间自定义该模型并扩展其行为。您可以编写自定义回调,也可以使用包含以下方法的内置 tf.keras.callbacks:
tf.keras.callbacks.ModelCheckpoint:定期保存模型的检查点。tf.keras.callbacks.LearningRateScheduler:动态更改学习速率。tf.keras.callbacks.EarlyStopping:在验证效果不再改进时中断训练。tf.keras.callbacks.TensorBoard:使用 TensorBoard 监控模型的行为。
要使用 tf.keras.callbacks.Callback,请将其传递给模型的 fit 方法:
callbacks = [
# Interrupt training if `val_loss` stops improving for over 2 epochs
keras.callbacks.EarlyStopping(patience=2, monitor='val_loss'),
# Write TensorBoard logs to `./logs` directory
keras.callbacks.TensorBoard(log_dir='./logs')
]
model.fit(data, labels, batch_size=32, epochs=5, callbacks=callbacks,
validation_data=(val_data, val_targets))7、保存和恢复
7.1、仅限权重
使用 tf.keras.Model.save_weights 保存并加载模型的权重:
# Save weights to a TensorFlow Checkpoint file
model.save_weights('./my_model')
# Restore the model's state,
# this requires a model with the same architecture.
model.load_weights('my_model')默认情况下,会以 TensorFlow 检查点文件格式保存模型的权重。权重也可以另存为 Keras HDF5 格式(Keras 多后端实现的默认格式):
# Save weights to a HDF5 file
model.save_weights('my_model.h5', save_format='h5')
# Restore the model's state
model.load_weights('my_model.h5')7.2、仅限配置
可以保存模型的配置,此操作会对模型架构(不含任何权重)进行序列化。即使没有定义原始模型的代码,保存的配置也可以重新创建并初始化相同的模型。Keras 支持 JSON 和 YAML 序列化格式:
# Serialize a model to JSON format
json_string = model.to_json()
# Recreate the model (freshly initialized)
fresh_model = keras.models.from_json(json_string)
# Serializes a model to YAML format
yaml_string = model.to_yaml()
# Recreate the model
fresh_model = keras.models.from_yaml(yaml_string)注意:子类化模型不可序列化,因为它们的架构由 call 方法正文中的 Python 代码定义。
8、整个模型
整个模型可以保存到一个文件中,其中包含权重值、模型配置乃至优化器配置。这样,您就可以对模型设置检查点并稍后从完全相同的状态继续训练,而无需访问原始代码。
# Create a trivial model
model = keras.Sequential([
keras.layers.Dense(10, activation='softmax', input_shape=(32,)),
keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(data, targets, batch_size=32, epochs=5)
# Save entire model to a HDF5 file
model.save('my_model.h5')
# Recreate the exact same model, including weights and optimizer.
model = keras.models.load_model('my_model.h5')9、Eager Execution
Eager Execution 是一种命令式编程环境,可立即评估操作。此环境对于 Keras 并不是必需的,但是受 tf.keras 的支持,并且可用于检查程序和调试。
所有 tf.keras 模型构建 API 都与 Eager Execution 兼容。虽然可以使用 Sequential 和函数式 API,但 Eager Execution 对模型子类化和构建自定义层特别有用。与通过组合现有层来创建模型的 API 不同,函数式 API 要求您编写前向传播代码。
请参阅 Eager Execution 指南,了解将 Keras 模型与自定义训练循环和 tf.GradientTape 搭配使用的示例。
10、分布
10.1、Estimator
Estimator API 用于针对分布式环境训练模型。它适用于一些行业使用场景,例如用大型数据集进行分布式训练并导出模型以用于生产。
tf.keras.Model 可以通过 tf.estimator API 进行训练,方法是将该模型转换为 tf.estimator.Estimator 对象(通过 tf.keras.estimator.model_to_estimator)。请参阅用 Keras 模型创建 Estimator。
model = keras.Sequential([layers.Dense(10,activation='softmax'),
layers.Dense(10,activation='softmax')])
model.compile(optimizer=tf.train.RMSPropOptimizer(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
estimator = keras.estimator.model_to_estimator(model)注意:请启用 Eager Execution 以调试 Estimator 输入函数并检查数据。
