
《MySQL DBA修炼之道》——3.2 数据模型
本节书摘来自华章出版社《MySQL DBA修炼之道》一书中的第3章,第3.2节,作者:陈晓勇,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
3.2 数据模型3.2.1 关系数据模型介绍
目前数据库领域使用最广泛的就是关系数据模型,业内主流的数据库产品都是建立在关系数据模型之上的,如Oracle、MS SQLServer、MySQL、PostgreSQL、DB2。关系型数据库系统的技术发展了几十年,已经相当成熟,在数据库中也得到了高效的实现。关系型数据库管理系统的标准语言——结构化查询语言(SQL),是一种高级的非过程化编程语言,它已经成为事实上的工业标准而被广泛使用,而且也变成了一项必须被程序员掌握的标准技能。
下面仍然以3.1节的两个表为例(见表3-4和表3-5),说明一些概念。
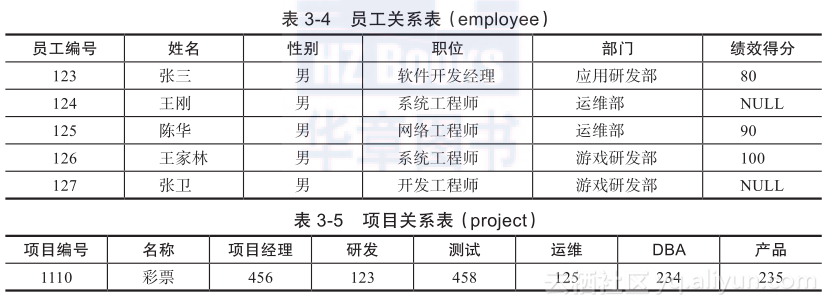
从表3-4和表3-5可以看出,关系数据模型是由一系列的“关系”组成的。“关系”也就是我们所说的表(table)。每个表也存在一个或多个属性(字段),如“员工编号”、“姓名”、“性别”。每个字段均有对应的数据类型(type),如“整型”、“字符型”、“枚举类型”。关系模型建立后,就可以在这些关系(表)中插入、修改、删除、查询数据了。
1.关于NULL
如果某个字段的值是未知的或未定义的,数据库会提供一个特殊的值NULL来表示。NULL值很特殊,在关系数据库中应该小心处理。例如对表employee,运行查询语句“select * from employee where绩效得分 =85 or 绩效得分 85;”可能很多人认为这样能获取所有记录,但实际上,由于王刚和张卫的绩效得分是未知的(NULL),因此他们不会被包含在查询结果中。
2.关于key和索引
key常指表中能唯一标识一笔记录的字段(属性)或多个字段的组合。现实中,key和索引可以简单地看作同义词,key不一定唯一标识一笔记录,本书以后的论述中会使用“索引”、“主键索引”、“唯一索引”这些术语。我们可以通过某个记录的索引/key去查找记录。数据库管理系统为了高效地检索记录,往往会创建各种索引结构加速检索记录,或者按照索引/key的顺序存储记录,所以基于记录的索引/key会很容易查找到记录。关系数据库中的表之间的关联往往也是通过索引来进行关联的,比如上面的project表,项目组成员存储的是员工编号,可以通过员工编号和另外一张员工关系表——employee表(员工编号字段上有主键索引)进行关联。
3.2.2 实体–关系建模
由于设计人员、研发人员和最终用户看待和使用数据的方式不同,因此可能会导致数据库的设计不能反映真实的需求,以及后期出现的扩展性问题,为了能够更准确理地解数据的本质,理解使用这些数据的方法,我们需要有一个通用的模型,这个模型和技术实现无关。实体关系图(ER模型)就是这样一个通用模型的例子。以下介绍ER建模的一些关键概念。
(1)ER建模
1976年Peter Chen首次提出了Entity Relationship Modeling(实体关系建模)概念,并发明了陈氏表示法(Peter Chen’s notation)。随着问题复杂度的增加,适应范围的增广,截至今天出现了许多ER模型的表示法,如Barker ER Information Engineering(IE)和 IDEF1X或 Crow’s foot 表示法。各种表示法都有它们的优缺点和适用领域,但它们都基于同样的建模概念。
ER建模是一种自上而下的数据库设计方法。我们通过标识模型中必须要表示的重要数据(称为实体)及数据之间的关系开始ER建模,然后增加细节信息,如实体和关系所要具有的信息(称为属性)。该方法的输出是实体类型、关系类型和约束条件的清单。
(2)UML
UML(Unified Modeling Language,统一建模语言)是一种分析人员和开发人员广泛使用的标准建模语言,它可以以图形化的方式表示实体、关系。UML最初用于软件设计,目前已经扩展到业务和数据库设计。UML包括分析、实施、部署过程中指定任何事项所必需的元素和图表。通过使用几种图表和数十种元素,UML能表达不同程度的系统抽象。对于ER建模,我们只需要了解常用于ER建模的一些视图和表示即可。
