
Prometheus+grafana监控--初探
目录
概述
Prometheus 是一个开源监控系统,它前身是 SoundCloud的告警工具包。从 2012 年开始,许多公司和组织开始使用 Prometheus。该项目的开发人员和用户社区非常活跃,越来越多的开发人员和用户参与到该项目中。目前它是一个独立的开源项目,且不依赖于任何公司。为了强调这点和明确该项目治理结构,Prometheus 在 2016 年继Kurberntes 之后,加入了 Cloud Native Computing Foundation。
Zabbix和Prometheus区别
和Zabbix类似,Prometheus也是一个近年比较火的开源监控框架,和Zabbix不同之处在于Prometheus相对更灵活点,模块间比较解耦,比如告警模块、代理模块等等都可以选择性配置。服务端和客户端都是开箱即用,不需要进行安装。zabbix则是一套安装把所有东西都弄好,很庞大也很繁杂。 zabbix的客户端agent可以比较方便的通过脚本来读取机器内数据库、日志等文件来做上报。而Prometheus的上报客户端则分为不同语言的SDK和不同用途的exporter两种,比如如果你要监控机器状态、mysql性能等,有大量已经成熟的exporter来直接开箱使用,通过http通信来对服务端提供信息上报(server去pull信息);而如果你想要监控自己的业务状态,那么针对各种语言都有官方或其他人写好的sdk供你使用,都比较方便,不需要先把数据存入数据库或日志再供zabbix-agent采集。 zabbix的客户端更多是只做上报的事情,push模式。而Prometheus则是客户端本地也会存储监控数据,服务端定时来拉取想要的数据。 界面来说zabbix比较陈旧,而prometheus比较新且非常简洁,简洁到只能算一个测试和配置平台。要想获得良好的监控体验,搭配Grafana还是二者的必走之路。
prometheus特点
多维度数据模型,一个时间序列由一个度量指标和多个标签键值对确定 灵活的查询语言,对收集的时许数据进行重组 强大的数据可视化功能,除了内置的浏览器,也支持grafana集成 高效存储,内存加本地磁盘,可通过功能分片和联盟来拓展性能 运维简单,只依赖于本地磁盘,go二进制安装包没有任何其他依赖 精简告警 非常多的客户端库 提供了许多导出器来收集常用系统指标
promQL一种灵活的查询语言,可以利用多维数据完成复杂查询
Prometheus基础架构
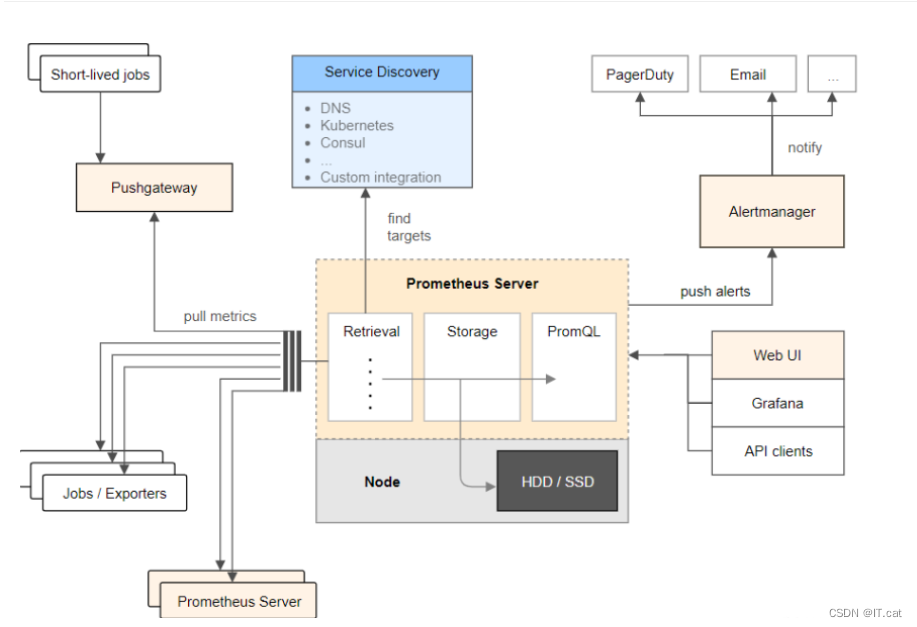
service discovery:服务发现
左边部分就是数据采集模块的两种方式如pushgatway和exporters
右边部分就是监控报警模块Prometheus成图绘图增强功能的方式
如上图,Prometheus 主要由以下部分组成:
Prometheus Server:主要是负责存储、抓取、聚合、查询方面。(服务器端) Alertemanager:主要是负责实现报警功能。 Pushgateway:主要是实现接收有 Client-push 过来的指标数据,在指定的时间间隔,有主程序来抓取。 *_exporter:主要是负责采集物理机、中间件的信息。(客户端)
报警和监控
报警和监控是需要严格区分开来的,监控是监控数据,报警有自己专门的报警系统,包括:短信报警,邮件报警,电话报警等,不想监控系统比较成型的报警系统,没有钱大多数是要收费的,商业化的。
报警系统中,最重要的一个概念就是对报警阈值的理解
阈值(trigger value):是监控系统中,对数据到达某一个临界值的定义:例如一台机器cpu突然升高,超过了80%的使用率,80就是作为一次报警的出发阈值
优秀的报警系统pagerduty

