
FlinkCEP的底层理论:NFA-b Automaton原理介绍
1. 基本概念
1.1. NFAb介绍
FlinkCEP是基于《Efficient Pattern Matching over Event Streams》这篇论文的思想实现的。
该论文提出了一种在事件流上进行高效模式匹配的方法,即带匹配缓存的非确定有限自动机【Non-deterministic finite automaton】,又称为NFAb自动机。
1.2. SASE+
SASE+语言:一个复杂的事件语言,它支持事件流上的Kleene闭包,并对该语言的可表达性提供了形式化的分析。
SASE+是一种专门用来描述CEP pattern的通用语言
1.3. CEP模式操作符
CEP模式操作符
【org.apache.flink.cep.operator.CepOperator】
- 针对键控输入流【keyed input stream】,对于每个键,CepOperator创建一个NFA和一个优先队列来缓冲顺序乱序的事件,这两种数据结构都使用托管键控状态进行存储。
- 针对于非键控输入流,CepOperator创建一个的全局NFA。
当事件被处理时,它更新NFA的内部状态机。
属于部分匹配序列的事件被保存在内部的SharedBuffer缓冲区【一个内存优化的数据结构】中。
当包含事件的所有匹配序列时碰到如下情况时,将删除缓冲区中的事件:
- emitted (success)
- discarded (patterns containing NOT)
- timed-out (windowed patterns)
2. NFAbAutomaton原理
2.1. NFAbAutomaton的定义与构造
在大学《形式语言与自动机》课程中的非确定有限状态机(NFA),用一句话概括就是:对于每个<状态,输入符号>二元组,其状态转移可以有多个,而不是确定的一个。
NFAbAutomaton的定义与普通NFA略有不同,为五元组:A = (Q, E, θ, q1, F)
说明如下:
- Q: 表示状态集合 a set of states
- E: 表示状态转移的有向边集合 a set of directed edges
- θ: 表示状态转移的公式集合,与E共同作用 a set of formulas
- q1: 表示边的初始状态;labelling those edges a start state
- F: 表示最终状态 a final state
下面通过实例来构造NFAbAutomaton。
先通过SASE+语言]定义如下的股票趋势事件模式:
PATTERN SEQ(Stock+ a[ ], Stock b)
WHERE skip_till_next_match(a[ ], b) {
[symbol]
and a[1].volume > 1000
and a[i].price > avg(a[..i-1].price)
and b.volume < 80%*a[a.LEN].volume }
WITHIN 1 hour
此事件模式以1小时作为时间窗口的长度,以“交易量大于1000”作为匹配序列的起始,且要求序列中股票的最近价格必须高于之前所有交易价格的均值,当检测到该股票的交易量下跌到最近一次交易量的80%以下时,则成功匹配整个事件模式。
根据此股票趋势事件模式,构造出NFAbAutomaton,如下图所示。这也是Flink CEP中NFACompiler组件需要做的事情。

匹配序列a[]的生成过程 就是构造符合谓词约束的事件的Kleene +闭包的过程
NFAbAutomaton的每个状态都有各自的匹配缓存,用于在运行时存储当前的匹配结果。
the start state, a[1], is where the matching process begins. It awaits input to start the Kleene plus and to select an event into the a[1] unit of the match buffer. At the next state a[i], it attempts to select another event into the a[i] (i > 1) unit of the buffer. The subsequent state b denotes that the matching process has fulfilled the Kleene plus (for a particular match) and is ready to process the next pattern component. The final state, F, represents the completion of the process, resulting in the creation of a pattern match.