(3)实体
实体代表现实世界的一组对象集合,可以粗略地认为它是名词,如学生、雇员、订单、演员、电影。实体一般用矩形来表示。
(4)关系
关系指特定实体之间的关系。可以粗略地认为是动词,如公司拥有员工、演员演电影。关系用线来表示。一般为二元关系。
关系的基数指参与关系的实体数目。二元关系的基数就是我们所说的一对一、一对多、多对多。在数据库设计中,需要选择合适的基数表示法,如IDEF1X表示法、关系表示法或Crow’s foot表示法。本书中的例子一般使用Crow’s foot表示法,下面简要介绍下Crow’s foot表示法。
对于Crow’s foot表示法,实体表示为矩形框,关系表示为矩形框之间的线,线两端的形状表示关系的基数。空心圆表示零或多,单阴影线标记表示一或多,单阴影线标记和空心圆表示零或一,双阴影线标记表示恰好为一。
许多建模工具都可以使用Crows’ foot表示法,如ARIS、System Architect、Visio、PowerDesigner、MySQL Workbench等。
属性指实体或关系的特征,如实体雇员的姓名、地址、生日、身份证ID等。如果要一起显示实体和属性,那么就把代表实体的矩形分为两部分,上半部分显示实体名,下半部分列出属性名。
在图3-1中,Artist(艺术家)实体和Song(歌曲)实体的关系是艺术家演唱歌曲。
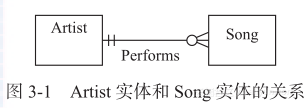
这两个实体使用的是Crow’s foot表示法,靠近Song实体一端的符号表示“0、1或更多”,靠近Artist一端的符号表示“1且只有1个”,所以图3-1表示一个艺术家可以演唱0首、1首或者多首歌曲。
关于ER建模更详细的信息,请阅读其他相关书籍。
3.2.3 其他数据模型
1. XML数据模型
对于结构化数据,除了关系模型,还可以使用XML数据模型存取数据。XML(eXtensible Markup Language)是可扩展标记语言,最开始设计XML的目的是为了在Internet上交换数据。标记是指计算机所能理解的信息符号,通过此种标记,计算机之间可以处理包含各种信息的文章等。如何定义这些标记?既可以选择国际通用的标记语言,比如HTML,也可以使用像XML这样由相关人士自由决定的标记语言,这就是语言的可扩展性。
XML被广泛用作跨平台之间数据交互的形式,主要针对数据的内容,通过不同的格式化描述手段(XSL、CSS等)来完成最终的形式展现(生成对应的HTML、PDF或其他的文件格式)。
常用的查询语言是XPath,即XML路径语言(XML path language),它是一种用来确定XML文档中某部分的位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。
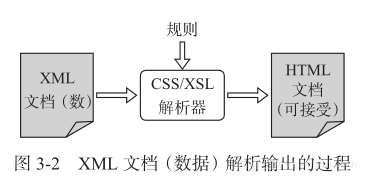
在图3-2中,一个形式良好的XML文档或XML字符串,经过CSS或XSL解析器的解析,最终生成客户端可接受的展现形式。
以下是一个XML的例子。
?xml version="1.0" ? person sex="female" firstname Anna /firstname lastname Smith /lastname /person
可以看到XML的格式和HTML文件比较类似,但两者也有不同之处。XML被设计为传输和存储数据,其标签描述的是数据的内容。HTML被设计用来显示数据,其标签是用来格式化数据的。
由于XML文件的标签描述的是数据的内容,因此XML文件可以看作“自描述”的文件。
一个形式良好的XML主要包含如下三个基本部分。
元素,如上面的person。元素允许嵌套,如person包含子元素firstname、lastname。元素有开始标签和关闭标签,如上面的 person /person 。
;属性,元素还可以拥有属性,如上面例子中的sex=“female”。
