
MySQL第四讲 MySql Undo日志 - 对聚簇索引进行CUD操作
事务需要保证原子性,如果在事务执行过程中出现以下情况,就需要用到undo log
1:事务执行中遇到各种错误,比如服务器本身的错误,操作系统错误甚至是断电导致的错误
2:事务在执行过程手动rollback结束当前事务
每当对一条记录进行改动的时候(值 Insert Update Delete)都需要留一手把需要回滚的东西记录下载,比如: 在插入一条记录的时候,至少要把这条记录的主键值记录下来,这样之后需要回滚的时候只需要将对应的主键值记录删除;在删除一条记录的时候,需要将这条记录的内容记录下载,需要回滚的时候就把这些内容在插入到表中;在修改一条记录的时候,至少需要将要被更细的旧值记录下载,回滚的时候只需要再把这些列更新为旧的记录值。
分配事务id的时机
通过start transaction read only 可以开启一个只读事务,在只读事务中不可以对普通的表(其他事务也能访问的表)进行增删改操作,但是可以对临时表进行增删改操作
通过start transaction read write 语句开启一个读写事务,(begin, start transaction 也算读写事务),读写事务可以对表进行增删改操作
对于只读事务来说,只有对某一个用户创建的临时表进行增删改操作的时候,才会分配一个事务id,否则不分配事务id,
对于读写事务来说,只有对某条记录进行增删改操作时,才会分配事务Id(包含用户定义的临时表)
事务Id是一个全局属性,默认开始时是0,随着事务分配每次递增1,每当这个变量值为256的倍数时,就会将这个变量值刷新到系统空间表页号为5的页面中一个名为MAX TRx ID的属性中,这个属性占据8个字节空间,当系统下一次重新启动的时候,会将这个MAX TRX ID 属性加载到内存中,将该值加256之后赋予前面提到的全局变量中(因为在上次关机的时候,该全局变量的值可能大于磁盘页面的MAX TRX ID属性值)
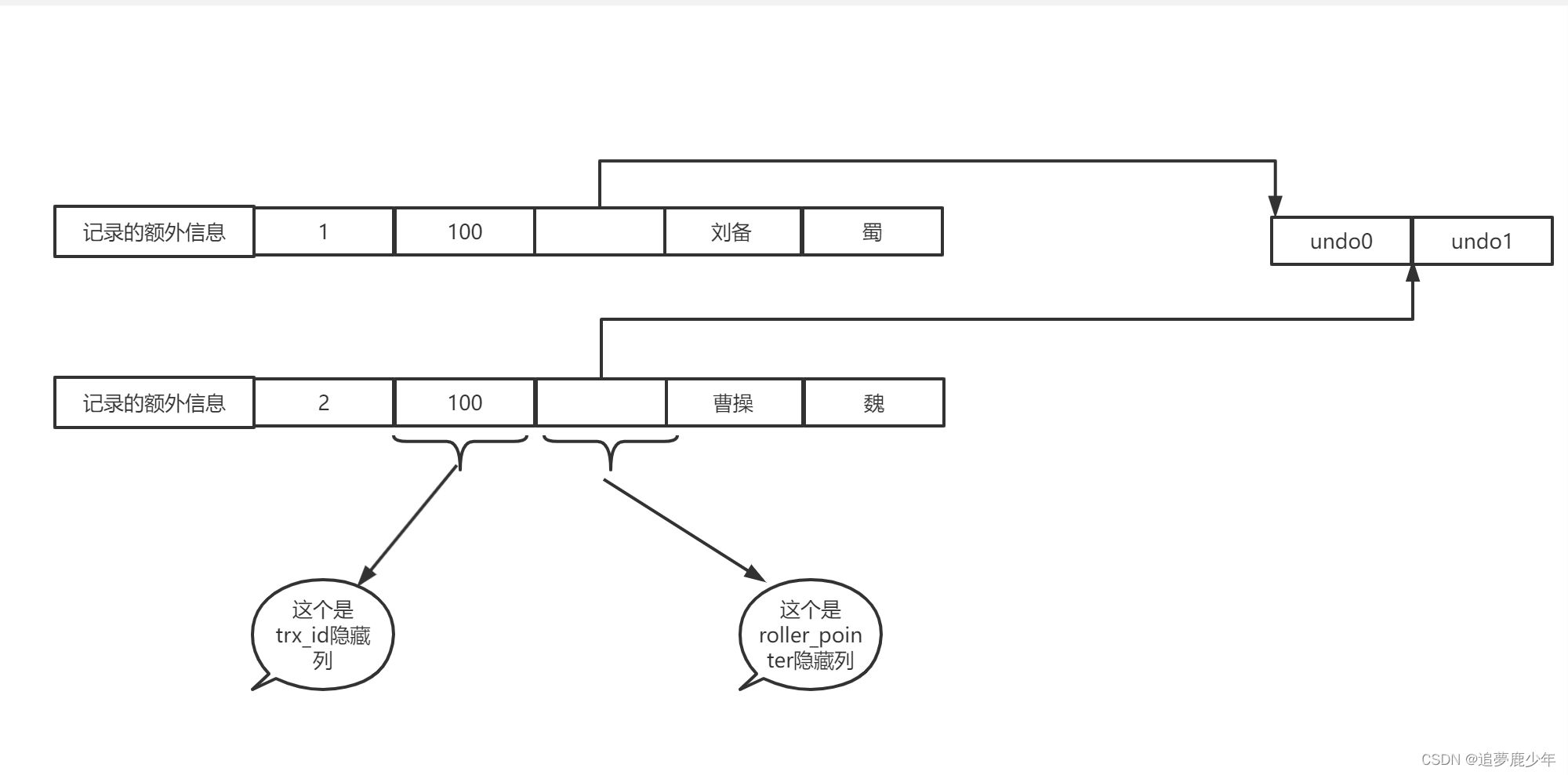
| 记录的额外信息 | row_id | trx_id | roll_pointer | 用户列信息 |
|---|---|---|---|---|
| 其中隐藏的row_id并不是必须的 |
