
Linux:文件内容排序和截取工具(sort、uniq、tr、cut)
目录
一、sort工具
sort 是一个以行为单位对文件内容进行排序的工具,也可以根据不同的数据类型来排 序。例如数据和字符的排序就不一样。sort 命令的语法为“sort[选项] 参数”,其中常用的选
项包括以下几种。
-f:忽略大小写;
-b:忽略每行前面的空格;
-M:按照月份进行排序;
-n:按照数字进行排序;
-r:反向排序;
-u:等同于 uniq,表示相同的数据仅显示一行;
-t:指定分隔符,默认使用[Tab]键分隔;
-o <输出文件>:将排序后的结果转存至指定文件;
-k:指定排序区域sort /etc/passwd #将/etc/passwd文件中的账号进行排序
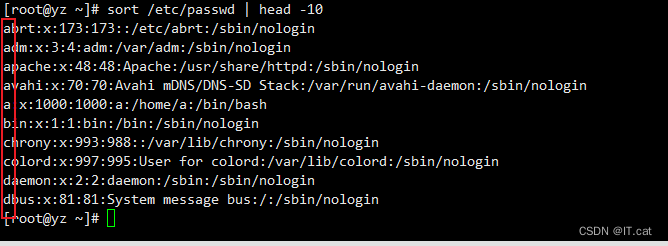
默认按照第一个字符排序
sort -t':' -rk 3 /etc/passwd #对文件中第三列进行反向排序
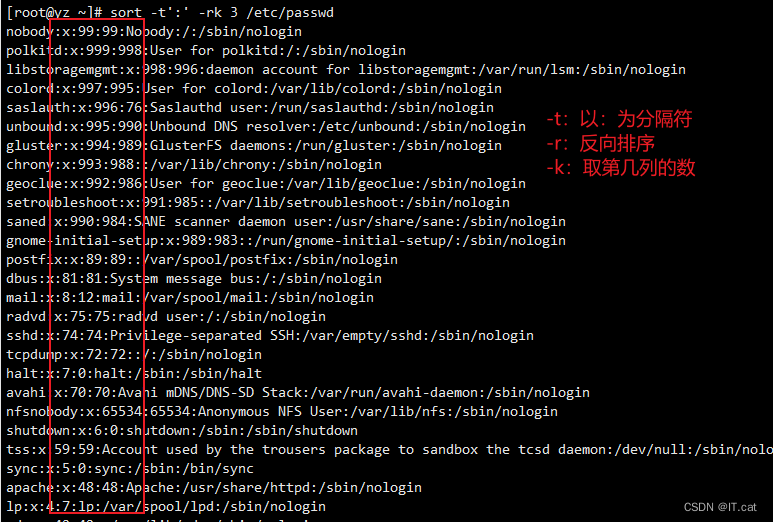
二、uniq工具
Uniq 工具在 Linux 系统中通常与 sort 命令结合使用,用于报告或者忽略文件中的重复 行。具体的命令语法格式为:uniq [选项] 参数。其中常用选项包括以下几种
-c:进行计数;
-d:仅显示重复行;
-u:仅显示出现一次的行。先准备一个文件
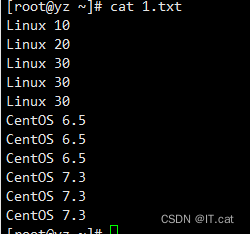
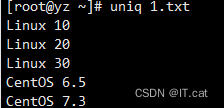
uniq 1.txt #去除重复行
uniq -c 1.txt #删除文件中的重复行,并在行首显示该行重复出现的次数
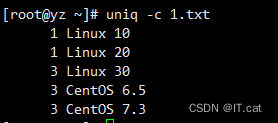
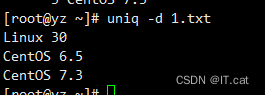
uniq -d 1.txt #查找文件中的重复行。
将sort和uniq结合使用

可以查看现在连接状态
三、tr工具
tr 命令常用来对来自标准输入的字符进行替换、压缩和删除。可以将一组字符替换之后 变成另一组字符,经常用来编写优美的单行命令,作用很强大
-c:取代所有不属于第一字符集的字符;
-d:删除所有属于第一字符集的字符;
-s:把连续重复的字符以单独一个字符表示;
-t:先删除第一字符集较第二字符集多出的字符。
echo "KGC" | tr 'A-Z' 'a-z' #将输入字符由大写转换为小写
![]()
#echo "thissss is a text linnnnnnne." | tr-s'sn' #压缩输入中重复的字符
![]()
echo 'hello world' |tr -d 'od' #删除字符串中某些字符
![]()
四、cut工具
cut命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。
如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一
cut只擅长于处理单个字符为间隔的文本,-b只能分割字母,-c既可以分割字母也可以分割中文
语法格式
cut [选项] [文件路径]
常用选项
-b:按字节截取
-c:按字符截取,常用于中文
-d:指定以什么为分隔符截取,默认为制表符
-f:通常和-d一起使用(表示截取第几列)echo "12345" | cut -b 1-2 #截取前两个字符
![]()
echo "1:2:3:4:5" | cut -d':' -f 1,4 #以:为分隔符,截取第1和第4列
![]()
![]()
相关文章
- Linux中在主机上实现对备机上文件夹及文件的操作的C代码实现
- Linux(入门)---001.desktop文件教程
- Linux df 查看磁盘空间使用量 du 查看指定目录/文件的大小
- 常用Linux命令,新必须掌握
- linux 将一个服务器上的文件或者文件夹复制到另一台服务器上
- 用linux mail命令发送邮件[Linux]
- linux中查找最近或今天修改过的文件
- 在Linux中的使用 ss 命令检查套接字/网络连接
- ant使用ssh和linux交互 如:上传文件
- linux下的什么工具可以用来查看PostScript文件?
- Linux split文件切分工具的使用
- 【Linux】文件拷贝-Linux当前目录所有文件移动到上一级目录(转)
- 基于linux环境的MP3文件转WAV文件实例解析
- putty对Linux上传下载文件或文件夹
- 《树莓派Python编程入门与实战》——第2章 认识Raspbian Linux发行版 2.1 了解Linux
- nginx验证微信文件(linux服务器添加校验文件)
- Linux 下获取进程所在文件的路径
- 使用 Linux 命令来获取输入文件中特定字符的出现次数
- 关于Linux操作系统层次结构分析
- linux下多进程同时操作文件
- php 将office文件(word/excel/ppt)转化为pdf(windows和linux只要安装对应组件应该就行)
- Linux基础:文件基础属性及如何更改文件属性、文件与目录管理、linux软硬链接的理解、linux用户和用户组管理
- Linux 文件的读写执行权限的说明
- Linux 系统必须掌握的文件_【all】
- [Linux]Linux环境,如何查找一个目录下所有包含特定字符串的文件
- 介绍两款Linux文件恢复工具,ext3grep与extundelete https://www.cnblogs.com/lazyfang/p/7699994.html
- 【正点原子FPGA连载】第十一章U-Boot使用实验 摘自【正点原子】DFZU2EG_4EV MPSoC之嵌入式Linux开发指南
- [加入用户]解决useradd 用户后没有加入用户Home文件夹的情况,Linux改变文件或文件夹的訪问权限命令,linux改动用户password,usermod的ysuum安装包。飞
- Linux常用命令参考与指南
- linux编写脚本执行.py文件