
【MySQL进阶-09】深入理解mysql执行的底层机制
MySql系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】深入理解mysql索引本质 | https://blog.csdn.net/zhenghuishengq/article/details/121027025 |
| 【二】深入理解mysql索引优化以及explain关键字 | https://blog.csdn.net/zhenghuishengq/article/details/124552080 |
| 【三】深入理解mysql的索引分类,覆盖索引(失效),回表,MRR | https://blog.csdn.net/zhenghuishengq/article/details/128273593 |
| 【四】深入理解mysql事务本质 | https://blog.csdn.net/zhenghuishengq/article/details/127753772 |
| 【五】深入理解mvcc机制 | https://blog.csdn.net/zhenghuishengq/article/details/127889365 |
| 【六】深入理解mysql的内核查询成本计算 | https://blog.csdn.net/zhenghuishengq/article/details/128820477 |
| 【七】深入理解mysql性能优化以及解决慢查询问题 | https://blog.csdn.net/zhenghuishengq/article/details/128854433 |
| 【八】深入理解innodb和buffer pool底层结构和原理 | https://blog.csdn.net/zhenghuishengq/article/details/128993871 |
| 【九】深入理解mysql执行的底层机制 | https://blog.csdn.net/zhenghuishengq/article/details/128100377 |
| 【十】深入理解mysql集群的高可用机制 | https://blog.csdn.net/zhenghuishengq/article/details/126239652 |
| 【彩蛋篇】深入理解顺序io和随机io | https://blog.csdn.net/zhenghuishengq/article/details/129080088 |
一条mysql的更新语句
一,深入理解mysql底层运行机制
在上一篇详细的的描述了mvcc的机制:https://blog.csdn.net/zhenghuishengq/article/details/127889365?spm=1001.2014.3001.5501
得知mvcc解决了当前事务在开启之后,提交之前,查询出来的值可以不受其他事务的增删改的影响,可以一直保持不变,从而保证事务的隔离性。mvcc主要是利用了一条公共的 undolog 版本控制链路和多个在不同条件下生成的 readview 视图组成,在更新一条sql时,需要使用到这个undolog这个日志文件。
因此接下来主要了解一下在一条sql的更新语句中,undolog 是在何时使用,还有redolog,binlog等日志文件在何时使用以及他们的作用。
1,mysql的更新语句的执行流程
如下,主要是对这条sql语句进行一个解析,并且保证这个name字段是一个唯一键
update user set name = huisheng where name = zhs;