undo日志也是从下标0开始进行编号的,根据生成的顺序分别称为第0号undo日志,第1号undo日志…第n号undo日志等,这个编号也称为undo no. 这些undo日志被记录到类型为FIL_PAGE——UNDO_LOG(对应的十六机制为0X0002)的页面中。这些页面可以从系统表空间中分配,也可以从专门存放undo日志的表空间分配(undo tablespace).
前面有说到在插入一条记录的时候,不管是乐观插入还是悲观插入,最终的结果都是将这条记录放到一个数据页中。在写undo日志的时候,只要把这条记录的主键信息记上就行,所以设计indoDB的大哥设计了一个类型为TRX_UNDO_INSERT_REC的undo日志,他的整体结构如下:
undo no 在一个事务中是从10开始递增的
如果记录中主键只包含一列,那么类型为 TRX_UNDO_INSERT_REC的undo日志中,只需要把该列占用的存储空间大小和真实值记录下来,如果记录中的主键值包含多个列,那么每一列占用的存储空间大小和对应的真实值都需要记录下来。len代表列占用的存储空间大小, value表示列的真实值
INSERT操作对应的 undo日志
实际上我们向表中插入一条记录的时候,需要向聚簇索引和所有的二级索引都插入一条记录,不过在记录undo日志的时候,我们只需要针对聚簇索引记录来记录一条undo日志,聚簇索引记录和二级索引记录都是一一对应的,我们在回滚insert记录的时候,只需要知道这条记录对应的主键信息,就可以根据主键信息进行对应的删除操作,在删除的同时也会把聚簇索引和所有的二级索引中对应的记录都删除掉。DELETE UPDATE操作也是针对聚簇索引记录的改动来记录undo日志的。
现在说一下roll_pointer,这个占用七个字节的字段其实本质上就是执向记录对应的undo日志的指针。比如 在一条表执行了两条更新操作,就会通过roll_pointer将生成的两条undo 日志链接起来,聚簇索引是存放在FILE_PAGE_INDEX的页面中(也就是数据页),undo日志存放在FILE_PAGE_UNDO_LOG页面中。
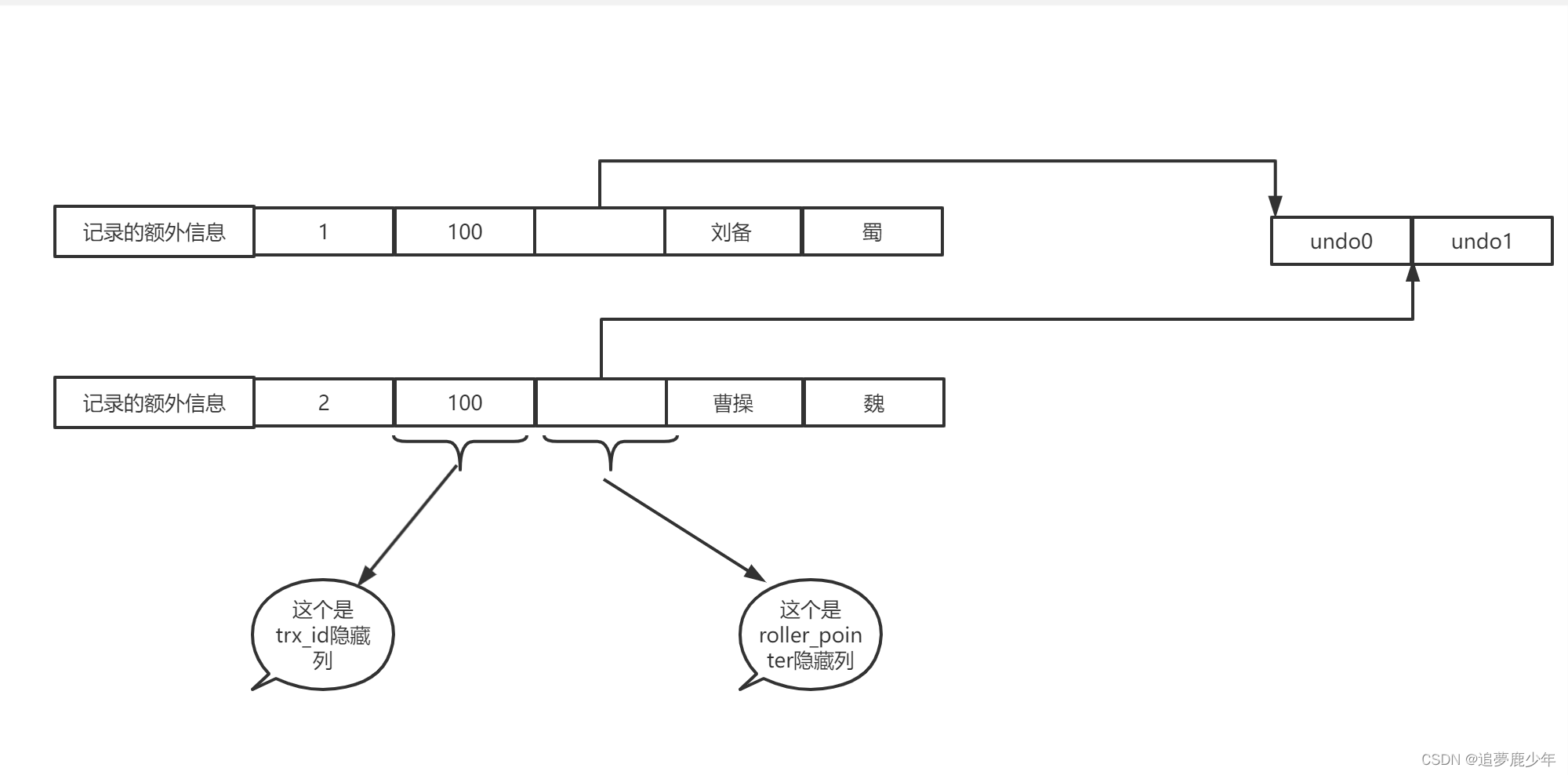
roll_pointer本质上就是一个指针,指向记录对应的undo日志。
DELETE操作对应的undo日志
