
JavaSE进阶:集合框架(一)
目录
1.集合的概念
概念:
对象的容器,实现了对对象常用的操作。类似数组功能集合中存储的是元素对象的地址
和数组的区别:
集合和数组都是容器,都可以存储数据
数组长度固定,集合长度不固定
数组可以存储基本类型和引用类型,集合只能存储引用类型
数组适合做个数和类型确定的场景
集合适合做数据类型不确定,而且做增删元素的场景,集合种类更多,功能更强大数组存储的元素必须是同一个数据类型;集合存储的对象可以是不同数据类型。
位置:
java.util.*;
2.泛型
Java泛型是JDK1.5后引入的一个新特性,可以在编译阶段约束操作的数据类型,并进行检查。
泛型的格式:<数据类型>
注意:泛型只能支持引用数据类型。特殊性:等待接收指定的数据
常见形式有泛型类、泛型接口、泛型方法
语法:<T,...>T称为类型占位符,表示一种引用类型,如果编写多个,使用逗号(,)隔开好处:1. 同意数据类型,提高代码重用性 2. 防止类型转换异常,提高代码安全性
泛型本质上是提供类型的“类型参数”,也就是参数化类型。
泛型作用 : 强制了集合存储固定的数据类型,而保证类型转换的绝对安全。
泛型的书写格式:
集合类<存储的数据类型> 变量名 = new 集合类<存储的数据类型>();
1.泛型类
语法:public class 类名<T>{}
T是类型占位符,表示一种引用类型,如果编写多个,使用逗号(,)隔开
这里的泛型变量T可以随便写为任意标识,只是变量名,满足标识符要求即可
作用:编译阶段可以指定数据类型,类似于集合的作用。
当自定义的一个类中的所有方法都需要操作相同的数据类型且暂时无法确定类型时,可以在类后通过定义一个泛型作为一个标识符,当该标识符被确定为某一个具体的类型时,该类中的所有方法的数据类型也一并确定。
//使用泛型类创建对象
//注意:1.泛型只能使用引用类型 2.不同泛型类型之间不能相互赋值
package java_se.java_jinjie.jihe.collection.demo03;
public class TestGeneric {
public static void main(String[] args) {
//使用泛型类创建对象
//注意:1.泛型只能使用引用类型 2.不同泛型类型之间不能相互赋值
//String
MyGeneric<String> myGeneric=new MyGeneric<>();//JDK7之后可以不写后边<>的类型
myGeneric.t="hello";
myGeneric.show("大家好,加油");
String string = myGeneric.getT();
//Integer
MyGeneric<Integer> myGeneric2=new MyGeneric<>();
myGeneric2.t=100;
myGeneric2.show(200);
Integer integer = myGeneric2.getT();
// MyGeneric<String> myGeneric3=myGeneric2;//报错 不同泛型类型之间不能相互赋值
}
}
/*
package java_se.java_jinjie.jihe.collection.demo03;
/**
* 泛型类
* 语法:类名<T>
* T是类型占位符,表示一种引用类型,如果编写多个,使用逗号(,)隔开
* @param <T>
public class MyGeneric<T> {
//使用泛型T
//1.创建变量
T t;
//2.添加方法
public void show(T t){
// T t1 = new T();//x不能new因为不能确定类型,也不能确定这个变量是否私有
System.out.println(t);
}
//3.泛型作为方法的返回值
public T getT(){
return t;
}
}
*/
2.泛型接口
语法:
public class A<> implements B {} 用的时候再确定用什么引用类型
public class A implements B<> {} 用之前就确定用什么引用类型
public class A<> implements B<> {} A的泛型表示本身泛型类的某种引用类型,B的泛型表示A的泛型传给B的泛型时的某种引用类型
不能泛型静态常量 可以正常接口静态常量
实现类可以在实现接口的时候传入自己操作的数据类型,这样重写的方法都将是针对于该类型的操作
作用:泛型接口可以让实现类选择当前功能需要操作的数据类型
package java_se.java_jinjie.jihe.collection.demo03;
public class TestInterfacempl {
public static void main(String[] args) {
MyInterfacempl impl = new MyInterfacempl();//用之前就在实现类确定的类型
impl.server("xxxxxx");
MyInterfacempl2<Integer> impl2 = new MyInterfacempl2<>();//用的时候在确定类型
impl2.server(1000);
}
}
/*
package java_se.java_jinjie.jihe.collection.demo03;
* 泛型接口
* 语法:接口名<T>
* 不能创建泛型静态常量
public interface MyInterface<T> {
String name="张三";//public static final接口默认常量
T server(T t);
}
package java_se.java_jinjie.jihe.collection.demo03;
// 这里自己的方法可以任意类型,但是重写的类型一定是String类型
