
编码
2023-09-11 14:16:16 时间
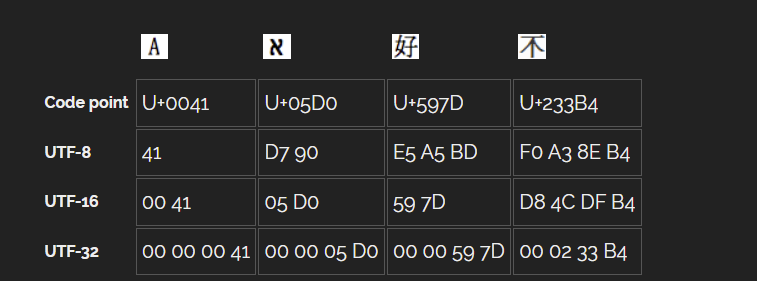
原先Windows上的Unicode指的是UTF-16LE且带有BOM,后来Unicode有了SIP、TIP平面,现在有U+2CC56这样的编码超出了原先Unicode只在BMP平面表示的范围,但UTF-32能使用四个字节完整表示一个字符如0002CC56,UTF-16则需要用两个字符D873 DC56来表示上述的编码U+2CC56。
如果是为了跨平台兼容性,只需要知道,在 Windows 记事本的语境中:
- 所谓的「ANSI」指的是对应当前系统 locale 的遗留(legacy)编码,中文系统下一般指GBK和GB18030
- 所谓的「Unicode」指的是带有 BOM 的小端序 UTF-16。
- 所谓的「UTF-8」指的是带 BOM 的 UTF-8。MacOS不带BOM。
UTF-16 能够清晰的表示使用两个字节的常用汉字,例如4DAE,但使用四个字节的汉字需要使用两个UTF-16字符表示,如D873 DC56。
UTF-8 本来是兼容性最好的编码,但 Windows 偏要加 BOM 于是在其他系统打开显示时经常出问题。
图片上的Windows系统的编码方式名称应该是纠正过来的正确名称。不能保存应该是没有输入文件名。
早期,把UTF-16称为Unicode,是因为那时UTF-16的2个字节四位16进制编码几乎能和Unicode的编码清晰对应。啊的Unicode是554A,它的UTF-16大端序编码也是554A,几乎是相同的。但后来有了SIP平面和TIP平面就不相同了,例如Unicode的编码30EDE,其大端序的UTF-16编码则是D883 DEDE,就产生了区别。
https://www.w3.org/International/articles/definitions-characters/
相关文章
- 【Vue】通过text按键执行事件,并且获取到按键的名称和编码
- Python2.x 里解决中文编码的万能钥匙
- 深入浅出计算机编码、乱码问题
- 用C语言实现LDPC的快速编码
- MPEG-2压缩编码的视频基本流
- c 语言默认什么编码
- 中文字符集编码Unicode ,gb2312 , cp936 ,GBK,GB18030
- 《C语言编程魔法书:基于C11标准》——2.5 字符编码
- netty系列之:netty中常用的字符串编码解码器
- java安全编码指南之:输入注入injection
- Java之utf8中文编码转换
- Python学习---JSON补充内容[中文编码 + dumps解析]
- mysql 5.0 参数优化,配置utf-8编码