
PgSQL · 应用案例 · "写入、共享、存储、计算" 最佳实践
数据是为业务服务的,业务方为了更加透彻的掌握业务本身或者使用该业务的群体,往往会收集,或者让应用埋点,收集更多的日志。
随着用户量、用户活跃度的增长,时间的积累等,数据产生的速度越来越快,数据堆积的量越来越大,数据的维度越来越多,数据类型越来越多,数据孤岛也越来越多。
日积月累,给企业IT带来诸多负担,IT成本不断增加,收益确不见得有多高。
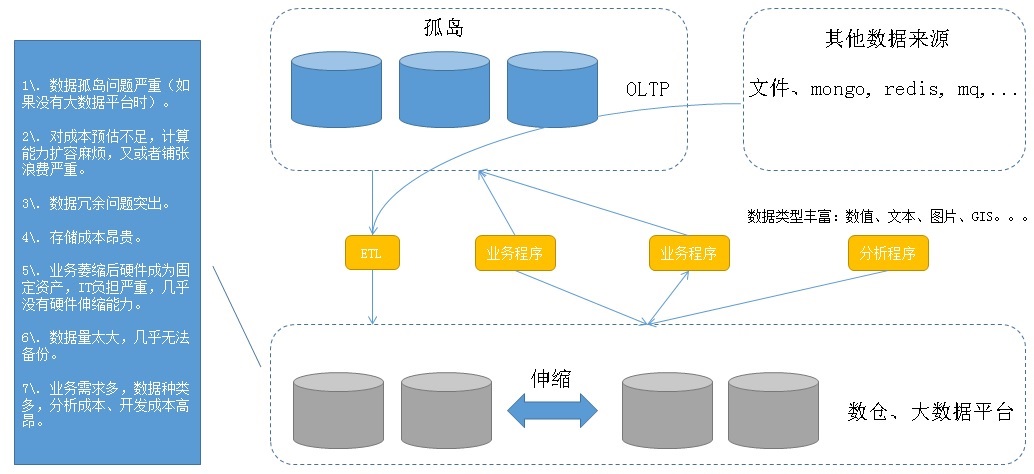
上图描绘了企业中可能存在的问题:
1. 数据孤岛问题严重(如果没有大数据平台时)。
2. 对成本预估不足,计算能力扩容麻烦,又或者铺张浪费严重。
3. 数据冗余问题突出。
4. 存储成本昂贵。
5. 业务萎缩后硬件成为固定资产,IT负担严重,几乎没有硬件伸缩能力。
6. 数据量太大,几乎无法备份。
7. 业务需求多,数据种类多,分析成本、开发成本高昂。
本文将针对这个场景,给出一个比较合理的方案,灵活使用,可以减轻企业IT成本,陪伴企业高速成长。
### 1. 物流
一个包裹,从揽件、发货、运输、中转、配送到签收整个流程中会产生非常多的跟踪数据,每到一个节点,都会扫描一次记录包裹的状态信息。
运输过程中,车辆与包裹关联,车辆本身采集的轨迹、油耗、车辆状态、司机状态等信息。
配送过程,快递员的位置信息、包裹的配送信息都会被跟踪,也会产生大量的记录。
一个包裹在后台可能会产生上百条跟踪记录。
运输的车辆,一天可能产生上万的轨迹记录。
配送小哥,一天也可能产生上万条轨迹记录。
我曾经分享过一个物流配送动态规划的话题。有兴趣的童鞋也可以参考
物流行业产生的行为数据量已经达到了海量级别。
怎样才能有效的对这些数据进行处理呢?
