
spring源码之BeanDefinitionScanner的底层源码详解
spring源码系列整体栏目
只谈源码,只玩真实。和面试官认真的谈一次源码吧
【三】spring源码之ApplicationContext超级详解
【四】spring源码之BeanDefinitionScan超级详解
【五】spring源码之BeanDefinitionRead超级详解
【六】spring源码之IOC的加载流程超级详解以及Bean的生命周期
BeanDefinitionScanner底层原理
一,BeanDefinitionScanner加载流程
1,源码分析前准备
在分析这个源码的时候,首先需要去官网下载这个spring的源码包,建议下载5.x.x的版本
我这里安装的是:https://github.com/spring-projects/spring-framework/tree/5.2.x
2,源码分析
1,ApplicationContext是参与了整个springIoc的加载流程,因此ApplicationContext也是作为SpringIoc的一个入口了。由于ApplicationContext接口有很多的实现类,因此这里使用注解的方式来获取上下文的内容。
首先通过这个注解类AnnotationConfigApplicationContext获取这个上下文的全部信息,然后加载里面的配置信息,环境等。
AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext(MainConfig.class);
2,然后进入这个AnnotationConfigApplicationContext类里面,可以发现有一个无参构造方法,注册配置类的方法和一个refresh刷新IOC容器的方法,这里的话主要先看这个无参的构造方法。
public AnnotationConfigApplicationContext(Class<?>... annotatedClasses) {
//调用构造函数
this();
//注册我们的配置类
register(annotatedClasses);
//IOC容器刷新接口
refresh();
}
3,在这个构造函数里面,会实例化一个BeanDefinitionReader的读取器和一个BeanDefinitionScanner的扫描器。读取器就是为了读取注解,扫描器是为了扫描这个包和类,最后注册成一个BeanDefinition,这个BeanDefinitionScanner 也是本篇文章的核心内容
public AnnotationConfigApplicationContext(DefaultListableBeanFactory beanFactory) {
super(beanFactory);
this.reader = new AnnotatedBeanDefinitionReader(this);
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
4,在这个ClassPathBeanDefinitionScanner类的构造方法里面,首先会设置一下这个当前的环境以及资源加载器,还有一个重要的就是有一个初始化一个默认的过滤器的方法。
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment, @Nullable ResourceLoader resourceLoader) {
this.registry = registry;
if (useDefaultFilters) {
registerDefaultFilters();
}
//设置环境对象
setEnvironment(environment);
//设置资源加载器
setResourceLoader(resourceLoader);
}
然后可以来查看一下这个registerDefaultFilters的方法,里面会初始化这个includeFilter的这个包含过滤器,其底层就是一个List集合。这个包含过滤器里面会去添加所有的加了@Component注解的类,并且在spring中,这个@Component的这个注解就是在这个阶段进行扫描的。这个包含过滤器会在后面是否成为一个候选的bean的时候起到作用。
private final List<TypeFilter> includeFilters = new LinkedList<>();
protected void registerDefaultFilters() {
//加入扫描我们的@Component的
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
}
5,接下来进入这个ClassPathBeanDefinitionScanner扫描类里面,会有一个scan方法,然后开始进行真正的对这个包路径的扫描。
public int scan(String... basePackages) {