public class MyInterfacempl implements MyInterface<String>{
@Override
public String server(String t) {
System.out.println(t);
return null;
}
}
package java_se.java_jinjie.jihe.collection.demo03;
// 自身类方法类型可以为任意引用类型 重写接口为任意类型
public class MyInterfacempl2<T> implements MyInterface{
@Override
public Object server(Object o) {
System.out.println(o);
return null;
}
}
*/
3.泛型方法
语法:public <T> T show(T t){} 这里的<T>只表示是一个泛型方法 前面加static 和final不会报错
作用:方法中可以使用泛型接收一切实际类型的参数,方法更具备通用性
调用泛型方法时返回值类型必须为T(引用类型)或其他的引用类型,如果不为指定的返回值类型,运行异常
泛型方法自动装箱操作
package java_se.java_jinjie.jihe.collection.demo03;
public class TestDome1 {
public static void main(String[] args) {
Demo1 d1 = new Demo1();
d1.show(1);//自动装箱操作 给自动变为对应的引用类型
d1.show("2");//自动装箱操作 给自动变为对应的引用类型
d1.show(3.14);//自动装箱操作 给自动变为对应的引用类型
Demo1 d2 = new Demo1();
d2.show1("6");//只能定义为String
System.out.println(d2.equals("6"));
}
}
/*
package java_se.java_jinjie.jihe.collection.demo03;
//泛型方法
//语法:<T> 返回值类型
public class Demo1 {
public <T> T show(T t){//这里的<T>只表示是一个泛型方法 前面加static 和final不会报错
System.out.println("泛型方法"+t);
return t;
}
public <T> String show1(T t1){//这里(的值只能为T或String(返回值的类型))但是最后的返回值必须为String,否则运行异常,不建议这么写
System.out.println("泛型方法"+t1);
return (String) t1;
}
}
*/
4.泛型好处
Java泛型是JDK1.5中引入的一个新特性,其本质是参数化类型,把类型作为参数传递。
常见形式有泛型类、泛型接口、泛型方法。
语法:
●<T...> T称为类型占位符,表示一种引用类型。
好处:
●(1) 提高代码的重用性
●(2) 防止类型转换异常,提高代码的安全性
5.泛型集合
概念:参数化类型、类型安全的集合,强制集合元素的类型必须一致
特点:
编译时即可检查,而非运行时抛出异常
访问时,不必类型转换(拆箱)
不同泛型之间应用不能相互赋值,泛型不存在多态
package java_se.java_jinjie.jihe.collection.demo03;
import java_se.java_jinjie.jihe.collection.Student;
import java.util.ArrayList;
import java.util.Iterator;
public class Demo02 {
public static void main(String[] args) {
ArrayList<Object> objects = new ArrayList<>();
objects.add(1);
objects.add("1");
objects.add(1.1);
for (Object o:objects) {
System.out.println(o);//Object泛型遍历所有类型
}
for (Object o:objects) {
// String str=(String) o;//因为泛型为Object,可以变为所有引用类型,但是在遍历的时候不能遍历一种类型
// System.out.println(str);
}
ArrayList<String> strings = new ArrayList<>();
// objects.add(1);//在写好泛型类型的时候就已经确认好能添加什么类型了
strings.add("1");
strings.add("2");
// objects.add(1.1);
for (String s:strings) {
System.out.println(s.toString());//Object泛型遍历所有类型
}
ArrayList<Student> students = new ArrayList<>();
Student s1 = new Student("张三",3);
Student s2 = new Student("李四",4);
Student s3 = new Student("王五",5);
students.add(s1);
students.add(s2);
students.add(s3);
Iterator<Student> it = students.iterator();
while (it.hasNext()){
Student s=it.next();
System.out.println(s);
}
//students=objects;//不同的泛型类型是不能相互赋值的
}
}
6.泛型通配符
通配符:?