比如:
实时按位置获取附近的快递员。
实时统计包裹的流量,快递员的调度,车辆的调度,仓库的选址等等一系列的需求。
2. 金融金融行业也是数据的生产大户,用户的交易,企业的交易,证券数据等等。
数据量大,要求实时计算,要求有比较丰富的统计学分析函数等。
我曾经分享过一个关于模拟证券交易的系统需求分析。有兴趣的童鞋也可以参考
3. 物联网物联网产生的数据有时序属性,有流计算需求(例如到达阈值触发),有事后分析需求。
数据量庞大,有数据压缩需求。
我刚好也写过一些物联网应用的数据库特性分析,这些特性可以帮助物联网实现数据的压缩、流计算等需求。
《流计算风云再起 - PostgreSQL携PipelineDB力挺IoT》
《旋转门数据压缩算法在PostgreSQL中的实现 - 流式压缩在物联网、监控、传感器等场景的应用》
《PostgreSQL 物联网黑科技 - 瘦身几百倍的索引(BRIN index)》
《一个简单算法可以帮助物联网,金融 用户 节约98%的数据存储成本》
《”物联网”流式处理应用 - 用PostgreSQL实时处理(万亿每天)》
《PostgreSQL 黑科技 range 类型及 gist index 助力物联网(IoT)》
物联网还有一个特性,传感器上报的数据往往包括数字范围(例如温度范围)、地理位置、图片等信息,如何高效的存储,查询这些类型的数据呢?
4. 监控监控行业,例如对业务状态的监控,对服务器状态的监控,对网络、存储等硬件状态的监控等。
监控行业具有比较强的业务背景,不同的垂直行业,对监控的需求也不一样,处理的数据类型也不一样。
例如某些行业可能需要对位置进行监控,如公车的轨迹,出了位置电子围栏,发出告警。换了司机驾驶,发出警告。等等。

公安的数据来自多个领域,例如 通讯记录、出行记录、消费记录、摄像头拍摄、社交、购物记录 等等。
公安的数据量更加庞大,一个比较典型的场景是风险控制、抓捕嫌犯。涉及基于地理位置、时间维度的人物关系分析(图式搜索)。
