
Go爬虫学习笔记(四)
day4
07|冰川之下:深入Go高并发网络模型
Go 是以同步的方式来处理网络 I/O 的,它会等待网络 I/O 就绪后,才继续下面的流程,这是符合开发者直觉的处理方式。
Go 语言高效,是因为在同步处理的表象下,Go 运行时封装 I/O 多路复用,灵巧调度协程,实现了异步的处理,也实现了对 CPU 等资源的充分利用。
-
阻塞与非阻塞
-
IO密集型:如果程序的大多数时间花费在等待 I/O 上,这种程序就是 I/O 密集型(I/O bound)的。
-
CPU密集型:如果当前程序处理的时间大多数花在 CPU 上,它就是 CPU 密集型(CPU-bound)系统。
-
高效的网络服务:
- 一个任务的阻塞不影响其他任务的执行;
- 任务之间能够并行;
- 当阻塞的任务准备好之后,能够通过调度恢复执行。
-
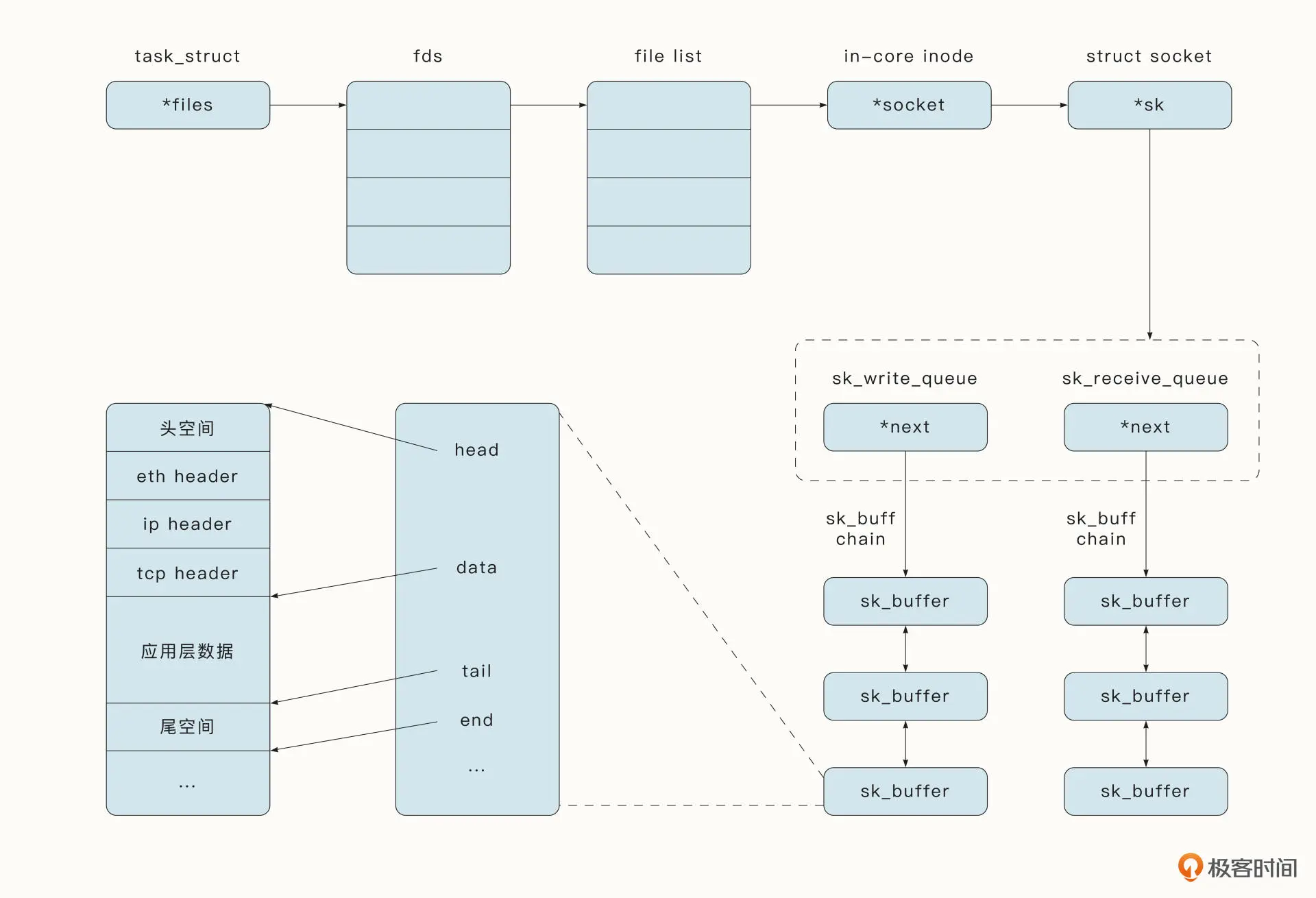
socket:Socket 是一个特殊的文件,存储在描述进程的 task_struct 结构中。
-
Socket 结构中存储了发送队列与接收队列,每一个队列中保存了结构sk_buffer。sk_buff 是代表数据包的主要网络结构,但是 sk_buff 本身存储的是一个元数据,不保存任何数据包数据,所有数据都保存在相关的缓冲区中。
-
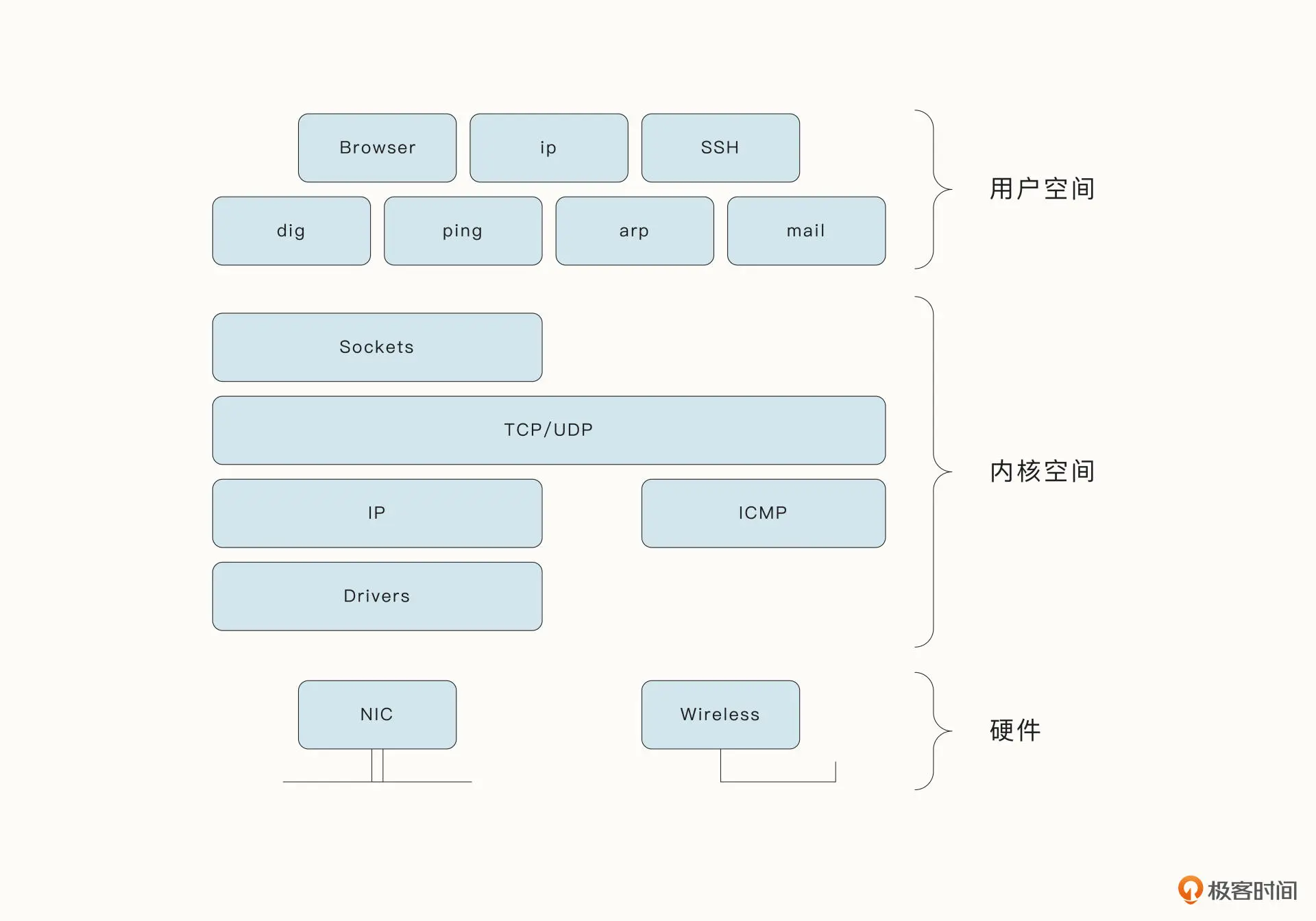
硬件、操作系统内核、用户态空间中分别对应的组件和交互
-
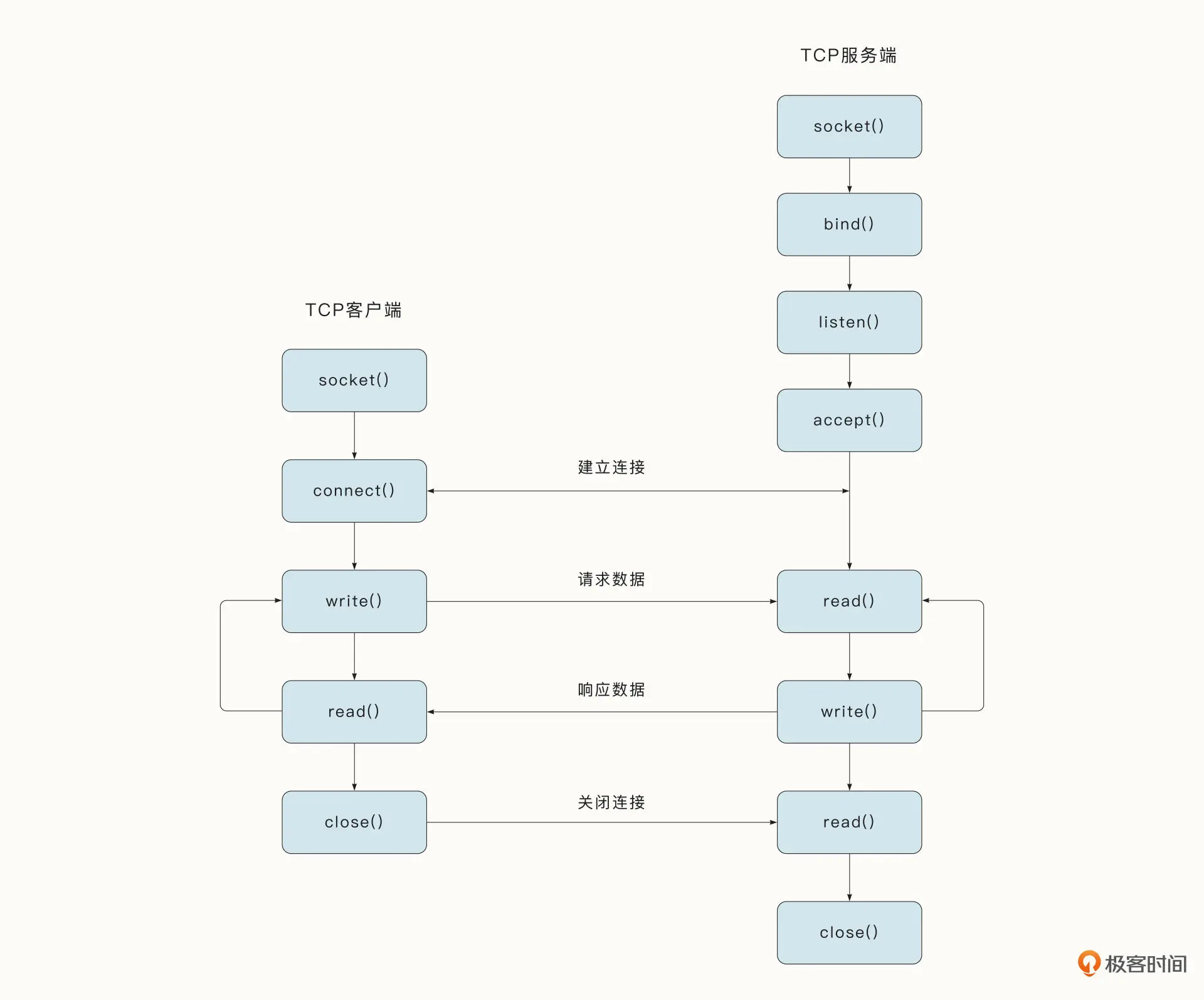
还有些时候,Socket 指的是 Socket API 中的 socket 函数。例如,在 Unix 典型的 TCP 连接中,需要完成诸多系统调用,但是第一步往往都是调用 socket 函数。
-
I/O模型
阻塞I/O
阻塞 I/O 是最简单直接的类型,例如,read 系统调用函数会一直堵塞,直到操作完成为止。
非阻塞I/O
非阻塞 I/O 顾名思义不会陷入到阻塞,它一般通过将 Socket 指定为 SOCK_NONBLOCK 非堵塞模式来实现。这时就算当前 Socket 没有准备就绪,read 等系统调用函数也不会阻塞,而会返回具体的错误。所以,这种方式一般需要开发者采用轮询的方式不时去检查。