//对这些pachage的这些包进行扫描
doScan(basePackages);
}
接下来进入这个doScan的这个方法里面,就是开始扫描包。
protected Set < BeanDefinitionHolder > doScan(String...basePackages) {
//创建bean定义的holder对象用于保存扫描后生成的bean定义对象
Set <BeanDefinitionHolder> beanDefinitions = new LinkedHashSet <> ();
//循环我们的包路径集合
for (String basePackage: basePackages) {
//找到候选的Components
Set < BeanDefinition > candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate: candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
//设置我们的beanName
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
//这是默认配置 autowire-candidate
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
//获取@Lazy @DependsOn等注解的数据设置到BeanDefinition中
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
//把我们解析出来的组件bean定义注册到我们的IOC容器中(容器中没有才注册)
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
6,在上面的doScan方法里面,会有一个findCandidateComponents(basePackage) 的方法,主要是为了找到需要生成beanDefinition的候选者。进入这个方法,里面会有一个这个scanCandidateComponents方法用于扫描全部的候选者。并且里面有一个componentsIndex的一个索引,主要是为了增加这个查询的效率
public Set < BeanDefinition > findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
} else {
return scanCandidateComponents(basePackage);
}
}
7,接下来在查看这个scanCandidateComponents方法,就是用来扫描这些候选的Component配置类的。这里面的basePackage就是具体的包路径,比如说com.zhs.study,最后会将这个包路径转化为资源路径com/zhs/study。然后会去遍历这个资源集合,最后判断这些包路径下面的类是不是一个候选的component
private Set <BeanDefinition> scanCandidateComponents(String basePackage) {
Set <BeanDefinition> candidates = new LinkedHashSet<>();
try {
//把我们的包路径转为资源路径 com/zhs/study
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
//扫描指定包路径下面的所有.class文件
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
//遍历这个resources集合
for (Resource resource : resources) {
try {
//获取这个当前类的一个读取器,就可以读取当前类的类名,注解等
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
//判断当前类是不是一个候选的bean
if (isCandidateComponent(metadataReader)) {
//如果这个类是一个有效的bean
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
//判断类的属性,如是否是接口,抽象类,内部类等,如果是也不能注册
if (isCandidateComponent(sbd)) {
//加入到集合中
candidates.add(sbd);
}
}
}
}
}
}
8,判断这个类是不是一个有效的bean的方法如下,主要是在这个 isCandidateComponent 方法里面实现。
-
首先会判断一下这个类在不在这个excludeFilters排除过滤器里面,如果在里面,那么直接返回false;
-
如果不在排除过滤器里面,那么会判断在不在这个includeFilters包含过滤器里面,就是判断一下这个类上面有没有这个@Component的这个注解。