如何才能满足这样的需求呢?
6. 其他行业其他不再列举。
如何解决数据孤岛,打通数据共享渠道?
如何高效率的写入日志、行为轨迹、金融数据、轨迹数据等?
如何高效的实时处理数据,根据阈值告警通知,实时分析等?
如何解决大数据的容灾、备份问题?
如何解决大数据的压缩和效率问题?
如何解决数据多维度、类型多,计算复杂的问题?
如何解决企业IT架构弹性伸缩的问题?
总结起来几个关键字:
写入、共享、存储、计算。
用到三个组件:
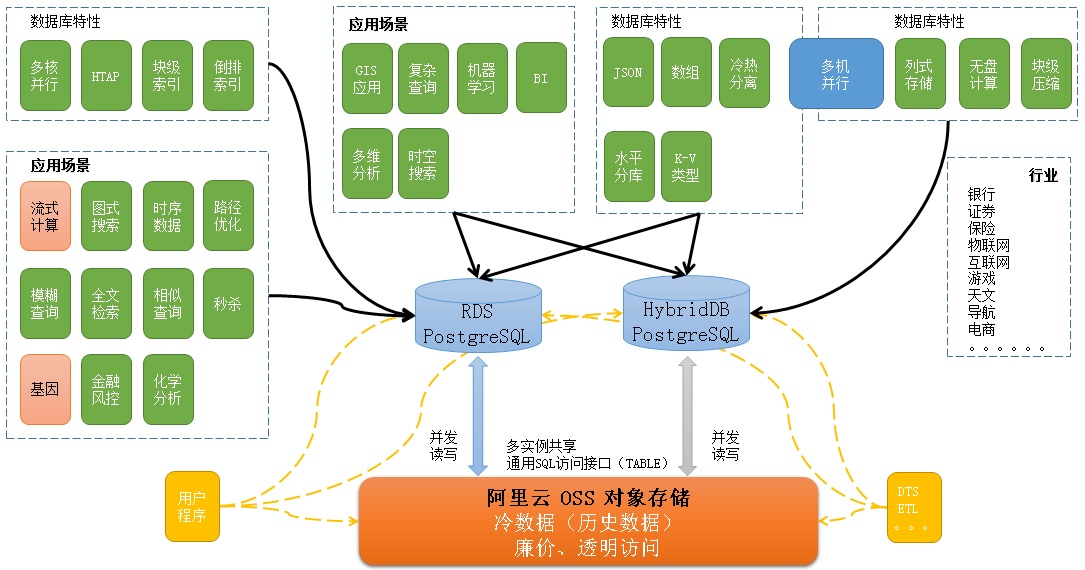
支持时序数据、块级索引、倒排索引、多核并行、JSON、数组存储、OSS_FDW外部读写等特性。
解决OLTP,GIS应用、复杂查询、时空数据处理、多维分析、冷热数据分离的问题。
2. HybridDB PostgreSQL支持列存储、水平扩展、块级压缩、丰富的数据类型、机器学习库、PLPYTHON、PLJAVA、PLR编程、OSS_FDW外部读写等特性。
解决海量数据的计算问题。
3. OSS 对象存储多个RDS实例之间,可以通过OSS_FDW共享数据。
OSS多副本、跨域复制。
解决数据孤岛、海量数据存储、跨机房容灾、海量数据备份等问题。
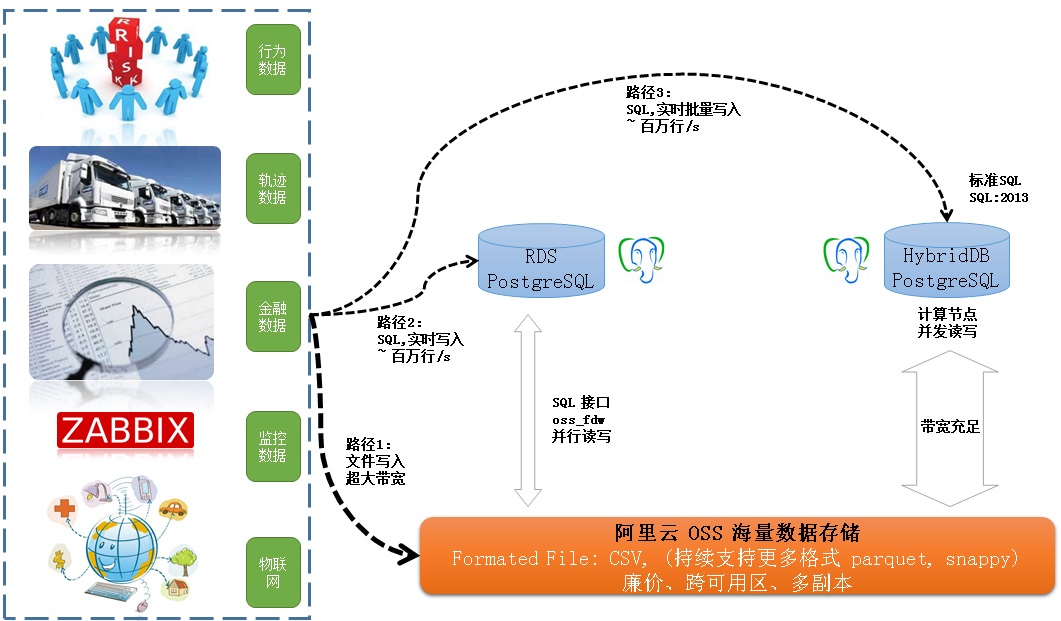
数据写入分为3条路径:
1. 在线实时写入,可以走RDS SQL接口,单个实例能达到 百万行/s 以上的写入速度。
2. 批量准实时写入,可以走HybridDB SQL接口,单个实例能达到 百万行/s 以上的写入速度。
3. 批量准实时写入,比如写文件,可以走OSS写入接口,带宽弹性伸缩。
多个RDS实例之间,可以通过OSS_FDW共享数据。
例如A业务和B业务,使用了两个RDS数据库实例,但是它们有部分需求需要共享数据,传统的方法需要用到ETL,而现在,使用OSS_FDW就可以实现多实例的数据共享,而且效率非常高。