插入到页面中的记录会根据记录头信息的next_record属性组成一个单向链表,称这个链表为正常记录链表。其中被删除的记录也会根据记头的信息中的next record属性组成一个链表,只不过这个链表中的记录占用的存储空间可以被重新利用,所以也称这个链表为垃圾链表。PAGE HEader中存在一个名为PAGE_FREE的属性,指向由被删除记录组成的垃圾链表中的头节点。
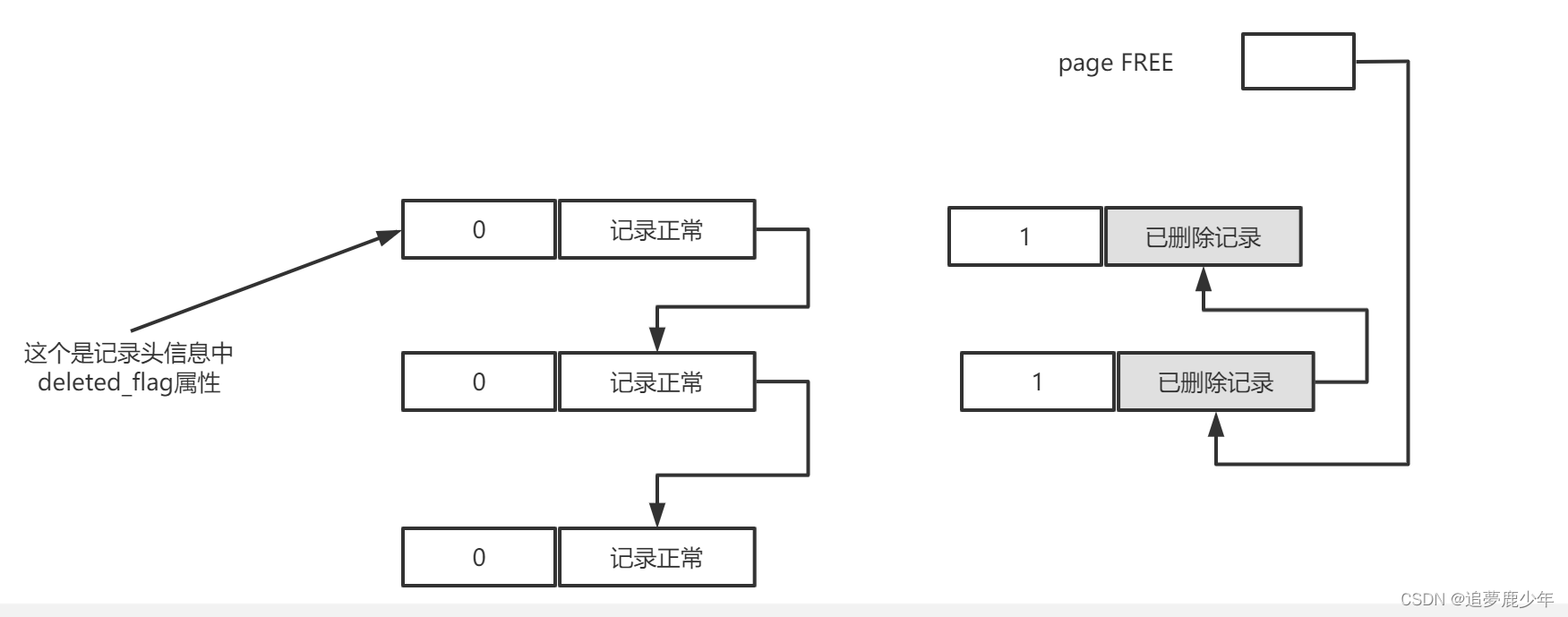
在垃圾链表中,这些记录占用的·存储空间可以被重新利用,在页面的page header部分中,page free属性的值代表指向垃圾链表头节点的指针。在delete语句把正常记录链的最后一条记录删除,这个删除操作过程历经两个阶段。
阶段1: 仅仅将记录的deleted_flag标识位设置为1,其他的不做修改(trx_id,roll_pointer也会修改,但是是隐藏列的值)这个阶段被称为delete mark,这个时候并不会把删除的正常记录添加到删除链表(加入到链表的头结点),在删除语句所在的事务提交前,被删除的记录一直处于这个中间状态。这个就是实现MVCC机制的一个功能。
阶段2: 删除语句的事务提交后,会有专门的线程来真正执行删除操作,把记录从正常记录链表删除,添加到垃圾链表,修改页面中的用户记录数量 PAGE_N_RECS,上次插入记录的位置PAGE_LAST_INSERT,垃圾链表头结点的指针 PAGE——FREE,页面中可重用的字节数 PAGE_GARBAGE,这个阶段被称为 purge。被删除后的记录占用的空间就可以被重新利用。
这里有一个问题,随着新插入记录的增多,如果新插入的记录小于垃圾链表头节点对应删除记录占用的空间,那意味着头结点占用的存储空间就要有一部分存储空间用不到,这部分空间就是碎片空间,随着记录越插越多,由此产生的碎片也越来越多,如何管理利用这部分碎片空间就变得十分重要。MYSQL设计值将这些碎片空间统计到 PAGE_GARBAGE属性中,这些碎片空间在整个页面快使用完之前并不会被重新利用,在页面快满时,如果再插入一条心记录,此时页面中并不能分配一条完整记录的空间,这个时候就需要看PAGE_GARBAGE的空间和剩余的可用空间相加之后是否可以容纳这条记录。这个时候INNODB会尝试重新组织页内的记录。重新组织的过程会先开辟一个临时页,把页面的记录依次插入一遍。因为依次插入记录时不会产生碎片,之后再把临时页面的内容复制到本页面,这样就可以把那些碎片空间都解放了,当然重新组织页面内的记录会比较耗费性能。