多路复用 I/O
多路复用 I/O 是一种另类的方式,它仍然可能陷入阻塞,但是它可以一次监听多个 Socket 是否准备就绪,任何一个 Socket 准备就绪都可以返回。典型的函数有 poll、select、epoll。多路复用仍然可以变为非阻塞的模式,这时仍然需要开发者采用轮询的方式不时去检查。
信号驱动 I/O
信号驱动 I/O 是一种相对异步的方式,当 Socket 准备就绪后,它通过中断、回调等机制来通知调用者继续调用后续对应的 I/O 操作,而后续的调用常常是堵塞的。
异步 I/O
异步 I/O 异步化更加彻底,全程无阻塞,调用者可以继续处理后续的流程。所有的操作都完全托管给操作系统。当 I/O 操作完全处理完毕后,操作系统会通过中断、回调等机制通知调用者。Linux 提供了一系列 aoi_xxx 系统调用函数来处理异步 I/O。
Reactor网络模型
Reactor网络模型 = I/O多路复用 + 线程池。
目前,Linux 平台上大多数知名的高性能网络库和框架都使用了 Reactor 网络模型,包括 Redis、Nginx、Netty、Libevent 等等。
Reactor 本身有反应堆的意思,表示对监听的事件做出相应的反应。Reactor 网络模型的思想是监听事件的变化,一般是通过 I/O 多路复用监听多个 Socket 状态的变化,并将对应的事件分发到线程中去处理。
- 单 Reactor 单进程 / 线程;
- 单 Reactor 多线程;
- 多 Reactor 多进程 / 线程。
Reactor多线程:主 Reactor 使用 selelct 等多路复用机制监控连接建立事件,收到事件后通过 Acceptor 接收,并将新的连接分配给子 Reactor。随后,子 Reactor 会将主 Reactor 分配的连接加入连接队列,监听 Socket 的变化,当 Socket 准备就绪后,在独立的线程中完成完整的业务流程。
基于协程的网络处理模型
同步编程 + 多路复用 + 非阻塞 I/O+ 协程调度。
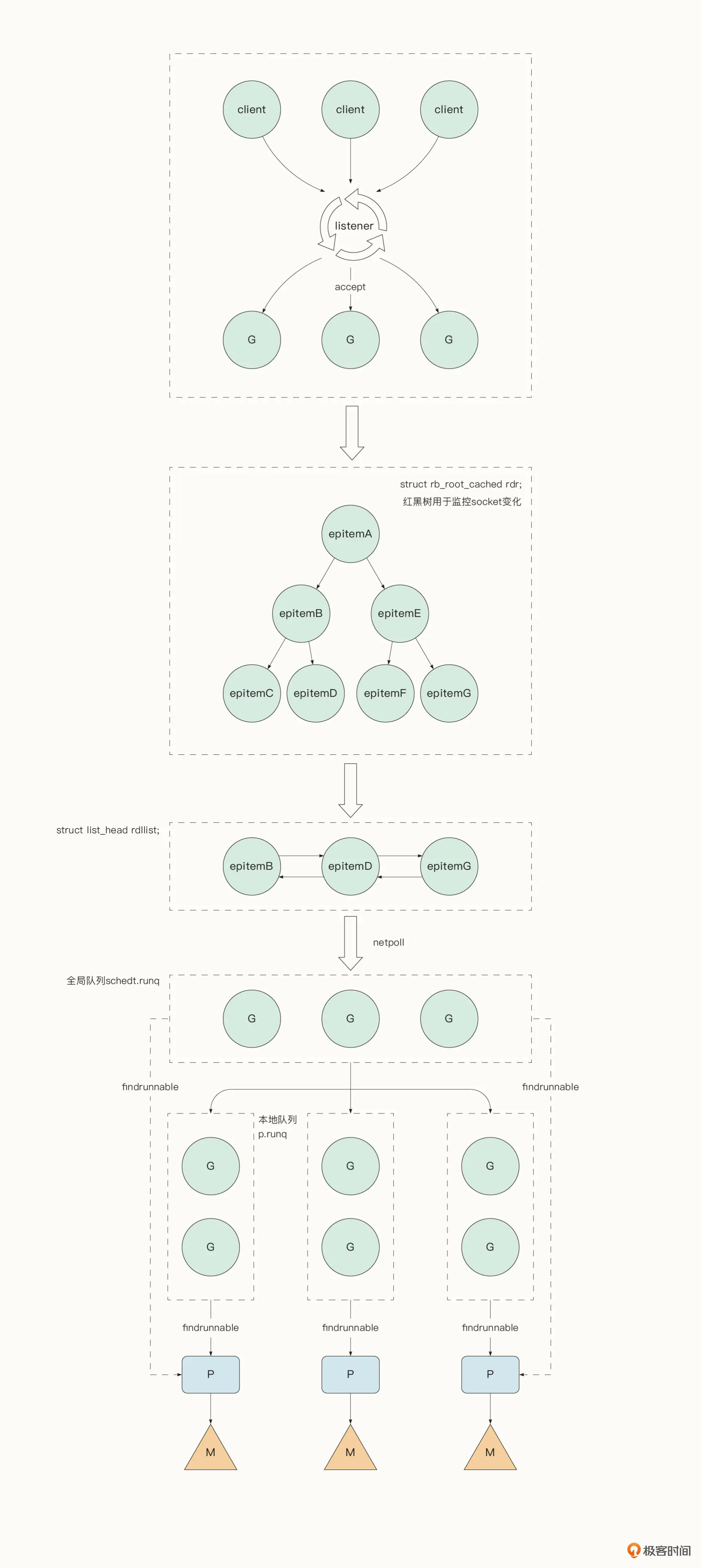