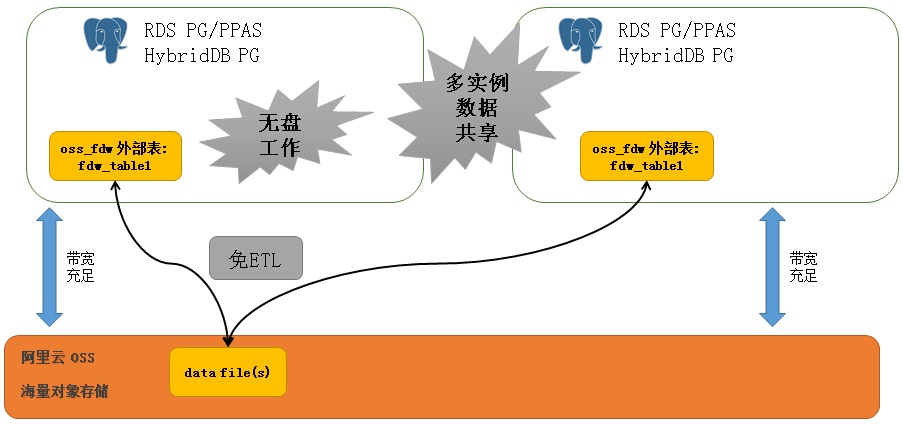
通过RDS PostgreSQL OSS_FDW的并行读写功能(同一张表的文件,可以开多个worker process进程并行读写),共享数据的读写效率非常高。
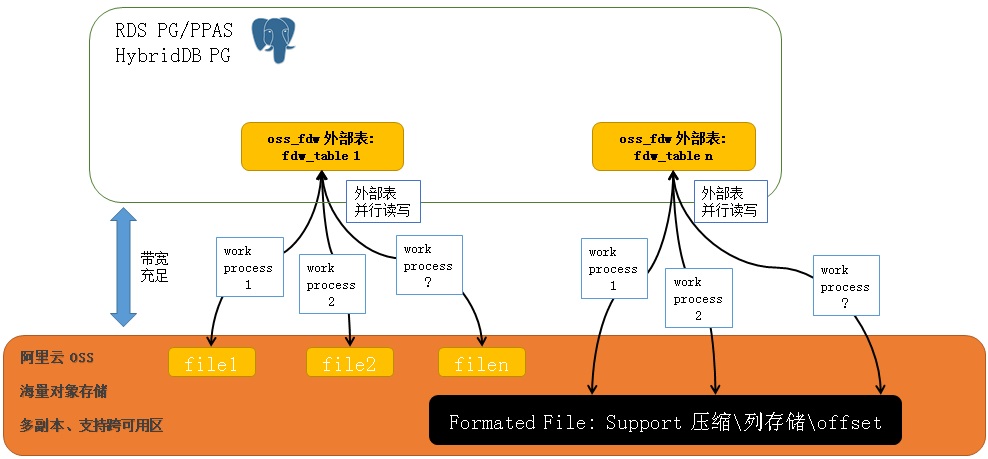
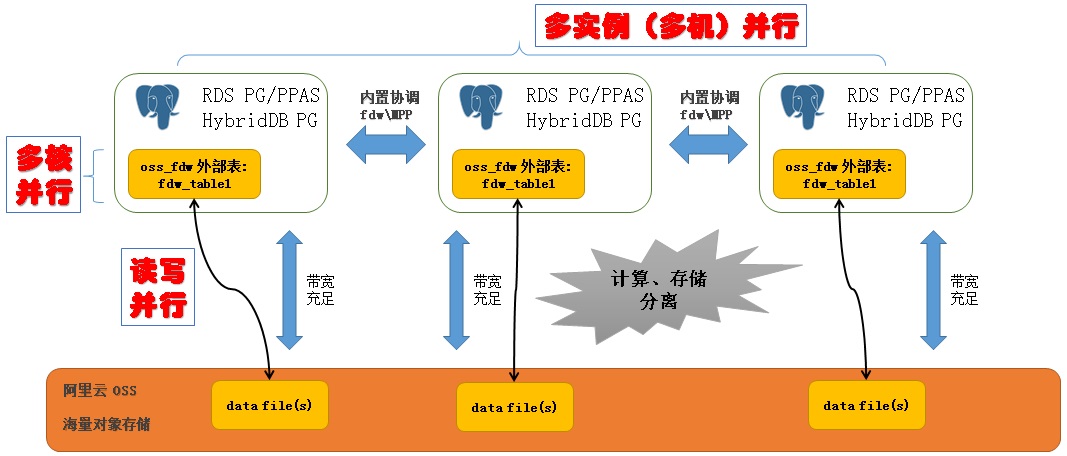
并行体现三个方面:OSS读写并行、RDS PostgreSQL多核计算并行、RDS PG或HybridDB的多机并行。
对于实时数据,使用RDS PostgreSQL, HybridDB的本地数据存储。对于需要分析、需要共享的数据,使用OSS进行存储。
OSS相比计算资源的存储更加的廉价,在确保灵活性的同时,降低了企业的IT成本。
通过OSS对象存储,解决了企业的数据冗余、成本高等问题,满足了数据的备份、容灾等需求。
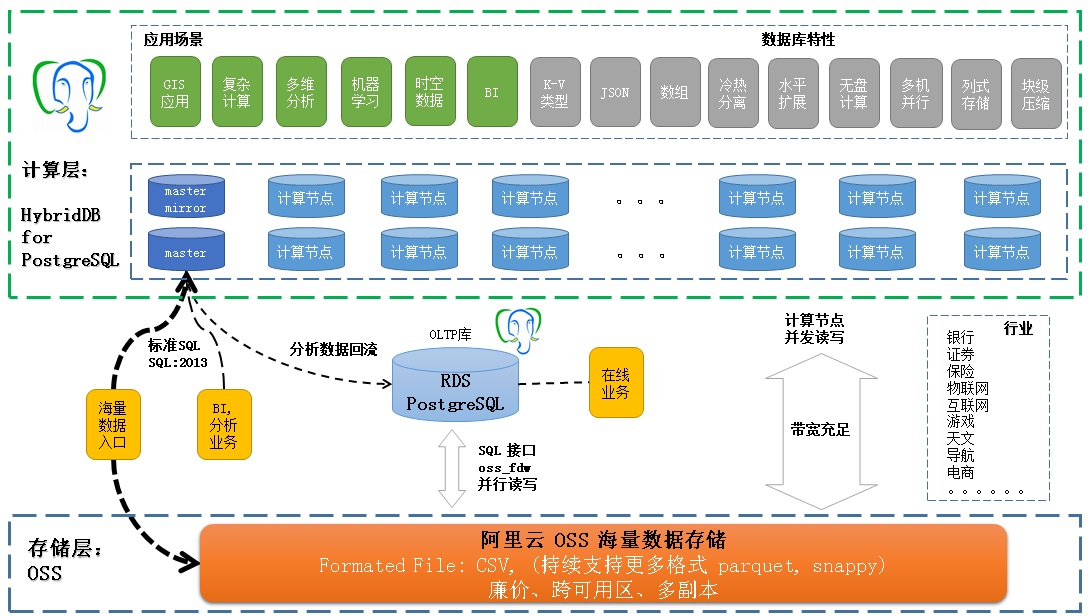
通过RDS PostgreSQL, HybridDB, OSS的三个基本组件,实现了计算资源、存储资源的分离。
因为计算节点的数据量少了(大部分数据都存在OSS了),计算节点的扩容、缩容、容灾、备份都更加方便。
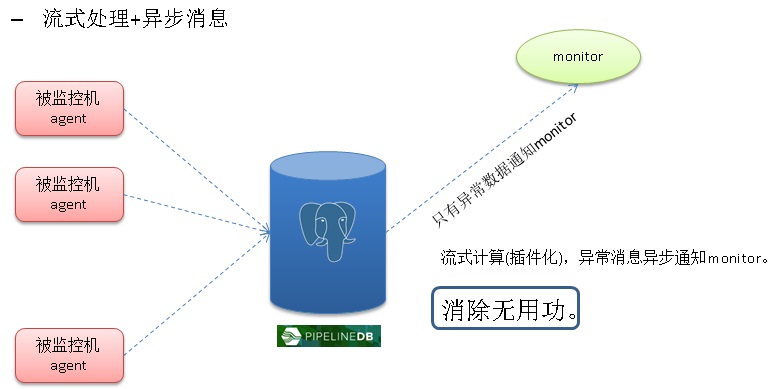
计算本身分为以下几种1. 流式计算
流式计算分为两种,一种是实时统计,另一种是设置阈值进行实时的告警。
通过pipelinedb(base on postgresql)可以实现这两类流计算。
好处:
SQL标准接口,丰富的内置函数支持复杂的流计算需求,丰富的数据类型(包括GIS,JSON等)支持更多的流计算业务场景,异步消息通知机制支持第二类流计算需求。
pipelinedb正在进行插件化改造,以后可以作为PostgreSQL的插件使用。