文本,如上面例子中的Anna、Smith。
XML作为一项数据交换的标准被广泛使用,因此某种意义上,XML也是关系数据模型的竞争者。表3-6对关系数据模型和XML数据模型做了简要对比。
在下面的XML文档中,第一本书没有输入price(价格)信息,而后面的两本书添加了price信息,这种数据结构的不一致性在XML中是允许存在的,这就意味着,可以在以后给元素添加或删除子元素,因此大大增加了灵活性。
bookstore book category="COOKING" title lang="en" Everyday Italian /title author Giada De Laurentiis /author year 2005 /year /book book category="CHILDREN" title lang="en" Harry Potter /title author J K. Rowling /author year 2005 /year price 29.99 /price /book book category="WEB" title lang="en" Learning XML /title author Erik T. Ray /author year 2003 /year price 39.95 /price /book /bookstore
2. JSON数据模型
JSON(JavaScript Object Notation)与XML类似,也适用于存储半结构化数据。JSON比XML出现得更晚,不像XML那样有比较完善的工具支持,但由于JSON更简洁,更符合程序语言的数据表达方式,因此,在互联网开发中,一般选择JSON而不是XML,JavaScript的很多工具包如jQuery、ExtJS等都大量使用了JSON。事实上,JSON已经成为了一种前端与服务器端的数据交换格式,前端程序通过Ajax发送JSON对象到后端,服务器端脚本对JSON进行解析,将其还原成服务器端对象,然后进行一些处理,反馈给前端的仍然是JSON对象。
尽管JSON是JavaScript的一个子集,但JSON是独立于语言的文本格式,并且采用了类似于C语言家族的一些习惯。许多程序语言都有解析器,可用来处理JSON数据。
JSON用于描述数据结构,有如下几种存在形式。
对象:是一个无序的“‘名称/值’对”集合。一个对象以“{”(左大括号)开始,“}”(右大括号)结束。每个“名称”后跟一个“:”(冒号);“‘名称/值’ 对”之间使用“,”(逗号)分隔。
数组:是值(value)的有序集合。一个数组以“[”(左中括号)开始,“]”(右中括号)结束。值之间使用“,”(逗号)分隔。
值:可以是双引号括起来的字符串(string)、数值(number)、true、false、NULL、对象(object)或数组(array)。这些结构可以嵌套。
下面来举一个例子。
"employees":[
{"firstName":"John", "lastName":"Doe"},
{"firstName":"Anna", "lastName":"Smith"},
{"firstName":"Peter","lastName":"Jones"}
]
在上面的例子中,对象employees是包含三个对象的数组。每个对象代表一条关于某人(有姓和名)的记录。
相对于传统的关系型数据库,一些基于文档存储的NoSQL非关系型数据库则选择JSON作为其数据存储格式,比较知名的产品有:MongoDB、CouchDB、RavenDB等。下面两个表(表3-7和表3-8)列举了其与关系数据模型和XML数据模型的不同。
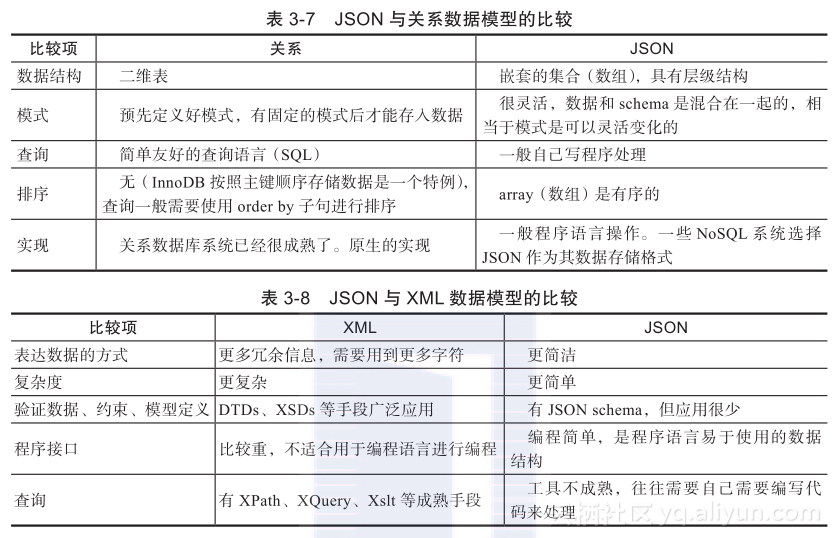
虽然XML会比JSON的存储占据更多字节,但是如果不是海量数据,一般是不会出现存储和性能上的问题的。有人可能会认为XML要比JSON的数据结构复杂得多,但如果只是用到XML的一个子集,用基本的结构,同样也是很简洁的。那为什么有人会觉得XML复杂呢?更多的原因是XML拥有大量的特性,设定很多,深入了解需要花费很多功夫,而JSON的简单模型,很快就可以掌握了。