Update操作对应的undo日志
update不更新主键的时候,可以细分为被更新的列占用的列存储空间不发生变化和发生变化
1:不更新主键-就地更新
对于更新的列,更新前后占用的存储空间大小一样,那么就可以就地更新
2:不更新主键-先删除旧记录,再插入新记录
这里的删除并不是delete mark操作而是真正的删除,也就是会把这条正常记录从正常记录链表中移除,并加入到垃圾链表头部,并且修改页面对应的统计信息。这里执行真正删除的操作线程不是在DElete语句中进行的purge操作时使用的线程,而是由用户线程同步执行真正的删除操作。、
3: 更新主键
需要先对旧记录进行delete mark操作,在update事务提交后才会由专门的线程执行purge操作。之索引只是对记录执行delete mark操作,是因为其他事务可能会访问这条记录,如果把它删除并加入到垃圾链表后,别的事务就无法访问了,这个功能就是MVCC。
之后会根据更新后各列的值创建一条记录,并将其插入到聚簇索引中。
增删改操作对二级索引的影响,对于二级索引来说执行INSERT DELETE操作与聚簇索引中执行是产出的影响是差不多的,但是在执行UPDATE的时候会有差别,当我们在二级索引执行UPDATE操作时,会执行两个操作;
1: 对旧的二级索引执行delete mark操作
2:根据更新后的值创建一条新的二级索引记录,然后再二级索引对应的B+树中重新定位到它的位置并插进去。
注意 :这里同样是delete mark操作,也就是说在update语句所在的事务提交前,对旧的记录只是执行了delete mark操作,并不是直接删除旧记录,在事务提交后会有专门的线程执行purge操作,从而把它们加入到垃圾链表中。(如果直接进行正在的删除并加入到垃圾链表中,别的事务就访问不到了,这个功能就是MVCC)
增删改操作对二级索引的影响
一个表可以拥有一个聚簇索引以及多个二级索引,对于二级索引来说,insert操作和delete对二级索引的影响和在聚簇索引中执行的操作产生的影响差不多,但是对于update操作,有稍微不同的地方,如果我们的update操作的列字段没有涉及到二级索引,那么就不需要对二级索引执行任何的操作,相反,如果在update的时候修改了二级索引列,就需要进行下面的操作:
1:对旧的二级索引进行delete mark操作
2:根据更新后的值创建一条新的二级索引记录,然后在二级索引对应的B+树中重新定位到它的位置并插入进去。
