
项目实战分享-大数据时代-航空公司该如何转型(四)
大数据时代-航空公司该如何转型(一)![]() https://blog.csdn.net/tipdm0526/article/details/124985456?spm=1001.2014.3001.5501
https://blog.csdn.net/tipdm0526/article/details/124985456?spm=1001.2014.3001.5501
大数据时代-航空公司该如何转型(二)![]() https://blog.csdn.net/tipdm0526/article/details/125006987?spm=1001.2014.3001.5501
https://blog.csdn.net/tipdm0526/article/details/125006987?spm=1001.2014.3001.5501
大数据时代-航空公司该如何转型(三)![]() https://blog.csdn.net/tipdm0526/article/details/125047962?spm=1001.2014.3001.5501
https://blog.csdn.net/tipdm0526/article/details/125047962?spm=1001.2014.3001.5501
下面进入第四篇正文
模型构建
客户价值分析模型构建主要由两个部分构成,第一个部分根据航空公司客户五个指标的数据,对客户作聚类分群。第二部分结合业务对每个客户群进行特征分析,分析其客户价值,并对每个客户群进行排名。
1. 客户聚类
采用K-Means聚类算法对客户数据进行客户分群,聚成五类(需要结合业务的理解与分析来确定客户的类别数量)。
使用scikit-learn库下的聚类子库(sklearn.cluster)可以实现K-Means聚类算法。使用标准化后的数据进行聚类,如代码清单1所示。
代码清单1 K-meas聚类标准化后的数据
| import pandas as pd import numpy as np from sklearn.cluster import KMeans # 导入kmeans算法
# 读取标准化后的数据 airline_scale = np.load('../tmp/airline_scale.npz')['arr_0'] k = 5 # 确定聚类中心数
# 构建模型,随机种子设为123 kmeans_model = KMeans(n_clusters=k,n_jobs=4,random_state=123) fit_kmeans = kmeans_model.fit(airline_scale) # 模型训练
# 查看聚类结果 kmeans_cc = kmeans_model.cluster_centers_ # 聚类中心 print('各类聚类中心为:\n',kmeans_cc) kmeans_labels = kmeans_model.labels_ # 样本的类别标签 print('各样本的类别标签为:\n',kmeans_labels) r1 = pd.Series(kmeans_model.labels_).value_counts() # 统计不同类别样本的数目 print('最终每个类别的数目为:\n',r1) # 输出聚类分群的结果 cluster_center = pd.DataFrame(kmeans_model.cluster_centers_,\ columns=['ZL','ZR','ZF','ZM','ZC']) # 将聚类中心放在数据框中 cluster_center.index = pd.DataFrame(kmeans_model.labels_ ).\ drop_duplicates().iloc[:,0] # 将样本类别作为数据框索引 print(cluster_center) |
*代码详见:demo/code/KMeans_cluster.py。
对数据进行聚类分群的结果如表1所示
表 1 客户聚类结果
| 聚类 类别 | 聚类 个数 | 聚类中心 | ||||
| ZL | ZR | ZF | ZM | ZC | ||
| 客户群1 | 15739 | 0.052191 | -0.002647 | -0.226745 | -0.231168 | 0.052191 |
| 客户群2 | 12125 | 0.483380 | -0.799373 | 2.483198 | 2.424722 | 0.308632 |
| 客户群3 | 4182 | -0.313656 | 1.686290 | -0.574022 | -0.536823 | -0.173324 |
| 客户群4 | 24661 | -0.700220 | -0.414859 | -0.161162 | -0.160978 | -0.255071 |
| 客户群5 | 5336 | 1.160682 | -0.377298 | -0.086907 | -0.094843 | -0.155919 |
*由于K-Means聚类是随机选择类标号,因此重复此实验得到结果中的类标号可能与此不同;另外由于算法的精度问题,重复实验得到的聚类中心也可能略有不同。