-
如果有这个@Component注解,又会去判断一下这个类上面有没有这个@Conditional这个条件注解,如果有这个注解,则会判断是否符合里面的条件,如果符合条件,那么可以成为一个BeanDefinition;如果没有这个注解,则可以通过这个过滤器,可以成为一个BeanDefinition
-
如果都不在这两个过滤器里面,那么也会返回一个false,表示不符合条件
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
//通过excludeFilters 进行是否需要排除的
for (TypeFilter tf: this.excludeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return false;
}
}
//includeFilters 是否需要进行包含的
for (TypeFilter tf: this.includeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return isConditionMatch(metadataReader);
}
}
return false;
}
//如果有这个@Component的这个注解,又会再判断一下这个这个类上面有没有加这个@Conditional的这个注解
private boolean isConditionMatch(MetadataReader metadataReader) {
if (this.conditionEvaluator == null) {
this.conditionEvaluator =
new ConditionEvaluator(getRegistry(), this.environment, this.resourcePatternResolver);
}
return !this.conditionEvaluator.shouldSkip(metadataReader.getAnnotationMetadata());
}
9,如果这个类是一个有效的bean,那么里面又内嵌了一个 isCandidateComponent 的布尔类型的方法,主要是判断一下这个有效bean的类是一个什么类型的类。如果里面不是一些接口,抽象类,内部类等,那么才能将这个有效的BeanDefinition对象加入set集合给返回。
protected boolean isCandidateComponent(AnnotatedBeanDefinition beanDefinition) {
AnnotationMetadata metadata = beanDefinition.getMetadata();
// metadata.isIndependent()=顶级类、嵌套类、静态内部类
// metadata.isConcrete() =非接口、非抽象类
// metadata.isAbstract() && metadata.hasAnnotatedMethods(Lookup.class.getName() = 抽象类并且必须方法中有@LookUp
return (metadata.isIndependent() && (metadata.isConcrete() ||
(metadata.isAbstract() && metadata.hasAnnotatedMethods(Lookup.class.getName()))));
}
10,回到5里面的doScan方法,再获取到这个全部需要生成的BeanDefinition之后,就会去给这个BeanDefinition进行一个初始的赋值。比如说设置一些作用域,bean的名字,是否懒加载等。
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
//这是默认配置 autowire-candidate
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
//获取@Lazy @DependsOn等注解的数据设置到BeanDefinition中
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
11,依旧是回到5里面的doScan的方法里面,再设置完一些属性之后,就会开始将这个BeanDefinition注册到这个springIoc的容器里面了。首先会判断一下这个BeanDefinition在这个容器里面是否存在,如果不存在,那么就会将这个BeanDefinition注册到这个springIoc的容器里面。
//把我们解析出来的组件bean定义注册到我们的IOC容器中(容器中没有才注册)
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
二,总结
1,BeanDifinitionScanner执行流程总结