对二级索引进行修改的时候,会影响到二级索引所在页面的Page Header的部分中一个名为PAGE_MAX_TRX_ID的属性,这个属性表示修改当前页面的最大事务id.
相关文章
- MySQL Binlog Digger 4.28 【mysql日志分析工具】
- mysql索引hash索引和b-tree索引的区别
- mysql二级索引
- MySql 索引数据结构,千万级大表,关于性别及年龄字段是否需要加索引?
- MySQL 自动获取当前时间,且 timestamp 类型与 datetime 类型的区别
- MYSQL 表结构的修改
- 关于Mysql 查询所有表的实时记录用于对比2个MySQL 库的数据是否异步
- 测试环境治理之MYSQL索引优化篇
- mysql 命令行 自动补全
- Mysql的索引为什么使用B+树而不使用跳表?
- 【MySQL进阶-02】mysql的explain执行计划以及索引优化
- MySQL 百万级数据量分页查询方法及其优化
- 搭建MySQL集群版遇到的坑,你踩过哪个?
- 《PHP和MySQL Web开发从新手到高手(第5版)》一一1.5 向虚拟主机询问什么
- 转 mysql 常用的 sql
- 转发 可设置skip_name_resolve参数 会出现 ERROR 2005 (HY000): Unknown MySQL server host _mysql ...
- MySQL基础之 LIKE操作符
- MySQL基础之 索引
- python操作mysql数据库系列-操作MySql数据库(三)
- mysql导出数据报错The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
- mysql索引的应用场景以及如何使用
- 数据库原理及MySQL应用 | 视图
- MySQL内存调优
- mysql聚集索引 mysql如何查看某个表的聚集索引
- (5.8)mysql高可用系列——MySQL中的GTID复制(实践篇)
- MYSQL 用户的基本操作
- Mac - Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)
- mysql 索引长度和区分度
- MySql使用优化——不同种类的索引在不同场景中的应用(附实战分析源码)
- MySQL 字段名为关键字