在多核时代,Go 在线程之上创建了轻量级的协程。作为并发原语,协程解决了传统多线程开发中开发者面临的心智负担(内存屏障、死锁等),并降低了线程的时间成本与空间成本。
Go 标准的网络库实现了对于不同操作系统提供的多路复用 API(epoll/kqueue/iocp)的封装。我们可以把 Go 语言的这种机制称作 netpoll。例如在 Linux 系统中,netpoll 封装的是 epoll。epoll 是 Linux2.6 之后新增的,它采用了红黑树的存储结构,在处理大规模 Socket 时的性能显著优于 select 和 poll。关于 select 和 poll 接口的缺陷,可以参考《The Linux Programming Interface》第 63 章。
epoll 中提供了 3 个 API,epoll_create 用于初始化 epoll 实例、epoll_ctl 将需要监听的 Socket 放入 epoll 中,epoll_wait 等待 I/O 可用的事件。
#include <sys/epoll.h>
int epoll_create(int size);
int epoll_ctl(int epfd,int op,int fd,struct epoll_event*event);
int epoll_wait(int epfd,struct epoll_event* events,int maxevents,int timeout);
在 Go 中对其封装的函数为:
// netpoll_epoll.go
func netpollinit()
func netpollopen(fd uintptr, pd *pollDesc) int32
func netpoll(delay int64) gList
Go 运行时只会全局调用一次 netpollinit 函数。而我们之前看到的 conn.Read、conn.Write 等读取和写入函数底层都会调用 netpollopen 将对应 Socket 放入到 epoll 中进行监听。
程序可以轮询调用 netpoll 函数获取准备就绪的 Socket。netpoll会调用 epoll_wait 获取 epoll 中 eventpoll.rdllist 链表,该链表存储了 I/O 就绪的 socket 列表。接着 netpoll 取出与该 Socket 绑定的上下文信息,恢复堵塞协程的运行。