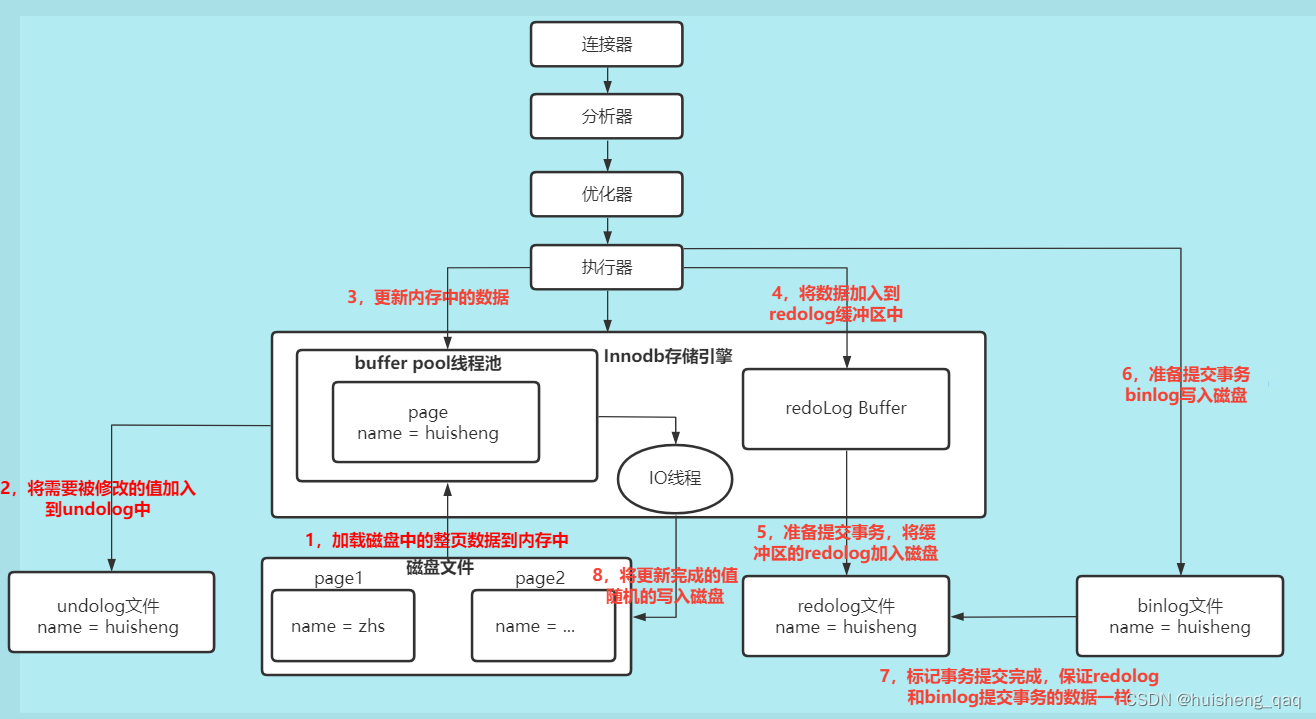
接下来描述一条sql语句的执行流程,其流程主要分为server层和引擎层两部分。server层是所有的存储引擎共享的,引擎层是由不同的存储引擎构成,如innodb,myIsam和memory等这几种,其不同的引擎有着不同的数据结构。这里主要分析Innodb这个引擎层。其流程主要如下图
1.1,server层
1.1.1,连接器
首先客户端和服务端建立连接之后才能发送命令,基于tcp的webSocket实现,同时会对用户的权限与密码做一个校验。mysql里面有一个系统库,里面有一张系统表user表,然后会对输入的这个host,password进行一个校验,校验成功之后进行连接,mysql会开辟一个专属的会话空间,用于临时操作。建立连接之后默认长连接时间为8小时。主要是为了建立连接以及权限校验
1.1.2,分析器
会有一些词法分析,语法分析,语义分析等。最后可以通过一个语法树,来分析具体的某一条sql语句,如select,delete,insert等。主要是对sql进行一个语法分析,看语句是否合法
1.1.3,优化器
在表里面存在多个索引的时候,会去判断走哪个索引。主要是对sql语句的一些优化
1.1.4,执行器
会进行一个权限的认证,判断一下是否有操作这张表的权限,如果有权限的话,就会去遍历表里面的每一行,看是否符合这个条件查询,如果符合,就把这行加入到结果集里面。并且通过表所对应的结构调用对应的执行引擎。
1.1.5,bin-log日志
记录mysql的执行语句,如增删改查等,以及执行后的结果集影响,主要是记录一条语句的原始逻辑。而且这个binlog是在server层公用的,因此不管引擎层是innodb还是myIsam,都需要使用到这个binlog日志。以及后期需要的主从复制原理,都是需要通过这个binlog日志实现
1.2,innodb存储引擎层
引擎层主要的引擎有innodb,myIsam和memory等这几种,mysql默认使用的是innodb这种引擎。mysql主要就是通过这个引擎层来实现横向扩展的,让server层大家共享,不同的引擎层的底层有着不一样的数据结构,从而实现mysql的多元化。然后通过这个执行器,mysql表对应的是什么引擎,那么执行器就会调用对应的存储引擎去查对应的值。
接下来详细的说一下在innodb这个引擎中,一条sql的更新语句的具体的执行流程。如上图对应的红色标注,其流程如下图
1,首先将这个 name = zhs 所在的这一页数据从磁盘中加载到BuferfPool的缓存池里面。(在mysql数据库中,数据交互以页为最小单位),此时缓存池中的name = zhs。
2,将当前要被修改的值加入到 undolog 日志文件里面,如果事务提交失败导致回滚,就用里面的这个值进行回滚。
3,在缓存池中更新数据,将name的值更新为huisheng,此时bufferpool缓存中的name = huisheng。
4,将缓存池中的操作加入到redolog的缓冲区里面,redolog里面记录了Buffer pool缓存池中对name的操作和结果
5,当Redolog缓冲区里面的数据达到一定量的时候,就会准备提交事务,并将这个redolog日志写入磁盘里面
6,将server层的binlog日志写入磁盘中,并且也会准备提交事务。准备提交的意思就是说如果在JAVA代码中,由于将这个事务的开启,提交和回滚都通过aop的方式交给了spring管理,那在一条更新语句之后可能还有其他的代码要执行,因此不能立马提交,只能说准备提交。