- 初始状态a[1]是匹配过程开始的位置,即NFAbAutomaton的初始状态。它等待输入以启动Kleene plus并将一个事件【交易量大于1000的事件】选择到匹配缓冲区的a[1]单元中。
- 在下一个状态a[i]时,它尝试选择另一个事件【最近价格高于之前所有交易价格的均值】到缓冲区的a[i] (i > 1)单元中。a[i]是正在构造Kleene +的状态
- 随后的状态b表示匹配过程已经完成了Kleene +(对于特定的匹配)闭包,并准备处理下一个模式组件【交易量下跌到最近一次交易量的80%以下】。
- 最后的状态F表示流程的完成,从而创建模式匹配。
2.2. 状态转移语义
复杂事件模式的匹配过程:本质上是输入事件流驱动NFAbAutomaton进行状态转移的过程。
根据θ集合定义的条件,在有向边集合E上可以定义4种状态转移语义:
- begin:消费输入事件,存入缓存,并转移到下一个状态;
- take:消费输入事件,存入缓存,并保持当前状态;
- ignore:忽略输入事件,不存入缓存,并保持当前状态;
- proceed:感知输入事件,转移到下一个状态,同时保留该事件给下一个状态处理。
结合这4种状态转移语义,就可以读懂上图中的转移公式了。
FlinkCEP的StateTransitionAction定义中没有begin语义,仅有take、ignore和proceed语义,但是它和NFAbAutomaton是等价的
/** Set of actions when doing a state transition from a {@link State} to another. */
public enum StateTransitionAction {
TAKE, // take the current event and assign it to the current state
IGNORE, // ignore the current event
PROCEED // do the state transition and keep the current event for further processing (epsilon transition)
}
2.3. 事件选择策略
事件选择策略:指选择符合条件的事件进入正闭包——即扩展匹配序列的方法。在时间窗口的限制之内,常用的有以下三种策略。
- Strict contiguity(严格连续):在最严格的事件选择策略中,两个选定的事件必须在输入流中是连续的。这种要求在正则表达式匹配字符串、DNA序列等时很常见。
- 严格按顺序选择所有符合条件的事件,途中不能出现不符合条件的事件
- 对应FlinkCEP API中的Pattern.next()/notNext();
- Partition contiguity:两个选定的事件不需要是连续的; 但是如果事件是根据一个条件在概念上划分的,那么在同一分区中,下一个相关事件必须与前一个相关事件相邻
- 例如示例中的[symbol],通常用于形成分区。然而如果事件模式的目的是检测价格上涨的总体趋势,尽管存在一些局部波动值,那么分区相邻可能不够灵活导致无法支持。
- 对应FlinkCEP在键控输入流【keyed input stream】上使用Strict contiguity
- skip till next match(宽松连续):进一步宽松,完全删除连续性要求: 所有不相关的事件将被跳过,直到读取下一个相关事件
- 按顺序选择所有符合条件的事件,而途中不符合条件的事件被忽略,
- 对应FlinkCEP API中的Pattern.followedBy()/notFollowedBy()。上述SASE+语言描述的pattern使用的就是这个策略;
- skip till any match(可变宽松连续):Finally, skip till any match relaxes the previous one by further allowing non-deterministic actions on relevant events
- 在skip till next match的基础上,还允许忽略一些符合条件的事件,以尽量延长匹配序列的长度,
- 对应FlinkCEP API中的Pattern.followedByAny()。
以skip till next match策略为例,给出如下的示例数据,可以产生3个匹配序列R1、R2、R3,如图所示。
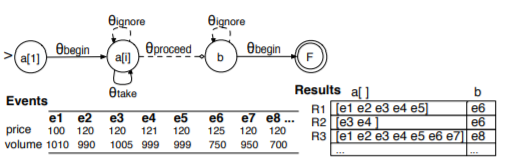
2.3. 共享版本匹配缓存
仍然考虑上一节的图,回顾一下a[i]状态的take和proceed转移逻辑:
θ*a[i]_take = θa[i]_take ∧ a[i].time<a[1].time+1 hour
θ*a[i]_proceed = θb_begin ∨ (¬θ*a[i]_take ∧ ¬θ*a[i]_ignore)
可见,在e6到达NFA时,可以同时满足a[i]_take和a[i]_proceed的转移(这里正好体现出了NFA的不确定性),所以原本的一个序列会在此分裂成两个:其中一个(R1)终止匹配,另一个(R3)继续匹配。同理,当e3到达NFA时,同时满足a[1]_begin和a[i]_take的转移,所以又会出现一个序列R2。
由上可知,这些序列之间的重合是比较大的,如果都按原样存储在匹配缓存中,会造成比较大的膨胀。为了避免这个问题,论文中设计了一种科学的缓存结构,称为shared versioned match buffer,即“共享版本匹配缓存”,如下图所示:

其中图a、b、c是原始的R1、R2、R3缓存,图d则是整合在一起的共享版本缓存。
它会将所有序列的前向指针附加上一个版本号(采用杜威十进制法,点号分隔),并且遵循以下两个规则:
- 迁移到下一个状态时,版本号增加一位,如a[1]状态的版本号是1(为了符合习惯写作1.0),a[i]状态的版本号是1.0、1.1,b状态的版本号是1.0.0、1.1.0……以此类推;
- 当序列发生分裂时,处于当前状态的版本号位加1。例如e3事件产生了2.0版本,e6事件产生了1.1版本。
依照这种规则,就可以根据前向指针上版本号的递增规律和前缀来回溯出正确的序列了。
FlinkCEP中将此缓存设计为SharedBuffer类,但是版本的设计有些不同。
2.4. 计算状态
对于每一个序列,NFAbAutomaton还需要维护一些最基础的状态数据,以方便执行状态转移和匹配逻辑,论文中将其称为computation state,即计算状态。
基础的计算状态结构如下图所示,包含以下数据项:
- 当前的版本号;
- 当前的状态;
- 指向匹配缓存中最近一个事件的指针;
- 整个序列的起始时间;
- 其他必要的上下文数据存储。以股票趋势数据为例,会维护Kleene +闭包内的事件数、价格之和以及交易量等。
运行计算状态【Computation state of runs】如下:

Flink CEP框架用ComputationState类来维护计算状态,大体思路与论文相同。
相关文章
- PHP程序执行的过程原理
- Spring依赖注入原理分析
- MySQL+InnoDB semi-consitent read原理及实现分析(转)
- systemd的原理和适用方法
- CICD详解(二)——Jenkins持续集成原理
- minio安装及特性原理介绍
- 红黑树之 原理和算法详细介绍(阿里面试-treemap使用了红黑树) 红黑树的时间复杂度是O(lgn) 高度<=2log(n+1)1、X节点左旋-将X右边的子节点变成 父节点 2、X节点右旋-将X左边的子节点变成父节点
- SAP Fiori Elements 框架里 Smart Table 控件的工作原理介绍
- ABAP development tools实现原理介绍
- rxjs Observable filter Operator 的实现原理介绍
- SAP CRM business partner determination原理介绍
- CGroup 介绍、应用实例及原理描述
- Atitit 异常机制与异常处理的原理与概论
- SAP Fiori Elements里Smart Link工作原理介绍
- 日志库 winston 的学习笔记 - logger.info 的实现原理单步调试
- Angular 依赖注入机制实现原理的深入介绍
- 云小课|MRS基础原理之Hudi介绍
- 云小课|MRS基础原理之Flink组件介绍
- 【nodejs原理&源码赏析(3)】欣赏手术级的原型链加工艺术
- Android AutoCompleteTextView悬浮提示列表原理简单分析
- 【人工智能 Open AI】写一篇介绍 聊天GPT 背后的实现原理的论文,题目叫《聊天GPT算法实现原理》,分5个章节,每个章节细化到三级目录,用不少于2000字。用markdown格式输出。
- 粗略介绍Java AQS的实现原理
- c++多态和虚函数表实现原理
- 020-docker镜像UnionFS、Docker镜像加载原理、分层的镜像与容器、结合docker命令理解镜像
- 相似图片搜索的原理(转)
- 闪存系统性能优化方向?NAND Interleave Program(闪存交错写) 并发原理与实战?