https://github.com/pipelinedb/pipelinedb/issues?q=is%3Aissue+is%3Aopen+label%3A%22extension+refactor%22
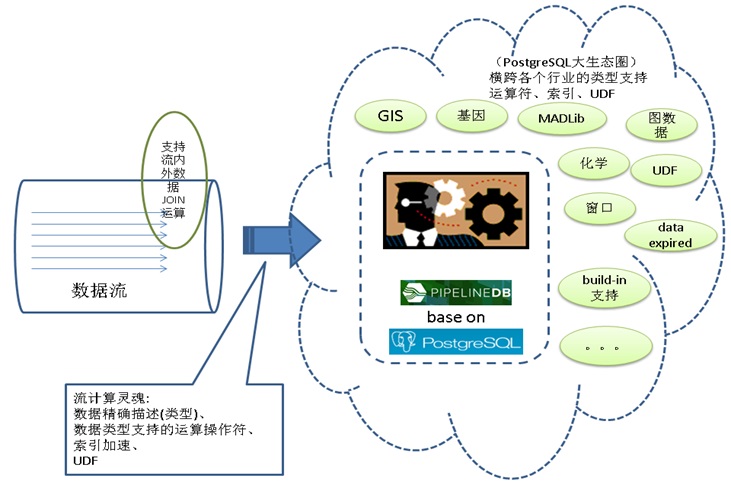
例如在监控领域,使用流计算的异步消息机制,可以避免传统主动问询监控的无用功问题。
2. 实时交互业务
传统的OLTP需求,使用RDS PostgreSQL可以满足。
PostgreSQL的特性包括:GIS、JSON、数组、冷热分离、水平分库、K-V类型、多核并行、块级索引、倒排索引等。
PostgreSQL支持的场景包括:流计算、图式搜索、时序数据、路径规划、模糊查询、全文检索、相似查询、秒杀、基因、金融、化学、GIS应用、复杂查询、BI、多维分析、时空数据搜索等。
覆盖银行、保险、证券、物联网、互联网、游戏、天文、出行、电商、传统企业等行业。
3. 准实时分析
结合OSS对象存储,RDS PostgreSQL和HybridDB都可以实现准实时的分析。
同一份OSS的数据,也可以在多个实例之间进行共享,同时访问。
4. 离线分析、挖掘
结合OSS对象存储,RDS PostgreSQL和HybridDB都可以实现对离线数据的分析和挖掘。
RDS PostgreSQL 支持单机多核并行,HybridDB for PostgreSQL支持多机并行。用户可以根据计算量进行选择。
计算需要具备的能力计算的灵魂是类型的支持、以及类型的处理。
1. PostgreSQL内置了丰富的类型支持,包括(数字、字符串、时间、布尔、枚举、数组、范围、GIS、全文检索、bytea、大对象、几何、比特、XML、UUID、JSON、复合类型等),同时支持用户自定义的类型。可以支持几乎所有的业务场景
2. 操作符,为了满足对数据的处理需求,PG对每一种支持的类型,都支持非常丰富的操作,
3. 内置函数,PG内置了丰富的统计学函数、三角函数、GIS处理函数,MADlib机器学习函数等。