pagerduty在企业中,尤其是外企出境率非常高,它的费用也相对非常便宜

pagerduty拥有短信,电话,邮件所有的报警机制
pagerduty还有非常实用的必要的运维值班管理制度和报警升级等等扩展功能
不足的问题:对中文支持不好,几乎不支持,站点在外网网络不太行。
Prometheus相比其他的监控,优势
监控数据的惊喜程序,绝对的第一可以精确到1-5s的采集精度
集群部署的速度,监控脚本的制作,非常快速大大缩短监控的搭建时间成本
周边插件很丰富,大多数都不需要自己开发
本身基于数学计算模型,大量的实用函数,可以实现很复杂的业务逻辑监控
可以嵌入很多开源工具的内部进行监控,数据更准时更可信
本身是开源的,更新速度快,bug修复快,支持n多种语言做本身和插件的二次开发
图形很难高大上很美观,老板特别喜欢这周业务图(和grafana的结合)
不足的地方
因数据采集的精度,如果集群数量太大,那么单点的监控有性能瓶颈,目前尚不支持集群,只能workaround
学习成本太大,尤其是其独有的数学命令行(非常强大的同时有机器难学),中文资料少
对磁盘资源消耗也非常大,这个具体要看监控的集群量和监控项的多少,还有保存时间的长短
本身的实用需要使用者的数学不难太差
监控的分类
业务监控:可以包含用户访问QPS,DAU日活,访问状态,业务接口(登陆,注册,聊天,上传等)
系统监控:主要是跟操作系统相关基本监控项,CPU/内存/硬盘/IO/TCP链接/流量
网络监控:对网络状态的监控,互联网公司必不可少,但很多时候会被忽略,如:丢包率,延迟等
日志监控:监控种的重头戏,往往单独设计和搭建,全部种类的日志都需要采集
程序监控:一般需要和开发人员配置,程序中嵌入各种接口,直接获取数据或者特质的日志格式
Prometheus监控的优质特性
基于时间序列模型(time series)
时间序列(time series)是一系列有序的数据,通常是等时间间隔的采样数据
基于K/V的数据模型
Key/value键值的概念:数据格式简单,速度快,易维护开发
采样数据的查询完全基于数学的运算,而不是其他的表达式,并提供转悠的查询输入console
采用HTTP pull/push两种对应的数据采集传输方式
开源,且大量的社区成品插件
push的方法,非常非常的灵活
本身自带图形调试
最精细的数据采样
Prometheus安装-图形界面展示
tar -xvf prometheus-2.38.0.linux-amd64.tar.gz -C /usr/local
mv prometheus-2.38.0.linux-amd64/ prometheus启动Prometheus
#两种启动方式,前台启动和后台启动
./prometheus
nohup /usr/local/prometheus/prometheus --config.my-cnf=/usr/local/prometheus/prometheus &
访问prometheus界面(默认端口9090)
打开的文件描述符数 process_open_fds


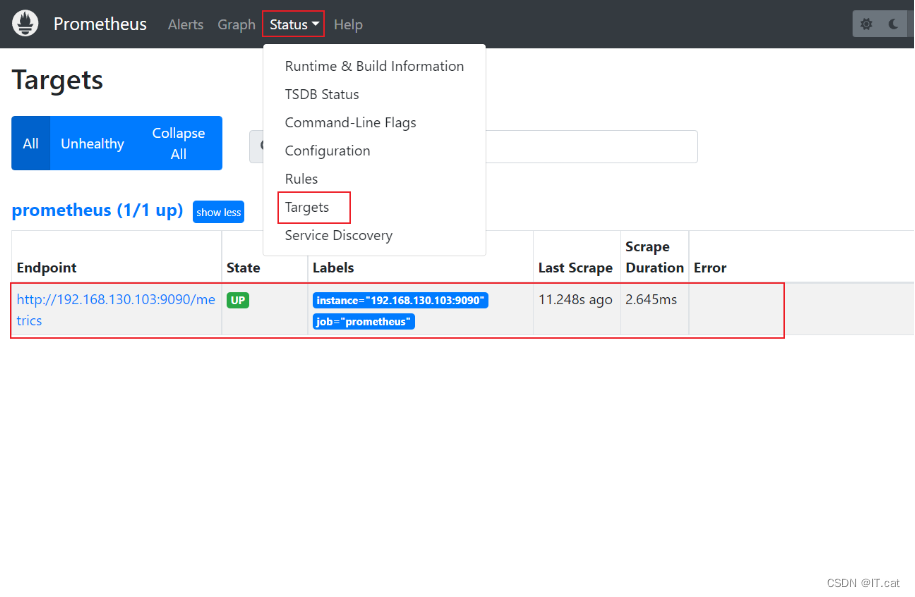
在status下的targets就能看到被监控的目标主机采集的数据
Prometheus组件

这里就是Prometheus的服务端,也就是核心
Prometheus本身是一个以进程方式启动,之后以多进程和多线程实现监控数据收集,计算,查询,更新,存储的这样一个C/S模型运行模式,本身启动很简单
prometheus 采用的是 time-series (时间序列)的方式以一种自定义的格式存储在本地硬盘上 prometheus的本地T-S(time-series)数据库以每两小时为间隔来分block(块)存储,每一个块中又分为多个chunk文件(我们以后会介绍chunk的概念),chunk文件是用来存放采集过来的数据的T-S数据,metadata和索引文件(index)
index文件是对metrics(prometheus中一灰K/V采集数据叫做一个metric)和labels(标签)进行索引之后存储在chunk中 chunk 是作为存储的基本单位,index and metadata是作为子集 prometheus平时是将采集过来的数据先都存放在内存之中(prometheus对内存的消耗还是不小的)以类似缓存的方式用于加快搜索和访问当出现当机时,prometheus有一种保拒机制叫做WAL可以讲数据定期存入硬盘中以chunk来表示,并在重新后动时用以恢复进入内存

这里面主要是Prometheus可以集成的服务发现功能
例如Consul
Prometheus采集客户端部分

Prometheus的客户端有两种方式
pull主动拉取的形式
pull:指的是客户端(被监控机器)先安装各类已有exporters(由社区组织或企业开发的监控客户端插件)在系统上,之后,exporters以守护进程的模式运行并开始采集数据
exports本身也是一个http_server可以对http请求作出响应,返回数据
Prometheus用pull这种主动拉的方式(HTTP get)取访问每个节点上exports并采样回需要的数据push被动推送的形式