- ?可以在“使用泛型”的时候代表一切类型
- E T K V是在定义泛型的时候使用的
泛型限定(限制的是数据类型)
作用:在创建一个泛型类对象时限制这个泛型类的类型必须实现或继承某个接口或类。
格式: 泛型类名称<? extends List>a = null;
<? extends List>作为一个整体表示类型未知,当需要使用泛型对象时,可以单独实例化。
泛型的上下限:
<? extends E> :?传递E类型或者是E的子类——泛型上限
<? super E> :?传递E类型或者是E的父类——泛型下限
3.数据结构
数据结构概述:
数据结构是计算机底层储存、组织数据的方式,是指数据相互之间是以什么方式排列在一起的
通常情况下,精心选择的数据结构可以带来更高的运行或储存效率
常见的数据结构:
栈、队列、数组、链表、二叉树、二叉查找法、平衡二叉树、红黑树等一些不常用的数据结构
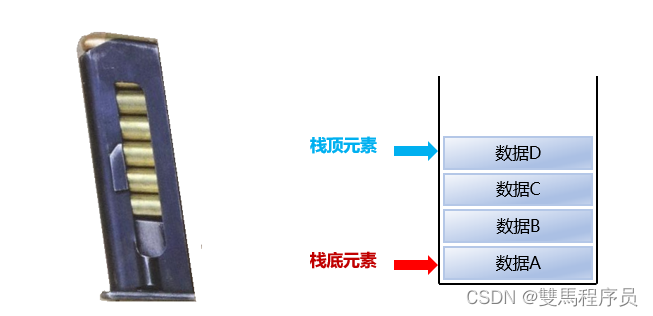
1.栈
后进先出,先进后出
数据进入栈模型的过程称为:压/进站
数据离开站模型的过程称为:弹/出栈
自下往上堆积,A需要等D、C、B离开才能离开
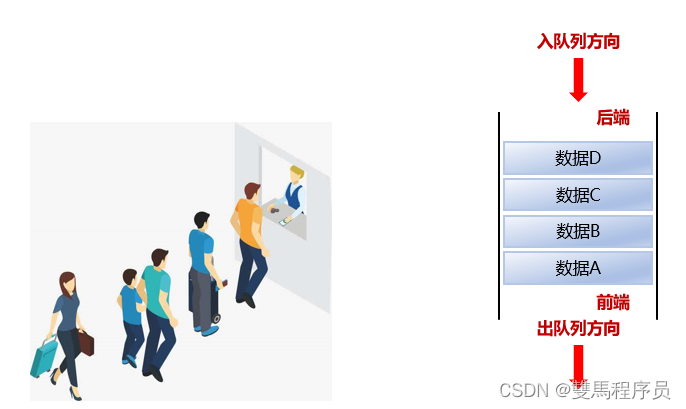
2.队列
先进先出,后进后出
数据从入队列方向进入
数据从出队列方向离开
比如:买饭排队,先买的买完直接从出口方向走,后面从入口方向进
3.数组
数组是一种查询快,增删慢的模型
查询速度快:查询数据通过地址值和索引定位,查询任意数据元素耗时相同(元素在内存中是连续存储的)
增删效率低:要将原始数据增加或删除,同时后面每个数据后移或前移

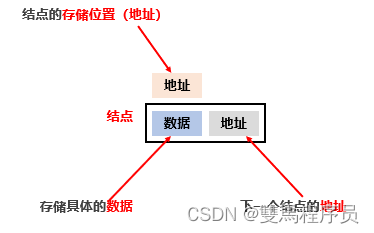
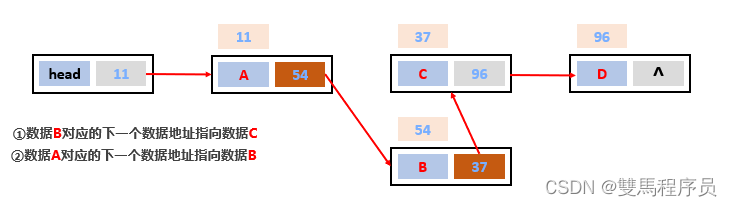
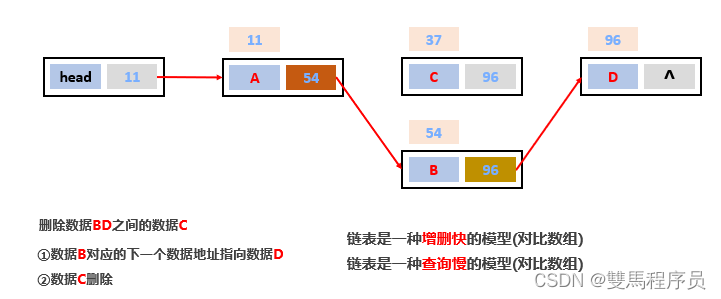