10.2、多个 GPU
tf.keras 模型可以使用 tf.contrib.distribute.DistributionStrategy 在多个 GPU 上运行。此 API 在多个 GPU 上提供分布式训练,几乎不需要更改现有代码。
目前,tf.contrib.distribute.MirroredStrategy 是唯一受支持的分布策略。MirroredStrategy 通过在一台机器上使用规约在同步训练中进行图内复制。要将 DistributionStrategy 与 Keras 搭配使用,请将 tf.keras.Model 转换为 tf.estimator.Estimator(通过 tf.keras.estimator.model_to_estimator),然后训练 Estimator
以下示例在一台机器上的多个 GPU 间分布了 tf.keras.Model。
首先,定义一个简单的模型:
model = keras.Sequential()
model.add(keras.layers.Dense(16, activation='relu', input_shape=(10,)))
model.add(keras.layers.Dense(1, activation='sigmoid'))
optimizer = tf.train.GradientDescentOptimizer(0.2)
model.compile(loss='binary_crossentropy', optimizer=optimizer)
model.summary()定义输入管道。input_fn 会返回 tf.data.Dataset 对象,此对象用于将数据分布在多台设备上,每台设备处理输入批次数据的一部分。
def input_fn():
x = np.random.random((1024, 10))
y = np.random.randint(2, size=(1024, 1))
x = tf.cast(x, tf.float32)
dataset = tf.data.Dataset.from_tensor_slices((x, y))
dataset = dataset.repeat(10)
dataset = dataset.batch(32)
return dataset接下来,创建 tf.estimator.RunConfig 并将 train_distribute 参数设置为 tf.contrib.distribute.MirroredStrategy 实例。创建 MirroredStrategy 时,您可以指定设备列表或设置 num_gpus 参数。默认使用所有可用的 GPU,如下所示:
strategy = tf.contrib.distribute.MirroredStrategy()
config = tf.estimator.RunConfig(train_distribute=strategy)将 Keras 模型转换为 tf.estimator.Estimator 实例:
keras_estimator = keras.estimator.model_to_estimator(
keras_model=model,
config=config,
model_dir='/tmp/model_dir')最后,通过提供 input_fn 和 steps 参数训练 Estimator 实例:
keras_estimator.train(input_fn=input_fn, steps=10)11、例子1:使用tf.keras搭建mnist手写数字识别网络
导入相关的Python包:
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
import numpy as np
mnist=keras.datasets.mnist11.1、Mnist数据集准备
我们以mnist数据集为例,构建一个神经网络实现手写数字的训练与测试,首先我们需要认识一下mnist数据集,mnist数据集有6万张手写图像,1万张测试图像。Keras通过datase来下载与使用mnist数据集,下载与读取的代码如下:
def get_train_val(mnist_path):
# mnist下载地址:https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
(train_images, train_labels), (test_images, test_labels) = mnist.load_data(mnist_path)
print("train_images nums:{}".format(len(train_images)))
print("test_images nums:{}".format(len(test_images)))
return train_images, train_labels, test_images, test_labels通可以调用下面的函数显示手写数字图像:
def show_mnist(images,labels):
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([ ])
plt.grid(False)
plt.imshow(images[i],cmap=plt.cm.gray)
plt.xlabel(str(labels[i]))
plt.show()

对数据re-scale到0~1.0之间,对标签进行了one-hot编码,代码如下:
# re-scale to 0~1.0之间
train_images=train_images/255.0
test_images=test_images/255.0
train_labels=one_hot(train_labels)
test_labels=one_hot(test_labels)其中one-hot编码函数如下:
def one_hot(labels):
onehot_labels=np.zeros(shape=[len(labels),10])
for i in range(len(labels)):
index=labels[i]
onehot_labels[i][index]=1
return onehot_labels11.2、建立模型
构建神经网络
- 输入层为28x28=784个输入节点
- 隐藏层120个节点
- 输出层10个节点
首先需要定义模型:
model = keras.Sequential()然后按顺序添加模型各层