JSON与XML最大的不同之处在于XML是一个完整的标记语言,而JSON不是,JSON仅仅是一种表达传输数据的方式,正如名字所言,JavaScript对象表示法(JavaScript Object Notation,JSON)是通过字符来表示一个对象的。XML的设计理念与JSON不同。XML利用标记语言的特性提供了绝佳的扩展性能,如果数据模型复杂多变,想要单独定义自己传输数据的模型,那么XML将是一个很好的选择,但是我们所使用的数据结构往往不需要变动,这时JSON更简洁,它的数据结构很像程序语言定义的数据结构,在你预先知道JSON结构的情况下,可以写出实用美观、可读性强的代码,如果要存储或传输的数据格式出现了变化,此时就需要重新编码来解析存储,这方面的成本往往是可以接受的。
一个奇怪的MySQL慢查询,打懵了一群不懂业务的DBA! 表上的字段既然都有索引,那么按照之前的文章分析,是两个字段都可以走上索引的。既然能够利用索引,表的总大小也就是200M左右,那么为什么形成了慢查呢?我们查看执行计划,去掉limit 后,发现他选择了走全表扫描。
首先,我们来看看DBA的具体工作,我觉得 DBA 真的很忙:备份和恢复、监控状态、集群搭建与扩容、数据迁移和高可用,这是我们 DBA 的功能。
利用Xtrabackup工具备份及恢复(MySQL DBA的必备工具) 利用Xtrabackup工具备份及恢复(MySQL DBA的必备工具) Xtrabackup——MySQL DBA的必备工具 文档参照http://www.percona.com/docs/wiki/percona-xtrabackup:start mysql要使用5.1.50版本或以上。
MySQL DBA 日常工作 最近有很多同学在跑路,有的会选择加入到DBA这个行业,可能之前做过开发,或者运维等相关行业,写这篇文章就是想让大家了解一下MySQL DBA正常工作的内容。也让大家更了解MySQL DBA。
相关文章
- mysql索引总结(2)-MySQL聚簇索引和非聚簇索引
- 实战:percona-xtrabackup 2.1.9 for mysql 5.6.19
- MySQL Binlog Digger 4.28 【mysql日志分析工具】
- 【MySQL】Mysql 日志
- 【MySQL高级】MySql中常用工具及Mysql 日志
- 【MySQL高级】Mysql复制及Mysql权限管理
- MYSQL 表结构的修改
- 《MySQL DBA修炼之道》——第2章 MySQL安装部署和入门 2.1如何选择MySQL版本
- 《MySQL DBA修炼之道》——2.4 安装InnoDB Plugin
- 《MySQL DBA修炼之道》——3.3 SQL基础
- 《MySQL DBA修炼之道》——3.7 字符集和国际化支持
- CSDN学霸课表——2017最新MySQL DBA核心课程
- 【MySQL进阶-10】mysql语句的执行流程以及集群的高可用
- Linux安装MySQL(只针对这个8.0版本其他版本的MYSQL不知道是不是也可以用可以自己尝试)
- MySQL mysqldump备份数据库及恢复数据库(mysql命令)
- 【mysql】MySQL的sql_mode模式说明及设置
- MySQL的常用命令
- 转发 可设置skip_name_resolve参数 会出现 ERROR 2005 (HY000): Unknown MySQL server host _mysql ...
- MYSQL导入csv类型的数据出现The MySQL server is running with the --secure-file-priv option
- MySQL benchmark() 重复执行某表达式
- 实践 —— 亲测从 RDS MySQL 通过数据集成导入 MaxCompute
- liunux mysql MySQL表名不区分大小写的设置方法
- 【MySQL】mysql更换root密码,全网唯一有用!
- (5.4)mysql高可用系列——MySQL异步复制(实践)