调用netpoll 的时机:
-
系统监控定时检测。Go 语言在初始化时会启动一个特殊的线程来执行系统监控任务 sysmon。系统监控在一个独立的线程上运行,不用绑定逻辑处理器 P。系统监控每隔 10ms 会检测是否有准备就绪的网络协程,若有,就放置到全局队列中。
func sysmon() { ... if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now { atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now)) // netpoll获取准备就绪的协程 list := netpoll(0) if !list.empty() { incidlelocked(-1) // 放入可运行队列中 injectglist(&list) incidlelocked(1) } } } -
在调度器决定下一个要执行的协程时,如果局部运行队列和全局运行队列都找不到可用协程,调度器会获取准备就绪的网络协程。调度器通过 runtime.netpoll 函数获取当前可运行的协程列表,返回第一个可运行的协程。然后通过 injectglist 函数将其余协程放入全局运行队列等待被调度。涉及到调度器的原理,在后面还会详细介绍。
func findrunnable() (gp *g, inheritTime bool) { ... if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 { if list := netpoll(0); !list.empty() { // non-blocking gp := list.pop() injectglist(&list) casgstatus(gp, _Gwaiting, _Grunnable) if trace.enabled { traceGoUnpark(gp, 0) } return gp, false } } }
要注意的是,netpoll 处理 Socket 时使用的是非堵塞模式,这也意味着 Go 网络模型中不会将阻塞陷入到操作系统调用中。而强大的调度器又保证了用户协程陷入堵塞时可以轻松的切换到其他协程运行,保证了用户协程公平且充分的执行。这就让 Go 在处理高并发的网络请求时仍然具有简单与高效的特性。
线程与协程
线程缺陷:
- 线程的时间成本主要来自于切换线程上下文时,用户态与内核态的切换、线程的调度、寄存器变量以及状态信息的存储。
- 如果两个线程位于不同的进程,进程之间的上下文切换还会因为内存地址空间的切换导致缓存失效,所以不同进程的切换要显著慢于同一进程中线程的切换(现代的 CPU 使用快速上下文切换技术解决了进程切换带来的缓存失效问题)。
- 线程的空间成本主要来自于线程的堆栈大小。线程的堆栈大小一般是在创建时指定的,为了避免出现栈溢出(Stack Overflow),默认的栈会相对较大(例如 2MB),这意味着每创建 1000 个线程就需要消耗 2GB 的虚拟内存,这大大限制了创建的线程的数量(虽然 64 位的虚拟内存地址空间已经让这种限制变得不太严重了)。
线程优化:
- 线程的特性决定了线程的数量并不是越多越好。实践中不会无限制地创建线程,而是会采取线程池等设计来控制线程的数量。
协程优势:
-
Go 语言中的协程栈大小默认为 2KB,并且是动态扩容的。
-
协程的特性决定了在实践中,我们一般不会考虑创建一个协程带来的成本。如下为一个典型的网络服务器,main 函数中监听新的连接,每一个新建立的连接都会新建了一个协程执行 handle 函数。这种设计是符合开发者直觉的,因此其书写起来非常简单。在正常情况下网络服务器会出现成千上万的协程,但 Go 运行时的调度器也能够轻松应对。
func main() { listen, err := net.Listen("tcp", ":8888") if err != nil { log.Println("listen error: ", err) return } for { conn, err := listen.Accept() if err != nil { log.Println("accept error: ", err) break } // 