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(units=120, activation=tf.nn.relu))
model.add(keras.layers.Dense(units=10, activation=tf.nn.softmax))封装成一个函数:
def mnist_net():
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(units=120, activation=tf.nn.relu))
model.add(keras.layers.Dense(units=10, activation=tf.nn.softmax))
return model编译模型
模型还需要再进行几项设置才可以开始训练。这些设置会添加到模型的编译步骤:
损失函数
衡量模型在训练期间的准确率。我们希望尽可能缩小该函数,以“引导”模型朝着正确的方向优化。
优化器
根据模型看到的数据及其损失函数更新模型的方式。
指标
用于监控训练和测试步骤。以下示例使用准确率,即图像被正确分类的比例
model.compile(optimizer=tf.train.AdamOptimizer(),loss="categorical_crossentropy",metrics=['accuracy'])
训练模型
训练神经网络模型需要执行以下步骤:
将训练数据馈送到模型中,在本示例中为 train_images 和 train_labels 数组。
模型学习将图像与标签相关联。我们要求模型对测试集进行预测,在本示例中为 test_images 数组。我们会验证预测结果是否与 test_labels 数组中的标签一致。
要开始训练,请调用 model.fit 方法,使模型与训练数据“拟合”:
model.fit(x=train_images,y=train_labels,epochs=5)评估模型
模型在测试集数据上运行:
test_loss,test_acc=model.evaluate(x=test_images,y=test_labels)
print("Test Accuracy %.2f"%test_acc)使用模型进行预测
# 开始预测
cnt=0
predictions=model.predict(test_images)
for i in range(len(test_images)):
target=np.argmax(predictions[i])
label=np.argmax(test_labels[i])
if target==label:
cnt +=1
print("correct prediction of total : %.2f"%(cnt/len(test_images)))保存模型
model.save('mnist-model.h5')完整的训练代码:
# -*-coding: utf-8 -*-
"""
@Project: tensorflow-yolov3
@File : keras_mnist.py
@Author : panjq
@E-mail : pan_jinquan@163.com
@Date : 2019-01-31 09:30:12
"""
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
import numpy as np
mnist=keras.datasets.mnist
def get_train_val(mnist_path):
# mnist下载地址:https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
(train_images, train_labels), (test_images, test_labels) = mnist.load_data(mnist_path)
print("train_images nums:{}".format(len(train_images)))
print("test_images nums:{}".format(len(test_images)))
return train_images, train_labels, test_images, test_labels
def show_mnist(images,labels):
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([ ])
plt.grid(False)
plt.imshow(images[i],cmap=plt.cm.gray)
plt.xlabel(str(labels[i]))
plt.show()
def one_hot(labels):
onehot_labels=np.zeros(shape=[len(labels),10])
for i in range(len(labels)):
index=labels[i]
onehot_labels[i][index]=1
return onehot_labels
def mnist_net():
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(units=120, activation=tf.nn.relu))
model.add(keras.layers.Dense(units=10, activation=tf.nn.softmax))
return model
def trian_model(train_images,train_labels,test_images,test_labels):
# re-scale to 0~1.0之间
train_images=train_images/255.0
test_images=test_images/255.0
train_labels=one_hot(train_labels)
test_labels=one_hot(test_labels)
# 建立模型
model = mnist_net()
model.compile(optimizer=tf.train.AdamOptimizer(),loss="categorical_crossentropy",metrics=['accuracy'])
model.fit(x=train_images,y=train_labels,epochs=5)
test_loss,test_acc=model.evaluate(x=test_images,y=test_labels)
print("Test Accuracy %.2f"%test_acc)