7,当server层的binlog将数据写成功之后,binlog会向引擎层的redolog写一个commit的标记,保证两个文件数据的一致性,然后再真正的提交事务。此时提交事务时,数据在buffer pool缓存池中并没有存入到磁盘中
8,事务提交成功之后,mysql内部会启动一个后台的IO线程,然后将BufferPoll线程池中的值进行一个随机的刷盘,将值写入到磁盘文件里面
2,redolog
2.1,commit提交的原因
在上图的第七步中,有一个commit的标记操作,主要是为了保证redolog和binlog的数据一致性。由于binlog主要是为了恢复数据的,因此binlog在不发生回滚的情况下必须要保证持久化成功。因此为了保证两个文件数据的一致性,可以让binlog在事务提交成功之后向redolog发一个commit标记,然后redolog这边接收到这个commit标记之后,redolog再提交事务。这样就可以保证两个文件里面的数据一样了。其原理有点类似主从复制的底层。
2.2,redolog在缓存池的作用
在这个innodb的存储引擎里面,有一个redolog buffer和一个redolog持久化文件,类似于一个两阶段提交,其第一阶段是为了起到一个缓存作用,并且降低持久化到磁盘的压力。第二阶段是一个批量持久化的过程,在数据达到一定量的时候,会将数据持久化到磁盘里面。
2.3,redolog存在的意义
那到了这里,相信大家都会和我一样在想,为什么有了 binlog 这个持久化的文件,还要有 **redolog ** 这个恢复数据的文件呢?
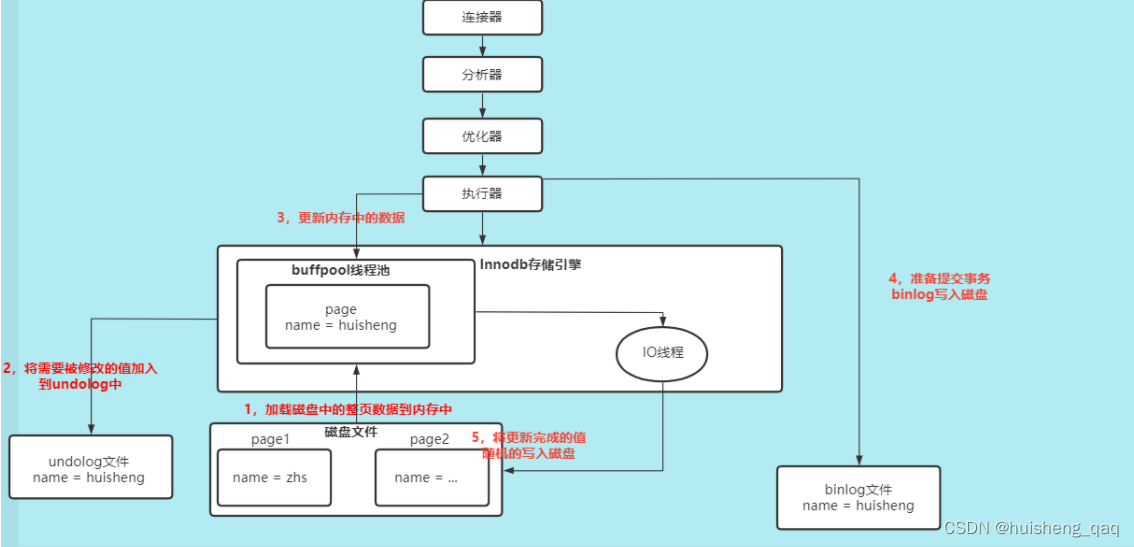
如果没有redolog这个日志文件,那么就会成为上面的样子,在更新完成之后,在binlog写入磁盘之后就会提交事务,那么此时就会通过内部的IO线程将值进行一个刷盘操作,从而将值写入到磁盘里面。
那么就会有一个问题,如果在innodb引擎层没有做任何日志记录,而只在server层进行了一个日志持久化的记录,当binlog事务提交之后,就会直接进入上图的第五步,server层就会默认的认为数据库已经将值从buffer pool缓冲区通过刷盘的方式加入到数据库了,而就在这个刷盘的同时,如果出现服务器突然宕机的情况,那么这个IO线程没来的及将数据加入到磁盘里面,那么就可能出现buffer poll数据更新成功,但是磁盘数据没有更新成功的情况。
到此为止,本人还是蒙的,总觉得就算没有redolog,也可以通过binlog进行一个数据恢复的呀,因为当时我觉得redolog里面存储的数据在binlog这个文件里面都有。一开始并没有绕过这个弯子,直到了解binlog的作用以及他们的区别之后,才发现用这个binlog恢复这个bufferpool的线程池的数据,那肯定是行不通的。
2.4,redolog和binlog的区别
1,首先binlog是在server层的数据,即使不是innodb这个引擎,binlog这个文件也是会有的;而redolog是innodb引擎层中的日志数据
2,binlog文件是用二进制文件进行数据的存储的,并且里面记录的是一些逻辑日志;redolog记录的是物理日志,会记录具体在哪一页改了什么
3,binlog是用于恢复整个mysql的数据的,因此里面是可以追加写入的,并不会覆盖以前的日志;但是这个redolog日志大小是固定的,里面是采用这种循环覆盖的方式存储数据,就类似与从头往尾写,写满了就将头部的覆盖掉,继续从头写,并且redolog里面就只记录未刷盘的文件。