开启新的Groutine,处理新的连接 go Handle(conn) } } func Handle(conn net.Conn) { defer conn.Close() packet := make([]byte, 1024) for { // 阻塞直到读取数据 n, err := conn.Read(packet) if err != nil { log.Println("read socket error: ", err) return } // 阻塞直到写入数据 _, _ = conn.Write(packet[:n]) } }
I/O 可以分为磁盘 I/O 与网络 I/O,你知道 Go 在处理二者时的区别吗?
网络 IO
- 能够用异步化的事件驱动的方式来管理,磁盘 IO 则不行.
- 网络 IO 的socket 的句柄实现了 .poll 方法,可以用 epoll 池来管理. 文件 IO 的 read/write 都是同步的 IO ,没有实现 .poll 所以也用不了 epoll 池来监控读写事件,所以磁盘 IO 的完成只能同步等待。
「此文章为3月Day4学习笔记,内容来源于极客时间《Go分布式爬虫实战》,强烈推荐该课程!/推荐该课程」
相关文章
- 《Go并发编程实战》第2版 紧跟Go的1.8版本号
- go vendor目录
- Go分布式爬虫笔记(二十二)
- Go分布式爬虫学习(七)
- Go爬虫学习笔记(三)
- Go爬虫学习笔记
- Understanding Tensorflow using Go
- 03、GO语言变量定义、函数
- [转]GO err is shadowed during return
- Go语言练习:go语言与C语言的交互——cgo
- GO语言练习:第一个Go语言工程--排序
- Go开发中如何进行自定义Response.go封装实现
- 【Go语言入门教程】WaitGroup 实现并发等待
- PHP转Go实践:xjson解析神器「开源工具集」
- Alpine容器中运行go的二进制文件
- Go 1.5keyword搜索文件夹、文件、文件内容_修复一个小BUG
- Debian 系统 开发 GO 语言
- go语言指针符号的*和&