4. 自定义计算逻辑,用户可以通过C, python, java, R等语言,定义数据的处理函数。扩展PostgreSQL, HybridDB for PostgreSQL的数据处理能力。
5. 聚合函数,内置了丰富的聚合函数,支持数据的统计。
6. 窗口查询功能的支持。
7. 递归查询的支持。
8. 多维分析语法的支持。
1 RDS PostgreSQL 优势主要体现在这几个方面
1. 性能
RDS PostgreSQL主要处理在线事务以及少量的准实时分析。
PG OLTP的性能可以参考这篇文档,性能区间属于商业数据库水准。
PG 的OLAP分析能力,可以参考这篇文档,其多核并行,JIT,算子复用等特性,使得PG的OLAP能力相比其他RDBMS数据库有质的提升。
《分析加速引擎黑科技 - LLVM、列存、多核并行、算子复用 大联姻 - 一起来开启PostgreSQL的百宝箱》
PostgreSQL 10 在HTAP(OLTP与OLAP混合应用场景)方面还有更多的增强,预计社区5月份会发布BETA版本。
2. 功能
功能也是PostgreSQL的强项,在上一章《计算需要具备的能力》有详细介绍。
3. 扩展能力
计算能力扩展,RDS PostgreSQL的主要场景是OLTP在线事务,通过增加CPU,可以同时扩展OLTP的能力,以及扩展复杂计算的性能。
存储能力扩展,通过OSS存储以及oss_fdw插件,可以扩展RDS PG的存储能力,打破存储极限。
4. 成本
存储成本:由于大部分需要分离的数据都存储到OSS了,用户不再需要考虑这部分的容灾、备份问题。相比存储在数据库中,存储成本大幅降低。
开发成本:RDS PG, HybridDB PG都支持丰富的SQL标准接口,访问OSS中的数据(通过TABLE接口),使用的也是SQL标准接口。节省了大量的开发成本,
维护成本:使用云服务,运维成本几乎为0。
5. 覆盖行业
覆盖了银行、保险、证券、物联网、互联网、游戏、天文、出行、电商、传统企业等行业。