指的是在客户端(或者服务器)安装这个官方提供的oushgetway插件
然后,使用我们运维自行开发的各种脚本,把监控数据组织成K/V形式metrics形式发送给pushgetway之后pushgetway回在推送给Prometheus
这种是一种被动的数据采集模式报警绘图部分
alertmanager是监控和其他商业报警的桥梁,当有数据超过阈值,Prometheus会将报警信息通过alertmanager会将报警再推给其他报警平台,才会实现真正报警,这里不需要多说alertmanage(有很多功能缺陷),而且我们会使用更高级的绘图平台如grafana中,通过这些平台自带的报警系统去实现,而不再用自带的alertmanager。
Prometheus metrics概念
Prometheus监控中对于采集过来的数据同一称为metrics数据。当我们需要为某个系统某个服务做监控,做统计,就需要用到metrics
metrics是一种对采样数据的总称(metrics并不代表某一种具体的数据格式 是一种对于度量计算单的抽象)
metrics的几种类型
Gauges
存储的是当前状态的快照,其关心的是数值本身,因此此类型的数据类型的值可升可降。例如: 使用Gauge数据类型的例子包括队列中元素个数、缓存的内存使用率,活跃的线程数,最后一分钟时间里没秒的平均请求数。
最简单的度量指标,只有一个简单的返回值,或者叫瞬时状态,例如我们想衡量一个待处理队列中任务的个数(例如:我们要监控硬盘容量或者内存的使用量,那么就i一个使用gauges的metrics格式来度量,因为硬盘的容量或者内存的使用量是醉着时间的推移,不断地瞬间,没有规则变化地,这种变化没有规律当前是多少,采集回来就是多少,既不能肯定是一直持续增长的,也不能肯定是一直降低,是多少就是多少,这就是gauges使用的类型的代表)
counters
描述: 它是使用最频繁的数据类型,其记录的是事件的数量或者大小,通常用来跟踪某个特定代码路径被执行的频率,此类型其根本的的意义是计数器随着时间的推移而增加的速度。
counter就是计数器,从数据0开始累计计算,在理想状态下只能是永远的增长不会降低(一些特殊情况另说)
举个例子说明:比如对用户访问量的采样数据,我们的产品被用户访问一次就是1,过了10分钟后累积到100,国一天后累计到20000
一周后积累到100000-150000
process_cpu_seconds_total 用户和系统的总cpu使用时间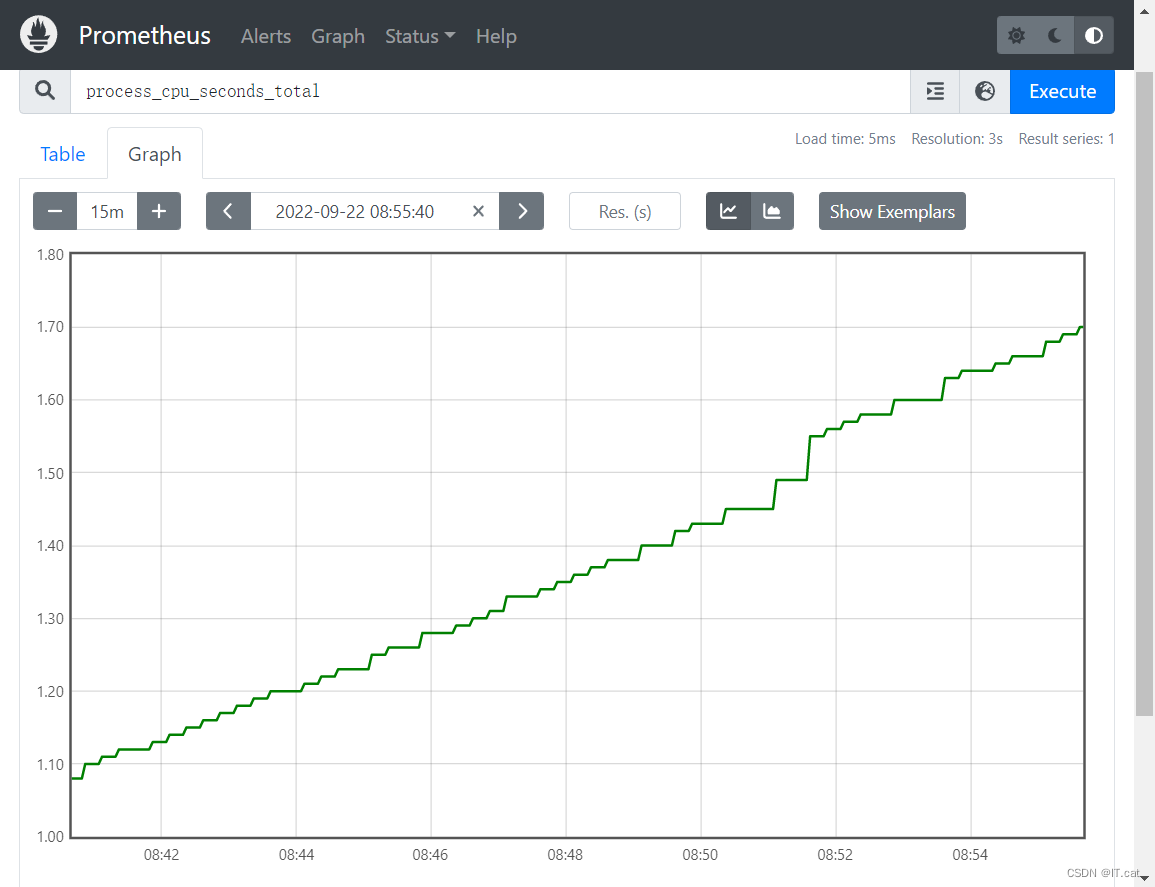
Histograms