2. 客户价值分析
针对聚类结果进行特征分析,绘制客户分群雷达图,如代码清单2所示。
代码清单2 绘制客户分群雷达图
| %matplotlib inline import matplotlib.pyplot as plt # 客户分群雷达图 labels = ['ZL','ZR','ZF','ZM','ZC'] legen = ['客户群' + str(i + 1) for i in cluster_center.index] # 客户群命名,作为雷达图的图例 lstype = ['-','--',(0, (3, 5, 1, 5, 1, 5)),':','-.'] kinds = list(cluster_center.iloc[:, 0]) # 由于雷达图要保证数据闭合,因此再添加L列,并转换为 np.ndarray cluster_center = pd.concat([cluster_center, cluster_center[['ZL']]], axis=1) centers = np.array(cluster_center.iloc[:, 0:])
# 分割圆周长,并让其闭合 n = len(labels) angle = np.linspace(0, 2 * np.pi, n, endpoint=False) angle = np.concatenate((angle, [angle[0]]))
# 绘图 fig = plt.figure(figsize=(8,6)) ax = fig.add_subplot(111, polar=True) # 以极坐标的形式绘制图形 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 # 画线 for i in range(len(kinds)): ax.plot(angle, centers[i], linestyle=lstype[i], linewidth=2, label=kinds[i]) # 添加属性标签 ax.set_thetagrids(angle * 180 / np.pi, labels) plt.title('客户特征分析雷达图') plt.legend(legen) plt.show() plt.close |
*代码详见:demo/code/ KMeans_cluster.py。
通过代码清单2得到客户分群雷达图,如图1所示。
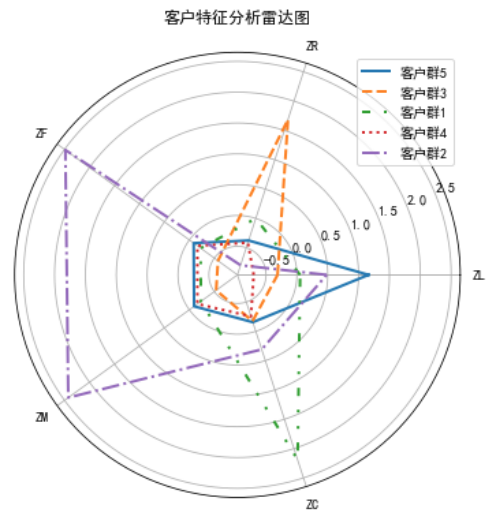
图 1 客户群特征雷达图
结合业务分析,通过比较各个特征在群间的大小对某一个群的特征进行评价分析。其中客户群1在特征C处的值最大,在特征F、M处的值较小,说明客户群1是偏好乘坐高级舱位的客户群;客户群2在特征F和M上的值最大,且在特征R上的值最小,说明客户群2的会员频繁乘机且近期都有乘机记录;客户群3在特征R处的值最大,在特征L、F、M和C处的值都较小,说明客户群3已经很久没有乘机,是入会时间较短的低价值的客户群;客户群4在所有特征上的值都很小,且在特征L处的值最小,说明客户群4属于新入会会员较多的客户群;客户群5在特征L处的值最大,在特征R处的值较小,其他特征值都比较适中,说明客户群5入会时间较长,飞行频率也较高,是有较高的价值的客户群。
总结出每个群的优势和弱势特征,具体结果如表2所示。
表 2 客户群特征描述表
| 群类别 | 优势特征 | 弱势特征 | |||||||||||||
| 客户群1 | C | R | F | M | |||||||||||
| 客户群2 | L | R | F | M | C | ||||||||||
| 客户群3 | L | R | F | M | C | ||||||||||
| 客户群4 | R | L | C | ||||||||||||
| 客户群5 | L | F | M | ||||||||||||
注:正常字体表示最大值,加粗字体表示次大值,斜体字体表示最小值,带下划线的字体表示次小值。
根据以上特征分析的图表,说明不同用户类别的表现特征显著不同。基于该特征描述,本案例定义5个等级的客户类别:重要保持客户,重要发展客户,重要挽留客户,一般客户,低价值客户。每种客户类别的特征如图 2所示。

图2 客户类别的特征分析
(1) 重要保持客户:这类客户的平均折扣率(C)较高(一般所乘航班的舱位等级较高),最近乘坐过本公司航班(R)低,乘坐的次数(F)或里程(M)较高。他们是航空公司的高价值客户,是最为理想的客户类型,对航空公司的贡献最大,所占比例却较小。航空公司应该优先将资源投放到他们身上,对他们进行差异化管理和一对一营销,提高这类客户的忠诚度与满意度,尽可能延长这类客户的高水平消费。
(2) 重要发展客户。这类客户的平均折扣率(C)较高,最近乘坐过本公司航班(R)低,但乘坐次数(F)或乘坐里程(M)较低。这类客户入会时长(L)短,他们是航空公司的潜在价值客户。虽然这类客户的当前价值并不是很高,但却有很大的发展潜力。航空公司要努力促使这类客户增加在本公司的乘机消费和合作伙伴处的消费,也就是增加客户的钱包份额。通过客户价值的提升,加强这类客户的满意度,提高他们转向竞争对手的转移成本,使他们逐渐成为公司的忠诚客户。