2 HybridDB PostgreSQL 优势1. 性能
HybridDB PostgreSQL为MPP架构,计算能力出众。
2. 功能
在上一章《计算需要具备的能力》有详细介绍。
3. 扩展能力
计算能力扩展,通过增加计算节点数,可以扩展复杂计算的性能。
存储能力扩展,通过OSS存储以及oss_fdw插件,可以扩展RDS PG的存储能力,打破存储极限。
4. 成本
存储成本:由于大部分需要分离的数据都存储到OSS了,用户不再需要考虑这部分的容灾、备份问题。相比存储在数据库中,存储成本大幅降低。
开发成本:RDS PG, HybridDB PG都支持丰富的SQL标准接口,访问OSS中的数据(通过TABLE接口),使用的也是SQL标准接口。节省了大量的开发成本,
维护成本:使用云服务,运维成本几乎为0。
5. 覆盖行业
覆盖了银行、保险、证券、物联网、互联网、游戏、天文、出行、电商、传统企业等行业。
《RDS PostgreSQL : 使用 oss_fdw 读写OSS对象存储》
《HybridDB PostgreSQL : 使用 oss_fdw 读写OSS对象存储》
MySQL · 内核特性 · 统计信息的现状和发展 简介我们知道查询优化问题其实是一个搜索问题。基于代价的优化器 ( CBO ) 由三个模块构成:计划空间、搜索算法和代价估计 [1] ,分别负责“看到”最优执行计划和“看准”最优执行计划。如果不能“看准”最优执行计划,那么优化器基本上就是瞎忙活,甚至会产生严重的影响,出现运算量特别大的 SQL ,造成在线业务的抖动甚至崩溃。在上图中,代价估计用一个多项式表示,其系数 c 反应了硬件环境和算子特性,而
MongoDB·最佳实践·count不准原因分析 一般来说,除了由于secondary延迟可能造成查询secondary节点数据不准以外,关于count的准确性问题,在MongoDB4.0官方文档中有这么一段话On a sharded cluster, db.