# 开始预测
cnt=0
predictions=model.predict(test_images)
for i in range(len(test_images)):
target=np.argmax(predictions[i])
label=np.argmax(test_labels[i])
if target==label:
cnt +=1
print("correct prediction of total : %.2f"%(cnt/len(test_images)))
model.save('mnist-model.h5')
if __name__=="__main__":
mnist_path = 'D:/MyGit/tensorflow-yolov3/data/mnist.npz'
train_images, train_labels, test_images, test_labels=get_train_val(mnist_path)
show_mnist(train_images, train_labels)
trian_model(train_images, train_labels, test_images, test_labels)
11.3、构建卷积神经网络
mnist数据转换为四维
# mnist数据转换为四维
train_images=np.expand_dims(train_images,axis = 3)
test_images=np.expand_dims(test_images,axis = 3)
print("train_images :{}".format(train_images.shape))
print("test_images :{}".format(test_images.shape))创建模型并构建CNN各层
def mnist_cnn(input_shape):
'''
构建一个CNN网络模型
:param input_shape: 指定输入维度,当然也可以指定
:return:
'''
model=keras.Sequential()
model.add(keras.layers.Conv2D(filters=32,kernel_size = 5,strides = (1,1),
padding = 'same',activation = tf.nn.relu,input_shape = input_shape))
model.add(keras.layers.MaxPool2D(pool_size=(2,2), strides = (2,2), padding = 'valid'))
model.add(keras.layers.Conv2D(filters=64,kernel_size = 3,strides = (1,1),padding = 'same',activation = tf.nn.relu))
model.add(keras.layers.MaxPool2D(pool_size=(2,2), strides = (2,2), padding = 'valid'))
model.add(keras.layers.Dropout(0.25))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(units=128,activation = tf.nn.relu))
model.add(keras.layers.Dropout(0.5))
model.add(keras.layers.Dense(units=10,activation = tf.nn.softmax))
return model
完成的代码:
# -*-coding: utf-8 -*-
"""
@Project: tensorflow-yolov3
@File : keras_mnist.py
@Author : panjq
@E-mail : pan_jinquan@163.com
@Date : 2019-01-31 09:30:12
"""
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
import numpy as np
mnist=keras.datasets.mnist
def get_train_val(mnist_path):
# mnist下载地址:https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
(train_images, train_labels), (test_images, test_labels) = mnist.load_data(mnist_path)
print("train_images nums:{}".format(len(train_images)))
print("test_images nums:{}".format(len(test_images)))
return train_images, train_labels, test_images, test_labels
def show_mnist(images,labels):
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([ ])
plt.grid(False)
plt.imshow(images[i],cmap=plt.cm.gray)
plt.xlabel(str(labels[i]))
plt.show()
def one_hot(labels):
onehot_labels=np.zeros(shape=[len(labels),10])
for i in range(len(labels)):
index=labels[i]
onehot_labels[i][index]=1
return onehot_labels
def mnist_net(input_shape):
'''
构建一个简单的全连接层网络模型:
输入层为28x28=784个输入节点
隐藏层120个节点
输出层10个节点
:param input_shape: 指定输入维度,当然也可以指定
:return:
'''
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=input_shape)) #输出层
model.add(keras.layers.Dense(units=120, activation=tf.nn.relu)) #隐含层
model.add(keras.layers.Dense(units=10, activation=tf.nn.softmax))#输出层