2.5,redolog总结
分析到这里,就可以知道redolog日志的作用了吧,首先再来看看之前上面提出的问题,就是在数据刷盘的时候,突然mysql服务器宕机了,此时buffer pool的数据还没有刷到磁盘文件里面,那必然会丢失一部分数据,那怎么去恢复这个丢失的数据呢?
首先先来解决我之前的疑惑,就是为什么我上面觉得binlog也可以用来恢复数据,现在突然觉得又不行了呢,依旧结合着图和理论分析:

1,binlog是server层数据,如上图,binlog提交事务之后才将数据从buffer pool缓存池中将数据刷盘到磁盘文件中,此时binlog日志并不管你刷盘的事情。因此不能记录哪些数据刷盘了哪些数据没刷盘,如果使用binlog来恢复磁盘文件,那么就会将全部的数据重新运行一遍,已经存在磁盘的数据又会再存一遍。那么此时数据肯定会重复了。
2,binlog毕竟是server层的数据,不可能为了innodb这一个存储引擎专门做一个标记位来标记那些已经刷盘哪些未刷盘吧,并且只为了恢复你那buffer pool那一点数据专门让binlog做一个标记是否刷盘的也不合适。
3,redolog是采用覆盖的数据结构,只存未刷盘的数据,已经刷入磁盘的数据都会从 redolog 这个有限大小的日志文件里删除。这样即解决了1,2数据刷盘导致数据重复的问题,也解决了服务层和引擎层跨层恢复数据的问题,这样通过redolog恢复这个buffer pool缓存池的数据再合适不过了。
这就解释了为啥要有这个redolog这个文件了,就是在宕机时,或者数据丢失时可以快速恢复buffer pool中的未刷盘的数据了。
相关文章
- mysql update语句 in执行效率优化
- Error connecting to database [Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (13)]
- 【Mysql 学习】mysql 的使用入门
- 【MySQL】批量删除mysql中数据库中的表
- Linux - mysql 异常: ERROR! MySQL is not running, but lock file (/var/lock/subsys/mysql) exists
- MySQL存储过程实现动态执行SQL
- MySQL配置文件my.ini参数注释说明
- docker 应用篇————mysql容器[十二]
- 数据库的硬迁移和mysql 5.5.38源码安装
- Centos 6.8 配置mysql数据库主从同步
- MySQL中数据类型的长度问题解析
- Mysql索引数据结构有多个选择,为什么一定要是B+树呢?_面试 (MySQL 索引为啥要选择 B+ 树)
- centos7 rpm方式离线安装mysql注意点:需先卸载mariadb(rpm -e mariadb-libs --nodeps)
- 【收藏】windows下 Mysql 错误 Can‘t open and lock privilege tables: Table ‘mysql.user‘ doesn‘t exist
- error: 'Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (2)'
- mysql查看正在执行的sql语句
- 采用keepalived施工可用性MySQL-HA
- mysql_10 _ MySQL为什么有时候会选错索引?
- Mysql之加密连接mysql_ssl_rsa_setup
- Java获取MySQL连接的演变
- MySQL常用运算符详解