【PG云栖周刊】第2期·PostGIS北京3月活动,存储扩展引擎zheap,Oracle兼容性之 - 数据类型 3月17-18 PG象行中国2018-地理信息处理GIS专题(北京站),活动地点:北京师范大学 艺术楼 201教室;PostgreSQL最新存储扩展引擎zheap,计划加入到PG12;PostgreSQL 10.3更新版本发布;云数据库PPAS Oracle兼容性 - 数据类型;PostgreSQL中HOOK的使用,避免误删库的问题。
MSSQL · 最佳实践 · 数据库备份链 在SQL Server备份专题分享中,前两期我们分享了三种常见的备份以及备份策略的制定,在第三期分享中,我们将要分享SQL Server的数据库备份链。完整的数据库备份链是保证数据库能够实现灾难恢复的基础,如果备份链条被打断或者备份链条上的文件损坏,势必会导致数据恢复不完整或者不能满足预期,而造成数据丢失,危害数据完整性生命线,后果非常严重。
MSSQL · 应用案例 · 日志表设计优化与实现 这篇文章从日志表问题引入、日志表的共有特性、日志表的设计需求、设计思路以及设计详细实现的角度,阐述了在SQL Server数据库中如何最优化设计日志表来降低系统资源的占用和提高系统吞吐量。问题引入 在平时与客户服务与交流过程中,我们不止一次的被客人问及这样的场景:我们现在面临如何设计SQL Server日志表方案,如何最优化设计数据库日志记录表。
HybridDB · 最佳实践 · HybridDB 数据合并的方法与原理 刚开始使用HybridDB的用户,有个问的比较多的问题:如何快速做数据“合并”(Merge)?所谓“合并”,就是把数据新版本更新到HybridDB中。如果数据已经存在,则将它们替换为新版本;如果不存在,将它们插入数据库中。一般是离线的做这种数据合并,例如每天一次批量把数据更新到HybridDB中。也有客户需要实时的更新,即做到分钟级甚至秒级延迟。这里我们介绍一下HybridDB中数据合并的
PgSQL · 应用案例 · 逻辑订阅给业务架构带来了什么? 逻辑订阅是PostgreSQL 10.0的新特性。 具体的原理,使用方法可以参考如下文章。 《PostgreSQL 10.0 preview 逻辑订阅 - 原理与最佳实践》 《PostgreSQL 10.0 preview 逻辑订阅 - pg_hba.conf变化,不再使用replication条目》 《PostgreSQL 10.0 preview 逻辑订阅 - 备库支持逻辑订阅,
db匠 rds内核团队秘密研发的全自动卖萌机. 追加特效: 发数据库内核月报. 月报传送: http://mysql.taobao.org/monthly/
相关文章
- Airtest自动化测试实操案例 | Windows应用篇
- 干货|分享一个EMC实际案例及整改过程
- SQL案例分析-应用系统用户权限设计.sql
- 【MATLAB教程案例13】基于SA模拟退火优化算法的函数极值计算matlab仿真及其他应用
- 【FPGA教程案例92】图像处理1——基于FPGA的图像形态学膨胀处理实现,使用MATLAB辅助测试
- 【FPGA教程案例66】硬件开发板调试6——基于FPGA的UDP网口通信和数据传输
- Flink教程(04)- Flink入门案例
- 网络安全产品之堡垒机介绍以及应用案例
- MSSQL-应用案例-SQL Server 2016基于内存优化表的列存储索引分析Web Access Log
- 教程 | 一个基于TensorFlow的简单故事生成案例:带你了解LSTM
- python 面向对象编程案例01
- 【快应用】任意拖动图标实现案例
- 【快应用】折叠屏展开与折叠判断案例
- 【AppLinking实战案例】通过AppLinking分享应用内图片
- 官方总结鸿蒙应用开发常见问题与实现方法典型案例
- 《Android 应用案例开发大全(第二版)》——导读
- 《Android 应用案例开发大全(第二版)》——6.9节解析数据
- 《Android 应用案例开发大全(第3版)》——第1章,第1.2节掀起Android的盖头来
- 《Android 应用案例开发大全(第3版)》——第2.3节壁纸的基本框架
- 《Android 应用案例开发大全(第3版)》——第2.9节壁纸的优化与改进
- 《区块链开发指南》一一1.5 合约应用案例
- 【Unity3D应用案例系列】计算器工具开发
- 【快应用】如何配置快应用图标,及几种常见的无效配置案例
- 数据库应用系统开发案例 │ 图书现场采购系统
- Vue使用第三方库实现动画效果:animate.css使用方法和教程案例
- 超融合基础设施主流应用案例