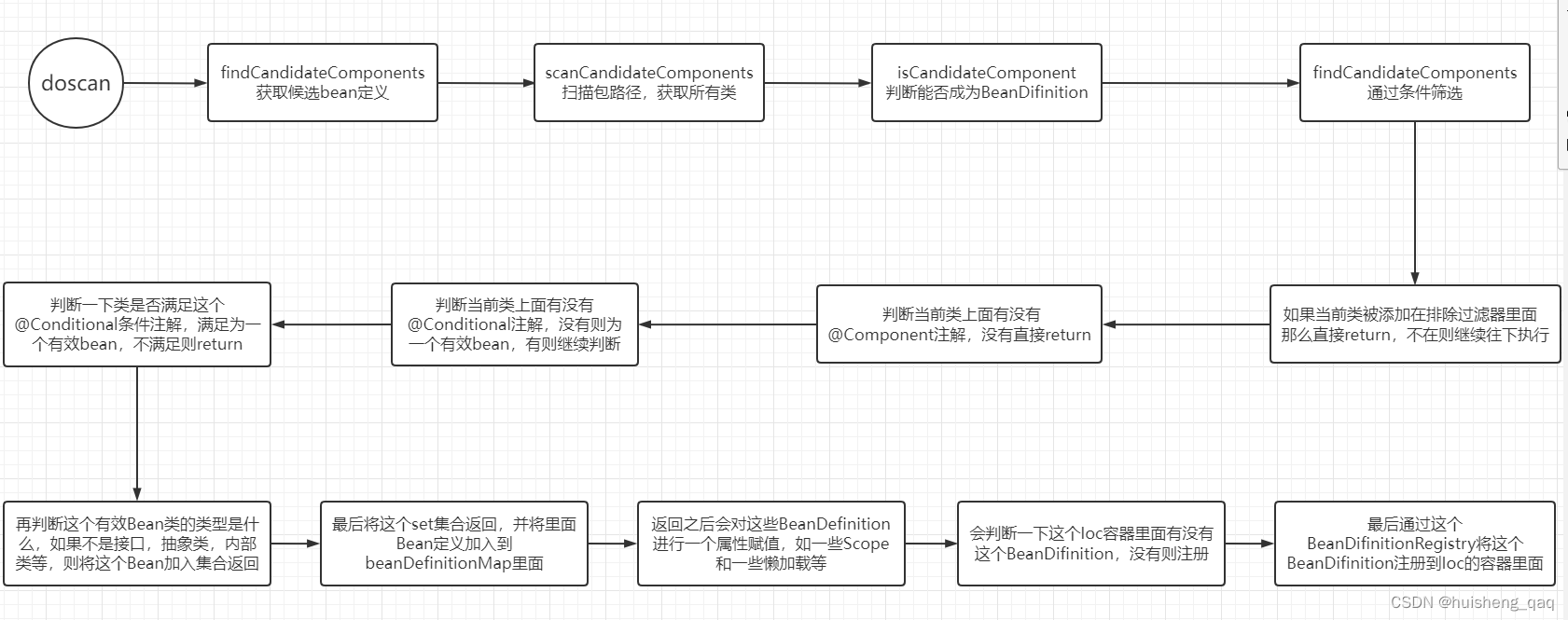
-
1,首先会调用一个scan的一个方法,然后调用里面的doscan方法开始真正的扫描。
-
2,首先会扫描所有的包路径,会获取包下面所有的类,然后会这些类都会成为一个被候选的类,如果满足条件那么就可以成为最终的BeanDefinition。
-
3,候选的规则如下,首先会判断一下这个类在不在一个excludeFilters的排除过滤器里面,如果在里面,那么直接返回;再判断一下这个类在不在一个includeFilters的包含过滤器里面,就是这个类上面有没有一个@Component这个类的注解,没有则直接return返回;有的话则继续判断一下这个类上面有没有一个@Conditional的条件注解,如果有的话看一下这个类是否满足里里面的条件表达式,如果不满足则直接return返回,如果满足的话就可以成为一个有效的BeanDifinition,如果这个类上面没有这个@Conditional的这个注解,那么也会成为一个有效的BeanDifinition
-
4,在成为一个有效的BeanDefinition之后,会判断一下这个BeanDefinition的类是一个什么类型,如果是接口,抽象类,内部类等,那么直接return ;如果不是接口,抽象类,内部类等,那么会将这个有效类加入到这个set集合里面,最后返回这个set集合
-
5,在获取到所有的BeanDefinition之后,会设置一些BeanDefinition的一些属性,如一些作用域、是否懒加载等,并且这些BeanDefinition都会加入到一个BeanDefinitionMap里面
-
6,最后会去判断一下这个Ioc容器里面是否存在这个BeanDefinition,如果不存在,那么会通过这个beanDefinitionRegistry将这个BeanDefinition注册到Spring的Ioc容器里面
2,@Component注解总结
就是在spring启动时,这个加了@Component这个注解上面的类,是在这个@IncludeFilter包含过滤器里面被创建和加载的。在创建这个@IncludeFilter的时候,就会去获取所有加了这个@Component这个注解的类,会把这些类加载到这个Spring的容器里面。
相关文章
- spring 之 类型转换 2
- Spring加载配置文件
- spring核心容器
- [Spring Boot ] Creating the Spring Boot Project : Demo: Creating a REST Controller
- Spring异常解决 java.lang.NullPointerException,配置spring管理hibernate时出错
- spring boot多环境配置
- spring boot日志框架体系剖析(默认采用logback作为日志框架)
- Spring AOP编程-传统aop开发总结
- Spring读源码系列之AOP--07---aop自动代理创建器(拿下AOP的最后一击)
- Spring读源码系列之AOP--03---aop底层基础类学习
- Spring读源码系列番外篇08---BeanWrapper没有那么简单--中
- Atitit db query op shourt code lib list 数据库查询最佳实践 JdbcTemplate spring v2 u77 .docx Atitit db query o
- Spring是什么
- @Value的使用 《Spring源码解析》java笔记
- spring security 在controller层 方法级别使用注解 @PreAuthorize("hasRole('ROLE_xxx')")设置权限拦截 ,无权限则返回403
- 毕业设计 Spring Boot的校园疫情师生防疫登记备案系统(含源码+论文)
- 毕业设计 Spring Boot的网上购物商城系统(含源码+论文)
- 毕业设计 Spring Boot的垃圾分类管理系统(含源码+论文)
- 毕业设计 Spring Boot的家教应聘招聘管理系统(含源码+论文)
- 解决com.alibaba.fastjson.JSONException: write javaBean error问题以及解决Spring Boot加入Shiro导致spring aop失效的问题
- Spring Cloud Vault介绍
- spring-boot-starter-redis配置详解
- Spring Boot 1.X和2.X优雅重启实战
- 005-spring mvc 请求转发和重定向
- 006-spring cloud gateway-GatewayAutoConfiguration核心配置-GatewayProperties初始化加载、Route初始化加载
- Spring JDBC调用存储过程
- [手写spring](2)初始化BeanDefinitionMap
- 【Spring源码学习】spring IOC容器管理