histogram统计数据的分布情况,比如最小值,最大值,中间值,还有中位数,75百分位,90百分位,98百分位,99百分位和99.9百分位的值
这是一种特殊的metrics数据类型,代表的是一种近似的百分比估算数值
举个例子,我们日后在企业工作中经常接触这种数据
Http_response_time HTTP响应时间
代表一次用户HTTP请求在系统传输和执行过程中,总共花费的时间
日常中,假设我们一天下来,线上没有发生故障,大部分用户的响应时间都在0.05s(通过总时长/总次数)但是我们不要忘记了,任何系统中都一定存在慢请求,就是右一少部分的用户请求时间会比总的平均值大很多,甚至接近5s,10s的也有(这种情况很普遍,因为各种因素,可能是软件本身的bug,也可能是系统的原因,更有可能是少部分用户的使用途径中出现了问题)
那么我们的监控需要发现和报警这种少部分的特殊情况,用总平均能获得吗
如果采取总平均的方式,那么不管发生上面特殊情况,因为发部分的用户响应都是正常的,你永远也发现不了少部分的问题
所以histogram的metrics类型在这种时候就派上用场了
通过histogram的metrics类型(Prometheus提供了一个基于histogram算法的函数,可以直接使用)可以分别统计出全部用户的响应时间中~=0.05s的量有多少,0~0.05s的有多少,>2s的有多少
我们就可以清晰的看到当前我们的系统中处于基本正常状态的有多少百分比的用户(或是请求)
metrics的类型其实还有另外的类型,但是上述三种是用的比较多的,能满足大部分需求
k/v的数据形式
我们在前面了解了metrics的概念和类型
Prometheus的数据类型就是依赖于这种metrics的类型来计算的
而对于采集回来的数据类型,在往细了说必须要以一种具体的数据格式供我们查看和使用
那么我们来看以下一个exporter给我们采集来的服务器上的k/v形式metrics数据
当一个exporter被安装和运行在被监控的服务器上后,使用简单的curl命令就可以看到exports帮我们采集到metrics数据的样子
curl 192.168.130.15:9104/metrics
其中我们真正关系的数据是这样的
![]()
代表当前采集的最大文件句柄数是1024
![]()
当前被打开的文件句柄数是10
获取系统打开的文件描述符数量
linux/unix,一切皆文件,每一次用户发起请求就会生成一个文件句柄,文件句柄可以理解为就是一个索引,所有文件句柄就会随着请求量的增多,而进程调用的频率增加,文件句柄的产生就会越多,系统对文件句柄默认的限制是1024个,对于nginx来说非常小了,需要改大一点