return model
def mnist_cnn(input_shape):
'''
构建一个CNN网络模型
:param input_shape: 指定输入维度,当然也可以指定
:return:
'''
model=keras.Sequential()
model.add(keras.layers.Conv2D(filters=32,kernel_size = 5,strides = (1,1),
padding = 'same',activation = tf.nn.relu,input_shape = input_shape))
model.add(keras.layers.MaxPool2D(pool_size=(2,2), strides = (2,2), padding = 'valid'))
model.add(keras.layers.Conv2D(filters=64,kernel_size = 3,strides = (1,1),padding = 'same',activation = tf.nn.relu))
model.add(keras.layers.MaxPool2D(pool_size=(2,2), strides = (2,2), padding = 'valid'))
model.add(keras.layers.Dropout(0.25))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(units=128,activation = tf.nn.relu))
model.add(keras.layers.Dropout(0.5))
model.add(keras.layers.Dense(units=10,activation = tf.nn.softmax))
return model
def trian_model(train_images,train_labels,test_images,test_labels):
# re-scale to 0~1.0之间
train_images=train_images/255.0
test_images=test_images/255.0
# mnist数据转换为四维
train_images=np.expand_dims(train_images,axis = 3)
test_images=np.expand_dims(test_images,axis = 3)
print("train_images :{}".format(train_images.shape))
print("test_images :{}".format(test_images.shape))
train_labels=one_hot(train_labels)
test_labels=one_hot(test_labels)
# 建立模型
# model = mnist_net(input_shape=(28,28))
model=mnist_cnn(input_shape=(28,28,1))
model.compile(optimizer=tf.train.AdamOptimizer(),loss="categorical_crossentropy",metrics=['accuracy'])
model.fit(x=train_images,y=train_labels,epochs=5)
test_loss,test_acc=model.evaluate(x=test_images,y=test_labels)
print("Test Accuracy %.2f"%test_acc)
# 开始预测
cnt=0
predictions=model.predict(test_images)
for i in range(len(test_images)):
target=np.argmax(predictions[i])
label=np.argmax(test_labels[i])
if target==label:
cnt +=1
print("correct prediction of total : %.2f"%(cnt/len(test_images)))
model.save('mnist-model.h5')
if __name__=="__main__":
mnist_path = 'D:/MyGit/tensorflow-yolov3/data/mnist.npz'
train_images, train_labels, test_images, test_labels=get_train_val(mnist_path)
# show_mnist(train_images, train_labels)
trian_model(train_images, train_labels, test_images, test_labels)
12、例子2:cifar10分类



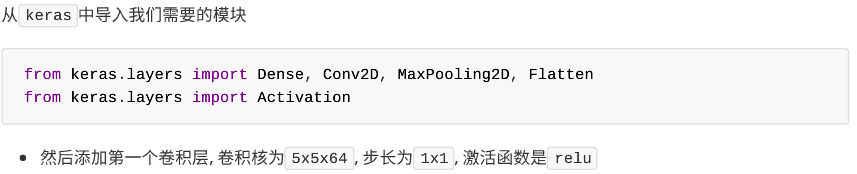






相关文章
- 【C#】Whisper 离线语音识别(微软晓晓语音合成的音频)(带时间戳、srt字幕)...
- [转] web前端js构造无法销毁的类UUID识别码,识别浏览器设备唯一性
- Python的pyhanlp库使用(自然语言识别、姓名)
- 通过ethtool命令解决网络的卡顿、时延、断断续续、路由带*****识别错误
- Google Earth Engine Python ——使用sentinel-1数据识别火灾前后的结果
- 【MATLAB教程案例56】VGG16网络的MATLAB编程学习和实现,以步态识别为例进行仿真分析
- 【车牌识别】基于HOG特征提取和GRNN网络的车牌识别算法matlab仿真
- 【车标识别】基于SIFT算子的车标识别算法matlab仿真
- 【Java】+图片相似度识别
- Windows 10 IoT Serials 10 – 如何使用OCR引擎进行文字识别
- 农业大数据模型-水产养殖水质智能识别
- 对模拟器虚假设备识别能力提升15%!每日清理大师App集成系统完整性检测
- HaGRID手势识别数据集使用说明和下载
- TensorFlow高阶 API: keras教程-使用tf.keras搭建mnist手写数字识别网络
- 面部识别是把双刃剑 取长补短是要诀
- 【树莓派4B学习】十一、树莓派4B实现颜色识别
- 基于SVM的数据分类预測——意大利葡萄酒种类识别
- 一个面部识别的广告创意 吓坏了 Facebook
- Python 模板匹配 匹配一个 识别一个图形
- 手写数字识别