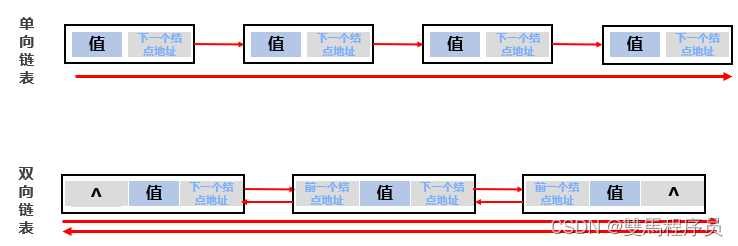
4.链表
链表中的元素是在内存中不连续存储的,每个元素节点包含数据值和下一个元素的地址。
链表中的元素是游离存储的,每个元素节点包含数据值和下一个元素的地址。
链表查询慢。无论查询哪个数据都要从头开始找
链表增删相对快
查询慢 ,增删快(相比于数组)

5.二叉树
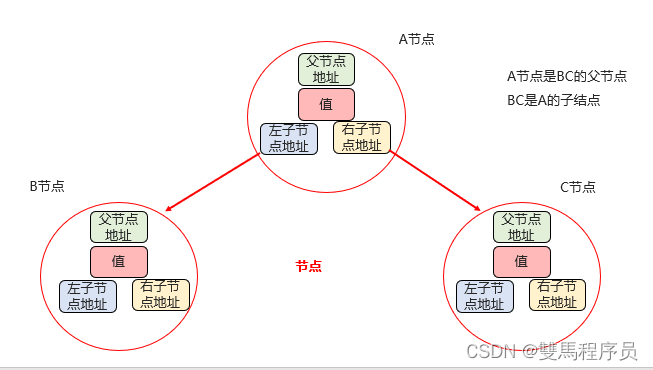
概述:
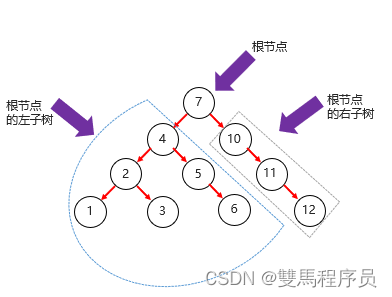
二叉树只能有一个根节点:每个节点最多支持两个直接子节点
节点的度:节点拥有的子树的个数,二叉树的度不大于2;叶子节点度为0的节点,也称之为终端节点
高度:叶子“结点”的高度为1,叶子"结点"的父“节点”高度为2,以此类推,根节点的高度最高
层:根节点在第一层,以此类推
兄弟节点:拥有共同父节点的节点称为兄弟节点

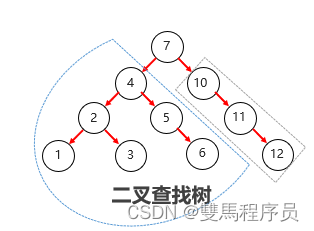
6.二叉查找树
二叉查找树又称二叉排序树或二叉搜索树
目的:提高检索数据的性能
特点:
1.每个节点上最多有两个字节点
2.左子树上所有节点的值都小于根节点的值
3.右子树上对的所有节点的值都大于根节点的值
规则:小的存左边,大的存右边,一样的不存
二叉查找树存在问题:出现瘸子现象,导致查询的性能与单列表一样,查询速度变慢
如:根节点为7,他的左子节点为6,右子节点为8、9、10、11
7.平衡二叉树
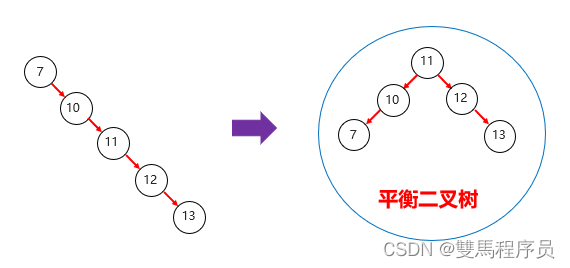
平衡二叉树的要求
平衡二叉树是在满足查找二叉树的大小规则下,让树尽可能矮小,以此提高查数据的性能
平衡二叉树必定是二叉搜索树,反之则不一定
任意节点的两个左右子树的高度差不超过1,任意节点的左右两个子树都是一颗平衡二叉树
8.红黑树