#内容告诉我们这以向数据的metrics类型属于gauge
exporter的使用
Prometheus官网本身就已经提供了很多可以免费使用的exporter

这些exporter使用的开发语言也不一样,java,py,go都有
我们不管社区组织和开发语言
只需要关系如何下载和正确安装使用就行
大多数exporter下载之后,就提供了启动的命令一般直接运行带上一定的参数就行
比如运用最广泛的node_exporter,这个exporter非常强大,几乎可以把Linux系统中和系统本身相关的监控数据全部抓出来
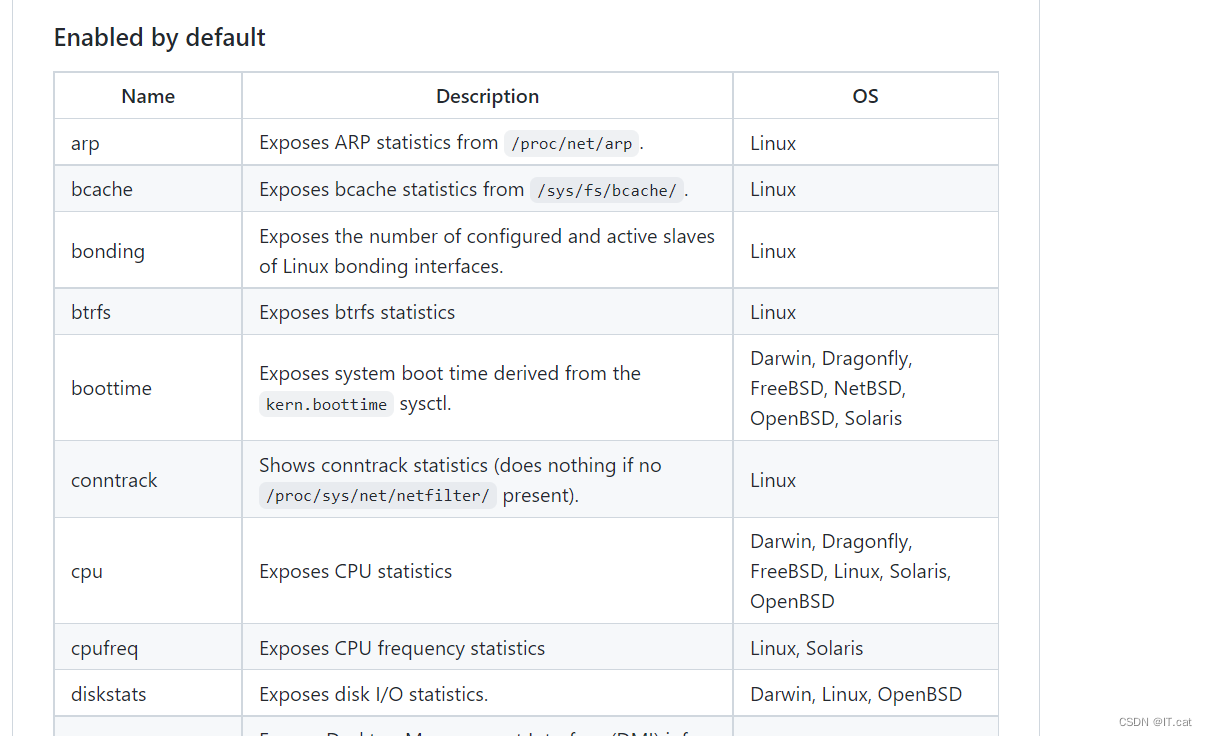
(官方介绍可以抓取的数据)
Prometheus配置文件
prometheus本身跟其他开源软件类似,也是通过定义配置文件,来给prometheus本身规定需要被监控的项目和被监控节点,我们开源看下配置文件的模板
![]()
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. 制定Prometheus采集数据时间间隔是多少,默认每15s去被监控机上采样一次
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. 监控数据规则的评估频率
假如我们设置当内存使用量>70%时,发出报警,这么一条rule(规则)那么Prometheus会默认每15s来执行一次这个规则检查内存情况,但是现在基本使用grafana的报警系统
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
#Alertmanager 是prometheus的一个用于管理和发出报警的插件因为现在基本使用grafana本身的报警系统,所以也不多介绍
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus" #定义任务job名称,在这个jobs的名字下面,具体来定义要被监控的节点,以及节点上具体的端口信息等等,那么如果promoetheus配合了,例如consul这周服务发现软件,prometheus的配置文件就不再需要人工取手工定义出来,而是能自动发现集群中,有哪些新机器以及新机器上出现了哪些新服务可以被监控
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["192.168.130.103:9090"] #将被监控端口暂时改为,只监控本机
#在生产中我们经常会使用(9100是node_exporter的默认端口)
- targets:["server:9100","nginx:9100","web:9100","redis:9100","log:9100"]
#需要注意的是这些域名都得现在/etc/hosts中定义一下或者local_dns server中定义
node_memory_MemFree_bytes #查看空闲内存