(3) 重要挽留客。这类客户过去所乘航班的平均折扣率(C),乘坐次数(F)或者里程(M)较高,但是较长时间已经没有乘坐本公司的航班(R)高或是乘坐频率变小。他们客户价值变化的不确定性很高。由于这些客户衰退的原因各不相同,所以掌握客户的最新信息,维持与客户的互动就显得尤为重要。航空公司应该根据这些客户的最近消费时间,消费次数的变化情况,推测客户消费的异动状况,并列出客户名单,对其重点联系,采取一定的营销手段,延长客户的生命周期。
(4) 一般与低价值客户。这类客户所乘航班的平均折扣率(C)很低,较长时间没有乘坐过本公司航班(R)高,乘坐的次数(F)或里程(M)较低,入会时长(L)短。他们是航空公司的一般用户与低价值客户,可能是在航空公司机票打折促销时,才会乘坐本公司航班。
其中,重要发展客户,重要保持客户,重要挽留客户这三类重要客户分别可以归入客户生命周期管理的发展期,稳定期,衰退期三个阶段。
根据每种客户类型的特征,对各类客户群进行客户价值排名,其结果如表3所示。针对不同类型的客户群提供不同的产品和服务,提升重要发展客户的价值,稳定和延长重要保持客户的高水平消费,防范重要挽留客户的流失并积极进行关系恢复。
表 3客户群价值排名
| 客户群 | 排名 | 排名含义 |
| 客户群2 | 1 | 重要保持客户 |
| 客户群1 | 2 | 重要发展客户 |
| 客户群5 | 3 | 重要挽留用户 |
| 客户群4 | 4 | 一般客户 |
| 客户群3 | 5 | 低价值客户 |
利用泰迪智能科技TIpDM模型搭建,本模型采用历史数据进行建模,随着时间的变化,分析数据的观测窗口也在变换。因此,对于新增客户详细信息,考虑业务的实际情况,该模型建议每一个月运行一次,对其新增客户信息通过聚类中心进行判断,同时对本次新增客户的特征进行分析。如果增量数据的实际情况与判断结果差异大,需要业务部门重点关注,查看变化大的原因以及确认模型的稳定性。如果模型稳定性变化大,需要重新训练模型进行调整。目前模型进行重新训练的时间没有统一标准,大部分情况都是根据经验来决定。根据经验建议:每隔半年训练一次模型比较合适。
相关文章
- (尚020)Vue打包发布项目
- VS2013与MySql建立连接;您的项目引用了最新实体框架;但是,找不到数据链接所需的与版本兼容的实体框架数据库 EF6使用Mysql的技巧
- 实体识别项目,如何快速的针对字典信息,对新闻数据进行数据标注
- Google Earth Engine ——全球人类住区层(GHSL)项目由欧盟委员会人口的分布和密度250米分辨率数据集
- Java项目如何导出数据为 PDF 文件?
- 企业级网关 Kong 部署 Spring Boot 项目实战
- uni-app - 实现多选功能,点击项目时选中并高亮显示(支持全选 / 反选,以及轻松的 “回显“ 数据)点击选中并改变样式,全端兼容 H5 App 小程序,代码高效简洁无 BUG
- 【软件测试】简历中的项目经历可以怎么写?
- 清华首推复合型大数据硕士项目
- 你的大数据项目离失败有多远?
- springboot项目引入了doris数据,建表模式如何选?
- 【QT】Qt项目demo:数据在ui界面上显示,鼠标双击可弹窗显示具体信息
- 大数据实操项目分享:餐饮智能推荐服务在线实习项目
- 大数据在线实习项目|学生消费行为分析在线实习项目-项目介绍
- 模型推荐丨政务大数据项目案例模型分享
- 《Hadoop海量数据处理:技术详解与项目实战》一1.2 Hadoop和大数据
- 基于Python面向《海贼王》领域数据的知识图谱项目【100010385】
- go项目在Linux, Windows交叉编译注意事项
- Hotel-ID打击人口贩卖(1)项目介绍和数据预处理
- 盘点2021最佳数据可视化项目
- Qt编写的项目作品16-Onvif搜索和云台控制工具
- SwiftUI SQLite数据大全之 如何创建加密数据库并在项目中读取加密数据 (SQLite.swift SQLCipher教程含源码)
- 《R语言数据挖掘:实用项目解析》——第2章 汽车数据的探索性分析 2.1 一元分析
- 项目笔记:导出Excel功能分sheet页插入数据
- 8.个人项目-STM32+机智云上传温湿度和MQ135数据,APP查看
- 【数字IC验证快速入门】35、UVM项目实践之APB_SPI(3)APB_SPI 数据建模(Transaction Modeling)
- QTP校验数据库中数据后台项目
- jenkins之从0到1利用Git和Ant插件打war包并自动部署到tomcat(第三话):创建一个自由风格的项目(非maven),实现自动打war包
- 如何在PHP项目中使用phinx进行数据迁移和建表
- apache开源项目--solr
- 【pyinstaller打包pyqt5编写的项目为exe(脱离环境可运行)】
- Komet Resources Inc.:Guiro和Moussala金矿勘探项目的最新进展
- 阿里开源中间件canal实现mysql数据库同步,零侵入不写代码实现,也可以通过整合到项目程序实现更加灵活的控制,简单几步实现高性能准实时多数据库多数据表的数据同步,可在windows和Linux部署
- 乌当区加快以大数据项目支撑的三区生态
- vue项目 上传到git