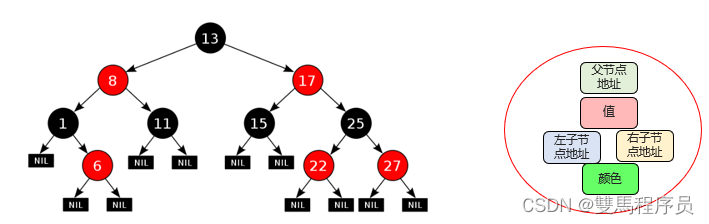
概括:
红黑树是一种自平衡的二叉查找树,是计算机科学中用刀的一种数据结构
1972年出现,当时被称位平衡二叉B树,1978年被修改为如今的红黑树
每一个节点可以是红或者是黑;红黑树不是通过高度平衡的,他的平衡是通过"红黑规则"进行实现的
红黑规则:
每个节点要么是黑色要么是洪泽,根节点必须是黑色。
如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)。
对每一个节点,从根节点到其叶节点或空 子节点的每条路径,均包含相同数目的黑色节点
如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点,每个叶节点(Nil)是黑色的;
红色节点效率高
特点:红黑树的增删改查的性能都很好
相关文章
- Javascript 学习总结,基本语法,数据类型,集合,类型转换,方法的使用,匿名方法,DOM,BOM,注册事件,动态操作元素,操作样式
- Java中的集合类
- Collections工具类(操作集合的工具类)
- Google Earth Engine(GEE)——计算两个影像集合间的相关性(MODIS中蒸散发数据和降水数据相关性)内涵统一两个影像之间的重分类和重投影以及影像的联合功能。
- Google Earth Engine(GEE)—— ImageCollection 影像集合上的映射
- Java判断List集合中的对象是否包含有某一元素
- 对集合排序的三种方式
- 获取精美的壁纸和神经网络训练素材的网站集合
- Java回顾之集合
- vscode插件集合
- Java集合细节(一):请为集合指定初始容量
- 集合对象转换为数组并把其转换为以逗号或者其它符号分隔的字符串
- 循环中逐一添加集合的方法
- 【JavaSE】13-集合
- javaSE集合
- C# 中的一些集合类