到这里会发现Prometheus很简单,一个key_value就能出结果,这是因为我们监控的数据很单一,并没有对更多的监控项进行计算。
较难命令的演示(真正的cpu使用率)
(1-((sum(increase(node_cpu_seconds_total{mode="idle"}[1m]))by(instance))/(sum(increase(node_cpu_seconds_total[1m]))by(instance))))*100

后台启动小工具
screen
yum -y install screenscreen #进入后端
然后执行操作
./prometheus
[ctrl] a d 退出后端就行了 
screen -ls #查看被放入后台的进程
screen -r 12535 #返回后台进程id的前端
部署node_exporter组件
将node_exporter传到需要被监控的MySQL主机上,进行解压

解压
tar -xvf node_exporter-1.4.0-rc.0.linux-amd64.tar.gz -C /usr/local
mv node_exporter-1.4.0-rc.0.linux-amd64/ node_exporter
./node_exporter #开启访问一下
就能看到被监控的数据了,能看到就说明部署完成
部署mysqld_exporter 组件
mysqld_exporter 是 Prometheus 的 MySQL 指标导出插件。Github 地址:GitHub - prometheus/mysqld_exporter: Exporter for MySQL server metrics。这里来演示它的部署。
tar -xvf mysqld_exporter-0.14.0.linux-amd64.tar.gz -C /usr/local
mv mysqld_exporter-0.14.0.linux-amd64/ mysqld_exporter
在mysql中创建监控用户,并赋权
create user 'exporter'@'localhost' IDENTIFIED BY '123456';
GRANT SELECT, PROCESS, SUPER, REPLICATION CLIENT, RELOAD ON *.* TO 'exporter'@'localhost';

为mysqld_exporter 创建个配置文件
vim /usr/local/mysqld_exporter/mysqld_exporter.cnf[client]
user=exporter
password=123456
启动组件
nohup /usr/local/mysqld_exporter/mysqld_exporter --config.my-cnf=/usr/local/mysqld_exporter/mysqld_exporter.cnf &浏览器访问一下默认端口为9104
这样就启动成功了
配置Prometheus获取监控数据
在Prometheus的配置文件中添加node_exporter 和 mysqld_exporter 的配置

然后重启一下

看到新增的被监控节点,就是说明配置成功
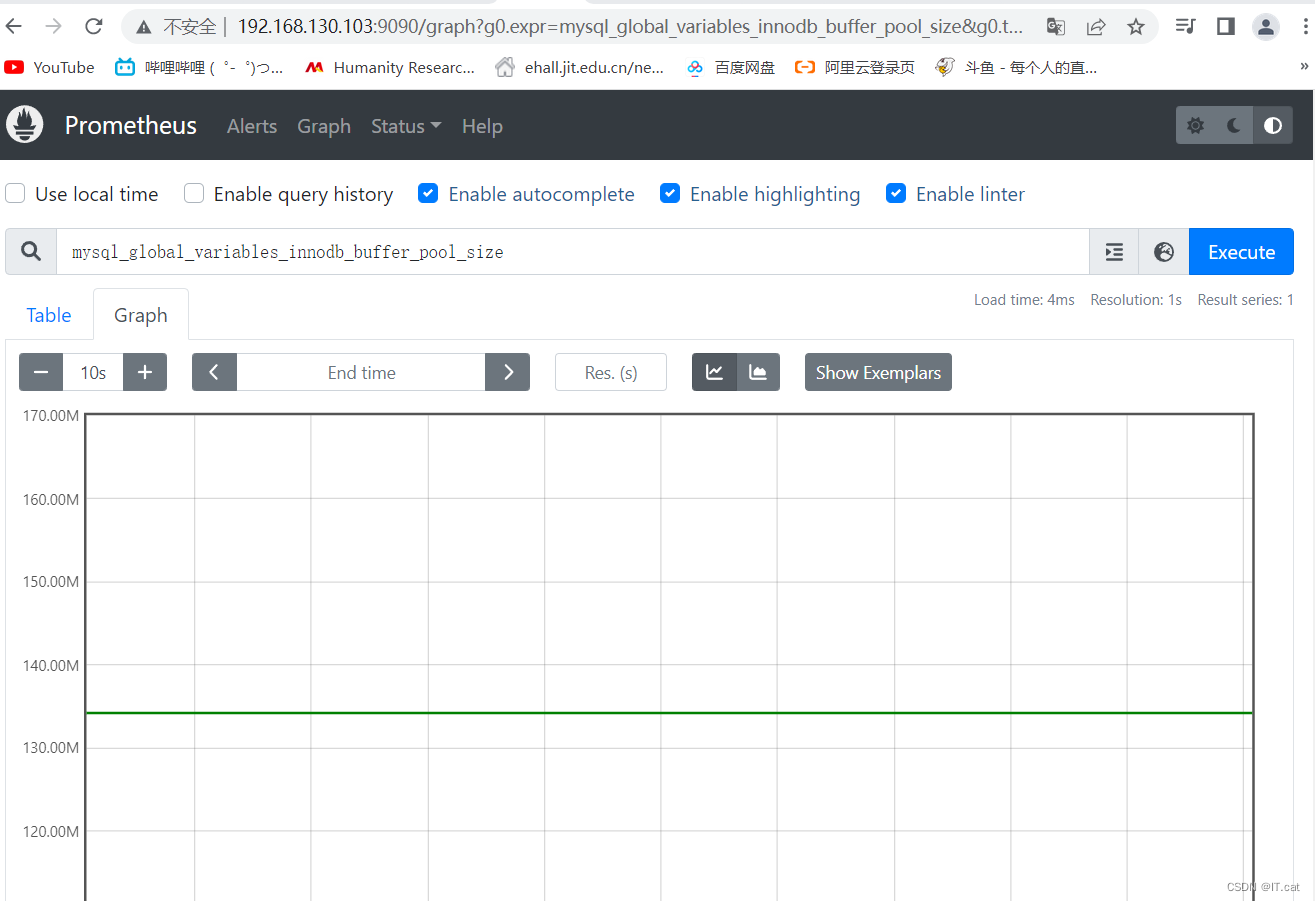
会主界面搜索 MySQL 相关参数,比如:innodb_buffer_pool_size:
部署grafana
Download Grafana | Grafana Labs
wget https://dl.grafana.com/oss/release/grafana-7.4.5-1.x86_64.rpm
yum install grafana-7.4.5-1.x86_64.rpm -y我们找一台192.168.130.102主机来部署grafana

启动一下
systemctl start grafana-server访问一下(grafana默认端口为3000)
用户名密码都是 admin。登录后,会让我们修改密码,则按提示操作即可,当然也可以点击跳过。

这就是grafana的主界面了
为grafana配置Prometheus数据源
点击 “Add data source”
如下图,选择“Prometheus”数据源:

如下图,增加 Prometheus 的 URL 即可:


 Grafana 展示 Linux 的监控数据
Grafana 展示 Linux 的监控数据
按照下图的方式进入模板导入界面:

11074是英文的,8919是中文的,这都是官方的id

点击load就会出现以下画面
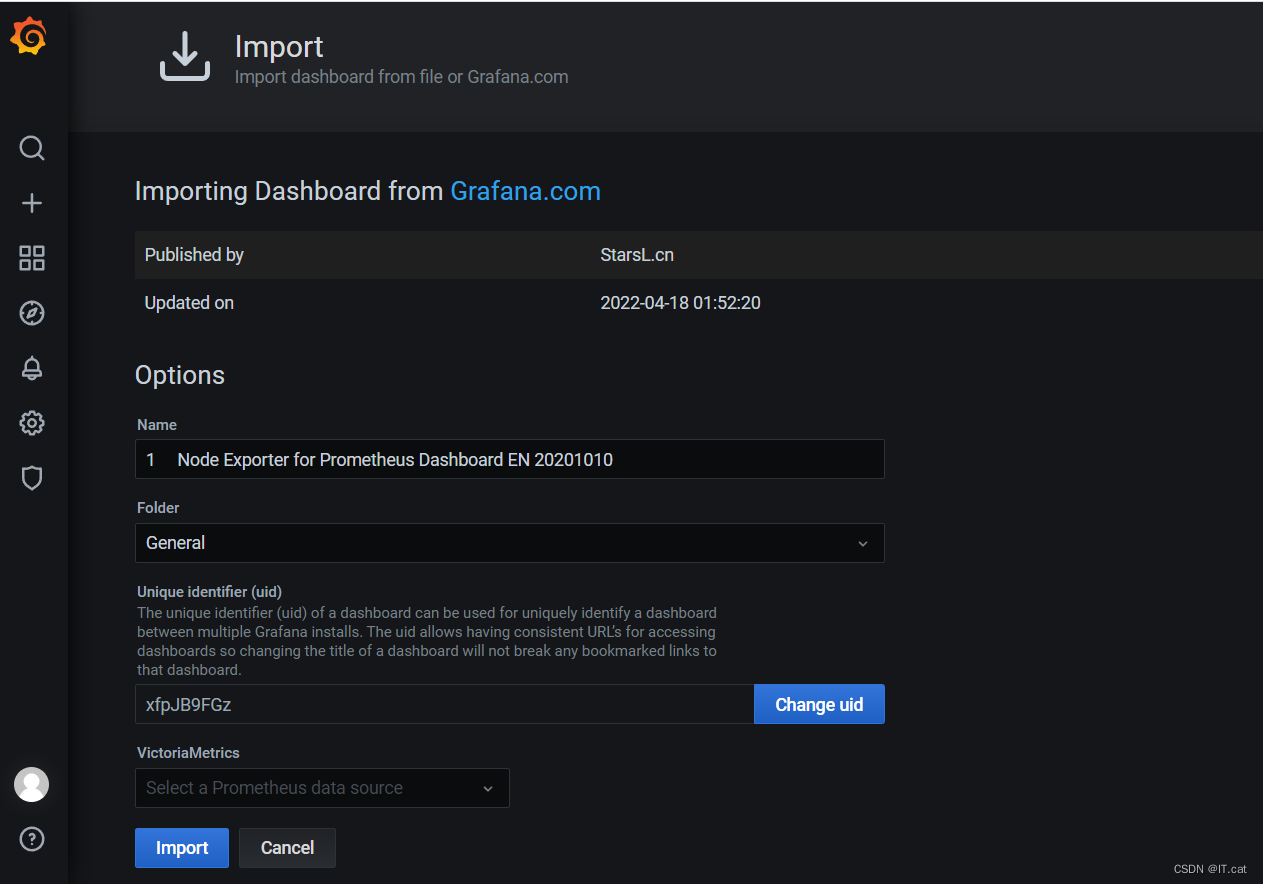
将 Name 改成你希望定义的名字,在 VictoriaMetrics 位置选择之前创建的 Prometheus 数据源,如下图:
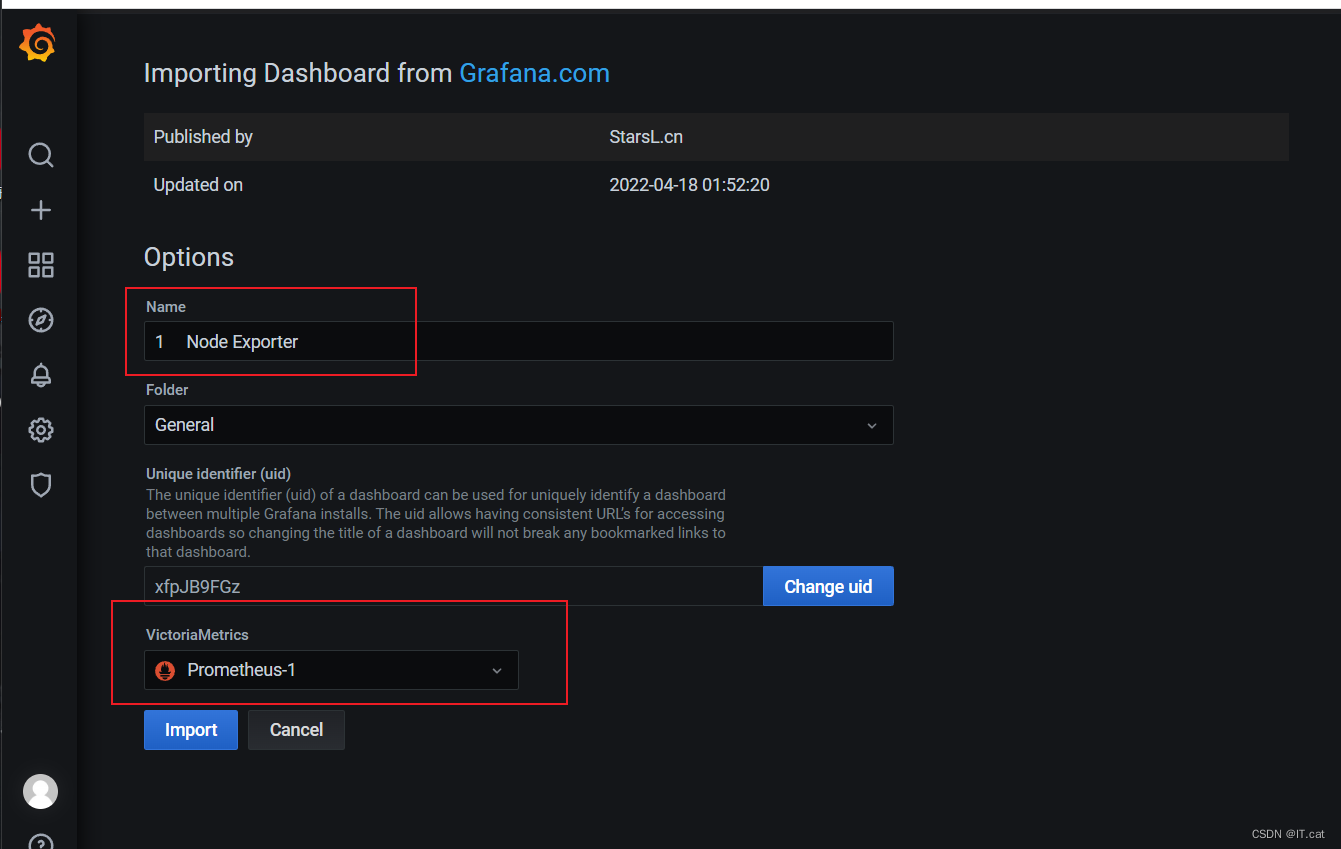
点击 “Import”,会自动跳转到如下界面:

到这里,完成了 Grafana 展示 Prometheus 中 Linux 操作系统的监控数据。
Grafana 展示 MySQL 的监控数据
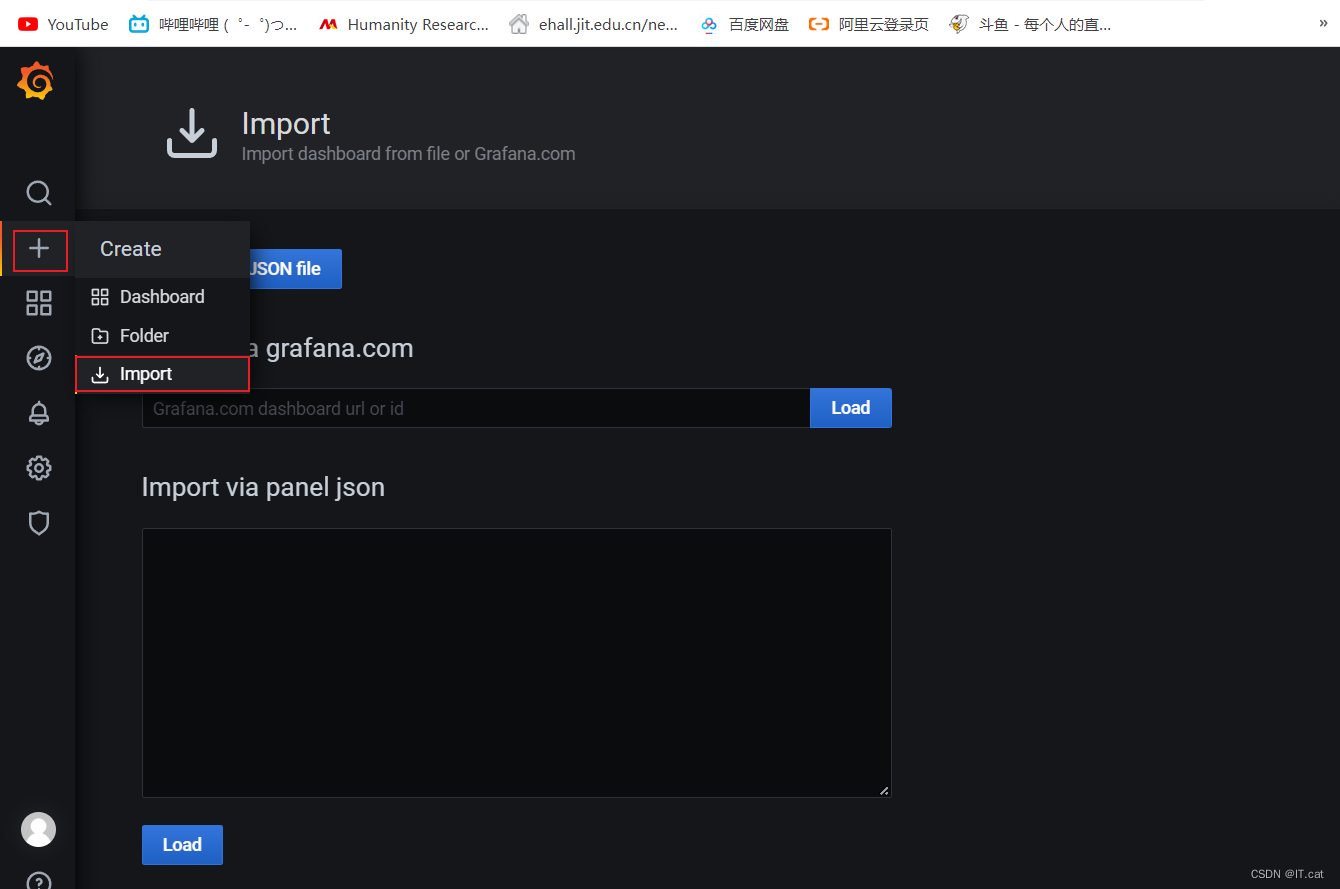
在 “Import via grafana.com” 下方输入 7362:

或者在 MySQL Overview | Grafana Labs 页面下载 JSON 模板,然后点击 “Upload JSON file” 导入,然后会显示如下信息(目前还有其他一些模板,比如 GitHub - percona/grafana-dashboards: PMM dashboards for database monitoring,有兴趣的可以尝试一下):

在 prometheus 选项选择之前创建的 Prometheus 数据源,点击 “Import”,会自动跳转到如下界面:

到这里,完成了 Grafana 展示 Prometheus 中 MySQL 的监控数据。
告警配置
对 Prometheus 中获取的数据进行告警配置,目前有很多方式,比如:
-
通过 Grafana 配置邮件告警
-
通过开源的运维告警中心消息转发系统:PrometheusAlert,Github 地址:GitHub - BegoniaFlowerHome/PrometheusAlert: Prometheus Alert是开源的运维告警中心消息转发系统,支持主流的监控系统Prometheus,Zabbix,日志系统Graylog和数据可视化系统Grafana发出的预警消息,支持钉钉,微信,华为云短信,腾讯云短信,腾讯云电话,阿里云短信,阿里云电话等。
-
等等
本节内容就拿 Grafana 配置邮件告警来举例,PrometheusAlert 在后面的内容中再跟朋友们介绍。编辑 Grafana 配置文件 etc/grafana/grafana.ini,按下图修改 [smtp] 部分配置:

重启 Grafana
systemctl restart grafana-server.service按如下方式进入通知渠道创建界面

填写好收件人,点击 “Test”,如果能正常收到邮件,则说明配置正常。

如果测试正常,则点击“Save”保存配置。
相关文章
- 十五天精通WCF——第十一天 如何对wcf进行全程监控
- url拨测,url访问检测,监控网站url是否正常
- zabbix应用之Low-level discovery监控磁盘IO
- 监控运维系统实施方案--监控对象信息收集阶段
- 性能测试:监控web服务器--apache
- 13视频监控-01视频监控布局-videobox
- 【视频】vue $watch监控数据的变化
- 使用Fiddler监控网易云笔记客户端向服务器定时发送的sync请求
- 容器监控—阿里云&容器内部服务监控
- paip.windows io监控总结
- 基于NB-IoT的智慧路灯监控系统(NB-IoT专栏—实战篇5:手机应用开发)
- Atitit.软件仪表盘(7)--温度监測子系统--电脑重要部件温度与监控and警报
- SpringBoot三种方式配置Alibaba Druid用于监控或者查看SQL状况:yml或properties配置;Java bean代码配置;注解配置 yml和properties的在线相互转换
- y74.第四章 Prometheus大厂监控体系及实战 -- PromQL简介和监控pod资源(五)
- y73.第四章 Prometheus大厂监控体系及实战 -- blackbox exporter安装和grafana安装(四)
- y71.第四章 Prometheus大厂监控体系及实战 -- prometheus server安装(二)
- y70.第四章 Prometheus大厂监控体系及实战 -- Prometheus监控介绍(一)
- Linux- 系统随你玩之--好用到炸裂的系统级监控、诊断工具
- zabbix低自动发现--监控mysql多实例(二十九)
- Prometheus安装部署及简单监控
- 如何才能监控查看出注册表更改情况,本地组策略设置更改了哪些注册表对应值?
- Zabbix 监控MySQL从服务器状态